
從核心的角度看程序以及多執行緒
前言:就如我之前所說的一樣,程式只是一個被編譯器(包括彙編器以及聯結器)將你的抽象程式碼轉換為計算機能理解的有一定格式的二進位制檔案,它有一定格式(ELF,PE之類),就如之前的我所說的例子,就好比程式就如一段鐵軌,你是鐵路設計師,編譯器負責把鐵軌做好,那麼之後很多複雜的事都被核心承包了,也就是鋪鐵軌以及讓火車(CPU)在上面跑起來。接下來我描述的問題會由淺入深,來糾正很多人對於多執行緒的疑惑,因為我發現很多我認為常識性的問題實際上很多人不懂裝懂,包括很多所謂面試官,當他們問我多執行緒或者與作業系統有關的東西的時候我內心的崩潰的,於是我想著有必要寫這個東西,我之前hack的核心原始碼我能把這東西說得比較透徹,且會結合測試程式來分析其原理。(本文涉及的核心原始碼為4.9版本)
1.程序(以linux下ELF格式為例)
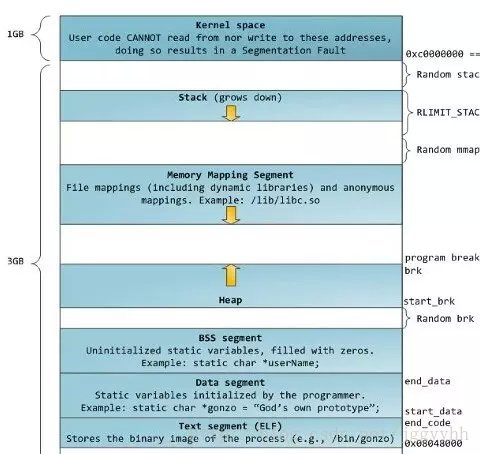
這張圖看似簡單其實是重要的一張圖,它涉及到一個程式的對映(mm_struct 佈局),舉個很簡單的例子,用的比較多的malloc函式,你第一次使用它返回的地址就是指向strart_brk也就是堆的開始這個地方(如果你沒有開ALSR堆疊隨機化保護措施那麼這個地址是固定的),關於其它段這些是基礎知識我之前的部落格有寫就不過多描述,接下來就是核心對一個程序的定義以及描述(task_struct):(linux-4.9/include/linux/Sched.h)
是不是有點懵逼,我剛開始看的時候也一樣,不過一項項來就好多了,這就是整個x86架構linux核心眼中的程序。我再附上UTL裡面的圖裡面標註了一些關鍵項struct task_struct { #ifdef CONFIG_THREAD_INFO_IN_TASK /* * For reasons of header soup (see current_thread_info()), this * must be the first element of task_struct. */ struct thread_info thread_info; #endif volatile long state; /* -1 unrunnable, 0 runnable, >0 stopped */ void *stack; atomic_t usage; unsigned int flags; /* per process flags, defined below */ unsigned int ptrace; #ifdef CONFIG_SMP struct llist_node wake_entry; int on_cpu; #ifdef CONFIG_THREAD_INFO_IN_TASK unsigned int cpu; /* current CPU */ #endif unsigned int wakee_flips; unsigned long wakee_flip_decay_ts; struct task_struct *last_wakee; int wake_cpu; #endif int on_rq; int prio, static_prio, normal_prio; unsigned int rt_priority; const struct sched_class *sched_class; struct sched_entity se; struct sched_rt_entity rt; #ifdef CONFIG_CGROUP_SCHED struct task_group *sched_task_group; #endif struct sched_dl_entity dl; #ifdef CONFIG_PREEMPT_NOTIFIERS /* list of struct preempt_notifier: */ struct hlist_head preempt_notifiers; #endif #ifdef CONFIG_BLK_DEV_IO_TRACE unsigned int btrace_seq; #endif unsigned int policy; int nr_cpus_allowed; cpumask_t cpus_allowed; #ifdef CONFIG_PREEMPT_RCU int rcu_read_lock_nesting; union rcu_special rcu_read_unlock_special; struct list_head rcu_node_entry; struct rcu_node *rcu_blocked_node; #endif /* #ifdef CONFIG_PREEMPT_RCU */ #ifdef CONFIG_TASKS_RCU unsigned long rcu_tasks_nvcsw; bool rcu_tasks_holdout; struct list_head rcu_tasks_holdout_list; int rcu_tasks_idle_cpu; #endif /* #ifdef CONFIG_TASKS_RCU */ #ifdef CONFIG_SCHED_INFO struct sched_info sched_info; #endif struct list_head tasks; #ifdef CONFIG_SMP struct plist_node pushable_tasks; struct rb_node pushable_dl_tasks; #endif struct mm_struct *mm, *active_mm; /* per-thread vma caching */ u32 vmacache_seqnum; struct vm_area_struct *vmacache[VMACACHE_SIZE]; #if defined(SPLIT_RSS_COUNTING) struct task_rss_stat rss_stat; #endif /* task state */ int exit_state; int exit_code, exit_signal; int pdeath_signal; /* The signal sent when the parent dies */ unsigned long jobctl; /* JOBCTL_*, siglock protected */ /* Used for emulating ABI behavior of previous Linux versions */ unsigned int personality; /* scheduler bits, serialized by scheduler locks */ unsigned sched_reset_on_fork:1; unsigned sched_contributes_to_load:1; unsigned sched_migrated:1; unsigned sched_remote_wakeup:1; unsigned :0; /* force alignment to the next boundary */ /* unserialized, strictly 'current' */ unsigned in_execve:1; /* bit to tell LSMs we're in execve */ unsigned in_iowait:1; #if !defined(TIF_RESTORE_SIGMASK) unsigned restore_sigmask:1; #endif #ifdef CONFIG_MEMCG unsigned memcg_may_oom:1; #ifndef CONFIG_SLOB unsigned memcg_kmem_skip_account:1; #endif #endif #ifdef CONFIG_COMPAT_BRK unsigned brk_randomized:1; #endif unsigned long atomic_flags; /* Flags needing atomic access. */ struct restart_block restart_block; pid_t pid; pid_t tgid; #ifdef CONFIG_CC_STACKPROTECTOR /* Canary value for the -fstack-protector gcc feature */ unsigned long stack_canary; #endif /* * pointers to (original) parent process, youngest child, younger sibling, * older sibling, respectively. (p->father can be replaced with * p->real_parent->pid) */ struct task_struct __rcu *real_parent; /* real parent process */ struct task_struct __rcu *parent; /* recipient of SIGCHLD, wait4() reports */ /* * children/sibling forms the list of my natural children */ struct list_head children; /* list of my children */ struct list_head sibling; /* linkage in my parent's children list */ struct task_struct *group_leader; /* threadgroup leader */ /* * ptraced is the list of tasks this task is using ptrace on. * This includes both natural children and PTRACE_ATTACH targets. * p->ptrace_entry is p's link on the p->parent->ptraced list. */ struct list_head ptraced; struct list_head ptrace_entry; /* PID/PID hash table linkage. */ struct pid_link pids[PIDTYPE_MAX]; struct list_head thread_group; struct list_head thread_node; struct completion *vfork_done; /* for vfork() */ int __user *set_child_tid; /* CLONE_CHILD_SETTID */ int __user *clear_child_tid; /* CLONE_CHILD_CLEARTID */ cputime_t utime, stime, utimescaled, stimescaled; cputime_t gtime; struct prev_cputime prev_cputime; #ifdef CONFIG_VIRT_CPU_ACCOUNTING_GEN seqcount_t vtime_seqcount; unsigned long long vtime_snap; enum { /* Task is sleeping or running in a CPU with VTIME inactive */ VTIME_INACTIVE = 0, /* Task runs in userspace in a CPU with VTIME active */ VTIME_USER, /* Task runs in kernelspace in a CPU with VTIME active */ VTIME_SYS, } vtime_snap_whence; #endif #ifdef CONFIG_NO_HZ_FULL atomic_t tick_dep_mask; #endif unsigned long nvcsw, nivcsw; /* context switch counts */ u64 start_time; /* monotonic time in nsec */ u64 real_start_time; /* boot based time in nsec */ /* mm fault and swap info: this can arguably be seen as either mm-specific or thread-specific */ unsigned long min_flt, maj_flt; struct task_cputime cputime_expires; struct list_head cpu_timers[3]; /* process credentials */ const struct cred __rcu *real_cred; /* objective and real subjective task * credentials (COW) */ const struct cred __rcu *cred; /* effective (overridable) subjective task * credentials (COW) */ char comm[TASK_COMM_LEN]; /* executable name excluding path - access with [gs]et_task_comm (which lock it with task_lock()) - initialized normally by setup_new_exec */ /* file system info */ struct nameidata *nameidata; #ifdef CONFIG_SYSVIPC /* ipc stuff */ struct sysv_sem sysvsem; struct sysv_shm sysvshm; #endif #ifdef CONFIG_DETECT_HUNG_TASK /* hung task detection */ unsigned long last_switch_count; #endif /* filesystem information */ struct fs_struct *fs; /* open file information */ struct files_struct *files; /* namespaces */ struct nsproxy *nsproxy; /* signal handlers */ struct signal_struct *signal; struct sighand_struct *sighand; sigset_t blocked, real_blocked; sigset_t saved_sigmask; /* restored if set_restore_sigmask() was used */ struct sigpending pending; unsigned long sas_ss_sp; size_t sas_ss_size; unsigned sas_ss_flags; struct callback_head *task_works; struct audit_context *audit_context; #ifdef CONFIG_AUDITSYSCALL kuid_t loginuid; unsigned int sessionid; #endif struct seccomp seccomp; /* Thread group tracking */ u32 parent_exec_id; u32 self_exec_id; /* Protection of (de-)allocation: mm, files, fs, tty, keyrings, mems_allowed, * mempolicy */ spinlock_t alloc_lock; /* Protection of the PI data structures: */ raw_spinlock_t pi_lock; struct wake_q_node wake_q; #ifdef CONFIG_RT_MUTEXES /* PI waiters blocked on a rt_mutex held by this task */ struct rb_root pi_waiters; struct rb_node *pi_waiters_leftmost; /* Deadlock detection and priority inheritance handling */ struct rt_mutex_waiter *pi_blocked_on; #endif #ifdef CONFIG_DEBUG_MUTEXES /* mutex deadlock detection */ struct mutex_waiter *blocked_on; #endif #ifdef CONFIG_TRACE_IRQFLAGS unsigned int irq_events; unsigned long hardirq_enable_ip; unsigned long hardirq_disable_ip; unsigned int hardirq_enable_event; unsigned int hardirq_disable_event; int hardirqs_enabled; int hardirq_context; unsigned long softirq_disable_ip; unsigned long softirq_enable_ip; unsigned int softirq_disable_event; unsigned int softirq_enable_event; int softirqs_enabled; int softirq_context; #endif #ifdef CONFIG_LOCKDEP # define MAX_LOCK_DEPTH 48UL u64 curr_chain_key; int lockdep_depth; unsigned int lockdep_recursion; struct held_lock held_locks[MAX_LOCK_DEPTH]; gfp_t lockdep_reclaim_gfp; #endif #ifdef CONFIG_UBSAN unsigned int in_ubsan; #endif /* journalling filesystem info */ void *journal_info; /* stacked block device info */ struct bio_list *bio_list; #ifdef CONFIG_BLOCK /* stack plugging */ struct blk_plug *plug; #endif /* VM state */ struct reclaim_state *reclaim_state; struct backing_dev_info *backing_dev_info; struct io_context *io_context; unsigned long ptrace_message; siginfo_t *last_siginfo; /* For ptrace use. */ struct task_io_accounting ioac; #if defined(CONFIG_TASK_XACCT) u64 acct_rss_mem1; /* accumulated rss usage */ u64 acct_vm_mem1; /* accumulated virtual memory usage */ cputime_t acct_timexpd; /* stime + utime since last update */ #endif #ifdef CONFIG_CPUSETS nodemask_t mems_allowed; /* Protected by alloc_lock */ seqcount_t mems_allowed_seq; /* Seqence no to catch updates */ int cpuset_mem_spread_rotor; int cpuset_slab_spread_rotor; #endif #ifdef CONFIG_CGROUPS /* Control Group info protected by css_set_lock */ struct css_set __rcu *cgroups; /* cg_list protected by css_set_lock and tsk->alloc_lock */ struct list_head cg_list; #endif #ifdef CONFIG_FUTEX struct robust_list_head __user *robust_list; #ifdef CONFIG_COMPAT struct compat_robust_list_head __user *compat_robust_list; #endif struct list_head pi_state_list; struct futex_pi_state *pi_state_cache; #endif #ifdef CONFIG_PERF_EVENTS struct perf_event_context *perf_event_ctxp[perf_nr_task_contexts]; struct mutex perf_event_mutex; struct list_head perf_event_list; #endif #ifdef CONFIG_DEBUG_PREEMPT unsigned long preempt_disable_ip; #endif #ifdef CONFIG_NUMA struct mempolicy *mempolicy; /* Protected by alloc_lock */ short il_next; short pref_node_fork; #endif #ifdef CONFIG_NUMA_BALANCING int numa_scan_seq; unsigned int numa_scan_period; unsigned int numa_scan_period_max; int numa_preferred_nid; unsigned long numa_migrate_retry; u64 node_stamp; /* migration stamp */ u64 last_task_numa_placement; u64 last_sum_exec_runtime; struct callback_head numa_work; struct list_head numa_entry; struct numa_group *numa_group; /* * numa_faults is an array split into four regions: * faults_memory, faults_cpu, faults_memory_buffer, faults_cpu_buffer * in this precise order. * * faults_memory: Exponential decaying average of faults on a per-node * basis. Scheduling placement decisions are made based on these * counts. The values remain static for the duration of a PTE scan. * faults_cpu: Track the nodes the process was running on when a NUMA * hinting fault was incurred. * faults_memory_buffer and faults_cpu_buffer: Record faults per node * during the current scan window. When the scan completes, the counts * in faults_memory and faults_cpu decay and these values are copied. */ unsigned long *numa_faults; unsigned long total_numa_faults; /* * numa_faults_locality tracks if faults recorded during the last * scan window were remote/local or failed to migrate. The task scan * period is adapted based on the locality of the faults with different * weights depending on whether they were shared or private faults */ unsigned long numa_faults_locality[3]; unsigned long numa_pages_migrated; #endif /* CONFIG_NUMA_BALANCING */ #ifdef CONFIG_ARCH_WANT_BATCHED_UNMAP_TLB_FLUSH struct tlbflush_unmap_batch tlb_ubc; #endif struct rcu_head rcu; /* * cache last used pipe for splice */ struct pipe_inode_info *splice_pipe; struct page_frag task_frag; #ifdef CONFIG_TASK_DELAY_ACCT struct task_delay_info *delays; #endif #ifdef CONFIG_FAULT_INJECTION int make_it_fail; #endif /* * when (nr_dirtied >= nr_dirtied_pause), it's time to call * balance_dirty_pages() for some dirty throttling pause */ int nr_dirtied; int nr_dirtied_pause; unsigned long dirty_paused_when; /* start of a write-and-pause period */ #ifdef CONFIG_LATENCYTOP int latency_record_count; struct latency_record latency_record[LT_SAVECOUNT]; #endif /* * time slack values; these are used to round up poll() and * select() etc timeout values. These are in nanoseconds. */ u64 timer_slack_ns; u64 default_timer_slack_ns; #ifdef CONFIG_KASAN unsigned int kasan_depth; #endif #ifdef CONFIG_FUNCTION_GRAPH_TRACER /* Index of current stored address in ret_stack */ int curr_ret_stack; /* Stack of return addresses for return function tracing */ struct ftrace_ret_stack *ret_stack; /* time stamp for last schedule */ unsigned long long ftrace_timestamp; /* * Number of functions that haven't been traced * because of depth overrun. */ atomic_t trace_overrun; /* Pause for the tracing */ atomic_t tracing_graph_pause; #endif #ifdef CONFIG_TRACING /* state flags for use by tracers */ unsigned long trace; /* bitmask and counter of trace recursion */ unsigned long trace_recursion; #endif /* CONFIG_TRACING */ #ifdef CONFIG_KCOV /* Coverage collection mode enabled for this task (0 if disabled). */ enum kcov_mode kcov_mode; /* Size of the kcov_area. */ unsigned kcov_size; /* Buffer for coverage collection. */ void *kcov_area; /* kcov desciptor wired with this task or NULL. */ struct kcov *kcov; #endif #ifdef CONFIG_MEMCG struct mem_cgroup *memcg_in_oom; gfp_t memcg_oom_gfp_mask; int memcg_oom_order; /* number of pages to reclaim on returning to userland */ unsigned int memcg_nr_pages_over_high; #endif #ifdef CONFIG_UPROBES struct uprobe_task *utask; #endif #if defined(CONFIG_BCACHE) || defined(CONFIG_BCACHE_MODULE) unsigned int sequential_io; unsigned int sequential_io_avg; #endif #ifdef CONFIG_DEBUG_ATOMIC_SLEEP unsigned long task_state_change; #endif int pagefault_disabled; #ifdef CONFIG_MMU struct task_struct *oom_reaper_list; #endif #ifdef CONFIG_VMAP_STACK struct vm_struct *stack_vm_area; #endif #ifdef CONFIG_THREAD_INFO_IN_TASK /* A live task holds one reference. */ atomic_t stack_refcount; #endif /* CPU-specific state of this task */ struct thread_struct thread; /* * WARNING: on x86, 'thread_struct' contains a variable-sized * structure. It *MUST* be at the end of 'task_struct'. * * Do not put anything below here! */
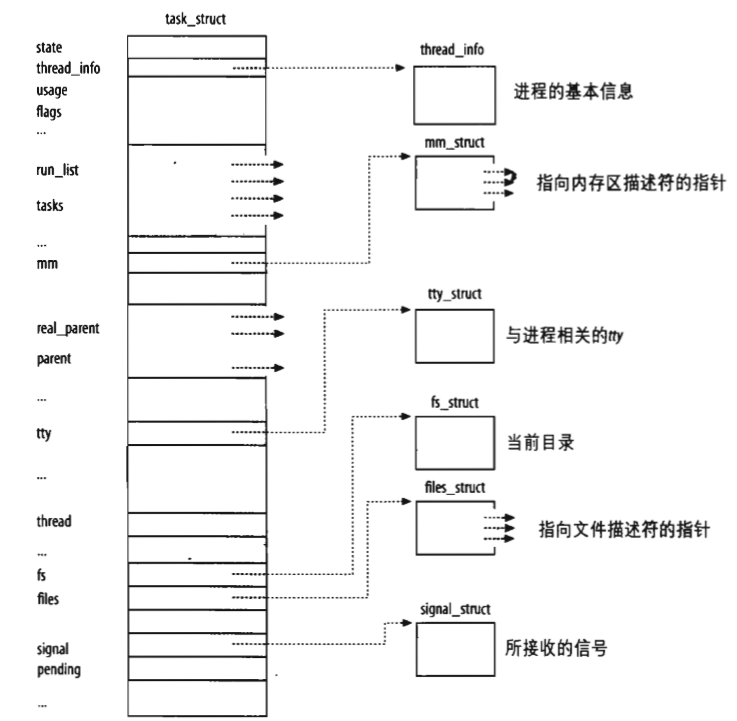
1.1與thread_info相關的東西:
我來解釋一下整個程序描述符,首先第一個thread_info,這個欄位存放一個核心態堆疊中一個名為thread_info的結構體的頭部的地址,這個結構體十分重要,是核心用來進行軟程序切換程序上下文存放的地方,也就是在程序切換時,其關鍵資訊存放的地方,其實核心只存放了一部分程序上下文在堆疊上,還有一部分是在TSS段中(TSS段中主要是存各類暫存器的硬體上下文),我認為我有必要再深入一下,請看核心CPU中關於這個TSS段的定義的定義:
static inline void load_cr3(pgd_t *pgdir)
{
write_cr3(__pa(pgdir));
}
#ifdef CONFIG_X86_32
/* This is the TSS defined by the hardware. */
struct x86_hw_tss {
unsigned short back_link, __blh;
unsigned long sp0;
unsigned short ss0, __ss0h;
unsigned long sp1;
/*
* We don't use ring 1, so ss1 is a convenient scratch space in
* the same cacheline as sp0. We use ss1 to cache the value in
* MSR_IA32_SYSENTER_CS. When we context switch
* MSR_IA32_SYSENTER_CS, we first check if the new value being
* written matches ss1, and, if it's not, then we wrmsr the new
* value and update ss1.
*
* The only reason we context switch MSR_IA32_SYSENTER_CS is
* that we set it to zero in vm86 tasks to avoid corrupting the
* stack if we were to go through the sysenter path from vm86
* mode.
*/
unsigned short ss1; /* MSR_IA32_SYSENTER_CS */
unsigned short __ss1h;
unsigned long sp2;
unsigned short ss2, __ss2h;
unsigned long __cr3;
unsigned long ip;
unsigned long flags;
unsigned long ax;
unsigned long cx;
unsigned long dx;
unsigned long bx;
unsigned long sp;
unsigned long bp;
unsigned long si;
unsigned long di;
unsigned short es, __esh;
unsigned short cs, __csh;
unsigned short ss, __ssh;
unsigned short ds, __dsh;
unsigned short fs, __fsh;
unsigned short gs, __gsh;
unsigned short ldt, __ldth;
unsigned short trace;
unsigned short io_bitmap_base;
} __attribute__((packed));
#else
struct x86_hw_tss {
u32 reserved1;
u64 sp0;
u64 sp1;
u64 sp2;
u64 reserved2;
u64 ist[7];
u32 reserved3;
u32 reserved4;
u16 reserved5;
u16 io_bitmap_base;
} __attribute__((packed)) ____cacheline_aligned;
#endif
需要注意的是TSS段是每個cpu只有一個,但是一個cpu可能要維持多個程序資訊故在32位機器下tss段還是一些通用暫存器的臨時寄存處,但是在64位機器也就是多核處理器開始逐漸流行的機器上,核心用thread欄位暫存程序硬體上下文,tss段作一些io點陣圖暫存以及程序從使用者態到核心態這個過程中核心態堆疊的定址功能,thread欄位如下:
struct thread_struct {
/* Cached TLS descriptors: */
struct desc_struct tls_array[GDT_ENTRY_TLS_ENTRIES];
unsigned long sp0;
unsigned long sp;
#ifdef CONFIG_X86_32
unsigned long sysenter_cs;
#else
unsigned short es;
unsigned short ds;
unsigned short fsindex;
unsigned short gsindex;
#endif
u32 status; /* thread synchronous flags */
#ifdef CONFIG_X86_64
unsigned long fsbase;
unsigned long gsbase;
#else
/*
* XXX: this could presumably be unsigned short. Alternatively,
* 32-bit kernels could be taught to use fsindex instead.
*/
unsigned long fs;
unsigned long gs;
#endif
/* Save middle states of ptrace breakpoints */
struct perf_event *ptrace_bps[HBP_NUM];
/* Debug status used for traps, single steps, etc... */
unsigned long debugreg6;
/* Keep track of the exact dr7 value set by the user */
unsigned long ptrace_dr7;
/* Fault info: */
unsigned long cr2;
unsigned long trap_nr;
unsigned long error_code;
#ifdef CONFIG_VM86
/* Virtual 86 mode info */
struct vm86 *vm86;
#endif
/* IO permissions: */
unsigned long *io_bitmap_ptr;
unsigned long iopl;
/* Max allowed port in the bitmap, in bytes: */
unsigned io_bitmap_max;
mm_segment_t addr_limit;
unsigned int sig_on_uaccess_err:1;
unsigned int uaccess_err:1; /* uaccess failed */
/* Floating point and extended processor state */
struct fpu fpu;
/*
* WARNING: 'fpu' is dynamically-sized. It *MUST* be at
* the end.
*/
};然而eax那類通用暫存器的硬體上下文是儲存在核心堆疊上的,可以通過thread_info來找到,thread_info放在核心堆疊底部。而其中cr3控制暫存器指向的是當前cpu控制程序的頁目錄指標表(PDPT 64位機器必有的一個東西,要不然定址能力突破不了4GB也就是所謂記憶體空間)或者頁全域性目錄表也就是PDGT(這個是32位機器的分頁定址第一級分頁),cr3在startup階段被設定代表著核心開啟了分頁,每當程序被__switch_to呼叫切換時,cr3的值就會改變指向當前cpu活躍程序的頁目錄基地址,tss段是全域性段描述符GDT中的一項,這個結構體每一項都特別重要:
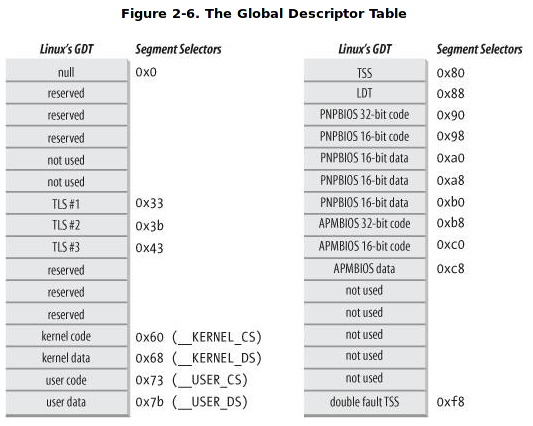
在linux-4.9/arch/x86/boot/Pm.c中有對其初始化的程式碼,凡是關於核心初始化的程式碼都是linus寫的:p,當時他才20幾歲,其程式設計水平可想而知:
struct gdt_ptr {
u16 len;
u32 ptr;
} __attribute__((packed));
static void setup_gdt(void)
{
/* There are machines which are known to not boot with the GDT
being 8-byte unaligned. Intel recommends 16 byte alignment. */
static const u64 boot_gdt[] __attribute__((aligned(16))) = {
/* CS: code, read/execute, 4 GB, base 0 */
[GDT_ENTRY_BOOT_CS] = GDT_ENTRY(0xc09b, 0, 0xfffff),
/* DS: data, read/write, 4 GB, base 0 */
[GDT_ENTRY_BOOT_DS] = GDT_ENTRY(0xc093, 0, 0xfffff),
/* TSS: 32-bit tss, 104 bytes, base 4096 */
/* We only have a TSS here to keep Intel VT happy;
we don't actually use it for anything. */
[GDT_ENTRY_BOOT_TSS] = GDT_ENTRY(0x0089, 4096, 103),
};
/* Xen HVM incorrectly stores a pointer to the gdt_ptr, instead
of the gdt_ptr contents. Thus, make it static so it will
stay in memory, at least long enough that we switch to the
proper kernel GDT. */
static struct gdt_ptr gdt;
gdt.len = sizeof(boot_gdt)-1;
gdt.ptr = (u32)&boot_gdt + (ds() << 4);
asm volatile("lgdtl %0" : : "m" (gdt));
}
這段程式碼很有意思,intel VT自行搜尋一下就知道,就如我所說,位於GDT中的tss是每個cpu都有一個,用於硬體上下文(暫存器)儲存,而thread_info也是如此,核心態堆疊佔用2個頁框,在4KB頁框機制下也就是8KB大小,thread_info也有程序上下文:
struct thread_info {
unsigned long flags; /* low level flags */
mm_segment_t addr_limit; /* address limit */
struct task_struct *task; /* main task structure */
int preempt_count; /* 0 => preemptable, <0 => bug */
int cpu; /* cpu */
};
struct thread_info {
unsigned long flags; /* low level flags */
int preempt_count; /* 0 => preemptable, <0 => bug */
mm_segment_t addr_limit; /* address limit */
struct task_struct *task; /* main task structure */
__u32 cpu; /* cpu */
__u32 cpu_domain; /* cpu domain */
struct cpu_context_save cpu_context; /* cpu context */
__u32 syscall; /* syscall number */
__u8 used_cp[16]; /* thread used copro */
unsigned long tp_value[2]; /* TLS registers */
#ifdef CONFIG_CRUNCH
struct crunch_state crunchstate;
#endif
union fp_state fpstate __attribute__((aligned(8)));
union vfp_state vfpstate;
#ifdef CONFIG_ARM_THUMBEE
unsigned long thumbee_state; /* ThumbEE Handler Base register */
#endif
這個是兩個架構的thread_info定義,可見其包含的程序上下文有此時核心態堆疊指向的程序描述符,以及CPU組,cpu標號,以及搶佔等級等等,接下來我們可以看看程序切換的關鍵函式__swich_to(linux-4.9/arch/x86/kernel/Process_32.c):
__switch_to(struct task_struct *prev_p, struct task_struct *next_p)
{
struct thread_struct *prev = &prev_p->thread,
*next = &next_p->thread;
struct fpu *prev_fpu = &prev->fpu;
struct fpu *next_fpu = &next->fpu;
int cpu = smp_processor_id();
struct tss_struct *tss = &per_cpu(cpu_tss, cpu);
fpu_switch_t fpu_switch;
/* never put a printk in __switch_to... printk() calls wake_up*() indirectly */
fpu_switch = switch_fpu_prepare(prev_fpu, next_fpu, cpu);
/*
* Save away %gs. No need to save %fs, as it was saved on the
* stack on entry. No need to save %es and %ds, as those are
* always kernel segments while inside the kernel. Doing this
* before setting the new TLS descriptors avoids the situation
* where we temporarily have non-reloadable segments in %fs
* and %gs. This could be an issue if the NMI handler ever
* used %fs or %gs (it does not today), or if the kernel is
* running inside of a hypervisor layer.
*/
lazy_save_gs(prev->gs);
/*
* Load the per-thread Thread-Local Storage descriptor.
*/
load_TLS(next, cpu);
/*
* Restore IOPL if needed. In normal use, the flags restore
* in the switch assembly will handle this. But if the kernel
* is running virtualized at a non-zero CPL, the popf will
* not restore flags, so it must be done in a separate step.
*/
if (get_kernel_rpl() && unlikely(prev->iopl != next->iopl))
set_iopl_mask(next->iopl);
/*
* Now maybe handle debug registers and/or IO bitmaps
*/
if (unlikely(task_thread_info(prev_p)->flags & _TIF_WORK_CTXSW_PREV ||
task_thread_info(next_p)->flags & _TIF_WORK_CTXSW_NEXT))
__switch_to_xtra(prev_p, next_p, tss);
/*
* Leave lazy mode, flushing any hypercalls made here.
* This must be done before restoring TLS segments so
* the GDT and LDT are properly updated, and must be
* done before fpu__restore(), so the TS bit is up
* to date.
*/
arch_end_context_switch(next_p);
/*
* Reload esp0 and cpu_current_top_of_stack. This changes
* current_thread_info().
*/
load_sp0(tss, next);
this_cpu_write(cpu_current_top_of_stack,
(unsigned long)task_stack_page(next_p) +
THREAD_SIZE);
/*
* Restore %gs if needed (which is common)
*/
if (prev->gs | next->gs)
lazy_load_gs(next->gs);
switch_fpu_finish(next_fpu, fpu_switch);
this_cpu_write(current_task, next_p);
return prev_p;
}
1.2mm_strcut
這個是程序記憶體地址對映空間,它描述了整個當前程序的虛擬地址空間,就是這個東西描述了圖一的整個地址空間:
struct mm_struct {
struct vm_area_struct *mmap; /* list of VMAs */
struct rb_root mm_rb;
u32 vmacache_seqnum; /* per-thread vmacache */
#ifdef CONFIG_MMU
unsigned long (*get_unmapped_area) (struct file *filp,
unsigned long addr, unsigned long len,
unsigned long pgoff, unsigned long flags);
#endif
unsigned long mmap_base; /* base of mmap area */
unsigned long mmap_legacy_base; /* base of mmap area in bottom-up allocations */
unsigned long task_size; /* size of task vm space */
unsigned long highest_vm_end; /* highest vma end address */
pgd_t * pgd; //頁目錄起始地址
atomic_t mm_users; /* How many users with user space? */
atomic_t mm_count; /* How many references to "struct mm_struct" (users count as 1) */
atomic_long_t nr_ptes; /* PTE page table pages */
#if CONFIG_PGTABLE_LEVELS > 2
atomic_long_t nr_pmds; /* PMD page table pages */
#endif
int map_count; /* number of VMAs */
spinlock_t page_table_lock; /* Protects page tables and some counters */
struct rw_semaphore mmap_sem;
struct list_head mmlist; /* List of maybe swapped mm's. These are globally strung
* together off init_mm.mmlist, and are protected
* by mmlist_lock
*/
unsigned long hiwater_rss; /* High-watermark of RSS usage */
unsigned long hiwater_vm; /* High-water virtual memory usage */
unsigned long total_vm; /* Total pages mapped */
unsigned long locked_vm; /* Pages that have PG_mlocked set */
unsigned long pinned_vm; /* Refcount permanently increased */
unsigned long data_vm; /* VM_WRITE & ~VM_SHARED & ~VM_STACK */
unsigned long exec_vm; /* VM_EXEC & ~VM_WRITE & ~VM_STACK */
unsigned long stack_vm; /* VM_STACK */
unsigned long def_flags;
unsigned long start_code, end_code, start_data, end_data;/*這些就是之前圖一的各種段的初始化,包括BSS,DATA,BRK,STACK*/
unsigned long start_brk, brk, start_stack;
unsigned long arg_start, arg_end, env_start, env_end;
unsigned long saved_auxv[AT_VECTOR_SIZE]; /* for /proc/PID/auxv */
/*
* Special counters, in some configurations protected by the
* page_table_lock, in other configurations by being atomic.
*/
struct mm_rss_stat rss_stat;
struct linux_binfmt *binfmt;
cpumask_var_t cpu_vm_mask_var;
/* Architecture-specific MM context */
mm_context_t context;
unsigned long flags; /* Must use atomic bitops to access the bits */
struct core_state *core_state; /* coredumping support */
#ifdef CONFIG_AIO
spinlock_t ioctx_lock;
struct kioctx_table __rcu *ioctx_table;
#endif
#ifdef CONFIG_MEMCG
/*
* "owner" points to a task that is regarded as the canonical
* user/owner of this mm. All of the following must be true in
* order for it to be changed:
*
* current == mm->owner
* current->mm != mm
* new_owner->mm == mm
* new_owner->alloc_lock is held
*/
struct task_struct __rcu *owner;
#endif
/* store ref to file /proc/<pid>/exe symlink points to */
struct file __rcu *exe_file;
#ifdef CONFIG_MMU_NOTIFIER
struct mmu_notifier_mm *mmu_notifier_mm;
#endif
#if defined(CONFIG_TRANSPARENT_HUGEPAGE) && !USE_SPLIT_PMD_PTLOCKS
pgtable_t pmd_huge_pte; /* protected by page_table_lock */
#endif
#ifdef CONFIG_CPUMASK_OFFSTACK
struct cpumask cpumask_allocation;
#endif
#ifdef CONFIG_NUMA_BALANCING
/*
* numa_next_scan is the next time that the PTEs will be marked
* pte_numa. NUMA hinting faults will gather statistics and migrate
* pages to new nodes if necessary.
*/
unsigned long numa_next_scan;
/* Restart point for scanning and setting pte_numa */
unsigned long numa_scan_offset;
/* numa_scan_seq prevents two threads setting pte_numa */
int numa_scan_seq;
#endif
#if defined(CONFIG_NUMA_BALANCING) || defined(CONFIG_COMPACTION)
/*
* An operation with batched TLB flushing is going on. Anything that
* can move process memory needs to flush the TLB when moving a
* PROT_NONE or PROT_NUMA mapped page.
*/
bool tlb_flush_pending;
#endif
struct uprobes_state uprobes_state;
#ifdef CONFIG_X86_INTEL_MPX
/* address of the bounds directory */
void __user *bd_addr;
#endif
#ifdef CONFIG_HUGETLB_PAGE
atomic_long_t hugetlb_usage;
#endif
struct work_struct async_put_work;
};因為你的程式被核心對映到多個頁上,這些頁被核心設定成不連續的vm_area_struct,核心用紅黑樹管理這些不連續的vm_area_strcut,限於篇幅這部分暫不深入,這樣做的結果導致了一些事情,那就是你的程序的data段和text段等等是不連續的,核心通過雙鏈表以及紅黑樹管理這些不連續虛擬地址片段,但是整個程序的地址空間被視為一個整個也就是一個mm描述符,故mm_struct有當前程序記憶體空間的頁目錄基址,而且還會對引用這個程序記憶體整體的使用者進行計數。
1.3run_list以及state
這兩個欄位主要是描述程序狀態的,以及特權等級,run_list其實是由多個描述不同許可權的雙鏈表構成它將不同優先權的執行程序連結在一起,state則描述了程序的狀態,這兩個欄位深入下去可以寫很多字,但與本文內容關係不太故不作介紹,感興趣可以自己hack。
1.4real_parent與parent
這兩個欄位代表真正父程序以及當前父程序,一般情況下是一樣的,但是用ptrace之類的除錯手法對程序進行跟蹤時,為了跟蹤程序能遍歷整個被跟蹤程序的程序關係樹(也就是父子以及兄弟之類的),這時的parent就指向跟蹤程序。
1.5fs_struct
指向核心的檔案系統中該程序對映的程式的節點,關於檔案系統我之前寫過部落格。
1.6files_struct
這個是維護當前程序開啟檔案的檔案描述符的,預設0是標準輸入,1輸出,2錯誤輸出,而後的就是開啟檔案的檔案描述符,一般開啟的一個檔案是3。
2.多執行緒
其實多執行緒在linux下只是一個程序的裁剪體,當前程序的執行緒的mm基地址是存放在GDT中的TLS欄位的,在task_struct的thread欄位中有個
struct desc_struct tls_array[GDT_ENTRY_TLS_ENTRIES];#include <stdlib.h>
#include <stdio.h>
#include <errno.h>
#include <pthread.h>
static pthread_mutex_t mtx = PTHREAD_MUTEX_INITIALIZER;
static pthread_cond_t cond = PTHREAD_COND_INITIALIZER;
static void pthread_func_1 (void);
static void pthread_func_2 (void);
int main (int argc, char** argv)
{
pthread_t pt_1 = 0;
pthread_t pt_2 = 0;
pthread_attr_t attr = {0};
int ret = 0;
pthread_attr_init (&attr);
pthread_attr_setscope (&attr, PTHREAD_SCOPE_SYSTEM);
pthread_attr_setdetachstate (&attr, PTHREAD_CREATE_DETACHED);
ret = pthread_create (&pt_1, NULL, (void *)pthread_func_1, NULL);
if (ret != 0)
{
perror ("pthread_1_create");
}
ret = pthread_create (&pt_2, NULL,(void *) pthread_func_2, NULL);
if (ret != 0)
{
perror ("pthread_2_create");
}
pthread_join (pt_1, NULL);
pthread_join (pt_2, NULL);
return 0;
}
static void pthread_func_1 (void)
{
while (1)
{
int i = 0;
int pid= getpid();
for (; i < 6; i++)
{
printf ("This is pthread_1,the tpid is %d\n ",pid);
if (i==2)
{
pthread_cond_signal(&cond);
return 0;
}
}
}
}
static void pthread_func_2 (void)
{
while(1)
{
int rc;
int pid= getpid();
pthread_mutex_lock(&mtx);
rc = pthread_cond_wait(&cond, &mtx);
if(rc ==0)
{
int i = 0;
for (; i < 3 ; i ++)
{
printf ("This is pthread_2.the tpid is %d\n",pid);
}
pthread_mutex_unlock(&mtx);
}
}
}
為啥要新增getuid(),因為我只想更正一個錯誤觀念,getuid()的返回值是tpid也就是當前執行緒所線上程組的pid而不是所謂pid,執行緒是有獨立pid的,但是一個程序裡面的執行緒的tpid是相同的,來我們跟蹤一下:
execve("./test3", ["./test3"], [/* 42 vars */]) = 0
brk(NULL) = 0x1615000
access("/etc/ld.so.nohwcap", F_OK) = -1 ENOENT (No such file or directory)
mmap(NULL, 8192, PROT_READ|PROT_WRITE, MAP_PRIVATE|MAP_ANONYMOUS, -1, 0) = 0x7f98d8606000
access("/etc/ld.so.preload", R_OK) = -1 ENOENT (No such file or directory)
open("/etc/ld.so.cache", O_RDONLY|O_CLOEXEC) = 3
fstat(3, {st_mode=S_IFREG|0644, st_size=130450, ...}) = 0
mmap(NULL, 130450, PROT_READ, MAP_PRIVATE, 3, 0) = 0x7f98d85e6000
close(3) = 0
access("/etc/ld.so.nohwcap", F_OK) = -1 ENOENT (No such file or directory)
open("/lib/x86_64-linux-gnu/libpthread.so.0", O_RDONLY|O_CLOEXEC) = 3
read(3, "\177ELF\2\1\1\0\0\0\0\0\0\0\0\0\3\0>\0\1\0\0\0\20o\0\0\0\0\0\0"..., 832) = 832
fstat(3, {st_mode=S_IFREG|0755, st_size=137440, ...}) = 0
mmap(NULL, 2213008, PROT_READ|PROT_EXEC, MAP_PRIVATE|MAP_DENYWRITE, 3, 0) = 0x7f98d81cb000
mprotect(0x7f98d81e3000, 2093056, PROT_NONE) = 0
mmap(0x7f98d83e2000, 8192, PROT_READ|PROT_WRITE, MAP_PRIVATE|MAP_FIXED|MAP_DENYWRITE, 3, 0x17000) = 0x7f98d83e2000
mmap(0x7f98d83e4000, 13456, PROT_READ|PROT_WRITE, MAP_PRIVATE|MAP_FIXED|MAP_ANONYMOUS, -1, 0) = 0x7f98d83e4000
close(3) = 0
access("/etc/ld.so.nohwcap", F_OK) = -1 ENOENT (No such file or directory)
open("/lib/x86_64-linux-gnu/libc.so.6", O_RDONLY|O_CLOEXEC) = 3
read(3, "\177ELF\2\1\1\3\0\0\0\0\0\0\0\0\3\0>\0\1\0\0\0P\34\2\0\0\0\0\0"..., 832) = 832
fstat(3, {st_mode=S_IFREG|0755, st_size=1729984, ...}) = 0
mmap(NULL, 3836448, PROT_READ|PROT_EXEC, MAP_PRIVATE|MAP_DENYWRITE, 3, 0) = 0x7f98d7e22000
mprotect(0x7f98d7fc1000, 2097152, PROT_NONE) = 0
mmap(0x7f98d81c1000, 24576, PROT_READ|PROT_WRITE, MAP_PRIVATE|MAP_FIXED|MAP_DENYWRITE, 3, 0x19f000) = 0x7f98d81c1000
mmap(0x7f98d81c7000, 14880, PROT_READ|PROT_WRITE, MAP_PRIVATE|MAP_FIXED|MAP_ANONYMOUS, -1, 0) = 0x7f98d81c7000
close(3) = 0
mmap(NULL, 4096, PROT_READ|PROT_WRITE, MAP_PRIVATE|MAP_ANONYMOUS, -1, 0) = 0x7f98d85e5000
mmap(NULL, 4096, PROT_READ|PROT_WRITE, MAP_PRIVATE|MAP_ANONYMOUS, -1, 0) = 0x7f98d85e4000
mmap(NULL, 4096, PROT_READ|PROT_WRITE, MAP_PRIVATE|MAP_ANONYMOUS, -1, 0) = 0x7f98d85e3000
arch_prctl(ARCH_SET_FS, 0x7f98d85e4700) = 0
mprotect(0x7f98d81c1000, 16384, PROT_READ) = 0
mprotect(0x7f98d83e2000, 4096, PROT_READ) = 0
mprotect(0x7f98d8608000, 4096, PROT_READ) = 0
munmap(0x7f98d85e6000, 130450) = 0
set_tid_address(0x7f98d85e49d0) = 4298
set_robust_list(0x7f98d85e49e0, 24) = 0
rt_sigaction(SIGRTMIN, {sa_handler=0x7f98d81d19f0, sa_mask=[], sa_flags=SA_RESTORER|SA_SIGINFO, sa_restorer=0x7f98d81da8d0}, NULL, 8) = 0
rt_sigaction(SIGRT_1, {sa_handler=0x7f98d81d1a80, sa_mask=[], sa_flags=SA_RESTORER|SA_RESTART|SA_SIGINFO, sa_restorer=0x7f98d81da8d0}, NULL, 8) = 0
rt_sigprocmask(SIG_UNBLOCK, [RTMIN RT_1], NULL, 8) = 0
getrlimit(RLIMIT_STACK, {rlim_cur=8192*1024, rlim_max=RLIM64_INFINITY}) = 0
mmap(NULL, 8392704, PROT_READ|PROT_WRITE, MAP_PRIVATE|MAP_ANONYMOUS|MAP_STACK, -1, 0) = 0x7f98d7621000
brk(NULL) = 0x1615000
brk(0x1636000) = 0x1636000
mprotect(0x7f98d7621000, 4096, PROT_NONE) = 0
clone(child_stack=0x7f98d7e20ff0, flags=CLONE_VM|CLONE_FS|CLONE_FILES|CLONE_SIGHAND|CLONE_THREAD|CLONE_SYSVSEM|CLONE_SETTLS|CLONE_PARENT_SETTID|CLONE_CHILD_CLEARTID, parent_tidptr=0x7f98d7e219d0, tls=0x7f98d7e21700, child_tidptr=0x7f98d7e219d0) = 4299
mmap(NULL, 8392704, PROT_READ|PROT_WRITE, MAP_PRIVATE|MAP_ANONYMOUS|MAP_STACK, -1, 0) = 0x7f98d6e20000
mprotect(0x7f98d6e20000, 4096, PROT_NONE) = 0
clone(child_stack=0x7f98d761fff0, flags=CLONE_VM|CLONE_FS|CLONE_FILES|CLONE_SIGHAND|CLONE_THREAD|CLONE_SYSVSEM|CLONE_SETTLS|CLONE_PARENT_SETTID|CLONE_CHILD_CLEARTID, parent_tidptr=0x7f98d76209d0, tls=0x7f98d7620700, child_tidptr=0x7f98d76209d0) = 4300
futex(0x7f98d7e219d0, FUTEX_WAIT, 4299, NULLstrace: Process 4300 attached
<unfinished ...>
[pid 4300] set_robust_list(0x7f98d76209e0, 24) = 0
[pid 4300] futex(0x601304, FUTEX_WAIT_PRIVATE, 1, NULLstrace: Process 4299 attached
<unfinished ...>
[pid 4299] set_robust_list(0x7f98d7e219e0, 24) = 0
[pid 4299] fstat(1, {st_mode=S_IFCHR|0620, st_rdev=makedev(136, 0), ...}) = 0
[pid 4299] mmap(NULL, 4096, PROT_READ|PROT_WRITE, MAP_PRIVATE|MAP_ANONYMOUS, -1, 0) = 0x7f98d8605000
[pid 4299] write(1, "This is pthread_1,the tpid is 42"..., 35This is pthread_1,the tpid is 4298
) = 35
[pid 4299] write(1, " This is pthread_1,the tpid is 4"..., 36 This is pthread_1,the tpid is 4298
) = 36
[pid 4299] write(1, " This is pthread_1,the tpid is 4"..., 36 This is pthread_1,the tpid is 4298
) = 36
[pid 4299] futex(0x601304, FUTEX_WAKE_OP_PRIVATE, 1, 1, 0x601300, FUTEX_OP_SET<<28|0<<12|FUTEX_OP_CMP_GT<<24|0x1) = 1
[pid 4299] madvise(0x7f98d7621000, 8368128, MADV_DONTNEED) = 0
[pid 4299] exit(0) = ?
[pid 4299] +++ exited with 0 +++
[pid 4298] <... futex resumed> ) = 0
[pid 4298] futex(0x7f98d76209d0, FUTEX_WAIT, 4300, NULL <unfinished ...>
[pid 4300] <... futex resumed> ) = 0
[pid 4300] write(1, " This is pthread_2.the tpid is 4"..., 36 This is pthread_2.the tpid is 4298
) = 36
[pid 4300] write(1, "This is pthread_2.the tpid is 42"..., 35This is pthread_2.the tpid is 4298
) = 35
[pid 4300] write(1, "This is pthread_2.the tpid is 42"..., 35This is pthread_2.the tpid is 4298
) = 35
[pid 4300] futex(0x6012c0, FUTEX_WAKE_PRIVATE, 1) = 0
[pid 4300] futex(0x601304, FUTEX_WAIT_PRIVATE, 3, NULL
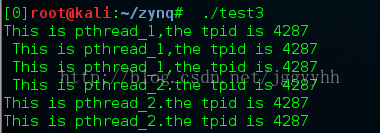
首先是shell呼叫execve執行命令指行程式,用brk(NULL)得到當前主執行緒的堆的開始(此時也是尾部)地址,接下來的一系列操作都是在把當前程序需要的動態連結庫通過mmap對映到主程式的mm_struct,讓主程式能夠定址到,這中間的手法就是不斷的open,read,然後通過state這個結構體獲得動態庫的長度,然後再mmap再close,這時的檔案操作符都是3,而且為了親屬執行緒能夠同時維護那部分地址,都採用anonymous模式進行mmap,用mmprotect設定記憶體保護模式,這時候主執行緒程該乾的事幹完了,就呼叫
set_tid_address()設定得到子執行緒的主執行緒的pid,然後呼叫
brk(NULL) = 0x1615000
brk(0x1636000) = 0x1636000
開闢新的堆空間,最後的clone呼叫是最經典的
clone(child_stack=0x7f98d7e20ff0, flags=CLONE_VM|CLONE_FS|CLONE_FILES|CLONE_SIGHAND|CLONE_THREAD|CLONE_SYSVSEM|CLONE_SETTLS|CLONE_PARENT_SETTID|CLONE_CHILD_CLEARTID, parent_tidptr=0x7f98d7e219d0, tls=0x7f98d7e21700, child_tidptr=0x7f98d7e219d0) = 4299這些選項說明了很多問題,這代表了子執行緒共享了主執行緒的VM虛擬地址意味著頁目錄那些一樣,FS也就是檔案系統,FILES開啟的檔案描述符也共享這個是linux能用管道這種牛逼操作的原因所在,就是因為子執行緒的這種共享,讓linux的shell煥發活力,clone函式還有個tls引數,這個引數來自於我之前所說的在GDT中的TLS執行緒描述符欄位,專門用來儲存該程序的子執行緒記憶體對映地址。
3.瞭解這些有啥用
首先,你對程式怎樣起來,怎樣被核心執行有了大致瞭解(限於篇幅我沒有敘述程序排程部分),然後你會理解一些東西:
1.單核CPU的多執行緒與多核的區別:
每一個程序都會被分配一個核心堆疊以及挨著的thread_info結構體但是對於每一個CPU(每個CPU單獨有一套暫存器也就是硬體上下文)只能作一個核心堆疊定址(通過esp找到它),只有在程序切換時,這個地址被核心控制路徑找到,很明顯在單核CPU程式設計根本不需要鎖的存在,因為無論何時只有一個執行流在CPU上執行,不會產生共享資源衝突,在單核CPU下的多執行緒是偽多執行緒,只是CPU依次處理各個程序被核心分配的時間片(800ms,400ms不等看優先順序之後有緣會寫),只需要注意一些編譯器優化問題,於是程式設計人員想到了用violate來限制編譯器優化一些衝突變數(因為編譯器有一些很邪惡的優化它會根據你這條指令的lantency也就是效率進行優化讀這種操作在多核處理器中讀是不會產生cache快取同步故往往編譯器會盡可能讓其提前讓寫滯後從而產生data race ),保持程式sc(sequential consistency),而這種violate也是之後被一些程式設計人員誤解的緣由,他們會感嘆這個東西怎麼不起作用了,這個必然的,多核CPU的並行程式設計是遠遠比這複雜的,有部分是因為編譯器的遺留問題,因為編譯器至今所做的優化是不會考慮多核情況,(聽說最近C++11有了方面的新特性),為了這個目的,不僅在程式設計上會設有各種記憶體避障以及鎖,這些東西在核心原始碼隨處可見:#define mb() alternative("lock; addl $0,0(%%esp)", "mfence", X86_FEATURE_XMM2)
#define rmb() alternative("lock; addl $0,0(%%esp)", "lfence", X86_FEATURE_XMM2)
#define wmb() alternative("lock; addl $0,0(%%esp)", "sfence", X86_FEATURE_XMM)2.對逆向更成熟於胸,而且加深了對shell的瞭解,且對bug定位有很大幫助:
比如說 ls | more這種操作,其實就是利用了兩個執行緒共享檔案描述符,由之前我的分析你應該能清楚ls開啟的檔案描述符應該是3,more是4,0是ls的輸入也是整個主執行緒的輸入,1 是輸出,那麼這個管道的作用就是把4這個檔案流給轉移到1,把3的檔案流轉移到0,這樣管道就形成了,而這樣形成的條件就是這兩個程序是兄弟程序和shell共享檔案描述符。而對逆向,當你對整個程式執行流了解過後,那麼思路會比較清晰。
相關推薦
從核心的角度看程序以及多執行緒
前言:就如我之前所說的一樣,程式只是一個被編譯器(包括彙編器以及聯結器)將你的抽象程式碼轉換為計算機能理解的有一定格式的二進位制檔案,它有一定格式(ELF,PE之類),就如之前的我所說的例子,就好比程式就如一段鐵軌,你是鐵路設計師,編譯器負責把鐵軌做好,那麼之後很多複雜
從jvm的角度來看java的多執行緒
最近在學習jvm,發現隨著對虛擬機器底層的瞭解,對java的多執行緒也有了全新的認識,原來一個小小的synchronized關鍵字裡別有洞天。決定把自己關於java多執行緒的所學整理成一篇文章,從最基礎的為什麼使用多執行緒,一直深入講解到jvm底層的鎖實現。 多執行緒的目的
一文看懂Python多程序與多執行緒程式設計(工作學習面試必讀)
程序(process)和執行緒(thread)是非常抽象的概念, 也是程式設計師必需掌握的核心知識。多程序和多執行緒程式設計對於程式碼的併發執行,提升程式碼效率和縮短執行時間至關重要。小編我今天就來嘗試下用一文總結下Python多程序和多執行緒的概念和區別, 並詳細介紹如何使
執行緒以及多執行緒,多程序的選擇
開發十年,就只剩下這套架構體系了! >>>
併發伺服器的實現(多程序、多執行緒...)
一、多程序實現併發伺服器 程式碼如下:multiprocess_server.c /* ============================================================================ Name : TCPServ
Linux程式設計 多程序,多執行緒求解PI(圓周率)
題目: 連結 多程序: #include <unistd.h> #include <stdio.h> #include <stdlib.h> #define n 100000000.0 int main() { i
Android核心技術-day05-04-JavaSE多執行緒下載
package com.gaozewen.lib; import java.io.BufferedReader; import java.io.File; import java.io.FileInputStream; import java.io.InputStream; import ja
spider ---- 程序&執行緒+++多程序&多執行緒
1案例演示: 程序-面向過程 import time from multiprocessing import Process def sing(): for x in range(1, 6): print('你在唱女兒情') time
DEVOPS-01多程序、多執行緒程式設計
一、多執行緒程式設計 1.1 forking工作原理 1.1.1 什麼是forking 1. fork(分岔)在Linux系統中使用非常廣泛 2. 當某一命令執行時,父程序(當前程序)fork出一個子程序 3. 父程序將自身資源拷貝一份,命令在子程序中執行時,就具
【Linux】多程序與多執行緒之間的區別
http://blog.csdn.net/byrsongqq/article/details/6339240 網路程式設計中設計併發伺服器,使用多程序與多執行緒 ,請問有什麼區別? 答案一: 1,程序:子程序是父程序的複製品。子程序獲得父程序資料空間、堆和棧的複製品。 2,執行緒:相
多執行緒——從生活中理解什麼是多執行緒
每一個程式可以包含至少一個執行緒,而多個執行緒之間可以“併發”執行。 在介紹執行緒前先來用生活中最常見的一個小例子來理解什麼是執行緒: &nbs
多程序和多執行緒的優缺點
在Linux下程式設計多用多程序程式設計少用多執行緒程式設計。 IBM有個傢伙做了個測試,發現切換執行緒context的時候,windows比linux快一倍多。進出最快的鎖(windows2k的
關於程序,執行緒,多程序和多執行緒的網路程式設計
程序執行緒網路 多工程式設計 : 可以有效的利用計算機資源,同時執行多個任務 程序 : 程序就是程式在計算機中一次執行的過程 程序和程式的區別: 程式是一個靜態檔案的描述,不佔計算機的系統資源 程序是一個動態的過程,佔有cpu記憶體等資源,有一定的生命週期 * 同一個程式的不同執行過程即為不同的程序
Python之——Python中的多程序和多執行緒
轉載請註明出處:https://blog.csdn.net/l1028386804/article/details/83042246 一、多程序 Python實現對程序的方式主要有兩種,一種方法是使用os模組中的fork方法,另一種方法是使用multiprocessing模組。區別在於:
Linux多程序和多執行緒的優缺點
教科書上最經典的一句話是“程序是作業系統分配的最小單位,執行緒是CPU排程的最小單位”。 多執行緒的優點: 1)它是一種非常”節儉”的多工操作方式。在Linux系統下,啟動一個新的程序必須分配給它獨立的地址空間,建立眾多的資料表來維護它的程式碼段、堆疊段和資料段,這是一種”昂貴”
多程序,多執行緒
一個程序可以多執行緒,但是多執行緒就像是十字路,一個執行緒掛了,如果對多執行緒的共享堆、全域性變數等非棧記憶體造成了影響,那麼它所屬的程序就掛了。 而多程序則像是立交橋,互不想幹。一個程序掛了不會導致整個程式崩潰。所以在想要保證 程式的可用性(不會動不動就堵塞)是可以使用多程序,也可以保證主程序的穩定,比
gdb 除錯多程序、多執行緒的小栗子
gdb除錯中多執行緒是一個難點,涉及到諸多執行緒的相互影響。對於多執行緒之間的相互影響,這個不在這個小栗子的闡述範圍內。這是除錯一個簡單的子程序中的子執行緒的小栗子。 使用材料 /*這是一個演示gdb除錯子程序、子執行緒的檔案 */ #include <stdio.h>
CPU如何執行程序、多執行緒,他們之間的關係是怎樣的
好文章分享,轉自:https://www.cnblogs.com/csfeng/p/8670704.html 當面臨這些問題的時候,有兩個關鍵詞無法繞開,那就是並行和併發。 首先,要先了解幾個概念: 1、程序是程式的一次執行。 2、程序是資源分配的基本單位(
socket伺服器程式設計的多程序,多執行緒實現
socket伺服器程式設計: 顧名思義就是使用socket套接字來編寫伺服器程式的過程。不熟悉socket程式設計的小夥伴可以看我之前的文章,但是當時所實現的功能伺服器同時只能和一個客戶端進行互動,效率太低,利用多程序或者多執行緒方式來實現伺服器可以做到同時和多個客戶端進行互動。提高伺服器的效能
linux多程序和多執行緒
轉載自CodeUniverse的部落格 程序:可執行程式是儲存在磁碟裝置上的由程式碼和資料按某種格式組織的靜態實體,而程序是可被排程的程式碼的動態執行。 在Linux系統中,每個程序都有各自的生命週期。在一個程序的生命週期中,都有各自的執行環境以及所需的資源,這些資訊都記錄在各自的程序控制塊中,以便系統對