
Hadoop之多行讀取資料
一,需求:
在map執行前,即setInputFormatClass過程,會進行資料的讀入,預設的是每次讀入一行資料,進行計算。現在需要改成每次讀入兩行資料並且合併結果輸出。
二,思路及解決方法:
建議先看看他們的原始碼,理解思路。
我這裡是採用的TextInputFormat.class的輸入格式。它的key是每一行的偏移位置,value就是它這一行的內容。其中有建立LineRecordReader類,它就是用來讀取資料的封裝類,我們需要重寫它。
在LineRecordReader類中,觀察出其nextKeyValue()方法中,有涉及到讀取資料的方法,readLine(),在這個readLine()方法之前加個boolean值,用來控制後面不會將已經讀到了的資料清空,然後再加個for迴圈用來做多次讀取。再把這個傳到readLine()中重寫這個方法。
這事又需要重寫它的父類LineReader,在LineRecordReader中是呼叫的SplitLineReader類,它是繼承的LineReader類,還需要重寫其他兩個類,UncompressedSplitLineReader和CompressedSplitLineReader這兩個類好像是用來做壓縮的,不用管直接複製就行。
回到LineReader類,我們需要過載他的readLine()方法增加了一個boolean的引數。並將引數傳到過載的readCustomLine()和readDefaultLine()在這個兩個方法中只需利用boolean值,對資料清除進行判斷,其他程式碼複製即可。
下面一個簡圖展示這個過程:
1,輸入的資料:
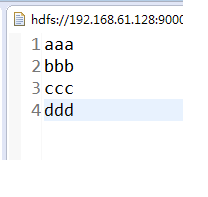
2,結果:
原始碼展示:
,1, 測試類
import java.io.IOException; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.Path; import org.apache.hadoop.io.LongWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Job; import org.apache.hadoop.mapreduce.Mapper; import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; public class TestUserInputFormat { public static class UserMapper extends Mapper<LongWritable,Text, LongWritable, Text>{ protected void map(LongWritable key, Text value, Mapper<LongWritable, Text, LongWritable, Text>.Context context) throws IOException, InterruptedException { context.write(key, value); } } public static void main(String[] args) { try { Configuration conf=new Configuration(); Job job=Job.getInstance(conf,"Test lineRecordReader"); job.setJarByClass(TestUserInputFormat.class); job.setInputFormatClass(TextInputFormat.class); job.setMapperClass(UserMapper.class); job.setOutputKeyClass(LongWritable.class); job.setOutputValueClass(Text.class); FileInputFormat.addInputPath(job, new Path("hdfs://192.168.61.128:9000/inline/")); FileOutputFormat.setOutputPath(job, new Path("hdfs://192.168.61.128:9000/outline/"+System.currentTimeMillis()+"/")); System.exit(job.waitForCompletion(true) ? 0 : 1); } catch (IllegalStateException e) { e.printStackTrace(); } catch (IllegalArgumentException e) { e.printStackTrace(); } catch (ClassNotFoundException e) { e.printStackTrace(); } catch (IOException e) { e.printStackTrace(); } catch (InterruptedException e) { e.printStackTrace(); } } }
2,輸入格式類
import org.apache.hadoop.classification.InterfaceAudience; import org.apache.hadoop.classification.InterfaceStability; import org.apache.hadoop.fs.Path; import org.apache.hadoop.io.LongWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.io.compress.CompressionCodec; import org.apache.hadoop.io.compress.CompressionCodecFactory; import org.apache.hadoop.io.compress.SplittableCompressionCodec; import org.apache.hadoop.mapreduce.InputFormat; import org.apache.hadoop.mapreduce.InputSplit; import org.apache.hadoop.mapreduce.JobContext; import org.apache.hadoop.mapreduce.RecordReader; import org.apache.hadoop.mapreduce.TaskAttemptContext; import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; import com.google.common.base.Charsets; /** An {@link InputFormat} for plain text files. Files are broken into lines. * Either linefeed or carriage-return are used to signal end of line. Keys are * the position in the file, and values are the line of text.. */ @InterfaceAudience.Public @InterfaceStability.Stable public class TextInputFormat extends FileInputFormat<LongWritable, Text> { @Override public RecordReader<LongWritable, Text> createRecordReader(InputSplit split, TaskAttemptContext context) { String delimiter = context.getConfiguration().get( "textinputformat.record.delimiter"); byte[] recordDelimiterBytes = null; if (null != delimiter) recordDelimiterBytes = delimiter.getBytes(Charsets.UTF_8); return new LineRecordReader(recordDelimiterBytes); } @Override protected boolean isSplitable(JobContext context, Path file) { final CompressionCodec codec = new CompressionCodecFactory(context.getConfiguration()).getCodec(file); if (null == codec) { return true; } return codec instanceof SplittableCompressionCodec; } }
3,讀取資料類:
import java.io.IOException;
import org.apache.hadoop.classification.InterfaceAudience;
import org.apache.hadoop.classification.InterfaceStability;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FSDataInputStream;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.fs.Seekable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.io.compress.CodecPool;
import org.apache.hadoop.io.compress.CompressionCodec;
import org.apache.hadoop.io.compress.SplitCompressionInputStream;
import org.apache.hadoop.io.compress.SplittableCompressionCodec;
import org.apache.hadoop.io.compress.CompressionCodecFactory;
import org.apache.hadoop.io.compress.Decompressor;
import org.apache.hadoop.mapreduce.InputSplit;
import org.apache.hadoop.mapreduce.RecordReader;
import org.apache.hadoop.mapreduce.TaskAttemptContext;
import org.apache.hadoop.mapreduce.lib.input.FileSplit;
import org.apache.commons.logging.LogFactory;
import org.apache.commons.logging.Log;
/**
* Treats keys as offset in file and value as line.
*/
@InterfaceAudience.LimitedPrivate({"MapReduce", "Pig"})
@InterfaceStability.Evolving
public class LineRecordReader extends RecordReader<LongWritable, Text> {
private static final Log LOG = LogFactory.getLog(LineRecordReader.class);
public static final String MAX_LINE_LENGTH =
"mapreduce.input.linerecordreader.line.maxlength";
private long start;
private long pos;
private long end;
private SplitLineReader in;
private FSDataInputStream fileIn;
private Seekable filePosition;
private int maxLineLength;
private LongWritable key;
private Text value;
private boolean isCompressedInput;
private Decompressor decompressor;
private byte[] recordDelimiterBytes;
public LineRecordReader() {
}
public LineRecordReader(byte[] recordDelimiter) {
this.recordDelimiterBytes = recordDelimiter;
}
public void initialize(InputSplit genericSplit,
TaskAttemptContext context) throws IOException {
FileSplit split = (FileSplit) genericSplit;
Configuration job = context.getConfiguration();
this.maxLineLength = job.getInt(MAX_LINE_LENGTH, Integer.MAX_VALUE);
start = split.getStart();
end = start + split.getLength();
final Path file = split.getPath();
// open the file and seek to the start of the split
final FileSystem fs = file.getFileSystem(job);
fileIn = fs.open(file);
CompressionCodec codec = new CompressionCodecFactory(job).getCodec(file);
if (null!=codec) {
isCompressedInput = true;
decompressor = CodecPool.getDecompressor(codec);
if (codec instanceof SplittableCompressionCodec) {
final SplitCompressionInputStream cIn =
((SplittableCompressionCodec)codec).createInputStream(
fileIn, decompressor, start, end,
SplittableCompressionCodec.READ_MODE.BYBLOCK);
in = new CompressedSplitLineReader(cIn, job,
this.recordDelimiterBytes);
start = cIn.getAdjustedStart();
end = cIn.getAdjustedEnd();
filePosition = cIn;
} else {
in = new SplitLineReader(codec.createInputStream(fileIn,
decompressor), job, this.recordDelimiterBytes);
filePosition = fileIn;
}
} else {
fileIn.seek(start);
in = new UncompressedSplitLineReader(
fileIn, job, this.recordDelimiterBytes, split.getLength());
filePosition = fileIn;
}
// If this is not the first split, we always throw away first record
// because we always (except the last split) read one extra line in
// next() method.
if (start != 0) {
start += in.readLine(new Text(), 0, maxBytesToConsume(start));
}
this.pos = start;
}
private int maxBytesToConsume(long pos) {
return isCompressedInput
? Integer.MAX_VALUE
: (int) Math.max(Math.min(Integer.MAX_VALUE, end - pos), maxLineLength);
}
private long getFilePosition() throws IOException {
long retVal;
if (isCompressedInput && null != filePosition) {
retVal = filePosition.getPos();
} else {
retVal = pos;
}
return retVal;
}
private int skipUtfByteOrderMark() throws IOException {
// Strip BOM(Byte Order Mark)
// Text only support UTF-8, we only need to check UTF-8 BOM
// (0xEF,0xBB,0xBF) at the start of the text stream.
int newMaxLineLength = (int) Math.min(3L + (long) maxLineLength,
Integer.MAX_VALUE);
int newSize = in.readLine(value, newMaxLineLength, maxBytesToConsume(pos));
// Even we read 3 extra bytes for the first line,
// we won't alter existing behavior (no backwards incompat issue).
// Because the newSize is less than maxLineLength and
// the number of bytes copied to Text is always no more than newSize.
// If the return size from readLine is not less than maxLineLength,
// we will discard the current line and read the next line.
pos += newSize;
int textLength = value.getLength();
byte[] textBytes = value.getBytes();
if ((textLength >= 3) && (textBytes[0] == (byte)0xEF) &&
(textBytes[1] == (byte)0xBB) && (textBytes[2] == (byte)0xBF)) {
// find UTF-8 BOM, strip it.
LOG.info("Found UTF-8 BOM and skipped it");
textLength -= 3;
newSize -= 3;
if (textLength > 0) {
// It may work to use the same buffer and not do the copyBytes
textBytes = value.copyBytes();
value.set(textBytes, 3, textLength);
} else {
value.clear();
}
}
return newSize;
}
public boolean nextKeyValue() throws IOException {
if (key == null) {
key = new LongWritable();
}
key.set(pos);
if (value == null) {
value = new Text();
}
int newSize = 0;
// We always read one extra line, which lies outside the upper
// split limit i.e. (end - 1)
boolean flag=true;
for(int i=1;i<=2;i++){
if(i==2){
flag=false;
}
while (getFilePosition() <= end || in.needAdditionalRecordAfterSplit()) {
if (pos == 0) {
newSize = skipUtfByteOrderMark();
} else {
newSize = in.readLine(value, maxLineLength, maxBytesToConsume(pos),flag);
pos += newSize;
}
if ((newSize == 0) || (newSize < maxLineLength)) {
break;
}
// line too long. try again
LOG.info("Skipped line of size " + newSize + " at pos " +
(pos - newSize));
}
}
if (newSize == 0) {
key = null;
value = null;
return false;
} else {
return true;
}
}
@Override
public LongWritable getCurrentKey() {
return key;
}
@Override
public Text getCurrentValue() {
return value;
}
/**
* Get the progress within the split
*/
public float getProgress() throws IOException {
if (start == end) {
return 0.0f;
} else {
return Math.min(1.0f, (getFilePosition() - start) / (float)(end - start));
}
}
public synchronized void close() throws IOException {
try {
if (in != null) {
in.close();
}
} finally {
if (decompressor != null) {
CodecPool.returnDecompressor(decompressor);
}
}
}
}
4,讀取資料的父類LineReader:
import java.io.Closeable;
import java.io.IOException;
import java.io.InputStream;
import org.apache.hadoop.classification.InterfaceAudience;
import org.apache.hadoop.classification.InterfaceStability;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.io.Text;
/**
* A class that provides a line reader from an input stream.
* Depending on the constructor used, lines will either be terminated by:
* <ul>
* <li>one of the following: '\n' (LF) , '\r' (CR),
* or '\r\n' (CR+LF).</li>
* <li><em>or</em>, a custom byte sequence delimiter</li>
* </ul>
* In both cases, EOF also terminates an otherwise unterminated
* line.
*/
@InterfaceAudience.LimitedPrivate({"MapReduce"})
@InterfaceStability.Unstable
public class LineReader implements Closeable {
private static final int DEFAULT_BUFFER_SIZE = 64 * 1024;
private int bufferSize = DEFAULT_BUFFER_SIZE;
private InputStream in;
private byte[] buffer;
// the number of bytes of real data in the buffer
private int bufferLength = 0;
// the current position in the buffer
private int bufferPosn = 0;
private static final byte CR = '\r';
private static final byte LF = '\n';
// The line delimiter
private final byte[] recordDelimiterBytes;
/**
* Create a line reader that reads from the given stream using the
* default buffer-size (64k).
* @param in The input stream
* @throws IOException
*/
public LineReader(InputStream in) {
this(in, DEFAULT_BUFFER_SIZE);
}
/**
* Create a line reader that reads from the given stream using the
* given buffer-size.
* @param in The input stream
* @param bufferSize Size of the read buffer
* @throws IOException
*/
public LineReader(InputStream in, int bufferSize) {
this.in = in;
this.bufferSize = bufferSize;
this.buffer = new byte[this.bufferSize];
this.recordDelimiterBytes = null;
}
/**
* Create a line reader that reads from the given stream using the
* <code>io.file.buffer.size</code> specified in the given
* <code>Configuration</code>.
* @param in input stream
* @param conf configuration
* @throws IOException
*/
public LineReader(InputStream in, Configuration conf) throws IOException {
this(in, conf.getInt("io.file.buffer.size", DEFAULT_BUFFER_SIZE));
}
/**
* Create a line reader that reads from the given stream using the
* default buffer-size, and using a custom delimiter of array of
* bytes.
* @param in The input stream
* @param recordDelimiterBytes The delimiter
*/
public LineReader(InputStream in, byte[] recordDelimiterBytes) {
this.in = in;
this.bufferSize = DEFAULT_BUFFER_SIZE;
this.buffer = new byte[this.bufferSize];
this.recordDelimiterBytes = recordDelimiterBytes;
}
/**
* Create a line reader that reads from the given stream using the
* given buffer-size, and using a custom delimiter of array of
* bytes.
* @param in The input stream
* @param bufferSize Size of the read buffer
* @param recordDelimiterBytes The delimiter
* @throws IOException
*/
public LineReader(InputStream in, int bufferSize,
byte[] recordDelimiterBytes) {
this.in = in;
this.bufferSize = bufferSize;
this.buffer = new byte[this.bufferSize];
this.recordDelimiterBytes = recordDelimiterBytes;
}
/**
* Create a line reader that reads from the given stream using the
* <code>io.file.buffer.size</code> specified in the given
* <code>Configuration</code>, and using a custom delimiter of array of
* bytes.
* @param in input stream
* @param conf configuration
* @param recordDelimiterBytes The delimiter
* @throws IOException
*/
public LineReader(InputStream in, Configuration conf,
byte[] recordDelimiterBytes) throws IOException {
this.in = in;
this.bufferSize = conf.getInt("io.file.buffer.size", DEFAULT_BUFFER_SIZE);
this.buffer = new byte[this.bufferSize];
this.recordDelimiterBytes = recordDelimiterBytes;
}
/**
* Close the underlying stream.
* @throws IOException
*/
public void close() throws IOException {
in.close();
}
/**
* Read one line from the InputStream into the given Text.
*
* @param str the object to store the given line (without newline)
* @param maxLineLength the maximum number of bytes to store into str;
* the rest of the line is silently discarded.
* @param maxBytesToConsume the maximum number of bytes to consume
* in this call. This is only a hint, because if the line cross
* this threshold, we allow it to happen. It can overshoot
* potentially by as much as one buffer length.
*
* @return the number of bytes read including the (longest) newline
* found.
*
* @throws IOException if the underlying stream throws
*/
public int readLine(Text str, int maxLineLength,
int maxBytesToConsume) throws IOException {
if (this.recordDelimiterBytes != null) {
return readCustomLine(str, maxLineLength, maxBytesToConsume);
} else {
return readDefaultLine(str, maxLineLength, maxBytesToConsume);
}
}
public int readLine(Text str, int maxLineLength,
int maxBytesToConsume,boolean flag) throws IOException {
if (this.recordDelimiterBytes != null) {
return readCustomLine(str, maxLineLength, maxBytesToConsume,flag);
} else {
return readDefaultLine(str, maxLineLength, maxBytesToConsume,flag);
}
}
protected int fillBuffer(InputStream in, byte[] buffer, boolean inDelimiter)
throws IOException {
return in.read(buffer);
}
/**
* Read a line terminated by one of CR, LF, or CRLF.
*/
private int readDefaultLine(Text str, int maxLineLength, int maxBytesToConsume)
throws IOException {
/* We're reading data from in, but the head of the stream may be
* already buffered in buffer, so we have several cases:
* 1. No newline characters are in the buffer, so we need to copy
* everything and read another buffer from the stream.
* 2. An unambiguously terminated line is in buffer, so we just
* copy to str.
* 3. Ambiguously terminated line is in buffer, i.e. buffer ends
* in CR. In this case we copy everything up to CR to str, but
* we also need to see what follows CR: if it's LF, then we
* need consume LF as well, so next call to readLine will read
* from after that.
* We use a flag prevCharCR to signal if previous character was CR
* and, if it happens to be at the end of the buffer, delay
* consuming it until we have a chance to look at the char that
* follows.
*/
str.clear();
int txtLength = 0; //tracks str.getLength(), as an optimization
int newlineLength = 0; //length of terminating newline
boolean prevCharCR = false; //true of prev char was CR
long bytesConsumed = 0;
do {
int startPosn = bufferPosn; //starting from where we left off the last time
if (bufferPosn >= bufferLength) {
startPosn = bufferPosn = 0;
if (prevCharCR) {
++bytesConsumed; //account for CR from previous read
}
bufferLength = fillBuffer(in, buffer, prevCharCR);
if (bufferLength <= 0) {
break; // EOF
}
}
for (; bufferPosn < bufferLength; ++bufferPosn) { //search for newline
if (buffer[bufferPosn] == LF) {
newlineLength = (prevCharCR) ? 2 : 1;
++bufferPosn; // at next invocation proceed from following byte
break;
}
if (prevCharCR) { //CR + notLF, we are at notLF
newlineLength = 1;
break;
}
prevCharCR = (buffer[bufferPosn] == CR);
}
int readLength = bufferPosn - startPosn;
if (prevCharCR && newlineLength == 0) {
--readLength; //CR at the end of the buffer
}
bytesConsumed += readLength;
int appendLength = readLength - newlineLength;
if (appendLength > maxLineLength - txtLength) {
appendLength = maxLineLength - txtLength;
}
if (appendLength > 0) {
str.append(buffer, startPosn, appendLength);
txtLength += appendLength;
}
} while (newlineLength == 0 && bytesConsumed < maxBytesToConsume);
if (bytesConsumed > Integer.MAX_VALUE) {
throw new IOException("Too many bytes before newline: " + bytesConsumed);
}
return (int)bytesConsumed;
}
private int readDefaultLine(Text str, int maxLineLength, int maxBytesToConsume,boolean flag)
throws IOException {
/* We're reading data from in, but the head of the stream may be
* already buffered in buffer, so we have several cases:
* 1. No newline characters are in the buffer, so we need to copy
* everything and read another buffer from the stream.
* 2. An unambiguously terminated line is in buffer, so we just
* copy to str.
* 3. Ambiguously terminated line is in buffer, i.e. buffer ends
* in CR. In this case we copy everything up to CR to str, but
* we also need to see what follows CR: if it's LF, then we
* need consume LF as well, so next call to readLine will read
* from after that.
* We use a flag prevCharCR to signal if previous character was CR
* and, if it happens to be at the end of the buffer, delay
* consuming it until we have a chance to look at the char that
* follows.
*/
if(flag){
str.clear();
}
int txtLength = 0; //tracks str.getLength(), as an optimization
int newlineLength = 0; //length of terminating newline
boolean prevCharCR = false; //true of prev char was CR
long bytesConsumed = 0;
do {
int startPosn = bufferPosn; //starting from where we left off the last time
if (bufferPosn >= bufferLength) {
startPosn = bufferPosn = 0;
if (prevCharCR) {
++bytesConsumed; //account for CR from previous read
}
bufferLength = fillBuffer(in, buffer, prevCharCR);
if (bufferLength <= 0) {
break; // EOF
}
}
for (; bufferPosn < bufferLength; ++bufferPosn) { //search for newline
if (buffer[bufferPosn] == LF) {
newlineLength = (prevCharCR) ? 2 : 1;
++bufferPosn; // at next invocation proceed from following byte
break;
}
if (prevCharCR) { //CR + notLF, we are at notLF
newlineLength = 1;
break;
}
prevCharCR = (buffer[bufferPosn] == CR);
}
int readLength = bufferPosn - startPosn;
if (prevCharCR && newlineLength == 0) {
--readLength; //CR at the end of the buffer
}
bytesConsumed += readLength;
int appendLength = readLength - newlineLength;
if (appendLength > maxLineLength - txtLength) {
appendLength = maxLineLength - txtLength;
}
if (appendLength > 0) {
str.append(buffer, startPosn, appendLength);
txtLength += appendLength;
}
} while (newlineLength == 0 && bytesConsumed < maxBytesToConsume);
if (bytesConsumed > Integer.MAX_VALUE) {
throw new IOException("Too many bytes before newline: " + bytesConsumed);
}
return (int)bytesConsumed;
}
private int readCustomLine(Text str, int maxLineLength, int maxBytesToConsume,boolean flag)
throws IOException {
/* We're reading data from inputStream, but the head of the stream may be
* already captured in the previous buffer, so we have several cases:
*
* 1. The buffer tail does not contain any character sequence which
* matches with the head of delimiter. We count it as a
* ambiguous byte count = 0
*
* 2. The buffer tail contains a X number of characters,
* that forms a sequence, which matches with the
* head of delimiter. We count ambiguous byte count = X
*
* // *** eg: A segment of input file is as follows
*
* " record 1792: I found this bug very interesting and
* I have completely read about it. record 1793: This bug
* can be solved easily record 1794: This ."
*
* delimiter = "record";
*
* supposing:- String at the end of buffer =
* "I found this bug very interesting and I have completely re"
* There for next buffer = "ad about it. record 179 ...."
*
* The matching characters in the input
* buffer tail and delimiter head = "re"
* Therefore, ambiguous byte count = 2 **** //
*
* 2.1 If the following bytes are the remaining characters of
* the delimiter, then we have to capture only up to the starting
* position of delimiter. That means, we need not include the
* ambiguous characters in str.
*
* 2.2 If the following bytes are not the remaining characters of
* the delimiter ( as mentioned in the example ),
* then we have to include the ambiguous characters in str.
*/
if(flag){
str.clear();
}
int txtLength = 0; // tracks str.getLength(), as an optimization
long bytesConsumed = 0;
int delPosn = 0;
int ambiguousByteCount=0; // To capture the ambiguous characters count
do {
int startPosn = bufferPosn; // Start from previous end position
if (bufferPosn >= bufferLength) {
startPosn = bufferPosn = 0;
bufferLength = fillBuffer(in, buffer, ambiguousByteCount > 0);
if (bufferLength <= 0) {
if (ambiguousByteCount > 0) {
str.append(recordDelimiterBytes, 0, ambiguousByteCount);
bytesConsumed += ambiguousByteCount;
}
break; // EOF
}
}
for (; bufferPosn < bufferLength; ++bufferPosn) {
if (buffer[bufferPosn] == recordDelimiterBytes[delPosn]) {
delPosn++;
if (delPosn >= recordDelimiterBytes.length) {
bufferPosn++;
break;
}
} else if (delPosn != 0) {
bufferPosn--;
delPosn = 0;
}
}
int readLength = bufferPosn - startPosn;
bytesConsumed += readLength;
int appendLength = readLength - delPosn;
if (appendLength > maxLineLength - txtLength) {
appendLength = maxLineLength - txtLength;
}
bytesConsumed += ambiguousByteCount;
if (appendLength >= 0 && ambiguousByteCount > 0) {
//appending the ambiguous characters (refer case 2.2)
str.append(recordDelimiterBytes, 0, ambiguousByteCount);
ambiguousByteCount = 0;
// since it is now certain that the split did not split a delimiter we
// should not read the next record: clear the flag otherwise duplicate
// records could be generated
unsetNeedAdditionalRecordAfterSplit();
}
if (appendLength > 0) {
str.append(buffer, startPosn, appendLength);
txtLength += appendLength;
}
if (bufferPosn >= bufferLength) {
if (delPosn > 0 && delPosn < recordDelimiterBytes.length) {
ambiguousByteCount = delPosn;
bytesConsumed -= ambiguousByteCount; //to be consumed in next
}
}
} while (delPosn < recordDelimiterBytes.length
&& bytesConsumed < maxBytesToConsume);
if (bytesConsumed > Integer.MAX_VALUE) {
throw new IOException("Too many bytes before delimiter: " + bytesConsumed);
}
return (int) bytesConsumed;
}
/**
* Read a line terminated by a custom delimiter.
*/
private int readCustomLine(Text str, int maxLineLength, int maxBytesToConsume)
throws IOException {
/* We're reading data from inputStream, but the head of the stream may be
* already captured in the previous buffer, so we have several cases:
*
* 1. The buffer tail does not contain any character sequence which
* matches with the head of delimiter. We count it as a
* ambiguous byte count = 0
*
* 2. The buffer tail contains a X number of characters,
* that forms a sequence, which matches with the
* head of delimiter. We count ambiguous byte count = X
*
* // *** eg: A segment of input file is as follows
*
* " record 1792: I found this bug very interesting and
* I have completely read about it. record 1793: This bug
* can be solved easily record 1794: This ."
*
* delimiter = "record";
*
* supposing:- String at the end of buffer =
* "I found this bug very interesting and I have completely re"
* There for next buffer = "ad about it. record 179 ...."
*
* The matching characters in the input
* buffer tail and delimiter head = "re"
* Therefore, ambiguous byte count = 2 **** //
*
* 2.1 If the following bytes are the remaining characters of
* the delimiter, then we have to capture only up to the starting
* position of delimiter. That means, we need not include the
* ambiguous characters in str.
*
* 2.2 If the following bytes are not the remaining characters of
* the delimiter ( as mentioned in the example ),
* then we have to include the ambiguous characters in str.
*/
str.clear();
int txtLength = 0; // tracks str.getLength(), as an optimization
long bytesConsumed = 0;
int delPosn = 0;
int ambiguousByteCount=0; // To capture the ambiguous characters count
do {
int startPosn = bufferPosn; // Start from previous end position
if (bufferPosn >= bufferLength) {
startPosn = bufferPosn = 0;
bufferLength = fillBuffer(in, buffer, ambiguousByteCount > 0);
if (bufferLength <= 0) {
if (ambiguousByteCount > 0) {
str.append(recordDelimiterBytes, 0, ambiguousByteCount);
bytesConsumed += ambiguousByteCount;
}
break; // EOF
}
}
for (; bufferPosn < bufferLength; ++bufferPosn) {
if (buffer[bufferPosn] == recordDelimiterBytes[delPosn]) {
delPosn++;
if (delPosn >= recordDelimiterBytes.length) {
bufferPosn++;
break;
}
} else if (delPosn != 0) {
bufferPosn--;
delPosn = 0;
}
}
int readLength = bufferPosn - startPosn;
bytesConsumed += readLength;
int appendLength = readLength - delPosn;
if (appendLength > maxLineLength - txtLength) {
appendLength = maxLineLength - txtLength;
}
bytesConsumed += ambiguousByteCount;
if (appendLength >= 0 && ambiguousByteCount > 0) {
//appending the ambiguous characters (refer case 2.2)
str.append(recordDelimiterBytes, 0, ambiguousByteCount);
ambiguousByteCount = 0;
// since it is now certain that the split did not split a delimiter we
// should not read the next record: clear the flag otherwise duplicate
// records could be generated
unsetNeedAdditionalRecordAfterSplit();
}
if (appendLength > 0) {
str.append(buffer, startPosn, appendLength);
txtLength += appendLength;
}
if (bufferPosn >= bufferLength) {
if (delPosn > 0 && delPosn < recordDelimiterBytes.length) {
ambiguousByteCount = delPosn;
bytesConsumed -= ambiguousByteCount; //to be consumed in next
}
}
} while (delPosn < recordDelimiterBytes.length
&& bytesConsumed < maxBytesToConsume);
if (bytesConsumed > Integer.MAX_VALUE) {
throw new IOException("Too many bytes before delimiter: " + bytesConsumed);
}
return (int) bytesConsumed;
}
/**
* Read from the InputStream into the given Text.
* @param str the object to store the given line
* @param maxLineLength the maximum number of bytes to store into str.
* @return the number of bytes read including the newline
* @throws IOException if the underlying stream throws
*/
public int readLine(Text str, int maxLineLength) throws IOException {
return readLine(str, maxLineLength, Integer.MAX_VALUE);
}
/**
* Read from the InputStream into the given Text.
* @param str the object to store the given line
* @return the number of bytes read including the newline
* @throws IOException if the underlying stream throws
*/
public int readLine(Text str) throws IOException {
return readLine(str, Integer.MAX_VALUE, Integer.MAX_VALUE);
}
protected int getBufferPosn() {
return bufferPosn;
}
protected int getBufferSize() {
return bufferSize;
}
protected void unsetNeedAdditionalRecordAfterSplit() {
// needed for custom multi byte line delimiters only
// see MAPREDUCE-6549 for details
}
}
5,幾個打醬油的類:
import java.io.IOException;
import java.io.InputStream;
import org.apache.hadoop.classification.InterfaceAudience;
import org.apache.hadoop.classification.InterfaceStability;
import org.apache.hadoop.conf.Configuration;
@InterfaceAudience.Private
@InterfaceStability.Unstable
public class SplitLineReader extends LineReader {
public SplitLineReader(InputStream in, byte[] recordDelimiterBytes) {
super(in, recordDelimiterBytes);
}
public SplitLineReader(InputStream in, Configuration conf,
byte[] recordDelimiterBytes) throws IOException {
super(in, conf, recordDelimiterBytes);
}
public boolean needAdditionalRecordAfterSplit() {
return false;
}
}
import java.io.IOException;
import java.io.InputStream;
import org.apache.hadoop.classification.InterfaceAudience;
import org.apache.hadoop.classification.InterfaceStability;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.io.compress.SplitCompressionInputStream;
/**
* Line reader for compressed splits
*
* Reading records from a compressed split is tricky, as the
* LineRecordReader is using the reported compressed input stream
* position directly to determine when a split has ended. In addition the
* compressed input stream is usually faking the actual byte position, often
* updating it only after the first compressed block after the split is
* accessed.
*
* Depending upon where the last compressed block of the split ends relative
* to the record delimiters it can be easy to accidentally drop the last
* record or duplicate the last record between this split and the next.
*
* Split end scenarios:
*
* 1) Last block of split ends in the middle of a record
* Nothing special that needs to be done here, since the compressed input
* stream will report a position after the split end once the record
* is fully read. The consumer of the next split will discard the
* partial record at the start of the split normally, and no data is lost
* or duplicated between the splits.
*
* 2) Last block of split ends in the middle of a delimiter
* The line reader will continue to consume bytes into the next block to
* locate the end of the delimiter. If a custom delimiter is being used
* then the next record must be read by this split or it will be dropped.
* The consumer of the next split will not recognize the partial
* delimiter at the beginning of its split and will discard it along with
* the next record.
*
* However for the default delimiter processing there is a special case
* because CR, LF, and CRLF are all valid record delimiters. If the
* block ends with a CR then the reader must peek at the next byte to see
* if it is an LF and therefore part of the same record delimiter.
* Peeking at the next byte is an access to the next block and triggers
* the stream to report the end of the split. There are two cases based
* on the next byte:
*
* A) The next byte is LF
* The split needs to end after the current record is returned. The
* consumer of the next split will discard the first record, which
* is degenerate since LF is itself a delimiter, and start consuming
* records after that byte. If the current split tries to read
* another record then the record will be duplicated between splits.
*
* B) The next byte is not LF
* The current record will be returned but the stream will report
* the split has ended due to the peek into the next block. If the
* next record is not read then it will be lost, as the consumer of
* the next split will discard it before processing subsequent
* records. Therefore the next record beyond the reported split end
* must be consumed by this split to avoid data loss.
*
* 3) Last block of split ends at the beginning of a delimiter
* This is equivalent to case 1, as the reader will consume bytes into
* the next block and trigger the end of the split. No further records
* should be read as the consumer of the next split will discard the
* (degenerate) record at the beginning of its split.
*
* 4) Last block of split ends at the end of a delimiter
* Nothing special needs to be done here. The reader will not start
* examining the bytes into the next block until the next record is read,
* so the stream will not report the end of the split just yet. Once the
* next record is read then the next block will be accessed and the
* stream will indicate the end of the split. The consumer of the next
* split will correctly discard the first record of its split, and no
* data is lost or duplicated.
*
* If the default delimiter is used and the block ends at a CR then this
* is treated as case 2 since the reader does not yet know without
* looking at subsequent bytes whether the delimiter has ended.
*
* NOTE: It is assumed that compressed input streams *never* return bytes from
* multiple compressed blocks from a single read. Failure to do so will
* violate the buffering performed by this class, as it will access
* bytes into the next block after the split before returning all of the
* records from the previous block.
*/
@InterfaceAudience.Private
@InterfaceStability.Unstable
public class CompressedSplitLineReader extends SplitLineReader {
SplitCompressionInputStream scin;
private boolean usingCRLF;
private boolean needAdditionalRecord = false;
private boolean finished = false;
public CompressedSplitLineReader(SplitCompressionInputStream in,
Configuration conf,
byte[] recordDelimiterBytes)
throws IOException {
super(in, conf, recordDelimiterBytes);
scin = in;
usingCRLF = (recordDelimiterBytes == null);
}
@Override
protected int fillBuffer(InputStream in, byte[] buffer, boolean inDelimiter)
throws IOException {
int bytesRead = in.read(buffer);
// If the split ended in the middle of a record delimiter then we need
// to read one additional record, as the consumer of the next split will
// not recognize the partial delimiter as a record.
// However if using the default delimiter and the next character is a
// linefeed then next split will treat it as a delimiter all by itself
// and the additional record read should not be performed.
if (inDelimiter && bytesRead > 0) {
if (usingCRLF) {
needAdditionalRecord = (buffer[0] != '\n');
} else {
needAdditionalRecord = true;
}
}
return bytesRead;
}
@Override
public int readLine(Text str, int maxLineLength, int maxBytesToConsume)
throws IOException {
int bytesRead = 0;
if (!finished) {
// only allow at most one more record to be read after the stream
// reports the split ended
if (scin.getPos() > scin.getAdjustedEnd()) {
finished = true;
}
bytesRead = super.readLine(str, maxLineLength, maxBytesToConsume);
}
return bytesRead;
}
@Override
public boolean needAdditionalRecordAfterSplit() {
return !finished && needAdditionalRecord;
}
}
import java.io.IOException;
import java.io.InputStream;
import org.apache.hadoop.classification.InterfaceAudience;
import org.apache.hadoop.classification.InterfaceStability;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FSDataInputStream;
import org.apache.hadoop.io.Text;
/**
* SplitLineReader for uncompressed files.
* This class can split the file correctly even if the delimiter is multi-bytes.
*/
@InterfaceAudience.Private
@InterfaceStability.Unstable
public class UncompressedSplitLineReader extends SplitLineReader {
private boolean needAdditionalRecord = false;
private long splitLength;
/** Total bytes read from the input stream. */
private long totalBytesRead = 0;
private boolean finished = false;
private boolean usingCRLF;
public UncompressedSplitLineReader(FSDataInputStream in, Configuration conf,
byte[] recordDelimiterBytes, long splitLength) throws IOException {
super(in, conf, recordDelimiterBytes);
this.splitLength = splitLength;
usingCRLF = (recordDelimiterBytes == null);
}
@Override
protected int fillBuffer(InputStream in, byte[] buffer, boolean inDelimiter)
throws IOException {
int maxBytesToRead = buffer.length;
if (totalBytesRead < splitLength) {
maxBytesToRead = Math.min(maxBytesToRead,
(int)(splitLength - totalBytesRead));
}
int bytesRead = in.read(buffer, 0, maxBytesToRead);
// If the split ended in the middle of a record delimiter then we need
// to read one additional record, as the consumer of the next split will
// not recognize the partial delimiter as a record.
// However if using the default delimiter and the next character is a
// linefeed then next split will treat it as a delimiter all by itself
// and the additional record read should not be performed.
if (totalBytesRead == splitLength && inDelimiter && bytesRead > 0) {
if (usingCRLF) {
needAdditionalRecord = (buffer[0] != '\n');
} else {
needAdditionalRecord = true;
}
}
if (bytesRead > 0) {
totalBytesRead += bytesRead;
}
return bytesRead;
}
@Override
public int readLine(Text str, int maxLineLength, int maxBytesToConsume)
throws IOException {
int bytesRead = 0;
if (!finished) {
// only allow at most one more record to be read after the stream
// reports the split ended
if (totalBytesRead > splitLength) {
finished = true;
}
bytesRead = super.readLine(str, maxLineLength, maxBytesToConsume);
}
return bytesRead;
}
@Override
public boolean needAdditionalRecordAfterSplit() {
return !finished && needAdditionalRecord;
}
@Override
protected void unsetNeedAdditionalRecordAfterSplit() {
needAdditionalRecord = false;
}
}
相關推薦
Hadoop之多行讀取資料
一,需求: 在map執行前,即setInputFormatClass過程,會進行資料的讀入,預設的是每次讀入一行資料,進行計算。現在需要改成每次讀入兩行資料並且合併結果輸出。 二,思路及解決方法: 建議先看看他們的原始碼,理解思路。 我這裡是採用的Tex
Python之按行讀取DataFrame二維陣列資料
import numpy as np import pandas as pd data = {"省份":['北京', "上海", "天津", "重慶", "江蘇", "浙江", "廣東"], "年份":[2017, 2015, 2013, 2016, 200
DataGridView控制元件之多行資料的選中與刪除功能
DataGridView控制元件之多行資料的選中與刪除步驟: (1)建立Windows窗體程式,並在窗體上防止一個dataGridView控制元件名字為dataGridView1,兩個按鈕控制元件(ADD和Delete),名字分別為AddBtn、DeleteBtn。 (2)
研究MapReduce原始碼之實現自定義LineRecordReader完成多行讀取檔案內容
TextInputFormat是Hadoop預設的資料輸入格式,但是它只能一行一行的讀記錄,如果要讀取多行怎麼辦? 很簡單 自己寫一個輸入格式,然後寫一個對應的Recordreader就可以了,但是要實現確不是這麼簡單的 首先看看TextInputForma
Hadoop之客戶端讀取HDFS中的資料
客戶端通過呼叫FileSystem物件的open()方法來開啟希望讀取的檔案 DistributedFileSystem使用RPC呼叫namenode,確定檔案起始塊位置。對於檔案的每個塊,namen
python學習之多行字符串
color logs har pre sof brush err clas true 多行字符串的寫法 ("..." "..." "...") 例子 >>> err = ("a" ... "b" ... "c") >
Python從txt檔案中逐行讀取資料
Python從txt檔案中逐行讀取資料 # -*-coding:utf-8-*- import os for line in open("./samples/label_val.txt"): print('line=', line, end = '') #後面
PyQt5之多行文字框(QtextEdit)類中的常用方法和訊號
PyQt5之QtextEdit類中的常用方法和訊號 一、QTextEdit類中的常用方法 setPlainText(): 設定多行文字框的內容。 toPlainText(): 返回多行文字框的文字內容。 setHtml(): 設定多行文
Oracle 資料庫入門之----------------------,多行函式
2,多行函式 SQL> --工資總額 SQL> select sum(sal) from emp; SUM(SAL) &
如何讓textarea中輸入多行的資料在p標籤中換行?
我們在用React開發Web專案的過程中,有的時候,我們需要把textarea中輸入的多行字串,在其他的標籤中輸出來,比如p標籤。但是,往往這個時候,在p標籤中輸出的內容其預設情況下是不換行的。比如下面的程式碼: import React,{Component} from 'reac
vim常用命令之多行註釋和多行刪除
vim中多行註釋和多行刪除命令,這些命令也是經常用到的一些小技巧,可以大大提高工作效率。 1.多行註釋: 1. 首先按esc進入命令列模式下,按下Ctrl + v,進入列(也叫區塊)模式; 2. 在行首使用上下鍵選擇需要註釋的多行; 3. 按下鍵盤(大
Python學習【第21篇】:程序池以及回撥函式 python併發程式設計之多程序2-------------資料共享及程序池和回撥函式
python併發程式設計之多程序2-------------資料共享及程序池和回撥函式 一、資料共享 1.程序間的通訊應該儘量避免共享資料的方式 2.程序
多行的資料中根據物件欄位給各個radio設值
開發中經常遇到這種情況: 後臺傳一個集合到頁面,我們需要遍歷它,常見使用<c:foreach>進行, 對各個欄位設定值。 那麼對於radio這種怎麼處理? 當然是是使用js來完成,該例子使用Jquery解決。 如下圖一個超級簡單的頁面, 整理筆記的時候比較少,沒來得及寫個像樣點的
微信小程式之多行文字省略號
最近在開發小程式,開發一個小元件,本來開發得差不多了,因為一個多行文字省略號的問題,拖了我一天啊(即使最後較好地解決了啊),可能是自己的開發經驗不足導致了沒能找到好的方案啊,把自己的經歷寫下來吧 一開始,我查了網上的各種資料,其實CSS就足以實現單行文字省略號
Qt總結之四:讀取資料夾所有檔案
之前,用標準C++寫過讀取資料夾。 現在用QT重寫程式碼,順便看了下QT如何實現,還是相當簡單的。 主要用到QDir,詳細文件可見這裡 A program that lists all the files in the current directory (excluding sym
C語言之按行讀取檔案
原文字檔案 outlook,temperature,humidity,windy,play sunny,hot,high,FALSE,no sunny,hot,high,TRUE,no overcas
Oracle-28-子查詢之多行子查詢&子查詢之多列子查詢
一、子查詢的基本型別之多行子查詢 (1)使用IN操作符進行多行子查詢。(總結:IN操作符後可用多行子查詢) 比如:查詢各個職位中工資最高的員工資訊。 SQL>select ename, job
shell學習之逐行讀取文字
#!/bin/bash daemonFilename="test.sh" fileName="/home/work/local/liumengting/setDaemon.cfg" while read line do parameterName=`echo $line | awk -F "=
行列轉換之——多行轉多列,多列轉多行實踐版
多行 max 演示 spa info 思想 .com 要求 列轉行 行列轉換之——多行轉多列,多列轉多行實踐版 1、多列轉行(核心思想,利用row_number() over() 來構造列傳行之後的唯一列,來行轉列) 要求: 實操演示: select
dialog之多行文字的使用
REPORT Z_CHANGWENBEN_001. DATA: CONTAINER TYPE REF TO CL_GUI_CUSTOM_CONTAINER, EDITOR01 TYPE REF TO CL_GUI_TEXTEDIT. START-OF