
延遲任務排程系統—技術選型與設計(上篇)
本文來自網易雲社群
-
- 延遲任務的場景是?
- 現有的解決方案是?
- 存在的問題是什麼?
- 希望達到的目標是?
- 可以實現的方案有?
- RabbitMQ實現
- 通過死信和死信路由實現
- 通過延遲訊息外掛來實現
- Redis實現
- DelayQueue實現
- 時間輪實現
- 單表時間輪
- 分層時間輪
- 之前的設計(DB/DelayQueue/ZooKeeper)
- 另一種方案(DB/DelayQueue/ZooKeeper/MQ
- RabbitMQ實現
延遲任務的場景是?
- 習題考試截止前3天,給未提交使用者傳送消
- 學習專案開課前2小時,給參與使用者傳送通知
- 問卷開始收集時,才對使用者可見
- 問卷結束收集時,觸發一些操作
- 指定時間釋出課件
- 課程結束時,開始計算使用者結業資訊
- 直播時間到了,給使用者傳送訊息
- 使用者下單後,30分鐘內未付款,關閉訂單
- 使用者付款後,24小時內未發貨,提示發貨
- 使用者打車後,48小時後自動評價為5星
- 這類業務的特點是:延遲執行。一種比較簡單的方法是使用後臺執行緒掃描符合條件的業務資料,逐一處理。 這種方法掃描間隔時間不好設定,間隔時間過大影響精確度,過小則影響效率和效能。
現有的解決方案是?
- 通過linux的crontab觸發定時任務
- 掃描業務表,篩選出符合條件的資料對其進行操作
存在的問題是什麼?
- 由於每種型別的任務都設有掃描間隔,任務不能精確處理
- 掃描業務庫,影響業務正常操作
- 任務的執行過於密集,容易導致伺服器間隔性壓力
- 存在系統單點,觸發定時排程的服務掛了,所有任務都不會執行
- 系統不具容錯能力,一旦錯過了,任務就不會再被執行
- 沒有統一的檢視來檢視任務的執行情況
- 沒有告警來提示失敗的任務
希望達到的目標是?
- 精確性(可在指定時間觸發任務處理)
- 通用性
- 高效能(叢集能力不少於1000TPS)
- 高可用(支援多例項部署)
- 可伸縮(增加和減少服務時,任務會重新分配)
- 可重試(任務失敗可重試)
- 多協議(支援http\dubbo呼叫)
- 可管理(業務使用方可修改、刪除任務)
- 能告警(失敗次數達到閾值可觸發告警)
- 統一檢視(方便檢視任務執行情況,可手動干預任務執行)
下面所討論技術方案的前提是精確觸發,所以我們不討論目前業界的一些分散式排程系統如:elastic-job,xxl-job,tbschedule等, 這些系統解決不了延遲任務精確觸發問題。
可以實現的方案有?
RabbitMQ實現
通過死信和死信路由實現
原理如下:
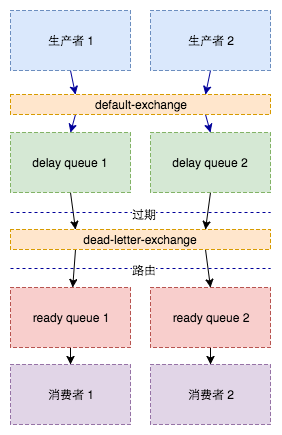
何為死信:
- 訊息被拒絕
- 訊息已過期
- 佇列達到最大長度
RabbitMQ可以對佇列和訊息設定x-message-tt、expiration來控制訊息的存活時間,如果超時,訊息變為死信。
何為死信路由:
RabbitMQ可以對佇列設定x-dead-letter-exchange和x-dead-letter-routing-key兩個引數。
當訊息在一個佇列中變成死信後會按這兩個引數路由,訊息就可以重新被消費。
例項操作:
- 建立延遲佇列(設定死信路由)
- 建立就緒佇列
- 建立死信路由
- 繫結死信路由與就緒佇列
- 傳送延遲訊息
- 訊息過期後進入就緒佇列
優點:
- 高效,可以利用RabbitMQ的分散式特性輕易進行橫向擴充套件,且支援持久化
缺點:
- 不支援對已傳送的訊息進行管理
- 一個訊息比在同一佇列中的其他訊息提前過期,提前過期的訊息也不會優先進入死信佇列。
所以需要確保業務上每個任務的延遲時間是一致的。如果有不同延時的任務,需要為每種不同延遲的任務單獨建立訊息佇列,缺乏靈活性。
通過延遲訊息外掛來實現
原理如下:
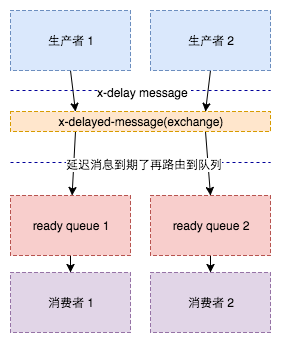
核心程式碼流程:

其原理是延遲訊息會被儲存到Mnesia表,在Exchange中根據每個message頭設定的延遲時間x-delay,訊息過期後才路由到對應佇列。
例項操作:
docker-compose.xml(將外掛安裝到容器中) version: '2' services: rabbitmq: hostname: rabbitmq image: rabbitmq:3.6.8-management mem_limit: 200m ports: - "5672:5672" - "15672:15672" volumes: - ~/dockermapping/rabbitmq/lib:/var/lib/rabbitmq/
- /Users/oldlu/workspace/document/docker-compose/rabbitmq/rabbitmq_delayed_message_exchange-0.0.1.ez:/usr/lib/rabbitmq/lib/rabbitmq_server-3.6.8/plugins/rabbitmq_delayed_message_exchange-0.0.1.ez
啟用外掛
rabbitmq-plugins enable rabbitmq_delayed_message_exchange
- 建立型別為x-delayed-message的路由
- 建立就緒佇列
- 繫結佇列和路由
- 釋出延遲訊息(設定x-delay=延遲的毫秒數)
核心函式
訊息入隊:internal_delay_message
啟動Timer:maybe_delay_first
訊息處理:handle_info
優點:
- 一個訊息比其他訊息提前過期,提前過期的訊息會被提前路由到佇列,不需要為不同延遲的訊息建立單獨的訊息佇列。
缺點:
- 不支援對已傳送的訊息進行管理
- 叢集中只有一個數據副本(儲存在當前節點下的Mnesia表中),如果節點不可用或關閉外掛會丟失訊息。
- 目前該外掛只支援disk節點,不支援RAM節點
- 效能比原生差一點(普通的Exchange收到訊息後直接路由到佇列,而延遲佇列需要判斷訊息是否過期,未過期的需要儲存在表中,時間到了再撈出來路由)
Redis實現
有序集合(Sorted Set)是Redis提供的一種資料結構,具有set和hash的特點。
其中每個元素都關聯一個score,並以這個score來排序。
其內部實現用到了兩個資料結構:hash table和 skip list(跳躍表)
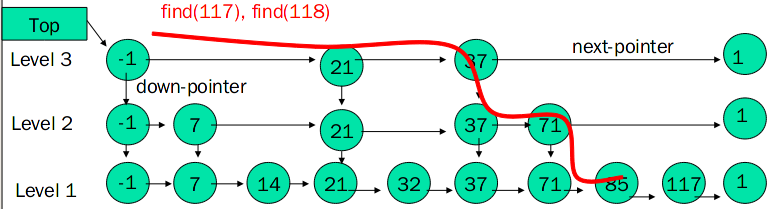
skip list的特點
- 由很多層結構組成,level是通過一定的概率隨機產生的
- 每一層都是一個有序的連結串列,預設是升序
- 最底層的連結串列包含所有元素
- 如果一個元素出現在Level i的連結串列中,則它在Level i之下的連結串列也都會出現
- 每個節點包含兩個指標,一個指向同一連結串列中的下一個元素,一個指向下面一層的元素
- 插入和刪除的時間複雜度是O(logn),當達到了一定的資料規模之後,它的效率與紅黑樹差不多
主要命令
- zadd:向Sorted Set中新增元素
- zrem:刪除Sorted Set中的指定元素
- zrange:按照從小到大的順序返回指定區間內的元素
實現延遲佇列
- 將延遲任務加到Sorted Set,將延遲時間設為score
- 啟動一個執行緒不斷判斷Sorted Set中第一個元素的score是否大於當前時間
- 如果大於,從Sorted Set中移除任務並新增到執行佇列中
- 如果小於,進行短暫休眠後重試
例項操作
[email protected]:/usr/local/bin# redis-cli127.0.0.1:6379> zadd delayqueue 1 task1
(integer) 1127.0.0.1:6379> zadd delayqueue 2 task2
(integer) 1127.0.0.1:6379> zadd delayqueue 4 task4
(integer) 1127.0.0.1:6379> zadd delayqueue 3 task3
(integer) 1127.0.0.1:6379>127.0.0.1:6379> zrange delayqueue 0 0 withscores1) "task1"
優點:
- 實現簡單
- 任務可管理(可刪除、修改任務)
缺點:
- 需要有短輪詢執行緒不斷判斷第一個元素是否過期,造成CPU空耗
- 分散式場景中,容易引起多個節點讀取到相同任務
DelayQueue實現
DelayQueue是一個使用優先佇列實現的BlockingQueue,優先佇列比較的是時間,內部儲存的是實現Delayed介面的物件。 只有在物件過期後才能從佇列中獲取物件。
內部結構
- 可重入鎖
- 用於根據delay時間排序的優先順序佇列
- 用於優化阻塞通知的執行緒leader
- 用於實現阻塞和通知的Condition物件
Leader/Followers
Leader/Followers是多個工作執行緒輪流進行事件監聽、分發、處理的一種模式。 該模式最大的優點在於,它是自己監聽事件並處理客戶請求,從接收到處理都是在同一執行緒中完成, 所以不需要線上程之間傳遞資料,解決執行緒頻繁切換帶來的開銷。
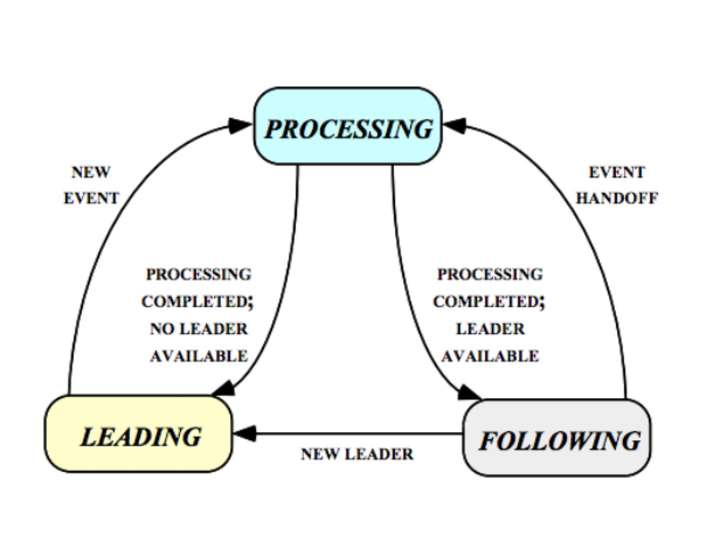
該模式工作的任何時間點,只有一個執行緒成為Leader ,負責事件監聽,而其他執行緒都是Follower,在休眠中等待成為Leader。 該模式的工作執行緒存在三種狀態,工作執行緒同一時間只能處於一種狀態,這三種狀態為
- Leading:執行緒處於領導者狀態,負責事件監聽。Leader監聽到事件後,有兩種處理方式:
- 可以轉移至Processing狀態,自己處理該事件,並呼叫方法推選新領導者。
- 也可以指定其他Follower來處理事件,此時Leader狀態不變。
- Processing:執行緒正在處理事件,處理完事件如果當前執行緒集中沒有領導者,它將成為新領導者,否則轉為追隨者。
- Following:執行緒處於追隨者狀態,等待成為新的領導者也可能被領導者指定來處理新的事件。
核心原始碼分析:
入隊public boolean offer(E e) {
final ReentrantLock lock = this.lock;
lock.lock();
try {
q.offer(e);
if (q.peek() == e) {//入隊物件延遲時間是佇列中最短的 leader = null;//重置leader available.signal();//喚醒一個執行緒去監聽新加入的物件 }
return true;
} finally {
lock.unlock();
}
}
出隊public E take() throws InterruptedException {
final ReentrantLock lock = this.lock;
lock.lockInterruptibly();
try {
for (;;) {
E first = q.peek();
if (first == null)
available.await();//佇列為空,無限等待 else {
long delay = first.getDelay(TimeUnit.NANOSECONDS);
if (delay <= 0)//延遲時間已過,直接返回 return q.poll();
else if (leader != null)//已有leader在監聽了,無限等待 available.await();
else {
Thread thisThread = Thread.currentThread();
leader = thisThread;//當前執行緒成為leader try {
available.awaitNanos(delay);//在delay納秒後喚醒 } finally {
if (leader == thisThread)// 入隊一個最小延遲時間的物件時leader會被清空 leader = null;
}
}
}
}
} finally {
if (leader == null && q.peek() != null)//leader不存在且佇列不為空,喚醒一個follower去成為leader去監聽 available.signal();
lock.unlock();
}
}
優點:
- 效率高,任務觸發時間延遲低
缺點:
- 資料是儲存在記憶體,需要自己實現持久化
- 不具備分散式能力,需要自己實現高可用
未完待續。
本文來自網易雲社群,經作者陳志良授權釋出。
相關推薦
延遲任務排程系統—技術選型與設計(上篇)
本文來自網易雲社群 延遲任務的場景是? 現有的解決方案是? 存在的問題是什麼? 希望達到的目標是? 可以實現的方案有? RabbitMQ實現 通過死信和死信路由實現 通過延遲訊息外掛來實現 Redis實現 Delay
延時任務排程系統——技術選型
經常會有這樣的需求,包含大量的延時執行任務 1,如一個代辦事項app,代辦實現可以設定觸發時間,像鬧鐘一樣。 2,如美團的訂單,下單後10分鐘不支付,會自動取消。 3,淘寶使用者7天不確認收貨,自動確認收貨。 諸如以上需求,需要的就是一個延時任務執行系統。
網際網路賬戶系統如何設計(上篇)?
在很多網際網路公司業務發展的早期,業務模式比較單一的情況下,涉及使用者賬戶資金交易相關的邏輯也比
網際網路賬戶系統如何設計(上篇)
在很多網際網路公司業務發展的早期,業務模式比較單一的情況下,涉及使用者賬戶資金交易相關的邏輯也比較簡單,但是隨著公司業務模式的不斷創新及型別的多元化發展,會漸漸發現現有系統賬戶邏輯越來越雍腫,不僅難以支援新業務的擴張,對現有業務的支援也適配困難,最終導致新業務系統不得不重新搭建自己的業務賬戶邏輯,造
【SqlServer系列】淺談SQL Server事務與鎖(上篇)
架構 tab 要求 允許 ble 1.2 定義 由於 數據庫引擎 一 概述 在數據庫方面,對於非DBA的程序員來說,事務與鎖是一大難點,針對該難點,本篇文章試圖采用圖文的方式來與大家一起探討。 “淺談SQL Server 事務與鎖”這個專題共分
太陽能電池系統的選型與設計
1、單晶矽太陽能電池板特性資料 以KLY200-72型單晶矽電池元件為例。 技術引數 ■元件由72片125×125的單晶矽太陽電池串聯組成。 ■陽極氧化鋁合金邊框構成實用的方開結構,允許單個使用或陣列使用 ■配有標準支架系統,安裝孔 ■保證25年使用壽命 ■
微服務之架構技術選型與設計
本文主要介紹了架構技術選型與設計-微服務選型,Spring cloud 實現採用的技術,希望對您的學習有所幫助。 架構技術選型與
計算機組成與設計(十一)—— 儲存層次結構(上)
儲存層次結構概況 這是我們非常熟悉的馮·諾依曼計算機結構, 那這其中哪些部件和儲存功能有關呢? 儲存器和外部記錄介質肯定具有儲存功能,另外還有一個自帶儲存功能的運算器,為了描述方便,我們把這些部件統稱為儲存器。那麼我們看一下計算機中對儲存器有哪些要求 ? 1、首先儲存器當
計算機組成與設計(十二)—— 儲存層次結構(二)
快取記憶體的原理 cpu和記憶體的速度差距越來越大,計算機的效能受到影響,而快取記憶體的出現挽救了這一局面。 為什麼在cpu和主存直接新增一個容量很小、速度更快的快取記憶體能增加計算機的效能呢? 程式的區域性性原理 這是一個經驗性結論:計算機程式從時間和空間都表現出區域性性。 時間區
基於深度學習的人臉識別AI技術謎與思(十四)--臉型識別
所有圖片源自網路,無意冒犯,如覺不適,通知後立即刪除。 本文在頭條號和百家號同步首發 前言 2017年12月25日,百度大腦人臉模組再一次升級,由原來的1.6.9.0升級為2.0.0.0,自此之後,我們的人臉識別就採用最新的版本了。大公司時刻充滿了焦慮感和
恩智浦杯(飛思卡爾)全國大學生智慧車競賽攝像頭簡單的影象失真矯正技術原理與實現(透視變換)
先說一些廢話(沒耐心看可直接看分割線下面的內容): 博主是去年參加了十二屆的恩智浦杯(飛思卡爾)全國大學生智慧車競賽光電競速組,我們隊當時獲得的是區賽預賽第三、決賽第四的成績,我們區賽的光電競速組可以選拔五組進入全國總決賽,但因為我們學校另一個隊獲得了區賽決賽第三,
史上最全的延遲任務實現方式彙總!附程式碼(強烈推薦)
這篇文章的誕生要感謝一位讀者,是他讓這篇優秀的文章有了和大家見面的機會,重點是優秀文章,哈哈。 事情的經過是這樣的... 不用謝我,送人玫瑰,手有餘香。相信接下來的內容一定不會讓你失望,因為它將是目前市面上最好的關於“延遲任務”的文章,這也一直是我寫作追求的目標,讓我的每一篇文章都比市面上的好那麼一點點。
高德SD地圖資料生產自動化技術的路線與實踐(道路篇)
一、背景及現狀 近些年,國內道路交通及相關設施的基礎建設日新月異。廣大使用者日常出行需求旺盛,對所使用到的電子地圖產品的資料質量和現勢性提出了更高的要求。傳統的地圖資料採集和生產過程,即通過採集裝置實地採集後對採集資料進行人工處理的模式,其資料更新慢、加工成本高等問題矛盾日益突顯。 高德地圖憑藉視覺AI和大資
編程經常使用設計模式具體解釋--(上篇)(工廠、單例、建造者、原型)
-a 裝飾器模式 nds support art 類的繼承 兩個 開放 lose 參考來自:http://zz563143188.iteye.com/blog/1847029 一、設計模式的分類 整體來說設計模式分為三大類: 創建型模式。共五種:工廠方法模式、抽
支付網關 | 京東618、雙11用戶支付的核心承載系統(上篇)
java 支付 雙11 支付網關 618 二零一七年六月二十一日,就是年中大促剛結束的那一天,我午飯時間獨在辦公室裏徘徊,遇見X君,前來問我道,“可曾為這次大促寫了一點什麽沒有?”我說“沒有”。他就正告我,“還是寫一點罷;小夥伴們很想了解支撐起這麽大的用戶支付流量所采用的技術。”「摘要
數據庫設計(理解篇)
國家 span 特性 定義 余數 給定 數據模型 用戶數 數據共享 1. 原始單據與實體之間的關系(原始單據可以理解為整個錄入界面的數據,這裏的實體可以理解為基本表) 可以是一對一、一對多、多對多的關系。 在一般情況下,它們是一對一的關系:即一張原始單據對應
數組與集合(基礎篇)
效率 變量 hset 取出 集合 初始 queue 字符 行為 一、數組 能存放任意多個同類型的數據 1. 數據的聲明與賦值合並書寫:數據類型[] 變量名 = new 數據類型[長度] ① 聲明:數據類型[] 變量名; ② 賦值:變量名 = new 數據類型[長度] 2
.net ef core 領域設計代碼轉換(上篇)
解決 con mage keys $1 服務 結構 刪除 sql 一、前言 .net core 2.0正式版已經發布幾個月了,經過研究,決定把項目轉移過來,新手的話可以先看一些官方介紹 傳送門:https://docs.microsoft.com/zh-cn/do
xgboost入門與實戰(原理篇)
enc 之前 fine 小結 附近 step 參考 search line http://blog.csdn.net/sb19931201/article/details/52557382 xgboost入門與實戰(原理篇) 前言: xgboost是大規模並行booste
【轉】PANDAS 數據合並與重塑(concat篇)
分享 levels 不同的 整理 con 簡單 post ignore num 轉自:http://blog.csdn.net/stevenkwong/article/details/52528616 1 concat concat函數是在pandas底下的方法,可以將數據