
Tensorflow #2 深度學習-RNN LSTM版 MNIST手寫識別Demo
Tensorflow #1 祖傳例子 MNIST 手寫識別
Tensorflow自帶的那個MNIST任務其實挺好用的,之前使用最簡單的方法去做,記得正確率應該是92%附近?
其實那個例子是用來熟悉Tensorflow的,算是一個對Tensorflow的熟悉吧,而最近也在看RNN,並且正好看到了這個RNN的例子,因此特別的讀了下原始碼,並且提供了相關的註釋。
如果有問題請留言就好,目前也不是特別熟悉,難免遇到問題。
這個程式總體來說,還是MNIST任務,如果有疑惑可以看我附上上一篇,或者文章最後我直接複製過來的那些。
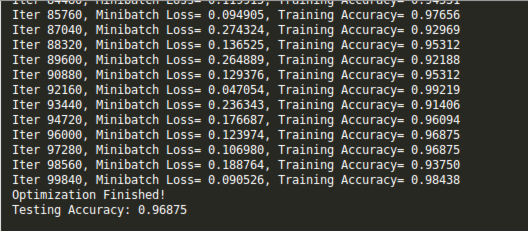
正確率大約在96%~97%
from tensorflow.examples.tutorials.mnist import 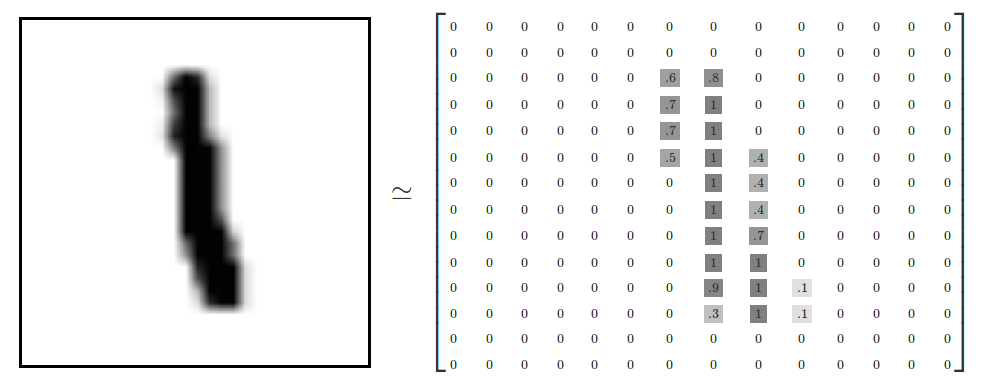
MNIST這個Demo感覺已經是遍地都是了,在這裡也是,就是最簡單的手寫數字識別,輸入理論上是一個寫了數字的影象作為測試資料,這裡測試資料轉化成的文字矩陣了(28*28=784 維),我們可以通過在python環境中執行如下程式碼自動獲取資料,程式碼執行完會在對應的資料夾儲存好資料,如果需要可以自定義地址:
from tensorflow.examples.tutorials.mnist import input_data
mnist = input_data.read_data_sets("MNIST_data/", one_hot=True)MNIST的資料集,共有三部分:
55,000 points 訓練集 (mnist.train), 10,000 points 測試集 (mnist.test), 5,000 驗證集 (mnist.validation).
與之同時,由於其是一個有監督的學習任務,所以還有對應的標籤(也就是影象對應的真實數字),這部分位於(mnist.train.labels),標籤也是以one-hot的方式表示,即這個向量共有10維,第I個位1就是證明這個Label是I
相關推薦
Tensorflow #2 深度學習-RNN LSTM版 MNIST手寫識別Demo
Tensorflow #1 祖傳例子 MNIST 手寫識別 Tensorflow自帶的那個MNIST任務其實挺好用的,之前使用最簡單的方法去做,記得正確率應該是92%附近? 其實那個例子是用來熟悉Tensorflow的,算是一個對Tensorflow的熟悉
深度學習系列——AlxeNet實現MNIST手寫數字體識別
本文實現AlexNet,用於識別MNIST手寫數字體。所有程式碼的框架基於tensorflow。看了幾篇論文的原始碼之後,覺得tensorflow 確實很難,學習程式設計還是靠實踐。這篇部落格留著給自己以及學習深度學習道路上的小夥伴們一些參考吧,希望能對大家有所幫助!
TensorFlow實現機器學習的“Hello World”--Mnist手寫數字識別
TensorFlow實現機器學習的“Hello World” 上一篇部落格我們已經說了TensorFlow大概怎麼使用,這次來說說機器學習中特別經典的案例,也相當於是機器學習的“Hello World”,他就是Mnist手寫數字識別,也就是通過訓練機器讓他能看
tensorflow-GPU 一步步搭建網路實現MNIST手寫識別
1. MNIST資料集的匯入 這裡介紹一下MNIST,MNIST是在機器學習領域中的一個經典問題。該問題解決的是把28x28畫素的灰度手寫數字圖片識別為相應的數字,其中數字的範圍從0到9. 首先我們要匯入MNIST資料集,這裡需要用到一個input_data.py檔案,在
《TensorFlow:實戰Google深度學習框架》--5.2.1 MNIST手寫識別問題(程式已改進)
目錄 MNIST資料集介紹: TensorFlow完整訓練MNIST資料集(程式已改進): 本篇部落格涉及很多本書第4章的知識:啟用函式、指數衰減的學習率設定、正則化、滑動平均等知識。如有疑問請參考本部落格關於第4章記錄介紹。 MNIST資料集介紹: MNIST資料集是N
tensorflow 學習筆記12 迴圈神經網路RNN LSTM結構實現MNIST手寫識別
長短時記憶網路(LSTM)就是為了解決在複雜的場景中,有用資訊的間隔有大有小、長短不一問題。LSTM是一種擁有三個門結構的特殊網路結構。 LSTM靠一些門的結構讓資訊有選擇的影響迴圈神經網路中每個時刻的狀態。所謂門的結構就是一個使用sigmoid神經網路和按位做乘法的操作
機器學習-->深度學習-->RNN,LSTM
本篇博文將把我所學習的迴圈神經網路(RNN)和長短時記憶神經網路(LSTM)做一個詳細的總結分析。 RNN 為什麼會有迴圈神經網路 傳統的神經網路(包括CNN),輸入輸出都是互相獨立的 。但是在一些場景中,後續的輸出和之前的內容是相關的。比如一段句
TensorFlow學習筆記(1)—— MNIST手寫識別
1、初步學習 資料處理 xs:60000張圖片,28*28大小,將所有畫素點按一列排列,資料集變為了[60000, 784]的二維矩陣。 ys:60000張圖片,每個圖片有一個標籤標識圖片中數字,採用one-hot向量,資料集變為[60000, 10]的二維矩陣。 softm
使用LSTM實現mnist手寫數字分類識別 TensorFlow
RNN做影象識別原理:MNIST資料集中一張圖片資料包含28*28的畫素點。RNN是將一張圖片資料的一行作為一個向量總體輸入一個X中。也就是說,RNN有28個輸入X,一個輸入X有28個畫素點。 輸出最後一個結果做為預測值。 TensorFlow入門學習程式碼: # -
win10下通過Anaconda安裝TensorFlow-GPU1.3版本,並配置pycharm運行Mnist手寫識別程序
mnist all -1 為什麽 提示 4.2 not correct sof 折騰了一天半終於裝好了win10下的TensorFlow-GPU版,在這裏做個記錄。 準備安裝包: visual studio 2015; Anaconda3-4.2.0-Windows-x86
Tensorflow編程基礎之Mnist手寫識別實驗+關於cross_entropy的理解
ast 大學時光 default ice red con graph cast utf-8 好久沒有靜下心來寫點東西了,最近好像又回到了高中時候的狀態,休息不好,無法全心學習,惡性循環,現在終於調整的好一點了,聽著純音樂突然非常傷感,那些曾經快樂的大學時光啊,突然又慢慢的一
fastai案例學習(3)——MNIST手寫資料集
本文主要介紹fastai自帶的案例,MNIST手寫資料集。 1、匯入包。 import fastai from fastai import * from fastai.vision import * 2、下載MNIST資料集。 path = untar_data(URLs.MNI
TensorFlow—mnist手寫識別
神經網路: 重點在闕值和w,因為y=w1*x1+w2*x2+w3*x3... 啟用函式:在隱藏層,每個輸出點帶入啟用函式,然後再繼續向後,最後輸出的y預測值不需要啟用 損失函式:定義的形式(三種):均方誤差(西瓜書)、自定義需要的引數、交叉熵(吳恩達裡面定義的有log的損失函
LSTM在MNIST手寫資料集上做分類(程式碼中尺寸變換細節)
RNN和LSTM學了有一段時間了,主要都是看部落格瞭解原理,最近在研究SLSTM,在對SLSTM進行實現的時候遇到了困難,想說先比較一下二者的理論實現,這才發現自己對於LSTM內部的輸入輸出格式、輸出細節等等都不是非常清楚,藉此機會梳理一下,供後續研究使用。 下面程式碼來自
pytorch 利用lstm做mnist手寫數字識別分類
程式碼如下,U我認為對於新手來說最重要的是學會rnn讀取資料的格式。 # -*- coding: utf-8 -*- """ Created on Tue Oct 9 08:53:25 2018 @author: www """ import sys sys.path
Caffe學習筆記(六):mnist手寫數字識別訓練例項
一、前言 深度學習的一個簡單例項就是mnist手寫數字識別,只要這個例子弄明白,其它的內容就可以舉一反三了。之前的內容如有遺忘,可以進行回顧。 二、準備資料 資料集可以直接從我的github下載,包括資料集和程式碼,使用如下指令:
Keras中將LSTM用於mnist手寫數字識別
import keras from keras.layers import LSTM from keras.layers import Dense, Activation from keras.datasets import mnist from keras.models
Tensorflow #1 祖傳例子 MNIST 手寫識別
1 前語 最近想學習DL,但是發現沒有什麼好的入門的東西,最近方向一直比較迷茫,東做做西做做,現在又來這裡做Tensorflow了。 關於Tensorflow 1.0是如何安裝的,可以直接參照他的官方文件,我是裝在了Ubuntu 14.04 64bit上的,
使用tensorflow實現mnist手寫識別(單層神經網絡實現)
for 神經網絡 評估 手寫識別 抽取 display mnist 一個 next import tensorflow as tf import tensorflow.examples.tutorials.mnist.input_data as input_data
吳裕雄 python 神經網絡——TensorFlow實現回歸模型訓練預測MNIST手寫數據集
rect ros its .com img tensor sce 交互 run import tensorflow as tf from tensorflow.examples.tutorials.mnist import input_data mnist =