
Hadoop 二次排序實現
業務場景:通常情況下,在MR操作中到達Reduce中的key值都是按照指定的規則進行排序,在單一key的情況下一切都進行的很自然,直到我們要求資料不再單純的按key進行排序,以如下資料舉例:
Key -> value:
100 -> 2017-02-27 19:21:31,45,67,68
50 -> 2017-02-27 19:22:04,89,90,56
90 -> 2017-02-27 19:22:27,90,89,99
50 -> 2017-02-27 19:20:42,88,45,89
現要求對結果資料進行分組,key值相同的為一組且組內有序
處理方式:
原理:藉助MR排序的優勢,提供可擴充套件的二次排序操作
流程
Map ->(複合主鍵,value) à自定義分割槽函式àReduce-
例項:
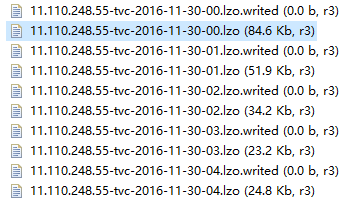
資料目錄如下,其中.loz結尾的為真正的資料檔案,以其檔名為字首.writed為字尾的問檔案標識當前.loz檔案寫狀態,只有處於.writed狀態的loz檔案為有效可讀檔案
資料格式如下:VERSION=1.0,PASSTIME=2016-11-30 00:00:39 000,CARSTATE=1,CARPLATE=無,PLATETYPE=99,SPEED=0,PLATECOLOR=4,LOCATIONID=-1,DEVICEID=-1,DRIVEWAY=2,DRIVEDIR=4,CAPTUREDIR=1,CARCOLOR=10,CARBRAND=99,CARBRANDZW=其它,TGSID=1125,PLATECOORD=0,0,0,0,CABCOORD=0,0,0,0,IMGID1=http://11.110.248.59:9099/image/dhdfs/2016-11-30/archivefile-2016-11-30-000040-00677B0200000001:5750848/308059.jpg,IMGID2=,IMGID3=,
資料量>=2G
要求如下:統計全部資料中每輛車按時間序列經過的卡口資訊(卡口欄位為元資料中TGSID列) 資料輸出格式為,檔名=號牌+輔助欄位,內容=過車時間(PASSTIME)-卡口編號(TGSID),…
程式設計實現:
1. CarOrder.class,自定義組合鍵,藉助MR的KEY排序操作實現Map內按key-time排序操作,要求實現兩序列化介面
classCarOrder implements Writable, WritableComparable<CarOrder> { //號牌 private Text carPlate; //過車時間 private Text day; public Text getDay() { return day; } public void setDay(Text day) { this.day = day; } public CarOrder() { carPlate = new Text(); day = new Text(); } public CarOrder(Text carPlate, Text day){ super(); this.carPlate = carPlate; this.day = day; } public int compareTo(CarOrder co){ int compareValue = this.carPlate.compareTo(co.carPlate); // 相等 if (compareValue == 0) { compareValue = this.day.compareTo(co.day); } return compareValue; } public void write(DataOutput out)throws IOException { this.carPlate.write(out); this.day.write(out); } public void readFields(DataInputin) throws IOException { this.carPlate.readFields(in); this.day.readFields(in); } public Text getCarPlate() { return carPlate; } public void setCarPlate(TextcarPlate) { this.carPlate = carPlate; } @Override public String toString() { return "CarOrder[carPlate=" + carPlate + ", day=" + day + "]"; } }
2. CarComparator.java,定義分組比較器,決定在MR SHUFFLE過程中對資料分組的依據,要求號牌相同時間不同的為同一組
classCarComparator extends WritableComparator {
public CarComparator() {
// 指定Key值
super(CarOrder.class, true);
}
@SuppressWarnings("rawtypes")
@Override
public int compare(WritableComparable a,WritableComparable b) {
CarOrder car1 = (CarOrder) a;
CarOrder car2 = (CarOrder) b;
return car1.getCarPlate().compareTo(car2.getCarPlate());
}
}3. CarPartitioner.class,自定義分割槽函式,Mapper操作中間結果分割槽依據,將資料均勻劃分.
classCarPartitioner extends Partitioner<CarOrder, Text> {
@Override
public int getPartition(CarOrder key, Textvalue, int numPartitions) {
return Math.abs(key.getCarPlate().hashCode())% numPartitions;
}
}4. CarMap.java Mapper函式,此處做簡單的資料解析工作,檔案過濾在驅動器節點完成,Mapper操作封裝複合鍵CarOrder輸出(CarOrder,”時間-卡口編號”)
classCarMap extends Mapper<LongWritable, Text, CarOrder, Text> {
@Override
protected void map(LongWritable key, Textvalue, Context context) throws IOException, InterruptedException {
String temp = value.toString();
if (temp.length() > 13) {
temp = temp.substring(12);
String[] items =temp.split(",");
if (items.length > 10) {
// CarPlate As Key
if(!items[2].endsWith("無牌")){
try {
CarOrderco = new CarOrder(new Text(items[2].substring(9)), newText(items[0].substring(9)));
//time + tgsid
context.write(co,new Text(items[0].substring(9)+"-"+items[14].substring(6)));
} catch(Exception e) {
e.printStackTrace();
}
}
}
}
}
}5. CarCombine.java ,考慮到Map端資料可能會偏大的情況,使用MR的Combine特性對Map的結果預先進行處理,減少Mapper端輸出,降低IO操作提高程式效能.
classCarCombine extends Reducer<CarOrder, Text, CarOrder, Text> {
@Override
protected void reduce(CarOrder co,Iterable<Text> values, Reducer<CarOrder, Text, CarOrder,Text>.Context context)
throws IOException,InterruptedException {
StringBuffer buf = newStringBuffer();
String before = null;
String current = null;
for (Text text : values) {
current = text.toString();
if (current.equals(before)){
continue;
}
buf.append(current);
buf.append(',');
before = current;
}
if(buf.length()==0){
return ;
}
context.write(co, newText(buf.toString()));
}
}6. OutputByCarPlate.java ,Reduce操作,由於要求結果按好配進行分類,經測試發現,在MR中使用大量的檔案輸出並不是好事,舉例來說如果有50萬車輛則可能需要50萬個檔案來儲存,效能開銷極大容易造成MR假死,甚至記憶體溢位! 未避免此問題,此處仍然採用多檔案輸出只不過降級為:按所有資料以天為檔案劃分依據進行儲存,單個車輛儲存一行。
classOutputByCarPlate extends Reducer<CarOrder, Text, NullWritable, Text> {
MultipleOutputs<NullWritable, Text> mo;
@Override
protected void setup(Reducer<CarOrder, Text,NullWritable, Text>.Context context)
throws IOException,InterruptedException {
mo = newMultipleOutputs<NullWritable, Text>(context);
}
@Override
protected void reduce(CarOrder key,Iterable<Text> values, Context context)
throws IOException,InterruptedException {
StringBuffer buf = newStringBuffer();
for (Text text : values) {
buf.append(text.toString());
buf.append(',');
}
String value = buf.toString();
String[] flows =value.split(",");
if (flows.length >= 3) {
String prefix =key.getDay().toString().replaceAll("[-\\s:]", "");
mo.write(NullWritable.get(),new Text(value.substring(0, value.length() - 1)), prefix.substring(0, 8));
}
}
@Override
protected void cleanup(Reducer<CarOrder,Text, NullWritable, Text>.Context context)
throws IOException,InterruptedException {
mo.close();
}
}7. Main.java ,驅動器節點,組織MR作業,預處理檔案,由於小檔案數量較多此處採用CombineTextInputFormat輸入文字檔案(因源資料使用LOZ壓縮演算法,經測試此處需要明確標識輸入塊的大小否則檔案合併無效,即: CombineTextInputFormat.setMaxInputSplitSize(job, 67108864);),MR提供的TextInputFormat.setInputPathFilter有侷限,只能過濾已經被識別的子目錄檔案,不支援動態修改,此處使用在Mapper之外過濾以CombineTextInputFormat.addInputPath(job, temp);方式追加輸入,以實現按特定要求去輸入檔案.
public class Main{
public static void main(String[] args) throwsException {
Configuration conf = newConfiguration();
conf.set("mapreduce.reduce.memory.mb","4096");
Job job = Job.getInstance(conf,"TRACK_BY_TIME_TGSID");
// 小檔案合併
job.setInputFormatClass(CombineTextInputFormat.class);
job.setJarByClass(cn.com.zjf.MR_04.Car1.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(Text.class);
job.setMapOutputKeyClass(CarOrder.class);
job.setMapOutputValueClass(Text.class);
job.setMapperClass(CarMap.class);
job.setReducerClass(OutputByCarPlate.class);
// 組合鍵的排序規則
//job.setSortComparatorClass(ResultComparator.class);
// 自定義分割槽
job.setPartitionerClass(CarPartitioner.class);
// 自定義比較器-->二次排序的依據
job.setGroupingComparatorClass(CarComparator.class);
FileSystem fs = FileSystem.get(conf);
Path input = new Path(args[0]);
/**
* 預處理檔案 .只讀取寫完畢的檔案 .writed結尾 .只讀取檔案大小大於0的檔案
*/
{
FileStatus childs[] =fs.globStatus(input, new PathFilter() {
public booleanaccept(Path path) {
if(path.toString().endsWith(".writed")) {
returntrue;
}
returnfalse;
}
});
Path temp = null;
for (FileStatus file :childs) {
temp = newPath(file.getPath().toString().replaceAll(".writed", ""));
if (fs.listStatus(temp)[0].getLen()> 0) {
CombineTextInputFormat.addInputPath(job,temp);
}
}
}
CombineTextInputFormat.setMaxInputSplitSize(job,67108864);
Path output = new Path(args[1]);
if (fs.exists(output)) {
fs.delete(output, true);
}
FileOutputFormat.setOutputPath(job,output);
if (!job.waitForCompletion(true))
return;
}
}相關推薦
Hadoop 二次排序實現
業務場景:通常情況下,在MR操作中到達Reduce中的key值都是按照指定的規則進行排序,在單一key的情況下一切都進行的很自然,直到我們要求資料不再單純的按key進行排序,以如下資料舉例: Key -> value: 100 -> 2
hadoop二次排序實現join
package join; import java.io.DataInput; import java.io.DataOutput; import java.io.IOException; import java.util.Iterator; import org.apac
一起學Hadoop——二次排序演算法的實現
二次排序,從字面上可以理解為在對key排序的基礎上對key所對應的值value排序,也叫輔助排序。一般情況下,MapReduce框架只對key排序,而不對key所對應的值排序,因此value的排序經常是不固定的。但是我們經常會遇到同時對key和value排序的需求,例如Hadoop權威指南中的求一年的高高氣溫
hadoop 二次排序和一個java實現
需要二次排序的原因:mapreduce架構自動對對映器生成的鍵進行排序,即歸約器啟動之前,所有鍵是有序的,但是值是隨機的,二次排序指的是對值進行排序。歸約器輸入形如:,即一個key對應多個值,這些值是無序的,排序後得到有序的值,如下: 其中,S按照升序或者降序排列
hadoop二次排序的原理和實現
預設情況下,Map輸出的結果會對Key進行預設的排序,但是有時候需要對Key排序的同時還需要對Value進行排序,這時候就要用到二次排序了。下面我們來說說二次排序 1、二次排序原理 我們把二次排序分為以下幾個階段 Map起始階段 在Map階段,使用jo
hadoop 二次排序的一些思考
先說一下mr的二次排序需求: 假如檔案有兩列分別為name、score,需求是先按照name排序,name相同按照score排序 資料如下: jx 20 gj 30 jx 10 gj 15 輸出結果要求: gj 15 gj 30 jx 10 jx 20 我們常見的實現思路是: 1. 自
hadoop二次排序 (Map/Reduce中分割槽和分組的問題)
1.二次排序概念:首先按照第一欄位排序,然後再對第一欄位相同的行按照第二欄位排序,注意不能破壞第一次排序的結果 。如: 輸入檔案:20 21 50 51 50 52 50 53 50 54 60 51 60 53 60 52 60 56 60 57 70 58 60 61 70 54 70 55 70 56
hadoop二次排序
趁這個時候,順便把hadoop的用於比較的Writable, WritableComparable, Comprator等搞清楚。。 1.二次排序概念: 首先按照第一欄位排序,然後再對第一欄位相同的行按照第二欄位排序,注意不能破壞第一次排序的結果 。 如: 輸入檔案: 20 21 50 51
Hadoop二次排序及MapReduce處理流程例項詳解
一、概述 MapReduce框架對處理結果的輸出會根據key值進行預設的排序,這個預設排序可以滿足一部分需求,但是也是十分有限的,在我們實際的需求當中,往往有要對reduce輸出結果進行二次排序的需求。對於二次排序的實現,網路上已經有很多人分享過了,但是對二次排序的實現原理
Hadoop 二次排序 Secondary Sort
mr自帶的例子中的原始碼SecondarySort,我重新寫了一下,基本沒變。 這個例子中定義的map和reduce如下,關鍵是它對輸入輸出型別的定義:(java泛型程式設計) public static class Map extends Mapp
Hadoop MapReduce二次排序演算法與實現之演算法解析
MapReduce二次排序的原理 1.在Mapper階段,會通過inputFormat的getSplits來把資料集分割成split public abstract class Input
Python Hadoop Mapreduce 實現Hadoop Streaming分組和二次排序
需求:公司給到一份全國各門店銷售資料,要求:1.按門店市場分類,將同一市場的門店放到一起;2.將各家門店按銷售額從大到小,再按利潤從大到小排列 一 需求一:按市場對門店進行分組 分組(partition) Hadoop streaming框架預設情況下會以’/t
Hadoop和Spark分別實現二次排序
將下列資料中每個分割槽中的第一列順序排列,第二列倒序排列。 Text 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 2021 5051
分別使用Hadoop和Spark實現二次排序
零、序(注意本部分與標題無太大關係,可直接翻到第一部分) 既然沒用為啥會有序?原因不想再開一篇文章,來抒發點什麼感想或者計劃了,就在這裡寫點好了: 前些日子買了幾本書,打算學習和研究大資料方面的知識,一直因為實習、考試、畢業設計等問題搞得沒有時間,現在進入了寒
大資料技術學習筆記之Hadoop框架基礎5-Hadoop高階特性HA及二次排序思想
一、回顧 -》shuffle流程 -》input:讀取mapreduce輸入的 &nbs
結合案例講解MapReduce重要知識點 ------- 使用自定義MapReduce資料型別實現二次排序
自定義資料型別SSData import java.io.DataInput; import java.io.DataOutput; import java.io.IOException; import org.apache.hadoop.io.WritableCompa
hadoop MR 二次排序
二次排序 例如這樣一組氣溫資料 年份 溫度 2006 -20 2006 21 2007 55 2007 16 2007 33 經過reduce處理年份會自動排序 但是如果要對年份和氣溫分別排序那就需要二次排序了 例如年份升序對氣溫降序 2006 21 200
43.top10熱門品類之使用Scala實現二次排序
本文為《Spark大型電商專案實戰》 系列文章之一,主要介紹使用Scala實現二次排序。 程式碼實現 在Scala IDE中的包com.erik.sparkproject中建立SortKey.sca
《資料演算法-Hadoop/Spark大資料處理技巧》讀書筆記(一)——二次排序
寫在前面: 在做直播的時候有同學問Spark不是用Scala語言作為開發語言麼,的確是的,從網上查資料的話也會看到大把大把的用Scala編寫的Spark程式,但是仔細看就會發現這些用Scala寫的文章
Hadoop Mapreduce分割槽、分組、二次排序過程詳解[轉]
徐海蛟 教學用途 1、MapReduce中資料流動 (1)最簡單的過程: map - reduce (2)定製了partitioner以將map的結果送往指定reducer的過程: map - partition - reduce (3)增加了在本地先進性一次reduce(優化)過程: