
連結串列--一些演算法的總結
1、連結串列的定義、建立、插入、查詢、刪除:
#include<stdio.h>
#include<stdlib.h>
//連結串列的定義//
struct node{
int data; //資料域
node *next; //指標域,只想下一個元素
};
//連結串列的建立//
node* creatlist(int arr[],int len){ //建立連結串列
node*head,*pre,*p;
head=new node; //創造頭結點
head->next=NULL;
pre=head; //pre 2、兩個單鏈表的第一個公共結點。
方法1:粗暴的辦法。
從一個連結串列的第一個結點開始,再另一個連結串列上查詢是否是交點(指向結點的指標一樣),這樣的話,如果一個連結串列的長度是m,另一個連結串列的長度是n,則時間複雜度是O(mn)。
方法2:從後往前遍歷
我們知道連結串列相交,不僅僅只是結點裡的data值一樣,next指標也是一樣的,也就是說,如果兩個連結串列從某一個結點處開始相交,那麼之後兩個連結串列一定是相交的。即就是,連結串列的相交模型不會是X型,而是Y型。所以我們可以從後向前找第一個交點,但是這裡是單鏈表,只能從後向前遍歷,所以這裡採用資料結構stack,將結點的資訊儲存在棧中,從棧頂開始比較兩個結點,如果不一樣,則就說明不相交,如果一樣,記住當前結點,將兩個棧的棧頂元素出棧,繼續比較下一個結點,就這樣,直到找到不一樣的結點,那麼上一個結點就是第一個公共結點。但是這種辦法需要兩個輔助棧,不是最好的辦法
方法3:快慢指標法
求出兩個連結串列的長度,讓長的連結串列先走兩個連結串列長度之差的絕對值步,然後兩個連結串列一起走,直到找到第一個公共結點。這就是所謂的快慢指標法。
方法4:通過環來看
如果兩個單鏈表相交,將連結串列的尾和其中任何一個連結串列的頭相接,就會構成一個環,求出環的入口就是連個連結串列的第一個公共結點;如果連結串列不相交,就不會構成環。判斷連結串列相不相交的辦法,就是直接看他們的最後一個結點是否一樣。這種辦法之後的文章(判斷連結串列是否帶環以及環的入口)會實現,這裡暫時不實現。
程式碼實現(包括測試程式碼):
#include<iostream>
using namespace std;
//連結串列結點的定義//
struct ListNode
{
int _data;
ListNode* _pNext;
ListNode(int x = 0):_data(x),_pNext(NULL){}
};
//連結串列的建立//
ListNode* Create(int arr[],int n)
{
ListNode* head = new ListNode(arr[0]);
ListNode* prev = head;
ListNode* cur = prev;
for(int i = 1; i < n; ++i)
{
cur = new ListNode(arr[i]);
prev->_pNext = cur;
prev = cur;
}
return head;
}
//獲取連結串列的長度//
size_t GetLength(ListNode* head)
{
size_t len = 0;
ListNode* cur = head;
while(cur)
{
++len;
cur = cur->_pNext;
}
return len;
}
//獲取連個連結串列的第一的相交點//
ListNode* GetFirstCommonNode(ListNode* head1,ListNode* head2)
{
size_t len1 = GetLength(head1);
size_t len2 = GetLength(head2);
ListNode* pLong = head1;
ListNode* pShort = head2;
int diff = len1 - len2;
if(diff < 0)//第一個連結串列比第二個連結串列短
{
pLong = head2;
pShort = head1;
diff = len2 - len1;
}
//讓長的連結串列先走diff步
for(int i = 0; i < diff; ++i)
{
pLong = pLong->_pNext;
}
//兩個連結串列一起向後走找第一個交點
while(pLong != NULL && pShort != NULL && pLong != pShort)
{
pLong = pLong->_pNext;
pShort = pShort->_pNext;
}
if(pLong && pShort == 0)//沒有找到公共結點
return NULL;
else
return pShort;
}
//連結串列的銷燬//
void Destroy(ListNode* head)
{
ListNode* cur = head;
ListNode* del = NULL;
while(cur)
{
del = cur;
cur = cur->_pNext;
delete del;
}
}
//連結串列的查詢//
ListNode* FindNode(ListNode* head,int data)
{
ListNode* cur = head;
while(cur)
{
if(cur->_data == data)
return cur;
cur = cur->_pNext;
}
return NULL;
}
//主函式//
int main()
{
int arr1[] = {3,4,5,6,7,8};
int arr2[] = {8,7};
//建立連結串列
ListNode* head1 = Create(arr1,sizeof(arr1)/sizeof(arr1[0]));
ListNode* head2 = Create(arr2,sizeof(arr2)/sizeof(arr2[0]));
//創造交點
ListNode* Node1 = FindNode(head1,6);
ListNode* Node2 = FindNode(head2,7);
Node2->_pNext = Node1;
ListNode* ret = GetFirstCommonNode(head1,head2);
if(ret)
cout<<"交點的值是:"<<ret->_data <<endl;
else
cout<<"沒有交點"<<endl;
Destroy(head1);
Node2->_pNext = NULL;
Destroy(head2);
system("pause");
return 0;
}
3、一個單鏈表的環入口
struct Node
{
int _data;
Node* _pNext;
Node(int x=0):_data(x),_pNext(NULL){}
};
Node *getLoopEntrance(Node *head)
{
Node *slow = head, *fast = head;
while (fast && fast->next)
{
slow = slow->next;
fast = fast->next->next; //走兩步
if (slow == fast)
{
break;
}
}
if (fast == NULL || fast->next == NULL)
{
return NULL;
}
fast = head; //從頭開始走了
while (slow != fast)
{
slow = slow->next;
fast = fast->next; //走一步
}
return fast;
} 解法如下:設定fast和slow兩個指標,初始都指向head。然後讓fast每次走2步,slow每次走一步,如果發現fast和slow重合,則確定單向連結串列有環路了。接下來,讓fast回到連結串列的頭部,重新走,每次步長不是走2步了,而是走1步,那麼當fast和slow再次相遇的結點,就是環路的入口位置了。
證明:當fast和slow第一次相遇的時候,slow肯定沒有遍歷完一次連結串列或剛好遍歷完一次連結串列,而fast已經在環內迴圈了n圈(n>=1)。這時,假設slow走了i個結點,則fast走了2i個結點,再假設環長為C,則
2i = i + nC => i = nC
設連結串列長度為L,連結串列起點距環入口的距離為j,環入口距相遇點的距離為k,則
j + k = i = nC
j + k = (n - 1)C + C = (n - 1)C + (L - j)
j = (n - 1)C + (L - j - k)
(L - j - k)同k一樣,同樣為環入口點距相遇點的距離。也就是說,從連結串列起點到環入口點的距離等於(n - 1)環長+相遇點到入口點的距離。於是,從連結串列起點、相遇點分別設一指標,每次各走一步,則兩指標必定相遇,且第一個相遇點即為環入口點。

4、單鏈表的反轉
迭代是從前往後依次處理,直到迴圈到鏈尾;而遞迴恰恰相反,首先一直迭代到鏈尾也就是遞迴基判斷的準則,然後再逐層返回處理到開頭。總結來說,連結串列翻轉操作的順序對於迭代來說是從鏈頭往鏈尾,而對於遞迴是從鏈尾往鏈頭。
非遞迴(迭代)方式
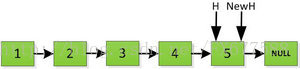
迭代的方式是從鏈頭開始處理,如下圖給定一個存放5個數的連結串列。
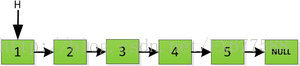
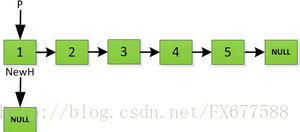
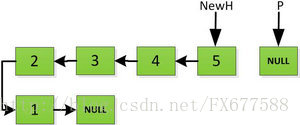
然後依次將舊連結串列上每一項新增在新連結串列的後面,然後新連結串列的頭指標NewH移向新的連結串列頭,如下圖所示。此處需要注意,不可以上來立即將上圖中P->next直接指向NewH,這樣存放2的地址就會被丟棄,後續連結串列儲存的資料也隨之無法訪問。而是應該設定一個臨時指標tmp,先暫時指向P->next指向的地址空間,儲存原連結串列後續資料。然後再讓P->next指向NewH,最後P=tmp就可以取回原連結串列的資料了,所有迴圈訪問也可以繼續展開下去。
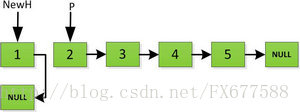
指標繼續向後移動,直到P指標指向NULL停止迭代。
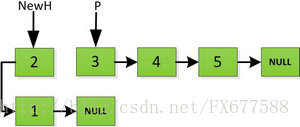
最後一步:
node* reverseList(node* H)
{
if (H == NULL || H->next == NULL) //連結串列為空或者僅1個數直接返回
return H;
node* p = H, *newH = NULL;
while (p != NULL) //一直迭代到鏈尾
{
node* tmp = p->next; //暫存p下一個地址,防止變化指標指向後找不到後續的數
p->next = newH; //p->next指向前一個空間
newH = p; //新連結串列的頭移動到p,擴長一步連結串列
p = tmp; //p指向原始連結串列p指向的下一個空間
}
return遞迴方式
我們再來看看遞迴實現連結串列翻轉的實現,前面非遞迴方式是從前面數1開始往後依次處理,而遞迴方式則恰恰相反,它先迴圈找到最後面指向的數5,然後從5開始處理依次翻轉整個連結串列。
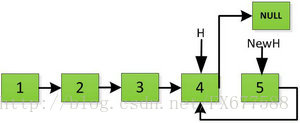
首先指標H迭代到底如下圖所示,並且設定一個新的指標作為翻轉後的連結串列的頭。由於整個連結串列翻轉之後的頭就是最後一個數,所以整個過程NewH指標一直指向存放5的地址空間。
然後H指標逐層返回的時候依次做下圖的處理,將H指向的地址賦值給H->next->next指標,並且一定要記得讓H->next =NULL,也就是斷開現在指標的連結,否則新的連結串列形成了環,下一層H->next->next賦值的時候會覆蓋後續的值。
繼續返回操作:
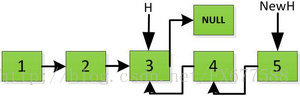
上圖第一次如果沒有將存放4空間的next指標賦值指向NULL,第二次H->next->next=H,就會將存放5的地址空間覆蓋為3,這樣連結串列一切都大亂了。接著逐層返回下去,直到對存放1的地址空間處理。
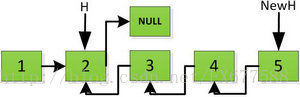
返回到頭:
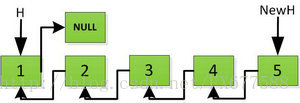
迭代實現的程式
node* In_reverseList(node* H)
{
if (H == NULL || H->next == NULL) //連結串列為空直接返回,而H->next為空是遞迴基
return H;
node* newHead = In_reverseList(H->next); //一直迴圈到鏈尾
H->next->next = H; //翻轉連結串列的指向
H->next = NULL; //記得賦值NULL,防止連結串列錯亂
return newHead; //新連結串列頭永遠指向的是原連結串列的鏈尾
完整程式#include<iostream>
using namespace std;
struct node{
int val;
struct node* next;
node(int x) :val(x){}
};
/***非遞迴方式***/
node* reverseList(node* H)
{
if (H == NULL || H->next == NULL) //連結串列為空或者僅1個數直接返回
return H;
node* p = H, *newH = NULL;
while (p != NULL) //一直迭代到鏈尾
{
node* tmp = p->next; //暫存p下一個地址,防止變化指標指向後找不到後續的數
p->next = newH; //p->next指向前一個空間
newH = p; //新連結串列的頭移動到p,擴長一步連結串列
p = tmp; //p指向原始連結串列p指向的下一個空間
}
return newH;
}
/***遞迴方式***/
node* In_reverseList(node* H)
{
if (H == NULL || H->next == NULL) //連結串列為空直接返回,而H->next為空是遞迴基
return H;
node* newHead = In_reverseList(H->next); //一直迴圈到鏈尾
H->next->next = H; //翻轉連結串列的指向
H->next = NULL; //記得賦值NULL,防止連結串列錯亂
return newHead; //新連結串列頭永遠指向的是原連結串列的鏈尾
}
int main()
{
node* first = new node(1);
node* second = new node(2);
node* third = new node(3);
node* forth = new node(4);
node* fifth = new node(5);
first->next = second;
second->next = third;
third->next = forth;
forth->next = fifth;
fifth->next = NULL;
//非遞迴實現
node* H1 = first;
H1 = reverseList(H1); //翻轉
//遞迴實現
node* H2 = H1; //請在此設定斷點檢視H1變化,否則H2再翻轉,H1已經發生變化
H2 = In_reverseList(H2); //再翻轉
return 0;
}5、反轉連結串列中偶數位節點,要求空間O(1)時間O(n)
相關推薦
連結串列--一些演算法的總結
1、連結串列的定義、建立、插入、查詢、刪除:#include<stdio.h> #include<stdlib.h> //連結串列的定義// struct node{ int data; //資料域 node *nex
資料結構——反轉連結串列的演算法實現
記錄一下連結串列的操作 這是曾經一道面試題 連結串列的考察更側重於程式碼的書寫和思路的形成。雖然說,連結串列的結構簡單,但是涉及到指標的操作,容易引申出一些挑戰性的考題,其中也牽涉到諸多小的細節的考慮,更能看出程式碼書寫的能力和功底。 廢話不多說上圖分析加程式碼
連結串列相關演算法
將兩個有序連結串列合併為一個新的有序連結串列並返回。新連結串列是通過拼接給定的兩個連結串列的所有節點組成的。 示例: 輸入:1->2->4, 1->3->4 輸出:1->1->2->3->4->4 /** * De
C++ 迴圈連結串列基本演算法
C++ 迴圈連結串列基本演算法 #ifndef CLinkList_h #define CLinkList_h #include <iostream> using namespace std; template <class T> struct Node{ T data
C++ 靜態連結串列基本演算法實現
C++ 靜態連結串列基本演算法實現 #ifndef StaticLinkList_h #define StaticLinkList_h const int MAXSIZE = 100; template <class T> struct StaticNode{ T data;
建立雙向連結串列的演算法——C語言實現
建立雙向連結串列的演算法——C語言實現 雙向連結串列也叫雙鏈表,是連結串列的一種,它的每個節點包含兩個指標,分別指向直接後繼和直接前驅(頭節點的前驅指空,尾節點的後繼指空)。所以,從雙向連結串列中的任意一個非前驅非後繼節點開始,都能很方便地訪問它的前驅和後繼節點。 實際上如果熟練掌握了單向連
連結串列排序演算法java實現(連結串列的快速排序、插入排序、歸併排序)
難易程度:★★ 重要性:★★★ 連結串列的排序相對陣列的排序更為複雜些,也是考察求職者是否真正理解了排序演算法(而不是“死記硬背”) 連結串列的插入排序 public class LinkedInsertSort { static cla
反轉連結串列的演算法實現
題目:定義一個函式,輸入一個連結串列的頭結點,反轉該連結串列並輸出反轉後連結串列的頭結點。 下面給出了連結串列結點的定義: struct ListNode { int val; stru
連結串列基礎知識總結--
連結串列和陣列作為演算法中的兩個基本資料結構,在程式設計過程中經常用到。儘管兩種結構都可以用來儲存一系列的資料,但又各有各的特點。陣列的優勢,在於可以方便的遍歷查詢需要的資料。在查詢陣列指定位置(如查詢陣列中的第4個數據)的操作中,只需要進行1次操作即可,時間複雜度為O(1)
連結串列常用演算法
1.刪除指定節點 /** * Definition for singly-linked list. * struct ListNode { * int val; * ListNode *next; * ListNode(int x) : val(x), next(N
幾種連結串列排序演算法的JAVA實現
插入排序 首先解釋一下一個概念叫做:前繼節點,即我們要的節點的前一個節點。我當時寫這個演算法的時候一直在猶豫的一點在於我怎麼儲存下個節點的狀態,因為在單向連結串列中的必須要儲存下個節點的狀態才能對當前節點進行操作,而另外一點是我應該怎麼樣利用當前的值和前一個值比較。這是我在做
有關連結串列一些基礎小知識
對連結串列的操作主要有以下幾種:建立連結串列,結構體的查詢與輸出,插入一個節點,刪除一個節點等 下面就一個典型的例子,談談連結串列的建立. #include<stdio.h> #include<stdlib.h> struct node { int num,sc
靜態連結串列相關演算法學習
大話資料結構學習筆記—靜態連結串列學習 c語言真是好東西,它具有指標能力,使得它可以非常容易地操作記憶體中的地址和資料,這比其他高階語言更加靈活方便。 後來的面向物件的語言,如java、C#等,雖然不使用指標,但是因為啟用了物件引用機制,從某種角度也間接實現了指標的 某些作
Python實現LeetCode連結串列類演算法(例子:Merge k Sorted Lists)
連結串列的演算法關鍵點:新建立一個頭結點,並且將這個節點賦值給另外的連結串列物件來完成操作。 例如19. Remove Nth Node From End of List class Soluti
連結串列面試題總結 C/C++
資料結構和演算法,是我們程式設計最重要的兩大元素,可以說,我們的程式設計,都是在選擇和設計合適的資料結構來存放資料,然後再用合適的演算法來處理這些資料。 在面試中,最經常被提及的就是連結串列,因為它簡單,但又因為需要對指標進行操作,凡是涉及到指標的,都需要我
連結串列問題歸納總結--C和C++
1.單鏈表的建立、測長以及列印 struct Node { int data; Node *next; }; Node *CreatList() { int data; Node *head, *p, *s = NULL;
連結串列經典演算法題實現
本文包含連結串列的以下內容: 1、單鏈表的建立和遍歷 2、求單鏈表中節點的個數 3、查詢單鏈表中的倒數第k個結點(劍指offer,題15) 4、查詢單鏈表中的中間結點 5、合併兩個有序的單鏈表,合併之後的連結串列依然有序【出現頻率高】(劍指o
【郝斌資料結構自學筆記】26_通過連結串列排序演算法的演示再次詳細討論到底什麼是演算法以及到底什麼是泛型【重點】
26_通過連結串列排序演算法的演示再次詳細討論到底什麼是演算法以及到底什麼是泛型【重點】 演算法: 狹義的演算法是與資料的儲存方式密切相關 廣義的演算法是與資料的儲存方式無關 泛型: 利用某種技術達到的效果就是:不同的儲存方式,執行的操作是一樣的 #include<
資料結構之連結串列基本操作總結
題意: 如何找到環的第一個節點? 分析: 1)先判斷是否存在環 使用兩個指標slow,fast。兩個指標都從表頭開始走,slow每次走一步,fast每次走兩步,如果fast遇到null,則說明沒有環,返回false;如果slow==fast,說明有環,並且此時fast超了s
Java中連結串列相關演算法
如下為連結節點,後續都用此表示連結節點 class ListNode{ int value; ListNode next; public ListN