
聊聊JVM(一)相對全面的GC總結
最近時間比較緊張,要寫的東西也有很多,只能想到一點寫一點。關於GC,網上的資料太多,之前對一個系統調優的時候又回顧了一下,找了幾篇廣泛流傳的資料,大部分都是大同小異,這裡總個總結,希望能夠做個相對的全集,並寫出一些新的點,比如Card Marking(卡片標記)等。
首先是大家都要提到的GC的基礎演算法:標記清除,標記整理,複製,分代。這些演算法的第一步都是做的一件事: 標記(Mark)。
JVM的標記演算法採用了根搜尋演算法(Root Tracing)。根有幾種:
1. JVM棧的Frame裡面的引用
2. 靜態類,常量的引用
3. 本地棧中的引用
4. 本地方法的引用
一般我們能控制的就是JVM棧中的引用和靜態類,常量的引用。標記也分為幾個階段,比如
1. 標記直接和根引用的物件
2. 標記間接和根引用的物件
3. 由於分代演算法,被老年代物件所引用的新生代的物件
對於第三種,JVM採用了Card Marking(卡片標記)的方法,避免了在做Minor GC時需要對整個老年代掃描。具體的方法如下:
1. 將老年代的記憶體分片,1個片預設是512byte
2. 如果老年代的物件發生了修改,就把這個老年代物件所在的片標記為髒 dirty。或者老年代物件指向了新生代物件,那麼它所在的片也會被標記為dirty
3. 沒有標記為髒的老年代片它沒有指向新的新生代物件,所以可以不需要去掃描
4. Minor GC掃描老年代空間時,只需要去掃描髒的卡片的物件,不需要掃描整個老年代空間

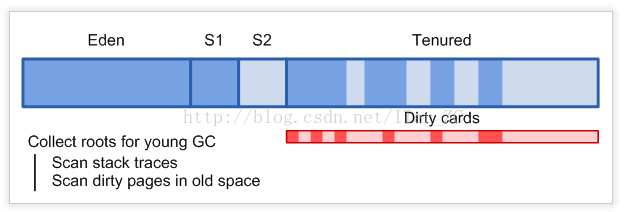
所以做Minor GC時標記的時間 = T(stack_scan) + T(card_scan) + T(old_root_scan).
T(stack_scan): 級聯掃描在JVM棧裡的根的時間
T(card_scan): 級聯掃描卡表中髒卡片的時間
T(old_root_scan): 掃描在老年代中的直接的根的時間。注意是直接的根,不會去級聯掃描老年代的物件。因為掃描都是從根開始的,一開始不知道根到底是在老年代還是新生代
和Card Marking相關的一個重要的JVM引數是-XX:UseCondCardMark 。使用這個引數的原因是在高併發的情況下,Card標記為髒的操作本身就存在著競爭,使用這個引數可以避免卡片被重複標記為髒,從而提高效能。
說完了標記,下面提一下幾種基礎的GC演算法,沒有什麼新的點,直接引用網上的圖
標記-清除演算法

複製演算法

標記--整理演算法

分代演算法是將物件分為新生代和老年代,然後使用不同的GC策略來進行回收,提高整體的效率。
由於新生代的大部分物件都會在一次Minor GC中死亡,存活的物件很少,所以新生代的GC收集器都採用了複製演算法。新生代分為Eden + S0 + S1. S0和S1就是用來實現複製的,在任何一次Minor GC後,S0和S1總是隻有一個區域有資料,另一個區域為空,以便於下一次複製使用
當新生代空間不能滿足大物件分配時,老年代空間為它提供了分配擔保,大物件可以直接進入老年代。有兩個JVM引數可以控制新生代進入老年代的門檻:
PretenureSizeThreshold: 單位是B,設定了物件大小的閥值
MaxTenuringThreshold: 設定了進入老年代的年齡的閥值
老年代物件一般都是存活時間久,老年代的空間本來就大,所以沒有更多空間來提供分配擔保,所以老年代一般採用標記--清理或者標記--整理演算法。
下面這張圖很好地介紹了JDK6的各種GC收集器以及各自的特點:
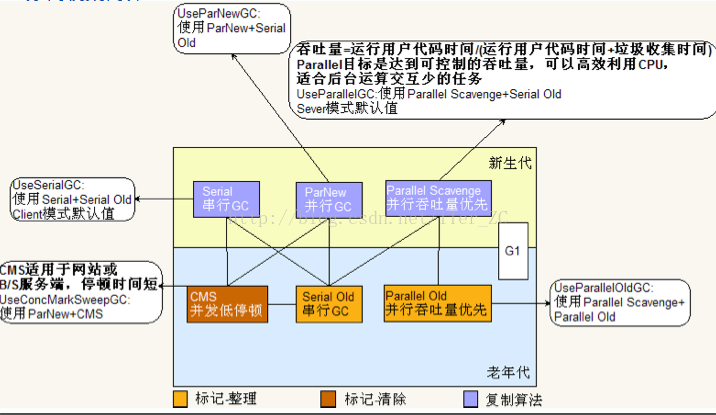
1. 新生代都採用複製演算法
2. CMS採用了標記--清除演算法,由於標記清除演算法會生成記憶體碎片,所以JVM提供了引數來使CMS可以在幾次清除後作一次整理
-XX:CMSFullGCsBeforeCompaction:由於併發收集器不對記憶體空間進行壓縮、整理,所以執行一段時間以後會產生“碎片”,使得執行效率降低。此值設定執行多少次GC以後對記憶體空間進行壓縮、整理。
-XX:+UseCMSCompactAtFullCollection:開啟對年老代的壓縮。可能會影響效能,但是可以消除碎片
3. Serial Old(MSC)和Parallel Old都採用標記整理演算法
4. UseSerialGC預設會在新生代使用Serial收集器,在老年代使用Serial Old收集器,這兩個都是單執行緒的收集器
5. UseConcMarkSweepGC預設會再新生代使用ParNew收集器,這是個併發的收集器。在老年代會使用CMS + Serial Old收集器,當CMS失敗的時候,會啟用Serial Old做FULL GC
6. UseParallelOldGC預設會在新生的使用Parallel Scavenge收集器,在老年代使用Parallel Old收集器。這兩個收集器都是吞吐量優先,所謂吞吐量優先就是它可以嚴格控制GC的時間,從而保證吞吐量。但是吞吐量提高了,新生代和老年代的空間就是動態調整的,而不是按照初始配置的大小。因為單位時間清除的垃圾量近乎一個常量,既然要保證時間,那麼必須保證垃圾總量,而垃圾總量可以通過新生代和老年代的大小來控制的
7. 對於和使用者有互動的應用,比如Web應用,一個重要的考量是系統的響應時間,要保證系統的響應時間就要保證由GC導致的stop the world次數少,或者讓使用者執行緒和GC執行緒一起執行。所以Web應用是使用CMS收集器的一個重要場景。CMS減少了stop the world的次數,不可避免地讓整體GC的時間拉長了。
8. 對於計算密集型的應用可能會考慮計算的吞吐量,這時候可以使用Parallel Scavenge收集器來保證吞吐量
9. Serial, ParNew, Parallel Scanvange, Parallel Old, Serial Old全程都會Stop the world,JVM這時候只執行GC執行緒,不執行使用者執行緒
10. CMS主要分為 initial Mark, Concurrent Mark, ReMark, Concurrent Sweep等階段,initial Mark和Remark佔整體的時間比較較小,它們會Stop the world. Concurrent Mark和Concurrent Sweep會和使用者執行緒一起執行。
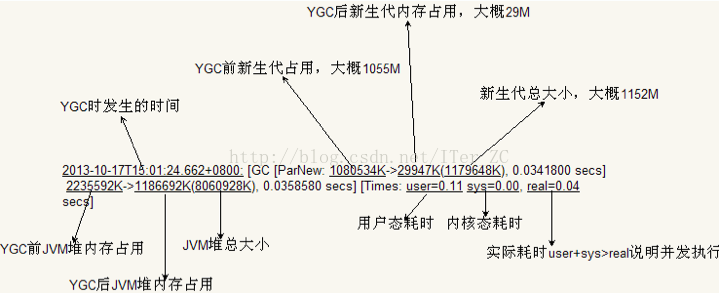
下面這張圖對GC的日誌資訊做了說明:
關於JVM調優的各種引數設定,網上一抓一大把,這裡不多說了。有一個調優的整體的原則:
1. 先做一個JVM的效能測試,瞭解當前的狀態
2. 明確調優的目標,比如減少FULL GC的次數,減少GC的總時間,提高吞吐量等
3. 調整引數後再進行多次的測試,分析,最終達到一個較為理想的狀態。各種引數要根據系統的自身情況來確定,沒有統一的解決方案
將各種工具的文章頁很多,這裡從解決問題的角度出發列出幾個。
檢視JVM啟動引數
1. jps -v
2. jinfo -flags pid
3. jinfo pid -- 列出JVM啟動引數和system.properties
4. ps -ef | grep java
檢視當前堆的配置
1. jstat -gc pid 1000 3 -- 列出堆的各個區域的大小
2. jstat -gcutil pid 1000 3 -- 列出堆的各個區域使用的比例
3. jmap -heap pid -- 列出當前使用的GC演算法,堆的各個區域大小
檢視執行緒的堆疊資訊
1. jstack -l pid
dump堆內的物件
1. jmap -dump:live,format=b,file=xxx pid
2. -XX:+HeapDumpOnOutOfMemoryError -XX:HeapDumpPath=xxx -- 設定JVM引數,當JVM OOM時輸出堆的dump
3. ulimit -c unlimited -- 設定Linux ulimit引數,可以產生coredump且不受大小限制。之前在線上遇到過一個極其詭異的問題,JVM整個程序突然掛了,這時候依靠JVM本身生成dump檔案已經不行了,只有依賴Linux,讓系統來生成程序掛掉的core dump檔案
使用jstack 可以來獲得這個coredump的執行緒堆疊資訊: jstack "$JAVA_HOME/bin/java" core.xxx > core.log
獲得當前系統佔用CPU最高的10個程序,執行緒
ps Hh -eo pid,tid,pcpu,pmem | sort -nk3 |tail > temp.txt
圖形化介面
1. jvisualvm 裡面有很多外掛,比如Visual GC,可以視覺化地看到各個堆區域時候的狀態,從而可以對整體GC的效能有整體的認識
就說到這吧,有遺漏的後面再補充
《深入理解JVM》
《Think in GC》
相關推薦
聊聊JVM(一)相對全面的GC總結(轉)
cor war 性能 依靠 blank 知識 flags 要去 內存空間 轉至:http://blog.csdn.net/iter_zc/article/details/41746265 最近時間比較緊張,要寫的東西也有很多,只能想到一點寫一點。關於GC,網上的資料太多,之
聊聊JVM(一)相對全面的GC總結
最近時間比較緊張,要寫的東西也有很多,只能想到一點寫一點。關於GC,網上的資料太多,之前對一個系統調優的時候又回顧了一下,找了幾篇廣泛流傳的資料,大部分都是大同小異,這裡總個總結,希望能夠做個相對的全集,並寫出一些新的點,比如Card Marking(卡片標記)等。 首先
聊聊JVM(四)深入理解Major GC, Full GC, CMS
很多人都分不清Major GC, Full GC的概念,事實上我查了下資料,也沒有查到非常精確的Major GC和Full GC的概念定義。分不清這兩個概念可能就會對這個問題疑惑:Full GC會引起Minor GC嗎? 經過一系列的查詢和對JVM表現的分析,基本可以給Fu
JVM(一)——GC,記憶體分配和垃圾回收
心得:Java中垃圾回收和記憶體可以實現高度的自動化,棧幀可以由JVM自動分配和回收,區域性變量表和運算元棧也可以在編譯時就確定好,堆中的記憶體分配和回收才是JVM關注的重點,JVM實現大多采用可達性分析來標記存活物件,什麼時候標記?讓使用者執行緒主動跑到那些安
JVM(一)運行機制
執行 vol defined 觀察 分配 bsp 寄存器 思考 區間 1.啟動流程 2.JVM基本結構 PC寄存器 》每個線程擁有一個PC寄存器 》在線程創建時創建 》指向下一條指令的地址 》執行本地方法時,PC的值為undefined 方法區 保存
JVM(一)JVM記憶體結構
Java程式碼需要執行在虛擬機器(JVM)上,而JVM為了方便管理記憶體,會把自己所管理的記憶體劃分為若干個不同的資料區域,用作不同的用途,先看一下大致劃分 堆 存放內容: ·大多數建立的物件 ·陣列值 GC情況:
深入理解JVM(一)——基本原理(掃盲篇)
前言 JVM一直是java知識裡面進階階段的重要部分,如果希望在java領域研究的更深入,則JVM則是如論如何也避開不了的話題,本系列試圖通過簡潔易讀的方式,講解JVM必要的知識點。 執行流程 我們都知道java一直宣傳的口號是:一次編譯,到處執行。那麼它如何實現的
深入理解JVM(一)——物件的建立
物件的建立 物件的建立,在語言層面上,通常只是new這個關鍵字而已。(本章所討論的物件限於普通Java物件,不包括陣列和 Class物件)虛擬機器遇到new指令時: 檢查這個指令的引數是否能在常量池定位到一個類的符號引用。 檢查這個符號引用代表的類是否已被載入,解析,初
深入理解JVM(一)——執行時的資料區域
Java與C++的圍牆:記憶體動態分配,垃圾收集技術 程式計數器 當前執行緒所執行的位元組碼的行號指示器,通過改變這個計數器的值來選擇下一條執行的位元組碼指令,分支,迴圈,跳轉,異常處理,執行緒恢復等依賴計數器。 執行緒私有,唯一不會OutOfMemory的區域。 執行Jav
JVM(一):JVM的執行時資料區
由於Java程式是交由JVM執行的,所以我們在談Java記憶體區域劃分的時候事實上是指JVM記憶體區域劃分。在討論JVM記憶體區域劃分之前,先來看一下Java程式具體執行的過程: 如上圖所示,首先Java原始碼檔案(.java字尾)會被Java編譯器編譯為位元組碼檔案(.class字尾),
聊聊併發(一)深入分析Volatile的實現原理
引言 在多執行緒併發程式設計中synchronized和Volatile都扮演著重要的角色,Volatile是輕量級的synchronized,它在多處理器開發中保證了共享變數的“可見性”。可見性的意思是當一個執行緒修改一個共享變數時,另外一個執行緒能讀到這個修改的值。它在某些情況下比syn
使用Spring Data Redis操作Redis(一) 很全面
Spring-Data-Redis專案(簡稱SDR)對Redis的Key-Value資料儲存操作提供了更高層次的抽象,類似於Spring Framework對JDBC支援一樣。 本文主要介紹Spring Data Redis的實際使用。 1.Spring Data
聊聊JVM(十)Mac下hsdis和jitwatch下載和使用
hsdis能夠檢視Java生成的彙編程式碼,具體的可以檢視上面這篇文章。這裡提供一下Mac下的hsdis-amd64.dylib和hsdis-amd64.so檔案的下載地址http://pan.baidu.com/s/1i3HxFDF 免得還要重新去編譯。前者是Mac
JVM(一)史上最佳入門指南
提到Java虛擬機器(JVM),可能大部分人的第一印象是“難”,但當讓我們真正走入“JVM世界”的時候,會發現其實問題並不像我們想象中的那麼複雜。唯一真正令我們恐懼的,其實是恐懼本身。而作為整個JVM系列的首篇,本文將帶你解除剛開始學習JVM時的種種疑惑。比如:什麼是JVM?為什麼學習JVM?怎麼有效的學習J
聊聊Dubbox(一):為何選擇
1. 前言 隨著現在網際網路行業的發展,越來越多的框架、中介軟體、容器等開源技術不斷地湧現,更好地來服務於業務,解決實現業務的問題。然而面對眾多的技術選擇,我們要如何甄別出適合自己團隊業務的技術呢?對於人來說,鞋子過大,可能影響奔跑的速度,鞋子過小,可能影響身體的成長。技術對於業務也是如此的關係。 所以,相
JVM(一):Run-Time Data Areas(執行時資料區)/ 記憶體區域
一:前言 特別說明:文章中引用的圖片是通過谷歌的方式找到的,當時並沒有找到圖片是否擁有版權,如果遇到了的話,請告知博主,我會將相應的圖片刪除。 本部落格主要總結的是JVM的Run Time Data Areas(執行時資料區),也就是我們常說的記憶體區域。借
【JVM】程式設計師進階JVM(一)——Java記憶體區域
一、前言 這篇部落格起,小編會向一個更加深層次、逼格滿滿的區域進發——JVM。 可以說JVM不是一個新鮮的東西,但是做java的都會了解JVM,都聽過JVM。有的時候我們寫的程式碼執行跟JVM也有關係。 二、JVM介紹
JVM(一)— 什麼是JVM
Java程式執行機制 計算機高階語言按程式的執行方式分為編譯型和解釋型兩種。 編譯器 計算機不能直接理解任何除機器語言以外的語言,所以必須要把程式設計師所寫的程式語言翻譯成機器語言,計算機才能執行程式。將其他語言翻譯成機器語言的工具,被稱為編譯器。 解釋
JVM(一):久識你名,初居我心
聊聊JVM JVM,一個熟悉又陌生的名詞,從認識Java的第一天起,我們就會聽到這個名字,在參加工作的前一兩年,面試的時候還會經常被問到JDK,JRE,JVM這三者的區別。 JVM可以說和我們是老朋友了,但是在工作中的應用場景也許不如那些框架,但是在關鍵時候還是得靠它去搞定問題,俗話說得好,知己知彼,方能百戰
玩命學JVM(一)—認識JVM和位元組碼檔案
**本篇文章的思維導圖**  ## 一、JVM的簡單介紹 ###1.1 JVM是什麼? JVM (java virtual machine),jav