
分析比較多表查詢中的IN與JOIN
IN 是子查詢的關鍵字,JOIN 是連線的關鍵字,專案開發中經常會使用到多表查詢,而子查詢與連線正是實現多表查詢的重要途徑。那兩者是怎麼執行的?IN與JOIN哪個更好?下面就來分析與比較。
現在有test1與test2兩張表,都沒有任何像主鍵,外來鍵那樣的約束,且只有一個欄位。兩張表是非相關的。
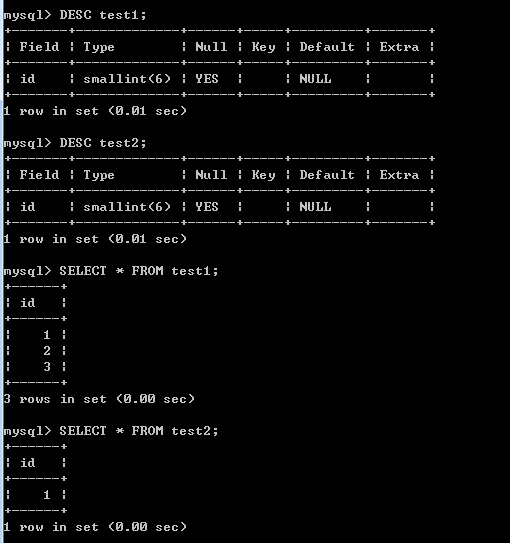
現在使用IN關鍵字實現子查詢,test2作為子查詢表(外部表):
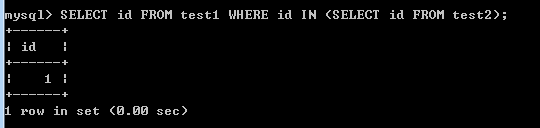
檢視執行計劃:
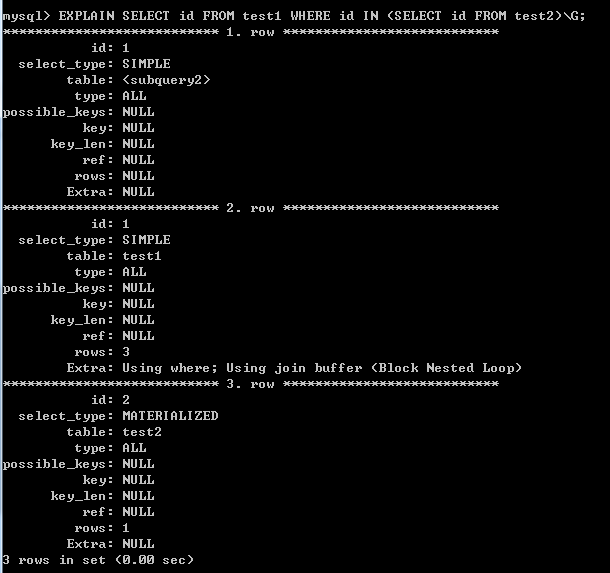
使用JOIN關鍵字實現連線,同樣test2作為外部表:

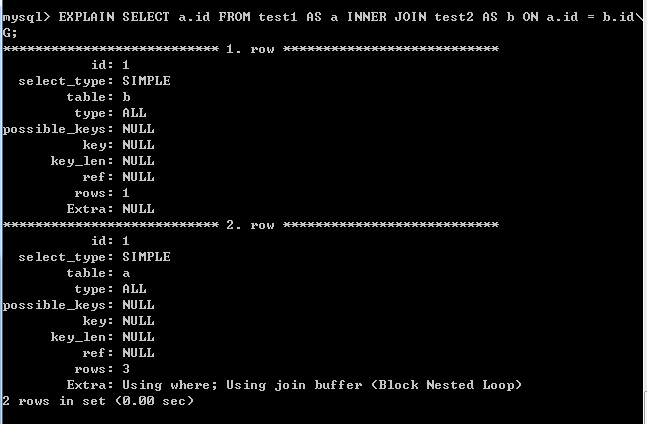
檢視執行計劃:
分析:
- 使用IN子查詢實現多表查詢時,從執行計劃可以看出,整個查詢分成3個部分,id = 1的查詢有兩個,id = 2的查詢有一個。id大的級別高,優先進行查詢。id = 2的查詢對應的是test2(子查詢表)的FTS。然後進行id = 1的查詢,同級別的查詢從上往下順序執行。計劃中顯示這個查詢是個子查詢(subquery),同時查詢test1的時候,使用到join buffer(Blocked Nested Loop),即連線緩衝(阻塞的巢狀迴圈)。
- 使用JOIN連線實現多表查詢時,先查詢test2表(外部表),幾乎與IN的方式一樣(FTS),再查詢test1表,也與IN的方式一樣,都用到了join buffer(Blocked Nested Loop)
- 總結一下,非相關(無索引)的多表查詢中,使用IN與JOIN的查詢都是先將外部表的查詢結果加入到連線緩衝區,再從內部表拿取資料進入緩衝區進行比較(巢狀迴圈)。查詢計劃幾乎沒有區別。但是,IN存在優先順序的關係,比JOIN多了一次subquery的查詢,在這種情況下,JOIN更優。
現在在test1表中新增主鍵(索引),在test2表中新增外來鍵約束(索引),兩張表是相關的。
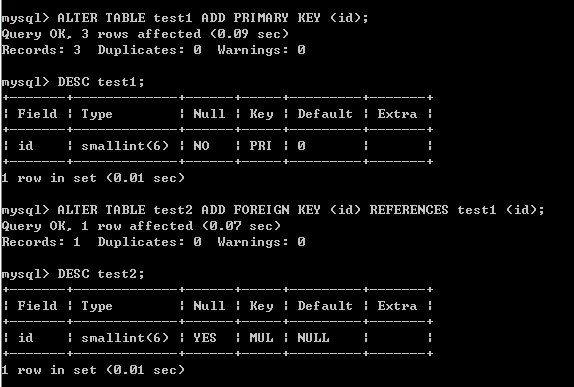
進行同樣的查詢,返回結果是一樣的:
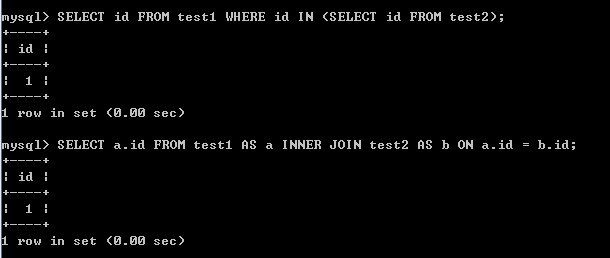
檢視IN方式的執行計劃:
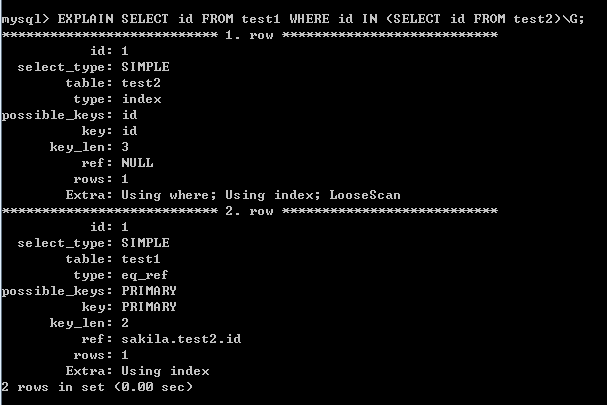
檢視JOIN方式的執行計劃:
分析:
- 現在使用IN方式進行查詢時,不再像非相關那樣顯示子查詢subquery了(若是子查詢會有不同的優先順序),而是有個參照的過程!先借助索引對外部表test2進行掃描;再借助索引對test1進行掃描,其中參照了test2的id列。
- 使用JOIN方式也是一樣有一個參照的過程!
- 這時兩種方式的查詢也沒有用到上面所說的連線緩衝區與阻塞巢狀迴圈。
- 總結一下,當兩張表相關(外來鍵相連)時,無論是IN還是JOIN,聯合查詢都是一個參照的過程。
寫到這裡,似乎IN與JOIN在表相關(邏輯外來鍵)的時候,並不知道哪個更優,下面就來實踐一下。
實際應用:
下面使用MySQL的示例資料庫sakila(customer表中有599個顧客資訊,主鍵為customer_id。rental表中有16044行資料,其中的主鍵為rental_id,外來鍵列customer_id參考customer表中的主鍵)分別執行IN與JOIN實現多表查詢:
IN查詢語句:SELECT CONCAT(first_name,last_name) FROM customer WHERE customer_id IN (SELECT customer_id FROM rental WHERE rental_id <=16000);
結果(返回了599條客戶名字資訊):
慢查詢日誌:
# Time: 160717 21:17:58
# [email protected]: root[root] @ localhost [127.0.0.1] Id: 17
# Query_time: 0.000000 Lock_time: 0.000000 Rows_sent: 599 Rows_examined: 1198
use sakila;
SET timestamp=1468761478;
SELECT CONCAT(first_name,last_name) FROM customer WHERE customer_id IN (SELECT customer_id FROM rental WHERE rental_id <=16000);
JOIN查詢語句:SELECT CONCAT(first_name,last_name) FROM customer AS a INNER JOIN rental AS b ON a.customer_id = b.customer_id WHERE rental_id<=16000;
結果(返回了15995行資料,發現裡面有很多重複的名字):
慢查詢日誌:
# Time: 160717 21:19:17
# [email protected]: root[root] @ localhost [127.0.0.1] Id: 18
# Query_time: 0.030000 Lock_time: 0.000000 Rows_sent: 15995 Rows_examined: 16643
SET timestamp=1468761557;
SELECT CONCAT(first_name,last_name) FROM customer AS a INNER JOIN rental AS b ON a.customer_id = b.customer_id WHERE rental_id<=16000;
使用DISTINCT關鍵字去重的JOIN查詢語句:SELECT DISTINCT CONCAT(first_name,last_name) FROM customer AS a INNER JOIN rental AS b ON a.customer_id = b.customer_id WHERE rental_id <=16000;
慢查詢日誌:
# Time: 160717 21:20:31
# [email protected]: root[root] @ localhost [127.0.0.1] Id: 19
# Query_time: 0.010000 Lock_time: 0.000000 Rows_sent: 599 Rows_examined: 1797
SET timestamp=1468761631;
SELECT DISTINCT CONCAT(first_name,last_name) FROM customer AS a INNER JOIN rental AS b ON a.customer_id = b.customer_id WHERE rental_id <=16000;
分析:
- 由於rental表的customer_id列作為外來鍵列,參照的是customer表的主鍵customer_id。因此在該查詢上兩張表是相關表。上面已經分析了這樣的IN與JOIN實現多表查詢就不存在連線緩衝與阻塞的巢狀迴圈。但都是通過參照的關係進行查詢。
- 通過比較查詢時間(SQL效率)與檢索行數(磁碟IO),在這種情況下我會選擇IN進行查詢。
相關推薦
分析比較多表查詢中的IN與JOIN
IN 是子查詢的關鍵字,JOIN 是連線的關鍵字,專案開發中經常會使用到多表查詢,而子查詢與連線正是實現多表查詢的重要途徑。那兩者是怎麼執行的?IN與JOIN哪個更好?下面就來分析與比較。 現在有test1與test2兩張表,都沒有任何像主鍵,外來鍵那樣的
多表查詢(內連線與外連線的混合使用)(union聯合)
內連線與外連線的混合使用: 格式:select*from表1 left other join 表2 on 條件 inner join 表3 on條件 查詢工資高於公司平均工資的所有員工列:顯示員工資訊,部門名稱,上級領導,工資等級 如下: SELECT
Oracle學習之路(二):oracle多表查詢+分組查詢+子查詢講解與案例分析+經典練習題
1.笛卡爾集和叉集 笛卡爾集會在下面條件下產生:省略連線條件、連線條件無效、所有表中的所有行互相連線。 為了避免笛卡爾集, 可以在 WHERE 加入有效的連線條件。在實際執行環境下,應避免使用全笛卡爾集。 使用CROSS JOIN 子句使連線的表產生叉集。叉集和笛卡
Hibernate中的HQL的基本常用小例子,單表查詢與多表查詢
<span style="font-size:24px;color:#3366ff;">本文章實現HQL的以下功能:</span> /** * hql語法: * 1)單表查詢 * 1.1 全表查詢 * 1.2 指定欄
MySQL 多表查詢實現分析
OS 是你 例子 dump table 多表查詢 一個 ont 由於 1、查看第一個表 mytable 的內容: mysql> select * from mytable; +----------+------+------------+-------
sql-多表查詢JOIN與分組GROUP BY
group 邊表 AS inner left join sdn AR full join ner 一、內部連接:兩個表的關系是平等的,可以從兩個表中獲取數據。用ON表示連接條件 SELECT A.a,B.b FROM At AS A INNER JOINT Bt AS B
oracle的多表查詢與表的連接
出現 png 部分 使用 結果 笛卡爾積 利用 信息 毫無 一、多表查詢 在任何多表查詢中一定會產生笛卡爾積的問題,但是,笛卡爾積產生的結果對於用戶來說是毫無意義的,是重復的無用數據。因此我們需要消除笛卡爾積,那麽在多表查詢的時候,就必須要有關聯字段。 範例
【java專案】mybatis中的mapper查詢時返回其他實體(多用於多表查詢)
<select id="selectUserorder" resultType="com.pojo.Orderdetail" parameterType="java.lang.Integer"> SELECT a.o_status, a.o_no, a.uid,
django之多表查詢與創建
紅樓夢 查找 手機 正向 地址 move *** () div https://www.cnblogs.com/liuqingzheng/articles/9499252.html # 一對多新增數據 添加一本北京出版社出版的書 第一種方式 re
Day055--MySQL--外來鍵的變種,表與表的關係,單表查詢,多表查詢, 內連線,左右連線,全外連線
表和表的關係 ---- 外來鍵的變種 * 一對多或多對一 多對多 一對一 如何找出兩張表之間的關係 分析步驟: #1、先站在左表的角度去找 是否左表的多條記錄可以對應右表的一條記錄,如果是,則證明左表的一個欄位foreign key 右表一個欄位(通常是id) #2、再站在右表的角度去找 是否右表
Mysql 索引 與 多表查詢效能優化
最近做專案需要用到Luence Whoosh,要定時從資料庫中索引出資料來供檢索,但是在索引中設計多表查詢,速度較慢,因為強迫症,想要做效能優化,因此把Mysql的核心又翻出來研究一遍。 關於MySQL索引的好處,如果正確合理設計並且使用索引的MySQL是一輛蘭博基尼的話,那麼
MySQL 多表查詢 學習與練習
字段 class 表連接 value 導入 數據 table 男女 強調 一、介紹 首先先準備表 員工表和部門表 #建表 create table department( id int, name varchar(20) ); create table employe
多表查詢、外來鍵、表與表之間的關係
外來鍵 通常在實際工作中,資料庫中表格都不是獨立存在的,且表與表之間是有種聯絡的,比如兩張表格,一張為分類表category,一張為商品表product。在分類表中有兩個資訊,cid、cname,商品表中有三個資料資訊pid、name、price。兩張表要想有著某種聯絡
Java面試題:Hibernate的二級快取與Hibernate多表查詢
我們來看兩個有關Java框架之Hibernate的面試題,這是關於Hibernate的常考知識點。 1、請介紹一下Hibernate的二級快取 解題按照以下思路來回答: (1)首先說清楚什麼是快取; (2)再說有了hibernate的Session就是一級快取,即有了一級快取,為什麼還要有二級快取;
MyBatis中實現多表查詢
一、 1、Mybatis是實現多表查詢方式 1.1 業務裝配:對兩個表編寫單表查詢語句,在業務(Service)把查詢的兩表結果合併 1.2 使用Auto Mapping 特性,在實現兩表聯合查詢時通過別名完成對映 1.3 使用MyBatis<re
SQL查詢中in和exists的區別分析
首先: select * from A where id in (select id from B); select * from A where exists (select 1 from B where A.id=B.id); 對於以上兩種情況,in是在記憶體裡遍
Hibernate的hql多表查詢取其中物件,in語句
場景: 我需要一個project物件,它關聯著一個工作附件attachment物件,中間有一個附件包的物件attachmentUnit,我要獲得沒有附件的project。 select p from project p , attachment a where **
MySQL 多表結構的建立與分析
=====================多對一===================== create table press( id int primary key auto_increment, name varchar(20) ); create table book( id
Oracle 多表查詢分析
這兩張表可以直接利用DEPTNO欄位關聯,所以需要利用WHERE欄位來消除笛卡爾積 以上查詢是之前基礎的加強,有明確的關聯欄位,可是很多的查詢是不會明確給出關聯欄位 例:要求查詢每個僱員的編號,姓名,職位,基本工資,工資等級 | - 確定要使用的資料表,
[資料庫]MySql單表多表查詢常用技巧(不斷更新中)
最近在給學校寫一個志願者管理系統,用到了一些資料庫的操作,由於在大二的時候沒有有強度的練習,所以寫一寫隨筆總結一些資料庫的程式設計查詢技巧。希望給大家提供一些幫助。 1.正則表示式 正則表示式完全可以使用正則表示式,支援字元匹配: 1.1:例如:查詢所有的2014級以及以上