
資料倉庫基礎介紹
前言
本文將會講述 BI/DW/DA 領域的一些常見概念,如:事實表、維度表、建模、多維分析、cube 等,但不涉及具體例項分析。
1、維(Dimension)
維是用於從不同角度描述事物特徵的,一般維都會有多層(Level:級別),每個Level都會包含一些共有的或特有的屬性(Attribute),可以用下圖來展示下維的結構和組成:
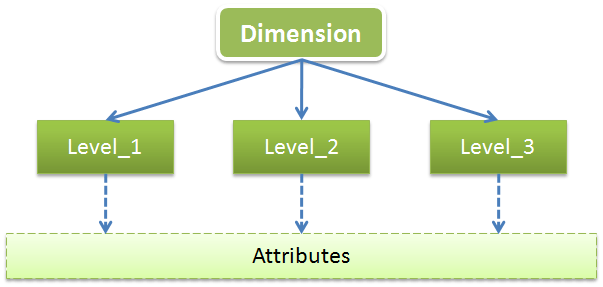
以時間維為例,時間維一般會包含年、季、月、日這幾個Level,每個Level一般都會有ID、NAME、DESCRIPTION這幾個公共屬性,這幾個公共屬性不僅適用於時間維,也同樣表現在其它各種不同型別的維。其中ID一般被視為代理主鍵(Agent),它只被用於作為唯一性標誌,並且是多維模型中關聯關係的代理者,在業務層面並不具有任何意義;NAME一般是業務主鍵(Business),在業務層面限制唯一性,一般作為資料裝載(Load)時的關聯鍵;而DESCRIPTION則記錄了詳細描述資訊,在多維展示和分析時我們都會選擇使用DESCRIPTION來表述具體含義。
多維資料模型是為了滿足使用者從多角度多層次進行資料查詢和分析的需要而建立起來的基於事實和維的資料庫模型,其基本的應用是為了實現OLAP(Online Analytical Processing)。
當然,通過多維資料模型的資料展示、查詢和獲取就是其作用的展現,但其真的作用的實現在於,通過資料倉庫可以根據不同的資料需求建立起各類多維模型,並組成資料集市開放給不同的使用者群體使用,也就是根據需求定製的各類資料商品擺放在資料集市中供不同的資料消費者進行採購。
2、Hierarchy 層次
因為上面這個結構的維是無法直接應用於OLAP的,我前面的文章有介紹,其實OLAP需要基於有層級的自上而下的鑽取,或者自下而上地聚合。所以每一個維必須有Hierarchy,至少有一個預設的,當然可以有多個,見下圖:
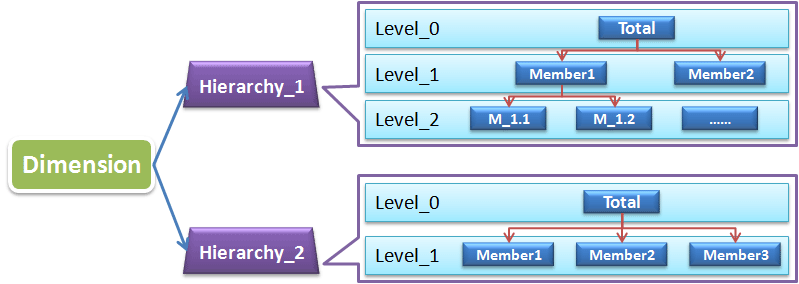
有了Hierarchy,維裡面的Level就有了自上而下的樹形結構關係,也就是上層的每一個成員(Member)都會包含下層的0個或多個成員,也就是樹的分支節點。這裡需要注意的是每個Hierarchy樹的根節點一般都設定成所有成員的彙總(Total),當該維未被OLAP中使用時,預設顯示的就是該維上的彙總節點,也就是該維所有資料的聚合(或者說該維未被用於細分)。Hierarchy中的每一層都會包含若干個成員(Member),還是以時間維,假設我們建的是2006-2015這樣一個時間跨度的時間維,那麼最高層節點僅有一個Total的成員,包含了所有這10年的時間,而年的那層Level中包含2006、2007…2015這10個成員,每一年又包含了4個季度成員,每個季度包含3個月份成員……這樣似乎順理成章多了,我們就可以基於Hierarchy做一些OLAP操作了。
實表是用來記錄具體事件的,也就是你要關注的內容,包含了每個事件的具體要素,以及具體發生的事情。事實表中以數字型為主,包含了度量資訊。比如使用者交易流水錶。
維表則是對事實表中事件的要素的描述資訊,就是你觀察該事務的角度,是從哪個角度去觀察這個內容的。維度表常以文字型別為主,常常被作為事實表的“上下文”。一般用來解釋事實表中關鍵字緯度的具體內容,為那些度量數值添加了業務意義。比如使用者屬性表。
基於事實表和維表就可以構建出多種多維模型,包括星形模型、雪花模型和星座模型。這裡不再展開了,解釋概念真的很麻煩,而且基於我的理解的描述不一定所有人都能明白,還是直接上例項吧:
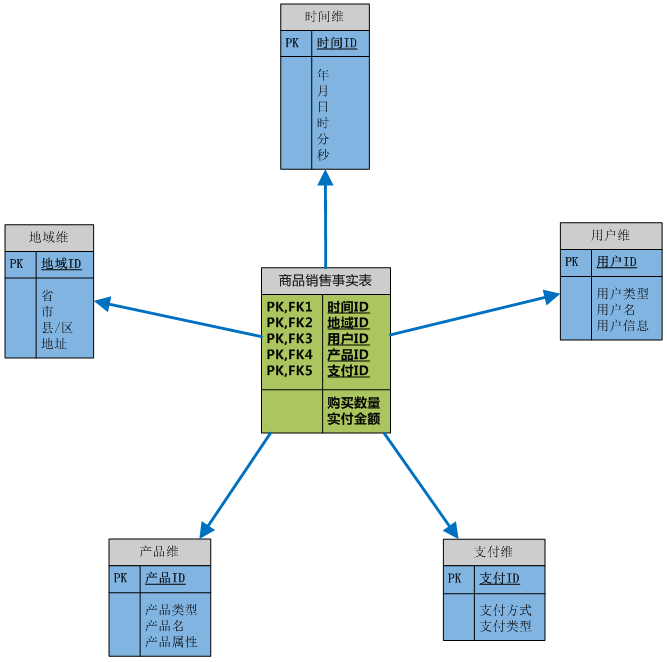
這是一個最簡單的星形模型的例項。事實表裡面主要包含兩方面的資訊:維和度量,維的具體描述資訊記錄在維表,事實表中的維屬性只是一個關聯到維表的鍵,並不記錄具體資訊;度量一般都會記錄事件的相應數值,比如這裡的產品的銷售數量、銷售額等。維表中的資訊一般是可以分層的,比如時間維的年月日、地域維的省市縣等,這類分層的資訊就是為了滿足事實表中的度量可以在不同的粒度上完成聚合,比如2010年商品的銷售額,來自上海市的銷售額等。
還有一點需要注意的是,維表的資訊更新頻率不高或者保持相對的穩定,例如一個已經建立的十年的時間維在短期是不需要更新的,地域維也是;但是事實表中的資料會不斷地更新或增加,因為事件一直在不斷地發生,使用者在不斷地購買商品、接受服務。
注:雪花模型是當有一個或多個維表沒有直接連線到事實表上,而是通過其他維表連線到事實表上時,其圖解就像多個雪花連線在一起,故稱雪花模型。雪花模型是對星型模型的擴充套件。相比星型模型,雪花模型的特點是貼近業務,資料冗餘較少,但由於表連線的增加,導致了效率相對星型模型來的要低一些。
、立方體 Cube
這裡所說的立方其實就是多維模型中間的事實表(Fact Table),它會引用所有相關維的維主鍵作為自身的聯合主鍵,加上度量(Measure)和計算度量(Calculated Measure)就組成了立方的結構:
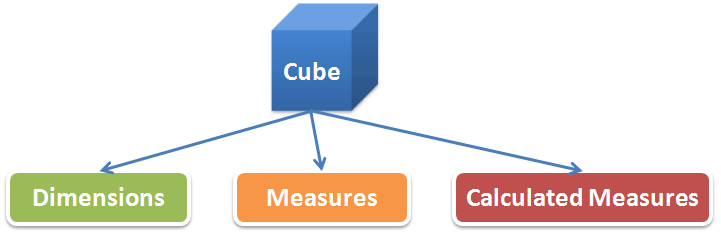
度量是用於描述事件的數字尺度,比如網站的瀏覽量(Pageviews)、訪問量(Visits),再如電子商務的訂單量、銷售額等。度量是實際儲存於物理表中的,而計算度量則沒有,計算度量是通過度量計算得到的,比如同比(如去年同期的月利潤)、環比(如上個月的利潤)、利率(如環比利潤增長率)、份額(如該月中某類產品利潤所佔比例)、累計(如從年初到當前的累加利潤)、移動平均(如最近7天的平均利潤額)等,這些計算度量在Oracle中都可以藉助分析函式直接計算得到,相信大部分的OLAP元件都會提供類似在時間序列上的分析功能。而這些計算度量往往對於分析而言更具意義,立方中藉助與各個維的關聯關係從不同的角度和層面來展現這些度量。
cube
一般是經過大量聚類運算好的而加以用特定方式存貯的多維報表,多拉幾個維度構成的報表雖然也有分析功能,但是它是死的,而cube可以進行任意維度角度組合去看待資料,分析的味道更濃一些。對於cube,
你可以把它想像成一個魔方的客觀形態(其實cube的維數一般比魔方的三維要多);而資料OLAP就是要從中抽取資料; 一個cube基於一個主題,
並且分為幾個維, 維是圍繞主題的;
舉例:基於銷售的方體(cube) 主題是 銷售,維是city; item; day; buyer; 等等,基於 cube,我們可以快速抽取和計算資料。
7、資料模型與資料建模
模型是對現實世界的抽象,設計資料庫系統時,一般會事先用抽象的圖表(ER圖)反映資料彼此之間的關係,稱為建立資料模型。資料模型是資料庫管理系統用來表示實體與實體間聯絡的方法。在設計資料庫時,對業務進行分析、抽象、並從中找出內在聯絡,進而確定資料庫的結構,這一過程就稱為資料建模。
資料模型與資料建模的過程就是用標準來定義、規範資料。合理的業務模型設計對ETL至關重要。資料倉庫是企業惟一、真實、可靠的綜合資料平臺。資料倉庫的設計建模一般都依照三正規化、星型模型、雪花模型,無論哪種設計思想,都應該最大化地涵蓋關鍵業務資料,把運營環境中雜亂無序的資料結構統一成為合理的、關聯的、分析型的新結構,而ETL則會依照模型的定義去提取資料來源,進行轉換、清洗,並最終載入到目標資料倉庫中。
模型的重要之處在於對資料做標準化定義,實現統一的編碼、統一的分類和組織。標準化定義的內容包括:標準程式碼統一、業務術語統一。ETL依照模型進行初始載入、增量載入、緩慢增長維、慢速變化維、事實表載入等資料整合,並根據業務需求制定相應的載入策略、重新整理策略、彙總策略、維護策略。
8、資料模型的定義
資料模型按不同的應用層次分成三種類型:分別是概念資料模型、邏輯資料模型、物理資料模型。概念資料模型(Conceptual Data Model)簡稱概念模型,是面向資料庫使用者的實現世界的模型,主要用來描述世界的概念化結構,它使資料庫的設計人員在設計的初始階段,擺脫計算機系統及DBMS的具體技術問題,集中精力分析資料以及資料之間的聯絡等,與具體的資料管理系統(Database Management System,簡稱DBMS)無關。概念資料模型必須換成邏輯資料模型,才能在DBMS中實現。邏輯資料模型是業務抽象到DBMS中,物理資料模型是邏輯資料模型的具體實現。
資料倉庫的物理模型較常見的操作型資料庫的物理模型有很大不同。最明顯的區別是:操作型資料庫主要是用來支撐即時操作,對資料庫的效能和質量要求都比較高,為了防止“garbage
in,garbage
out”,通常設計操作型資料庫的都要遵循幾個正規化的約束,除非少數情況下為了效能進行妥協,才可能出現冗餘。而資料倉庫的建立並不上為了支撐即時操作,或者說,資料倉庫的資料是來源於即時操作產生的資料,而不是直接來源於即時操作。所以它的資料質量是由操作性系統來保證的,而不是由幾個正規化來保證的。而且為了更好的跟蹤歷史資訊,以及更快的產生報表,資料倉庫的物理模型中存在著大量冗餘欄位。
資料倉庫的物理模型分為星型和雪花型兩種。所謂星型,就是將模型中只有一個主題,其他的表中儲存的都是主題的一些特徵。比如貨物銷量的主題倉庫中,每次出售記錄是事實表,而時間,售貨員,商品是維度,都和事實表有聯絡,組織起來就是星型。而如果更細化來看,商品是有種類,產地,價格等特徵的,從這個角度來看,有兩個主題,一個是商品出售,一個是商品本身。組織起來就是雪花型。實際專案中,由於操作型系統業務的複雜性導致本身產生了大量的資料,所以,組織起來也以雪花型居多。
9、事實表和維度表的分界線
事實表是用來儲存主題的主幹內容的。以日常的工作量為例,工作量可能具有如下屬性:工作日期,人員,上班時長,加班時長,工作性質,是否外勤,工作內容,稽核人。那麼什麼才是主幹內容?很容易看出上班時長,加班時長是主幹,也就是工作量主題的基本內容,那麼工作日期,人員,工作性質,是否外勤,工作內容是否為主幹資訊呢?認真分析特徵會發現,日期,人員,性質,是否外勤都是可以被分類的,例如日期有年-月-日的層次,人員也有上下級關係,外勤和正常上班也是兩類上班考勤記錄,而上班時長和加班時長則不具有此類意義。所以一般把能夠分類的屬性單獨列出來,成為維度表,在事實表中維護事實與維度的引用關係。
在上述例子中,事實表可以設計成如下
WorkDate EmployeeID,WorkTypeID,Islegwork,Content,
而時間,員工,工作型別,是否外勤則歸為維度表。
總的來看,和其他建立主外來鍵關係的表也都一樣。但是維度表的建立是需要有層次的(雖然不是必須,但是也是典型特徵),而事實表的建立是針對已經發生的事實的,是歷史資料的存檔,也就是說是不應該修改的。以測試部測試軟體的Bug為例。每個Bug都是一個事實。這個Bug的狀態在資料字典裡可能設計成新建,轉派,修復,拒絕等等。那麼在事實表中Bug表中有一個欄位為Status。當測試員或者開發人員改變了這個狀態的值,事實表中該如何更新呢?是直接更新Status還是什麼其他的方式?顯然,為了能夠追蹤這個Bug的歷史資訊,應該是重新插入一條新的記錄(這裡可以參考歷史拉鍊表的etl重新整理策略)。那麼這和以往的資料庫設計有什麼區別呢?可以看出對於原始記錄和新插入的記錄,其他欄位全部是相同的,也就是全部冗餘的。如果以BugID作為主鍵,這時候會發現主鍵都是冗餘的(當然,插入之前只能刪除主鍵)。所以可以看出,事實表一般是沒有主鍵的。資料的質量完全由業務系統來把握。
總的說來,事實表的設計是以能夠正確記錄歷史資訊為準則,維度表的設計是以能夠以合適的角度來聚合主題內容為準則。
10、鑽取
鑽取是改變維的層次,變換分析的粒度。它包括向上鑽取(roll
up)和向下鑽取(drill down)。roll
up是在某一維上將低層次的細節資料概括到高層次的彙總資料,或者減少維數;是指自動生成彙總行的分析方法。通過嚮導的方式,使用者可以定義分析因素的彙總行,例如對於各地區各年度的銷售情況,可以生成地區與年度的合計行,也可以生成地區或者年度的合計行。
而drill
down則相反,它從彙總資料深入到細節資料進行觀察或增加新維。例如,使用者分析“各地區、城市的銷售情況”時,可以對某一個城市的銷售額細分為各個年度的銷售額,對某一年度的銷售額,可以繼續細分為各個季度的銷售額。通過鑽取的功能,使使用者對資料能更深入瞭解,更容易發現問題,做出正確的決策。
鑽取允許你駕御一個報表內的不同層次的資訊。 在你的商業模式中,我們定義不同層次的資訊,這些定義方式也代表著你的商業構建方法。
你能夠從一個資訊層到有細節的更低層或更高層進行提取。例如,假如你的資料是被區域、市場、和商店所組織的,並且你能夠執行一個顯示區域銷售的報表,那麼你就可以從一個區域層鑽取資料以便顯示組成該區域的市場的銷售。反之,你能從從商店中鑽取資料去瀏覽商店所屬的市場狀況。
11、交叉分析
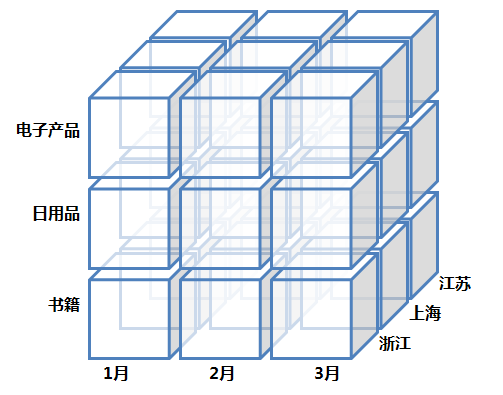
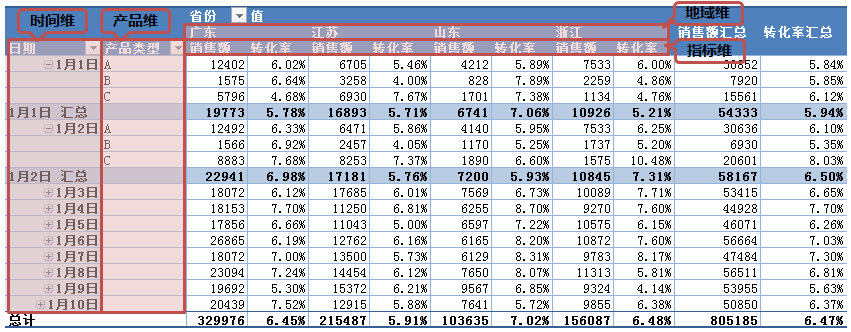
交叉分析是指對資料在不同維度進行交叉展現,進行多角度結合分析的方法,彌補了獨立維度進行分析沒法發現的一些問題。交叉分析以多維模型和資料立方為基礎,也可以認為是一種特殊的細分方式,但跟細分的概念有點差異,如果有興趣可以先閱讀下之前的文章——資料立方體與OLAP。細分的方法更多的是基於同一維度的縱深展開,也就是OLAP中的鑽取(Drill-down),比如從月彙總的資料細分來看每天的資料,就是在時間維度上的細分,或者從省份的資料細分檢視省份中各城市的資料,是基於地域維的下鑽。交叉分析不再侷限於一個維度,就像資料立方體與OLAP文章中的立方體,是基於不同維度的交叉,時間維、地域維和產品維交叉在一起分析每個小立方的資料表現,可以通過OLAP的切片(Slice)和切塊(Dice)操作檢視例如上海市在3月份的電子產品的銷售情況,這會幫助我們發現很多在單個維度中無法發現的問題。所以,交叉分析是基於不同維度橫向地組合交叉,而不是細分在同一維度的縱向展開。大體大樣式如下:

一般以表格呈現:
相關推薦
資料倉庫基礎介紹
前言 本文將會講述 BI/DW/DA 領域的一些常見概念,如:事實表、維度表、建模、多維分析、cube 等,但不涉及具體例項分析。 1、維(Dimension) 維是用於從不同角度描述事物特徵的,一般維都會有多層(Level:級別),每個Level都會包含一些共有的或特有的屬性(Attribute),可以用下
數據倉庫基礎介紹
提取 鏈表 proc 不一定 聚類 質量 ofo 允許 -s 前言 本文將會講述 BI/DW/DA 領域的一些常見概念,如:事實表、維度表、建模、多維分析、cube 等,但不涉及具體實例分析。 1、維(Dimension) 維是用於從不同角度描述事物特征的,一般維都會有多層
維度模型資料倉庫基礎物件概念一覽
一、度量、指標、指標器 度量和維度構成OLAP的主要概念,對於在事實表或者一個多維立方體裡面存放的數值型的、連續的欄位,就是度量。這符合上面的意思,有標準,一個度量欄位肯定是統一單位,例如元、戶數。如果一個度量欄位,其中的度量值可能是歐元又有可能是美元,那這個度量沒法彙總。
數據倉庫基礎(七)Informatica PowerCenter介紹
blog monitor form tro get rom 發的 moni AR 本文轉載自:http://www.cnblogs.com/evencao/p/3140938.html Infromatica PowerCenter介紹: 1993年在美國加利福
MPP架構海量資料分析倉庫——Greenplum介紹
一、Greenplum背景 時間回到2002年,網際網路行業經過近10年的發展,資料量正處於快速增長期: 1、傳統的主機計算模式在海量資料面前,除了造價昂貴外,在CPU計算和IO吞吐上不能滿足海量資料的計算需求; 2、傳統資料庫大多基於SMP架,縱向擴容(scale-up)模式遇到了瓶頸。
資料倉庫ETL演算法、常用的ETL工具介紹
1. ETL的定義:是資料抽取(Extract)、轉換(Transform)、清洗(Cleansing)、裝載(Load)的過程。是構建資料倉庫的重要一環,使用者從資料來源抽取出所需的資料,經過資料清洗,最終按照預先定義好的資料倉庫模型,將資料載入到資料倉庫中去; 2. 常用的ETL工具:主要有
JS基礎知識(一)【資料型別基本介紹,檢測資料型別端方法簡介】
1、基礎知識 ECMAScript(ES):規定了JS的一些基礎核心的知識(變數、資料型別、語法規範、操作語句等) DOM:document object model 文件物件模型,裡面提供了一些屬性和方法,可以讓我們操作頁面中的元素 BOM:browser ob
Git倉庫.git資料夾目錄介紹
說明 以下皆為.git/ 目錄下的檔案 1 ORIG_HEAD 遠端倉庫 當前引用 在git本地倉庫根目錄 執行: cat .git/ORIG_HEAD 顯示 88e6fb86f5317bdfd2e8a78899334e9f0ba16987 2
kaldi基礎介紹(一)在說話人識別中的資料準備
在kaldi說話人識別示例(egs/sre10,egs/sre16)中,資料總共有兩大類,一是訓練集(training),二是評估資料集(evaluation)。對於評估資料集又分為兩類,一是用來註冊(enrollment)的資料集,二是測試(test)集。一、訓練集的準備訓
【轉】基於Hadoop的資料倉庫Hive 基礎知識
基於Hadoop的資料倉庫Hive 基礎知識 - miao君的文章 - 知乎 https://zhuanlan.zhihu.com/p/25608332 Hive是基於Hadoop的資料倉庫工具,可對儲存在HDFS上的檔案中的資料集進行資料整理、特殊查詢和分析處理,提供了類
什麼是Hive——大資料倉庫Hive基礎
Hive是什麼: Hive是基於Hadoop的一個數據倉庫工具,可以將結構化的資料檔案對映成一張表,並提供類SQL查詢功能;其本質是將HQL轉化成MapReduce程式。 構建在Hadoop之上的資料倉庫: 使用HQL作為查詢介面
【資料極客】Week2_邏輯迴歸_Tensorflow基礎介紹
本文目錄 1. 推薦內容學習 【資料極客】任務總結_Week2 ## **1.0 線性迴歸Linear Regression** fw,b(x)=∑iwixi+b 各個feature的 `Xi` 對應的權重 `Wi` 相乘並求和, 再最後加上
維度模型資料倉庫(二) —— 維度模型基礎
從圖中可以看出,每種架構中都有資料集市。資料集市就是面向終端使用者的資料庫。資料集市通常使用維度模型來建模,並根據報表和分析的需求而優化。Kimball和Inmon架構最大的區別就是是否需要一個企業級的資料倉庫(EDW)。Inmon架構中有EDW,Kimball架構中沒有。EDW本質上就是一個
微軟MSBI零基礎從資料倉庫到商業智慧實戰(SSIS SSAS SSRS)
第一章理論講解部分 1.1、商業智慧系統的發展-商業智慧的概念、學科範圍、演化史和應用案例 1.2、商業智慧系統的發展–資訊抽取、自然演化式的體系結構以及面臨的問題 1.3、商業智慧系統的發展–初識資料倉庫 1.4、商業智慧系統的發展–資料倉庫開發方法 1.5、資料倉庫的主要術語解析-資料倉庫的概念 1.6、
資料倉庫介紹與實時數倉案例
浪費了“黃金五年”的Java程式設計師,還有救嗎? >>>
資料倉庫元件:Hive環境搭建和基礎用法
本文原始碼:[GitHub](https://github.com/cicadasmile/big-data-parent) || [GitEE](https://gitee.com/cicadasmile/big-data-parent) # 一、Hive基礎簡介 **1、基礎描述** Hive是基
Flask基礎介紹
ict 常用工具 路由 服務器 nginx done .org extend redirect 1. 介紹 Flask是一種使用Python 編寫的輕量級Web應用框架, 實現了基礎的核心, 用extension增加其他功能它的WSGI工具箱采用Werkzeug, 模板引
深度學習數學基礎介紹(二)概率與數理統計
特征 數字特征 抽樣分布 第5章 最大 中心 3.4 獨立 知識 第1章 隨機事件與概率§1.1 隨機事件§1.2 隨機事件的概率§1.3 古典概型與幾何概型§1.4 條件概率§1.5 事件的獨立性 第2章 隨機變量的分布與數字特征§2.1 隨機變量及其分布§2.2 隨機變
計算機基礎介紹
文件打開 暴風影音 軟件 文件 程序 作用 計算 基礎 取出 一。三大層 應用軟件(作用於)——操作系統(作用於)——電腦硬件 例如:通過暴風影音看電影,打開暴風影音後,暴風影音從電腦的硬盤上取出電影文件打開進行播放。 暴風影音(應用軟件)
【Android高級】NDK/JNI編程技術基礎介紹
data jint man 搭建 原理 編程 java代碼 rom pat 作為一個Andoird的Java程序猿,會受到Java語言的局限。由於作為一面門向對象的語言不能像C/C++那樣輕易調用與硬件有關的操作。因此JNI就搭建了這樣一