
Pentaho Work with Big Data(八)—— kettle叢集
叢集技術可以用來水平擴充套件轉換,使它們能以並行的方式執行在多臺伺服器上。轉換的工作可以平均分到不同的伺服器上。
一個叢集模式包括一個主伺服器和多個子伺服器,主伺服器作為叢集的控制器。簡單地說,作為控制器的Carte伺服器就是主伺服器,其他的Carte伺服器就是子伺服器。
一個叢集模式也包含元資料,元資料描述了主伺服器和子伺服器之間怎樣傳遞資料。在Carte伺服器之間通過TCP/IP套接字傳遞資料。
二、環境
4臺CentOS release 6.4虛擬機器,IP地址為
192.168.56.104
192.168.56.102
192.168.56.103
192.168.56.104作為主Carte。
192.168.56.102、192.168.56.103作為子Carte。
192.168.56.104、192.168.56.102、192.168.56.103分別安裝Pentaho的PDI,安裝目錄均為/home/grid/data-integration。
PDI版本:6.0
三、配置靜態叢集
1. 建立子伺服器
(1)開啟PDI,新建一個轉換。
(2)在“主物件樹”標籤的“轉換”下,右鍵點選“子伺服器”,新建三個子伺服器。如圖1所示。
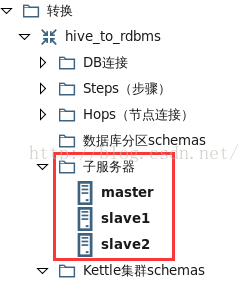
圖1
說明:. master、slave1、slave2的配置分別如圖2、圖3、圖4所示。
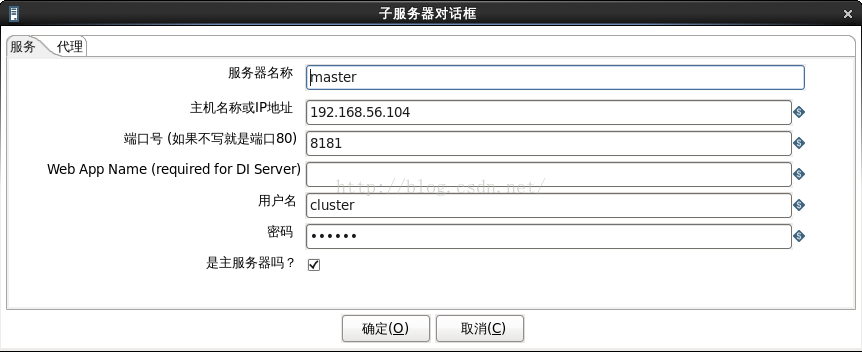
圖2
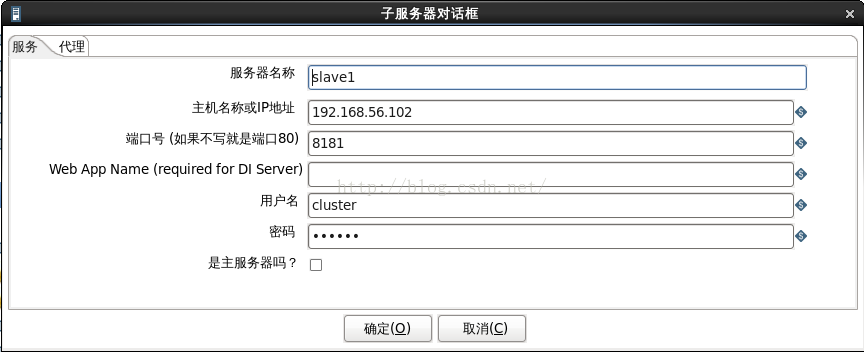
圖3
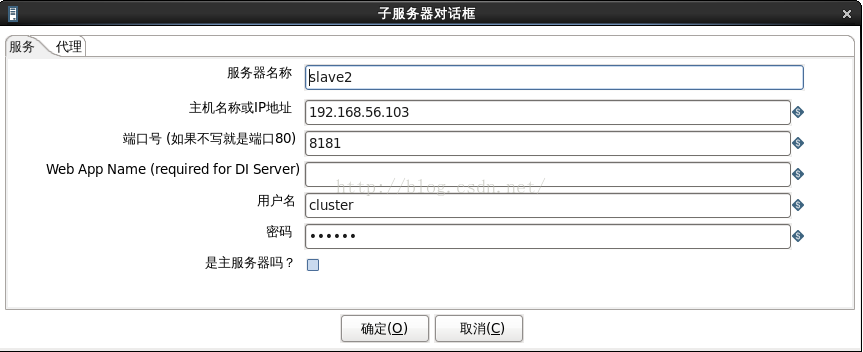
圖4
. “使用者名稱”和“密碼”項在各自子伺服器的/home/grid/data-integration/pwd/kettle.pwd檔案中定義,如圖5所示。
圖5
2. 建立叢集模式
在“主物件樹”標籤的“轉換”下,右鍵點選“Kettle叢集Schemas”,新建一個名為“cluster”叢集模式。如圖6所示。
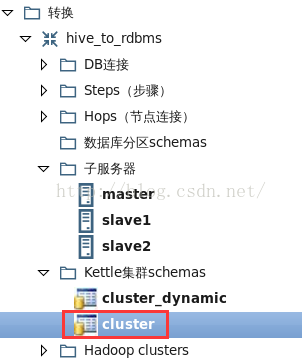
圖6
說明:. cluster的配置如圖7所示。
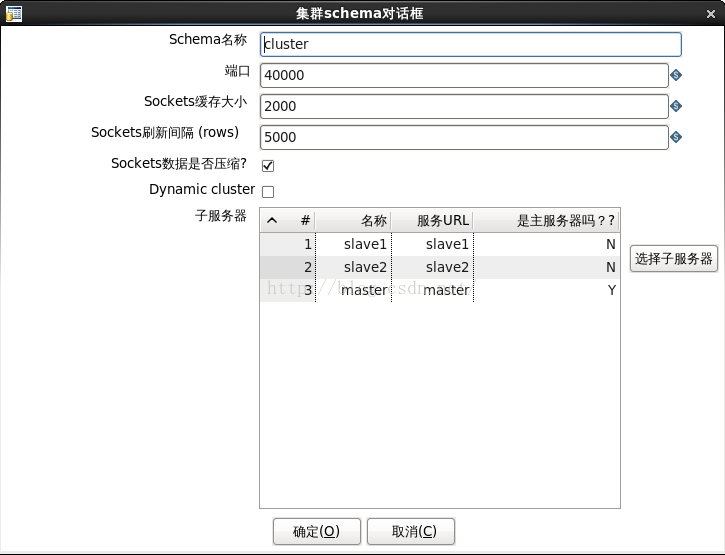
圖7
. 叢集模式中加入了上一步建立的一主兩從Carte子伺服器。3. 編輯轉換
(1)建立轉換如圖8所示。

圖8
說明:. 這個轉換的詳細配置參考http://blog.csdn.net/wzy0623/article/details/51160948中的“把資料從Hive抽取到RDBMS”。
. 右鍵點選“Table output”,選擇彈出選單裡的“叢集...”,如圖9所示。

圖9
. 在彈出視窗中選擇上一步建立的叢集模式“cluster”後,點選確定,如圖10所示。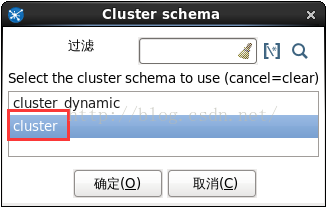
圖10
此時會看到“Table output”步驟的右上角出現“Cx2”標誌,如圖8的紅框中所示,說明此步驟在叢集的兩個子伺服器上執行。. “Table input”沒有叢集標誌,說明此步驟在主伺服器上執行。
4. 執行與監控
(1)在192.168.56.104上執行下面的命令啟動master。
(2)在192.168.56.102上執行下面的命令啟動slave1。cd /home/grid/data-integration/ ./carte.sh 192.168.56.104 8181
cd /home/grid/data-integration/
./carte.sh 192.168.56.102 8181cd /home/grid/data-integration/
./carte.sh 192.168.56.103 8181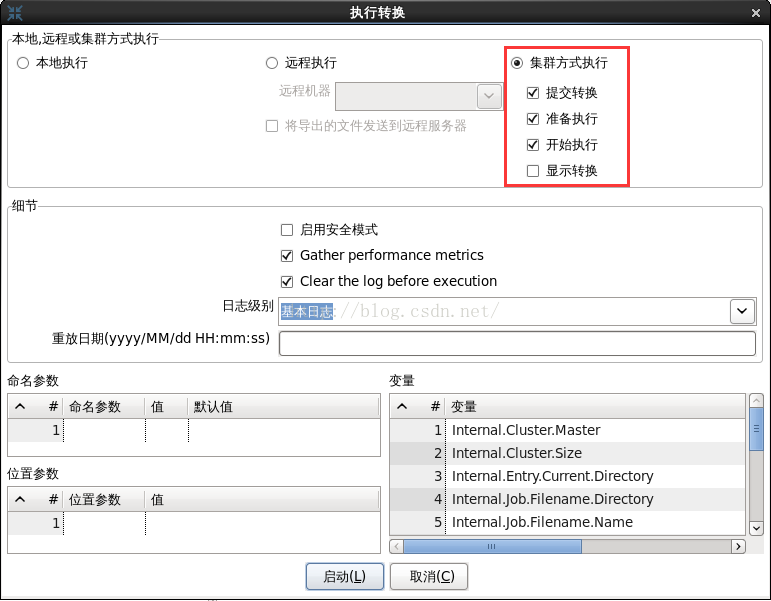
圖11
(5)右鍵點選“cluster”,選擇彈出選單中的“Monitor all slave servers”,如圖12所示。
圖12
(6)轉換成功執行後,會在監控標籤中看到執行資訊,如圖13到15所示。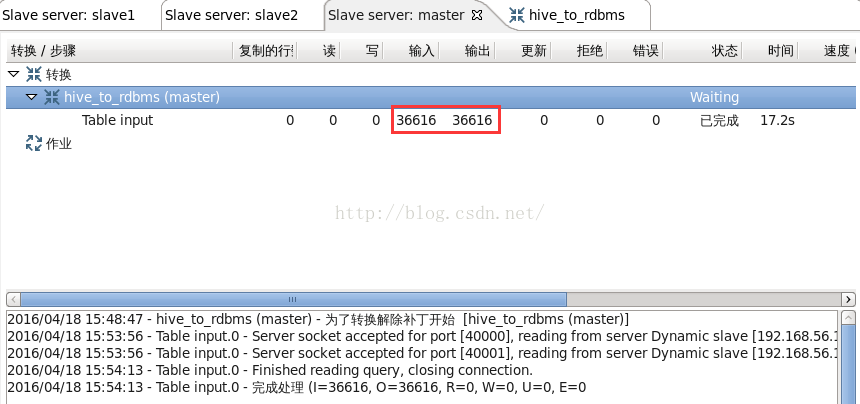
圖13
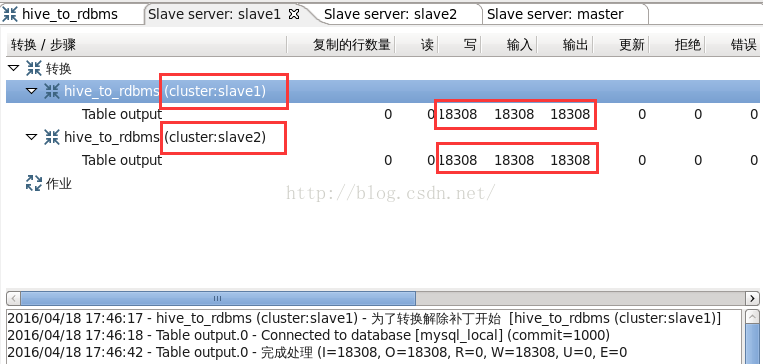
圖14
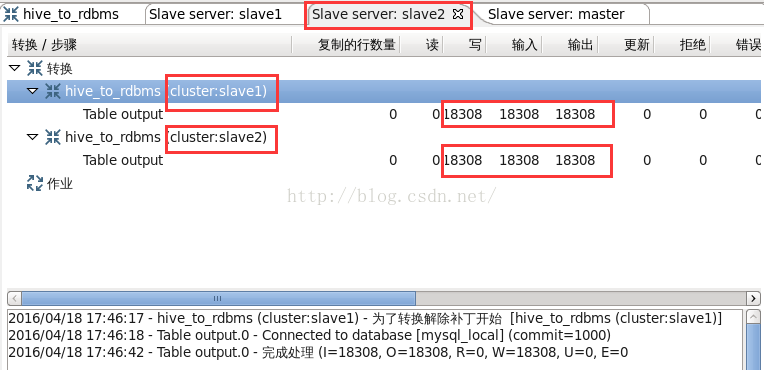
圖15
從圖13可以看到,“Table input”步驟在master執行,從hive表讀取36616行記錄,向“Table output”步驟輸出36616行記錄。從圖14、圖15可以看到,“Table output”步驟分別在兩個子伺服器slave1、slave2上執行,各自讀取了18308行記錄,並分別向mysql表寫了18308行記錄。此時檢視mysql表,共寫入了36616行記錄。如圖16所示。
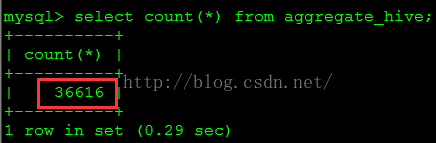
圖16
四、配置動態叢集
1. 建立子伺服器,這步和配置靜態叢集相同。
2. 建立叢集模式
在“主物件樹”標籤的“轉換”下,右鍵點選“Kettle叢集Schemas”,新建一個名為“cluster_dynamic”叢集模式。如圖17所示。
圖17
說明:. cluster_dynamic的配置如圖18所示。
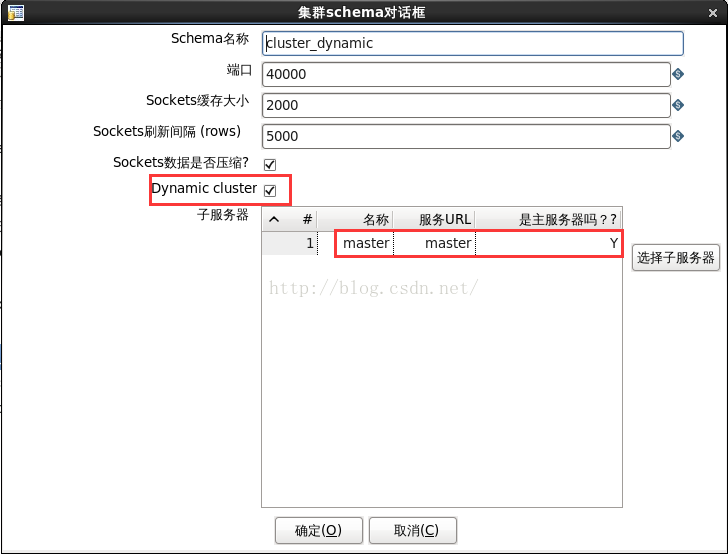
圖18
. 與配置靜態叢集不同,這裡只加入了master。3. 編輯轉換
(1)建立轉換如圖19所示。

圖19
說明:. 這個轉換的詳細配置參考http://blog.csdn.net/wzy0623/article/details/51160948中的“把資料從Hive抽取到RDBMS”。
. 右鍵點選“Table output”,選擇彈出選單裡的“叢集...”,如圖9所示。
. 在彈出視窗中選擇上一步建立的叢集模式“cluster_dynamic”後,點選確定,如圖20所示。
圖20
此時會看到“Table output”步驟的右上角出現“CxN”標誌,如圖19的紅框中所示,說明此步驟在叢集的兩個子伺服器上執行。. “Table input”沒有叢集標誌,說明此步驟在主伺服器上執行。
4. 執行與監控
(1)在192.168.56.104上編輯/home/grid/data-integration/pwd/carte-config-8181.xml檔案,內容如下:
<slave_config>
<slaveserver>
<name>master</name>
<hostname>192.168.56.104</hostname>
<port>8181</port>
<username>cluster</username>
<password>mypassword</password>
<master>Y</master>
</slaveserver>
</slave_config><slave_config>
<masters>
<slaveserver>
<name>master</name>
<hostname>192.168.56.104</hostname>
<port>8181</port>
<username>cluster</username>
<password>mypassword</password>
<master>Y</master>
</slaveserver>
</masters>
<report_to_masters>Y</report_to_masters>
<slaveserver>
<name>slave1</name>
<hostname>192.168.56.102</hostname>
<port>8181</port>
<username>cluster</username>
<password>mypassword</password>
<master>N</master>
</slaveserver>
</slave_config><slave_config>
<masters>
<slaveserver>
<name>master</name>
<hostname>192.168.56.104</hostname>
<port>8181</port>
<username>cluster</username>
<password>mypassword</password>
<master>Y</master>
</slaveserver>
</masters>
<report_to_masters>Y</report_to_masters>
<slaveserver>
<name>slave2</name>
<hostname>192.168.56.103</hostname>
<port>8181</port>
<username>cluster</username>
<password>mypassword</password>
<master>N</master>
</slaveserver>
</slave_config>cd /home/grid/data-integration/
./carte.sh pwd/carte-config-8181.xml(5)在192.168.56.102上執行下面的命令啟動slave1。
cd /home/grid/data-integration/
./carte.sh pwd/carte-config-8181.xmlcd /home/grid/data-integration/
./carte.sh pwd/carte-config-8181.xml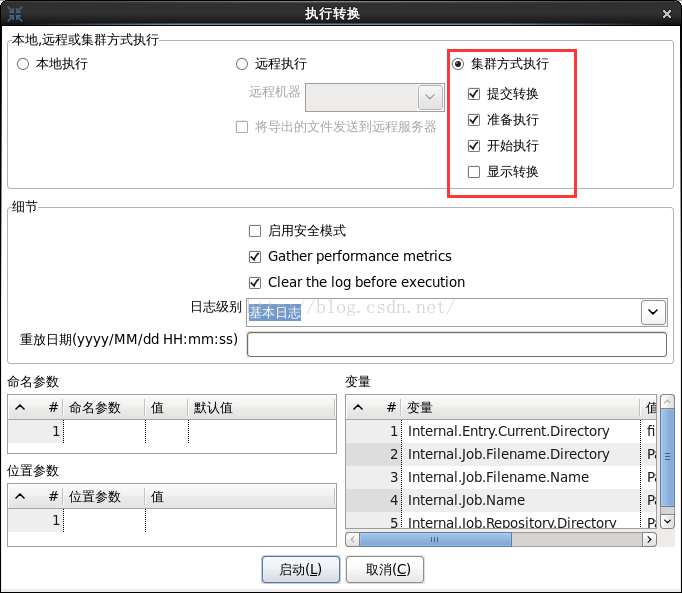
圖21
(5)右鍵點選“cluster”,選擇彈出選單中的“Monitor all slave servers”,如圖12所示。(6)轉換成功執行後,會在監控標籤中看到執行資訊,如圖22到24所示。
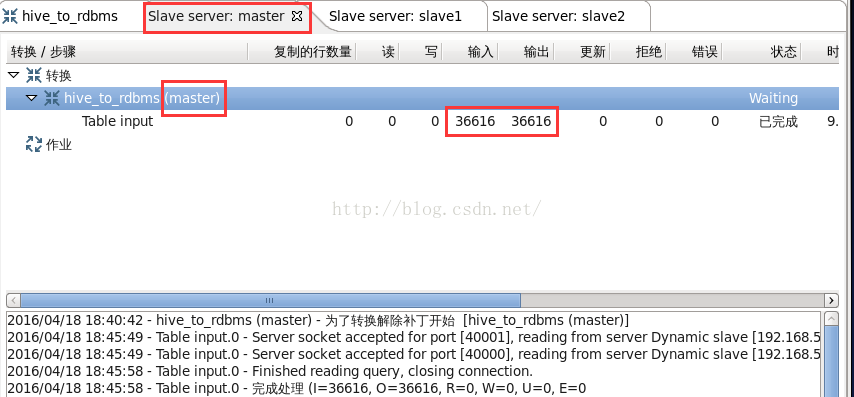
圖22
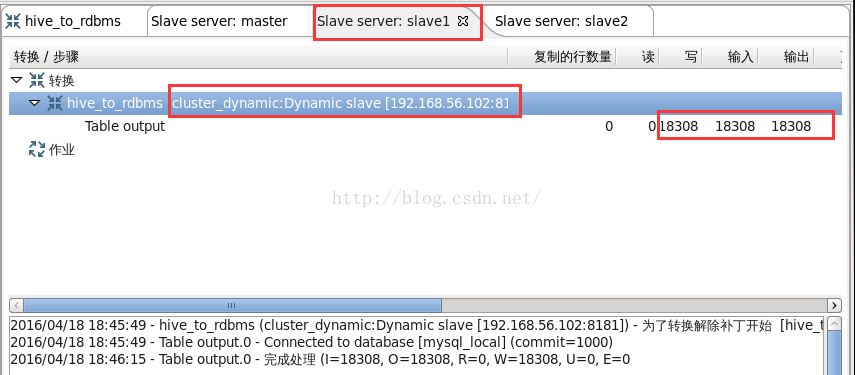
圖23
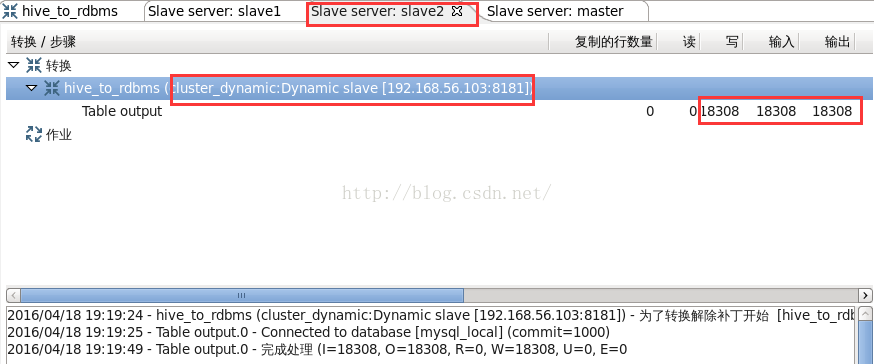
圖24
從圖23可以看到,“Table input”步驟在master執行,從hive表讀取36616行記錄,向“Table output”步驟輸出36616行記錄。從圖23可以看到,“Table output”步驟分別在動態子伺服器slave1執行,讀取了18308行記錄,並向mysql表寫了18308行記錄。
從圖24可以看到,“Table output”步驟分別在動態子伺服器slave2執行,讀取了18308行記錄,並向mysql表寫了18308行記錄。
此時檢視mysql表,共寫入了36616行記錄。如圖16所示。
參考:
Kettle解決方案:使用PDI構建開源ETL解決方案
相關推薦
Pentaho Work with Big Data(八)—— kettle叢集
一、簡介 叢集技術可以用來水平擴充套件轉換,使它們能以並行的方式執行在多臺伺服器上。轉換的工作可以平均分到不同的伺服器上。 一個叢集模式包括一個主伺服器和多個子伺服器,主伺服器作為叢集的控制器。簡單地說,作為控制器的Carte伺服器就是主伺服
【 專欄 】- Pentaho Work with Big Data
Pentaho Work with Big Data 用例項說明Pentaho Kettle 產品對大資料的支援,包括從Hadoop叢集匯入匯出資料、Hive資料轉換、MapReduce聚合、執行Spark作業、Kettle叢集等
kettle學習筆記(八)——kettle查詢步驟與連接步驟
ttl 配置 實例 nio ket 裏的 mage 2.x 步驟 一、概述 查詢步驟: 用來查詢數據源裏的數據並合並到主數據流中 。 連接步驟: 結果集通過關鍵字進行連接 。(與前面的UNION不同) 二、查詢步驟 1.流查詢 流查詢示
(八)Redis叢集常用命令、叢集節點新增刪除
一、cluster info :列印叢集資訊 二、cluster nodes:列出叢集中已知的所有節點(node),以及這些節點相關 資訊 可以看到上面有六個節點,三個主節點(master),三個備份節點(slave),其中有一個埠為7001的主節點前有mysel
《Hadoop》之"踽踽獨行"(八)Hadoop叢集的啟動指令碼整理及守護執行緒原始碼
在上一章的偽分散式叢集搭建中,我們使用start-dfs.sh指令碼啟動了叢集環境,並且上傳了一個檔案到HDFS上,還使用了mapreduce程式對HDFS上的這個檔案進行了單詞統計。今天我們就來簡單瞭解一下啟動指令碼的相關內容和HDFS的一些重要的預設配置屬性。 一、啟動指令碼 hadoo
Apache shiro叢集實現 (八) web叢集時session同步的3種方法
在做了web集群后,你肯定會首先考慮session同步問題,因為通過負載均衡後,同一個IP訪問同一個頁面會被分配到不同的伺服器上, 如果session不同步的話,一個登入使用者,一會是登入狀態,一會又不是登入狀態。所以本文就根據這種情況給出三種不同的方法來解決這個問題: 一,利用資料庫同步sessio
Android開發教程 - 使用Data Binding(八)使用自定義Interface
extend 方便 獲取 ble main implement lec click 簡單 為什麽要使用自定義Interface 我們平常在Android的開發中,比如如果要設置一個View的點擊事件,通常通過view.setOnClickListener()來實現的,這
MongoDB進階(八)Spring整合MongoDB(Spring Data MongoDB)
最近比較忙,忙的都沒空理csdn了,今天我繼續邁著魔鬼般的步伐,摩擦摩擦……總結下最近學到的MongoDB的知識。 1.認識Spring Data MongoDB 之前還的確不知道Spring連整合Nosql的東西都實現了,還以為自己又要
解壓縮模組zipfile — Work with ZIP archives(檔案檔案)
zipfile是一個module ,有兩個非常重要的class, 分別是ZipFile和ZipInfo, 在絕大多數的情況下,我們只需要使用這兩個class就可以了。ZipFile是主要的類,用來建立和讀取zip檔案,ZipInfo是儲存的zip檔案的每個檔案的資訊的。 簡
Notes on tensorflow(八)read tfrecords with slim
import tensorflow as tf slim = tf.contrib.slim file_pattern = './pascal_train_*.tfrecord' #檔名格式 # 介面卡1:將example反序列化成儲存之前的格式。由t
設計模式學習總結(八)策略模式(Strategy)
isp 筆記本 override div ont 角色 write stat 通過 策略模式,主要是針對不同的情況采用不同的處理方式。如商場的打折季,不同種類的商品的打折幅度不一,所以針對不同的商品我們就要采用不同的計算方式即策略來進行處理。 一、示例展示: 以
機器學習筆記(八)非線性變換
nbsp 線性 logs 等於 線性模型 images http 自己 空間 一、非線性問題 對於線性不可分的數據資料,用線性模型分類,Ein會很大,相應的Ein=Eout的情況下,Eout也會很大,導致模型表現不好,此時應用非線性模型進行分類,例如: 分類器模型是一個圓
學習MVC之租房網站(八)- 前臺註冊和登錄
設置 rup 密碼錯誤 發送短信 mvc 短信驗證 ont 上傳 錯誤 在上一篇<學習MVC之租房網站(七)-房源管理和配圖上傳>完成了在後臺新增、編輯房源信息以及上傳房源配圖的功能。到此後臺開發便告一段落了,開始實現前臺的功能,也是從用戶的登錄、註冊開始。 前
黑盒測試用例設計-功能圖法和場景法(八)
重新 感覺 結果 軟件 簡單 可能 遷移 面向 通話 7.功能圖法 一個程序的功能包括靜態和動態說明。動態說明描述輸入數據的次序或轉移的次序,和業務流程緊密對應。靜態說明描述了輸入輸出條件之間的對應關系。對於面向市場的產品,其邏輯復雜、組合龐大,必須用動態說明
Python(八)之函數
列表 應該 聚合 作用 接收 求階乘 問題 mage 函數式編程 Python函數 函數作用: (1)代碼重用 (2)一種設計工具,分解復雜問題 (3)將相關功能打包並參數化 函數種類: 全局函數:定義在模塊中 局部函數:嵌套在其他函數中 lambda函數:表達
自然語言交流系統 phxnet團隊 創新實訓 項目博客 (八)
aud 權限 use 開始 write 創新 技術 read 交流 在本項目中使用到的“文本轉語音”的技術總結: 文本轉語音,使用的是科大訊飛的接口,因為此作品之中語音包不是重點,所以語音包的轉換我們統一調用的科大訊飛的語音包接口,依舊是在線的文字轉語音
uml系列(八)——部署圖與構件圖
復雜 數據 net 打包 img 之前 說明 而且 bsp 之前說了uml的設計圖,現在說一下uml的最後兩種圖:構件圖、部署圖。這兩種圖之所以放在一起是因為它們都是軟件的實現圖。 構件圖 構件圖是描述一組構件之間
webots自學筆記(八)麥克納母輪移動機器人平臺,可控制攝像頭視角
left sad src blog com 例子 好玩 也有 工作量 原創文章,來自“博客園,_阿龍clliu” http://www.cnblogs.com/clliu/,轉載請註明原文章出處。 覺得基礎的東西說的差不多了,之後就分享一些好玩的仿
網絡命令(八)
網絡 網卡 接口 網卡配置管理命令:ip, ifconfig,mii-tool,ethtool,ping,netstat,ss路由設置管理命令:route,traceroute ,tracert8.1.ifconfig功能:配置打印網絡接口語法:ifconfig [interface]
Hibernate(八):基於外鍵映射的1-1關聯關系
hbm 初始化 inno oot type nat create getc source 背景: 一個部門只有一個一把手,這在程序開發中就會設計數據映射應該設置為一對一關聯。 在hibernate代碼開發中,實現這個業務有兩種方案: 1)基於外鍵映射的1-1關