
學習壓縮感知比較好的文章連結收藏
本文真的對我理解壓感起到很大的幫助,特別在OMP(正交匹配追蹤重構演算法)演算法的講解中,尤為精彩,我從來沒有見過哪個博主能如此認真的去一行一行地解釋,解讀程式碼,我對此十分感謝。
個人認為,能有超過70%註釋的程式碼才是負責人的程式碼,當然也是好的程式碼。本文做到的不僅如此,簡直優秀。為此,我一行一行的抄寫了裡面的程式碼。
精彩節選:
1. 原始訊號x是什麼?我採集的是原始訊號x還是y = Ax得到的y?
解答:
記原始訊號為x,我們在sensor方得到的原始訊號就是n*1的訊號x,而在receiver方採集到的訊號是y。針對y=Ax做變換時,A(m*n )是一個隨機矩陣(真的很隨機,不用任何正交啊什麼的限定)。
(我認為藍色部分是精髓)
2. O M P 重構演算法:
% 1-D訊號壓縮感測的實現(正交匹配追蹤法Orthogonal Matching Pursuit) % 測量數M>=K*log(N/K),K是稀疏度,N訊號長度,可以近乎完全重構 % 程式設計人--香港大學電子工程系 沙威 Email: [email protected] % 程式設計時間:2008年11月18日 % 文件下載: http://www.eee.hku.hk/~wsha/Freecode/freecode.htm % 參考文獻:Joel A. Tropp and Anna C. Gilbert % Signal Recovery From Random Measurements Via Orthogonal Matching % Pursuit,IEEE TRANSACTIONS ON INFORMATION THEORY, VOL. 53, NO. 12, % DECEMBER 2007. clc;clear %% 1. 時域測試訊號生成 K=7; % 稀疏度(做FFT可以看出來) N=256; % 訊號長度 M=64; % 測量數(M>=K*log(N/K),至少40,但有出錯的概率) f1=50; % 訊號頻率1 f2=100; % 訊號頻率2 f3=200; % 訊號頻率3 f4=400; % 訊號頻率4 fs=800; % 取樣頻率 ts=1/fs; % 取樣間隔 Ts=1:N; % 取樣序列 x=0.3*cos(2*pi*f1*Ts*ts)+0.6*cos(2*pi*f2*Ts*ts)+0.1*cos(2*pi*f3*Ts*ts)+0.9*cos(2*pi*f4*Ts*ts); % 完整訊號,由4個訊號疊加而來 %% 2. 時域訊號壓縮感測 Phi=randn(M,N); % 測量矩陣(高斯分佈白噪聲)64*256的扁矩陣,Phi也就是文中說的D矩陣 s=Phi*x.'; % 獲得線性測量 ,s相當於文中的y矩陣 %% 3. 正交匹配追蹤法重構訊號(本質上是L_1範數最優化問題) %匹配追蹤:找到一個其標記看上去與收集到的資料相關的小波;在資料中去除這個標記的所有印跡;不斷重複直到我們能用小波標記“解釋”收集到的所有資料。 m=2*K; % 演算法迭代次數(m>=K),設x是K-sparse的 Psi=fft(eye(N,N))/sqrt(N); % 傅立葉正變換矩陣 T=Phi*Psi'; % 恢復矩陣(測量矩陣*正交反變換矩陣) hat_y=zeros(1,N); % 待重構的譜域(變換域)向量 Aug_t=[]; % 增量矩陣(初始值為空矩陣) r_n=s; % 殘差值 for times=1:m; % 迭代次數(有噪聲的情況下,該迭代次數為K) for col=1:N; % 恢復矩陣的所有列向量 product(col)=abs(T(:,col)'*r_n); % 恢復矩陣的列向量和殘差的投影係數(內積值) end [val,pos]=max(product); % 最大投影係數對應的位置,即找到一個其標記看上去與收集到的資料相關的小波 Aug_t=[Aug_t,T(:,pos)]; % 矩陣擴充 T(:,pos)=zeros(M,1); % 選中的列置零(實質上應該去掉,為了簡單我把它置零),在資料中去除這個標記的所有印跡 aug_y=(Aug_t'*Aug_t)^(-1)*Aug_t'*s; % 最小二乘,使殘差最小 r_n=s-Aug_t*aug_y; % 殘差 pos_array(times)=pos; % 紀錄最大投影係數的位置 end hat_y(pos_array)=aug_y; % 重構的譜域向量 hat_x=real(Psi'*hat_y.'); % 做逆傅立葉變換重構得到時域訊號 %% 4. 恢復訊號和原始訊號對比 figure(1); hold on; plot(hat_x,'k.-') % 重建訊號 plot(x,'r') % 原始訊號 legend('Recovery','Original') norm(hat_x.'-x)/norm(x)
3.對上述程式碼的解讀:



最精彩部分:
好了,有了OMP演算法,開始對應解釋程式碼: for col=1:N; % 恢復矩陣的所有列向量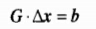 它的最小二乘解為:
它的最小二乘解為: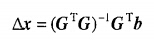 其中
其中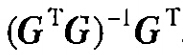 即為矩陣G的最小二乘廣義逆(廣義逆的一種)。有了這些知識背景後代碼就容易理解了,在第三步中,得到矩陣T中的與殘差r_n最相關的列組成的矩陣Aug_t,而第四步實際上就是在求方程組Aug_t*Aug_y=s的最小二乘解。r_n=s-Aug_t*aug_y;這一句就是用求得的最小二乘解更新殘差r_n,在下一次迭代中使用。注意最小二乘解的含義,它並不是使Aug_t*Aug_y=s成立,而只是讓s-Aug_t*aug_y的2範數最小,而r_n就是最小的值。此即英文步驟中的第五步,兩個式子合在一起寫了。pos_array(times)=pos; 把與T中與殘差最相關的列號記下來,恢復時使用。到此,主要的for迴圈就說完了。hat_y(pos_array)=aug_y; 最後一次迭代得到的最小二乘解aug_y即為恢復的值,位置分別對應於迭代中每一次與殘差r_s最相關的矩陣T的列號。hat_y(pos_array)大小是和pos_array大小一樣的,並且hat_y(pos_array)的第k個元素就是pos_array(k)。hat_x=real(Psi'*hat_y.');此即:
即為矩陣G的最小二乘廣義逆(廣義逆的一種)。有了這些知識背景後代碼就容易理解了,在第三步中,得到矩陣T中的與殘差r_n最相關的列組成的矩陣Aug_t,而第四步實際上就是在求方程組Aug_t*Aug_y=s的最小二乘解。r_n=s-Aug_t*aug_y;這一句就是用求得的最小二乘解更新殘差r_n,在下一次迭代中使用。注意最小二乘解的含義,它並不是使Aug_t*Aug_y=s成立,而只是讓s-Aug_t*aug_y的2範數最小,而r_n就是最小的值。此即英文步驟中的第五步,兩個式子合在一起寫了。pos_array(times)=pos; 把與T中與殘差最相關的列號記下來,恢復時使用。到此,主要的for迴圈就說完了。hat_y(pos_array)=aug_y; 最後一次迭代得到的最小二乘解aug_y即為恢復的值,位置分別對應於迭代中每一次與殘差r_s最相關的矩陣T的列號。hat_y(pos_array)大小是和pos_array大小一樣的,並且hat_y(pos_array)的第k個元素就是pos_array(k)。hat_x=real(Psi'*hat_y.');此即: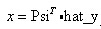 ,這裡用hat_x以與原如訊號x區分,x為原訊號,hat_x為恢復的訊號。程式碼中對hat_y取了轉置是因為hat_y應該是個列向量,而在程式碼中的前面hat_y=zeros(1,N); 將其命成了行向量,所以這裡轉置了一下,沒什麼大不了的。matlab執行一下就發現了 psi*hat_y的結果是實數,但是都帶著+0.0000i 所以要取實部。
,這裡用hat_x以與原如訊號x區分,x為原訊號,hat_x為恢復的訊號。程式碼中對hat_y取了轉置是因為hat_y應該是個列向量,而在程式碼中的前面hat_y=zeros(1,N); 將其命成了行向量,所以這裡轉置了一下,沒什麼大不了的。matlab執行一下就發現了 psi*hat_y的結果是實數,但是都帶著+0.0000i 所以要取實部。————————————————————————————————————————————————————
是不是對這段程式碼解讀感動的淚流滿面。
事實上,學習這段程式碼的目的並不在此例本身,而是通過對這段程式碼的學習,來舉一反三,應用於自己的工程,或者用於理解自己的工程相關的程式碼。
為什麼會感動,那是因為看到自己的前輩留下來的註釋率不到2%的程式碼砸到你的臉上讓你死磕,那種無奈與孤獨可曾瞭解?看到這種程式碼能不感動嗎?這是我等的典範!!!
————————————————————————————————————————————————————
起名為:Hello World,我服。這才是配得上Hello world 之名的博文。
這是一篇碩士學位論文,對於研究壓感重建演算法很有幫助。
主要是中文版的,所以閱讀起來障礙會小一點。
文中給出了O M P重建演算法的中文版流程:


這只是本論文中的冰山一角,論文繼續研讀中。
這是西安電子科技大學的一篇碩士論文,哈哈,這是我師兄的一篇畢業碩士畢業論文,雖然沒有見過師兄,但覺得師兄應該挺牛的,這是第一個研究這個專案的人,目前此專案由我接手,說來已經經歷第三代實驗室人了。同時也感謝親手將此專案傳於我的師兄,讓我更快的走上了硬體的這條路,還有我的即將離開的研三師兄,你對我的指導也讓我感激不盡。
持續更新中。
下面一篇文章,我即將閱讀,先保存於此:
相關推薦
學習壓縮感知比較好的文章連結收藏
本文真的對我理解壓感起到很大的幫助,特別在OMP(正交匹配追蹤重構演算法)演算法的講解中,尤為精彩,我從來沒有見過哪個博主能如此認真的去一行一行地解釋,解讀程式碼,我對此十分感謝。個人認為,能有超過70%註釋的程式碼才是負責人的程式碼,當然也是好的程式碼。本文做到的不僅如此,
學習tensor好文章連結
形象的解釋神經網路啟用函式的作用是什麼? https://www.cnblogs.com/silence-tommy/p/7113405.html 為什麼要對資料進行歸一化處理? https://www.cnblogs.com/silence-tommy/p/7113498.html MNI
學習知識點的比較好的blog
樹狀數組 tor details pre http 第k大 res sdn fft 樹狀數組 https://blog.csdn.net/flushhip/article/details/79165701 FFT https://blog.csdn.net/ggn_20
大學生利用一些空閒時間學習什麼技能比較好?
誰的青春不迷茫,這句話好像一點也不假,因為高考之前的人生是一條單行道,一條道走到黑,沒有其他出口,不學習,你就走不下去。而大學之後的人生是隨機放射的蒲公英式飄蕩,沒有明確的落腳點,沒有明確的路線圖。在很多人看來,高考之前是服役,高考之後是退伍。部隊訓練那一套,究竟在社會上有沒有用,哪些素質能
Zookeeper技術文章連結收藏
http://www.cnblogs.com/shanyou/p/3221990.html Windows安裝和使用zookeeper http://blackproof.iteye.com/blog/2039040 zookeeper 入門講解例項 轉
技術文章,連結收藏.
--------------------------------------------------------------華麗的分隔線---------------------------------------------------------------------
java WEB專案中的異常處理(好文章連結)
http://blog.csdn.net/luqin1988/article/details/7970455 http://blog.csdn.net/luqin1988/article/details/7970782 http://blog.csdn.net/luq
關於深度學習的一些比較好的網站總結
神經網路模型之AlexNet的一些總結 http://www.cnblogs.com/gongxijun/p/6027747.html 卷積與濾波的一些特點
學習Python的比較好的網站
今天第一天接觸Python語言,它是如此的優雅,簡直是世界上最美的語言,讓人沉醉其中——題記 那麼對於新手,如何開始學習Python,有什麼比較好的社群或中文資料推薦呢? 1.Python3 中文手冊,釋出版本3.5.2 介紹了Python的基本知識和Python直譯器的
學習java必看--好文章
(1) 類名首字母應該大寫。欄位、方法以及物件(控制代碼)的首字母應小寫。對於所有識別符號,其中包含的所有單詞都應緊靠在一起,而且大寫中間單詞的首字母。例如: ThisIsAClassName thisIsMethodOrFieldName 若在定義中出現了常數初始化字元,
計算機視覺影象處理機器學習壓縮感知等論文程式碼大全
點選連結進入相關博文 主要包括: 1.影象去噪,編碼,去馬賽克,超分辨,分割,去模糊,紋理合成,修復,質量評估等 2.視訊編碼和目標追蹤,動作匹配,視覺追蹤
好文章收藏--五分鐘理解一致性哈希算法(consistent hashing)
角度 發生 out fonts http 空間 如果 ip地址 hash 一致性哈希算法在1997年由麻省理工學院提出的一種分布式哈希(DHT)實現算法,設計目標是為了解決因特網中的熱點(Hot spot)問題,初衷和CARP十分類似。一致性哈希修正了CARP使用的簡 單哈
遇到的比較好的文章
-s pos tail 方便 com 好的 font hashcode span 解決問題時遇到的比較好的文章,記錄下來,經常更新,方便查閱: 01. Java快速掃盲指南 02.hashcode()和equals()及HashSet判斷對象相等 遇到的比較好的文
斯坦福大學公開課機器學習:machine learning system design | data for machine learning(數據量很大時,學習算法表現比較好的原理)
ali 很多 好的 info 可能 斯坦福大學公開課 數據 div http 下圖為四種不同算法應用在不同大小數據量時的表現,可以看出,隨著數據量的增大,算法的表現趨於接近。即不管多麽糟糕的算法,數據量非常大的時候,算法表現也可以很好。 數據量很大時,學習算法表現比
學習英文比較好的網站
https://baijiahao.baidu.com/s?id=1605333674424297696&wfr=spider&for=pc 1、http://www.englishpage.com/ 2、http://www.breakingnewsenglish.com/
比較好的Python機器學習庫有哪些?
Python是一種面向物件的解釋型計算機程式設計語言,具有豐富和強大的庫,再加上其簡單、易學、速度快、開源免費、可移植性、可擴充套件性以及面向物件的特點,Python成為2017年最受歡迎的最受歡迎的程式語言! 人工智慧是當前最熱門話題之一,機器學習技術是人工智慧實現必備技能,Python程式語
JAVA高併發---收藏的好文章(持續更新)
JAVA高併發—AQS詳解(轉載) 學習前因 本來對多執行緒略懂,最近忽然看到了CountDownLatch 的用法,忽然想簡單看看它的原理,瞭解一下它阻塞執行緒的方法,我只知道阻塞執行緒的lock 和wait/notifyAll ,才發現原來還有LockSupport 的p
比較好的學習網站:易百教程網
比較好的學習網站:易百教程網 例如網站上關於pg和es的教程: postgrepSQL https://www.yiibai.com/html/postgresql/2013/080567.html Elasticsearch https://www.yiibai.com/e
一篇個人感覺比較好的lua入門的文章
Lua是一個嵌入式的指令碼語言,它不僅可以單獨使用還能與其它語言混合呼叫。Lua與其它指令碼語言相比,其突出優勢在於: 1. 可擴充套件性。Lua的擴充套件性非常卓越,以至於很多人把Lua用作搭建領域語言的工具(注:比如遊戲指令碼)。Lua被設計為易於擴充套件的,可以通過Lua程式碼或者 C程式碼擴充套件
計算機學習中有哪些比較好的刷題網…
ZOJ ZOJ :: Home POJ Welcome To PKU JudgeOnline HDOJ Welcome to Hangzhou Dianzi University Online Judge 三個是主流,任意選一個,認真做就可以了! 北京大學的Online Judge。POJ上面的題目有點