
爬蟲小白——利用pycharm爬取網頁內容
概述:
這是一個利用pycharm在phthon環境下做的一個簡單爬蟲分享,主要通過對豆瓣音樂top250的歌名、作者(專輯)的爬取來分析爬蟲原理
什麼是爬蟲?
我們要學會爬蟲,首先要知道什麼是爬蟲。
網路爬蟲(又被稱為網頁蜘蛛,網路機器人,在FOAF社群中間,更經常的稱為網頁追逐者),是一種按照一定的規則,自動地抓取全球資訊網資訊的程式或者指令碼。另外一些不常使用的名字還有螞蟻、自動索引、模擬程式或者蠕蟲。- 中文名
- 網路爬蟲
- 外文名
- web crawler
- 別 稱
- 網路蜘蛛
- 目 的
- 按要求獲取全球資訊網資訊
網路爬蟲是一個自動提取網頁的程式,它為搜尋引擎從全球資訊網上下載網頁,是搜尋引擎的重要組成。傳統爬蟲從一個或若干初始網頁的URL開始,獲得初始網頁上的URL,在抓取網頁的過程中,不斷從當前頁面上抽取新的URL放入佇列,直到滿足系統的一定停止條件。聚焦爬蟲的工作流程較為複雜,需要根據一定的網頁分析演算法過濾與主題無關的連結,保留有用的連結並將其放入等待抓取的URL佇列。然後,它將根據一定的搜尋策略從佇列中選擇下一步要抓取的網頁URL,並重覆上述過程,直到達到系統的某一條件時停止。另外,所有被爬蟲抓取的網頁將會被系統存貯,進行一定的分析、過濾,並建立索引,以便之後的查詢和檢索;對於聚焦爬蟲來說,這一過程所得到的分析結果還可能對以後的抓取過程給出反饋和指導。
準備工作:
使用工具:requests , lxml ,xpath
xpath是一門在xml文件中查詢資訊的語言。xpath可用來在xml文件中對元素和屬性進行遍歷。xpath的使用可以參考他的教程:話不多說,開始我們的爬蟲之旅
可以看到我們要獲取的歌名、作者(專輯)在頁面中有十頁,每頁十行

於是我們可以利用for迴圈來獲取目標:

然後用requests請求網頁:
import requestsheaders = {"User_Agent": "Mozilla/5.0(compatible; MSIE 5.5; Windows 10)"}
data = requests.get(url, headers=headers).text再用lxml解析網頁:
from lxml import etree
s = etree.HTML(data)
接下來就可以提取我們想要的資料了

最後把獲取到的資料儲存到我們想要放的地方就可以了
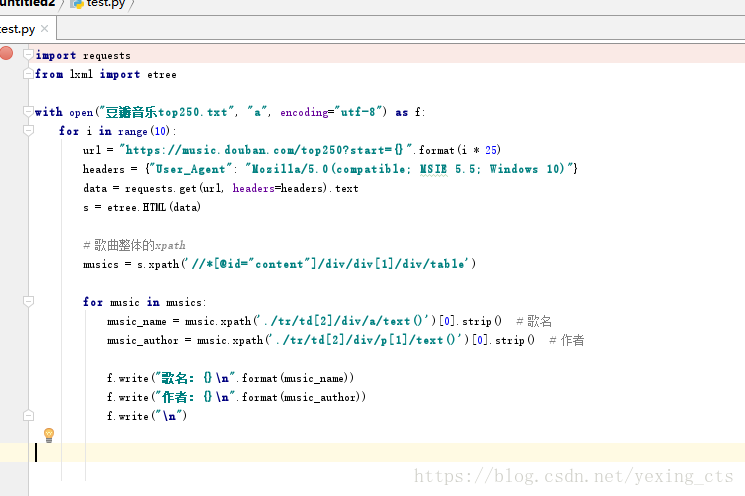
到了這裡,我們基本上完成了,完整程式碼如下:
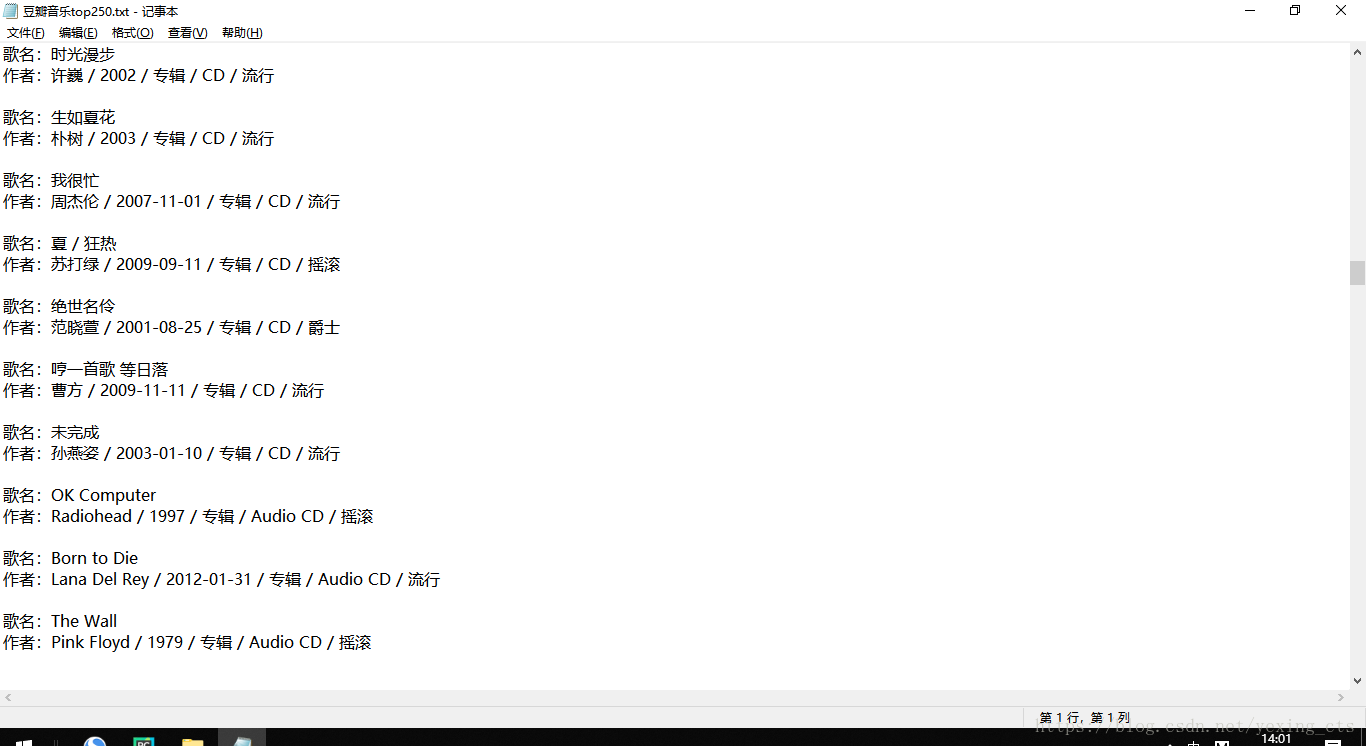
然後來看看我們爬取的成果
總結:
爬蟲流程:

1、發起請求
使用http庫向目標站點發起請求,即傳送一個Request
Request包含:請求頭、請求體等
Request模組缺陷:不能執行JS 和CSS 程式碼
2、獲取響應內容
如果伺服器能正常響應,則會得到一個Response
Response包含:html,json,圖片,視訊等
3、解析內容
解析html資料:正則表示式(RE模組),第三方解析庫如lxml,bs4等
解析json資料:json模組
解析二進位制資料:以wb的方式寫入檔案
4、儲存資料
資料庫(MySQL,Mongdb、Redis)
檔案
總而言之,爬蟲的流程就是爬取——解析——儲存相關推薦
爬蟲小白——利用pycharm爬取網頁內容
概述:這是一個利用pycharm在phthon環境下做的一個簡單爬蟲分享,主要通過對豆瓣音樂top250的歌名、作者(專輯)的爬取來分析爬蟲原理什麼是爬蟲?我們要學會爬蟲,首先要知道什麼是爬蟲。網路爬蟲(又被稱為網頁蜘蛛,網路機器人,在FOAF社群中間,更經常的稱為網頁追逐者
利用BeautifulSoup爬取網頁內容
利用BeautifulSoup可以很簡單的爬取網頁上的內容。這個套件可以把一個網頁變成DOM Tree 要使用BeautifulSoup需要使用命令列進行安裝,不過也可以直接用python的ide。 基礎操作 : ① 使用之前需要先從bs4中匯入包:from
Python爬蟲案例:利用Python爬取笑話網
htm 分享 targe pen 技術分享 搞笑 lan tle import 學校的服務器可以上外網了,所以打算寫一個自動爬取笑話並發到bbs的東西,從網上搜了一個笑話網站,感覺大部分還不太冷,html結構如下: 可以看到,笑話的鏈接列表都在<div cla
Java爬蟲學習《一、爬取網頁URL》
導包,如果是用的maven,新增依賴: <dependency> <groupId>commons-httpclient</groupId> <artifactId>commons
爬蟲實例 利用Ajax爬取微博數據
alt b2b 每次 png 微博 可變 實例 我們 images 隨著代理IP技術的普及,爬蟲的使用也變得簡單起來,許多企業和個人都開始用爬蟲技術來抓取數據。那麽今天就來分享一個爬蟲實例,幫助你們更好的理解爬蟲。下面我們用程序模擬Ajax請求,將我的前10頁微博全部爬取下
Python爬蟲:selenium掛shadowsocks代理爬取網頁內容
selenium掛ss代理爬取網頁內容 from selenium import webdriver from selenium.webdriver.chrome.options import Options from selenium.common.exceptions import
Selenium學習三——利用Python爬取網頁表格資料並存到excel
利用Python爬取網頁表格資料並存到excel 1、具體要求: 讀取教務系統上自己的成績單,並儲存到本地的excel中 2、技術要求: 利用Selenium+Python獲取網頁,自動登陸並操作到成績單頁面 通過xlwt模組,將表格儲存到本地excel (其中xlwt
利用python爬取網頁圖片
學習python爬取網頁圖片的時候,可以通過這個工具去批量下載你想要的圖片 開始正題: 我從尤物網去爬取我喜歡的女神的寫真照,我們這裡主要用到的就兩個模組 re和urllib模組,有的時候可能會用
爬蟲之Scrapy遞迴爬取網頁資訊
# -*- coding: utf-8 -*- import re import scrapy from zhipin.items import ZhipinItem class BossZhipinSpider(scrapy.Spider):
實戰 利用Xpath爬取網頁資料
#coding=utf-8 #step1 匯入模組 import re import requests from lxml import etree #抓取網頁原始碼 url = 'http://www.liaoxuefeng.com/wiki/001374738125095c955c1e6d8bb4931
利用Beautifulsoup爬取網頁圖片
BeautifulsoupBeautifulsop是一個python模組,該模組用於接收一個HTML或XML字元,然後將其進行格式化,之後便可以使用他提供的方式快速查詢指定的元素(如圖片,文字等),從而使得在html或xml中查詢指定元素比起用正則表示式更簡單。所用庫:for
python爬蟲實戰:利用pyquery爬取貓眼電影TOP100榜單內容-2
上次利用pyquery爬取貓眼電影TOP100榜單內容的爬蟲程式碼中點選開啟連結 存在幾個不合理點。1. 第一個就是自定義的create_file(檔案存在判斷及建立)函式。我在後來的python檔案功能相關學習中,發現這個自定義函式屬於重複造輪子功能。因為 for data
Selenium學習四——利用Python爬取網頁多個頁面的表格資料並存到已有的excel中
利用Python爬取網頁多個頁面的表格資料並存到已有的excel中 1、具體要求 獲取牛客網->題庫->線上程式設計->劍指Offer網頁,獲取表格中的全部題目,儲存到本地excel中 2、技術要求 利用Selenium+Python獲取網頁,操
爬蟲-----selenium模塊自動爬取網頁資源
pri 輸入文字 豆瓣 移動 相關 append 字符 scrollto value selenium介紹與使用 1 selenium介紹 什麽是selenium?selenium是Python的一個第三方庫,對外提供的接口可以操作瀏覽器,然後讓瀏覽器完成自動化的操
PHP爬取網頁內容
1.使用file_get_contents方法實現 $url = "http://www.baidu.com"; $html = file_get_contents($url); //如果出現中文亂碼使用下面程式碼 //$getcontent = iconv("
Python之簡單爬取網頁內容
爬去網頁通用流程 這樣看著雖然很麻煩,但是爬取網頁都離不開這四個步驟,以後如果爬取更復雜的網頁內容,只需要在這個基礎上新增內容就ok了。 import requests class Qiushi: # 初始化函式 def __init__(self,name):
JAVA爬取網頁內容
之前的文章沒有整理好,這邊重新標註一下,有需要可以到我的個人部落格看完整的三篇文章。在此之前,大家先了解一個Jsoup,一個html頁面解析的jar包。如果你上面的Jsoup看完了。前期準備工作:需要去檢視一下要爬的網頁的結構,對自己要爬的資料的標籤要熟悉。操作:在頁面上按F
python3定向爬取網頁內容
import requests import bs4 from bs4 import BeautifulSoup def getHTMLText(url): # 獲取網頁內容 try: r = requests.get(url, timeout=30) r.ra
PHP加JavaScript爬取網頁內容,超實用簡易教程
php+js爬取網頁內容—–先看下效果 如何做到的呢? 我們一直以為只有Python才能爬取網頁內容,那是因為Python本身集合很多類庫用來爬取網頁很方便,但是我們使用PHP+js的方法一樣很方便,一樣可以拿到我們想要的網頁內容,而且也不用很繁瑣。
使用HTTPURLConnection模擬登陸,爬取網頁內容
如果你需要爬取某些網頁的內容,但這些網站需要登入,那就需要一些額外的步驟來由程式來完成這些登入並爬取我們需要的網頁內容了,任意登入頁面都是向伺服器傳送請求,如果我們能夠模擬向伺服器傳送請求,那麼自然登入也就不在話下,通過Fiddler抓取我們需要的一些資訊,很輕鬆的就能模擬