
Spark SQL資料載入和儲存實戰
一:前置知識詳解:
Spark SQL重要是操作DataFrame,DataFrame本身提供了save和load的操作,
Load:可以建立DataFrame,
Save:把DataFrame中的資料儲存到檔案或者說與具體的格式來指明我們要讀取的檔案的型別以及與具體的格式來指出我們要輸出的檔案是什麼型別。
二:Spark SQL讀寫資料程式碼實戰:
import org.apache.spark.SparkConf;
import org.apache.spark.api.java.JavaRDD;
import org.apache.spark.api.java.JavaSparkContext 讀取過程原始碼分析如下:
1. read方法返回DataFrameReader,用於讀取資料。
/**
* :: Experimental ::
* Returns a [[DataFrameReader]] that can be used to read data in as a [[DataFrame]].
* {{{
* sqlContext.read.parquet("/path/to/file.parquet")
* sqlContext.read.schema(schema).json("/path/to/file.json")
* }}}
*
* @group genericdata
* @since 1.4.0
*/
@Experimental
//建立DataFrameReader例項,獲得了DataFrameReader引用
def read: DataFrameReader = new DataFrameReader(this)
2. 然後再呼叫DataFrameReader類中的format,指出讀取檔案的格式。
/**
* Specifies the input data source format.
*
* @since 1.4.0
*/
def format(source: String): DataFrameReader = {
this.source = source
this
}
3. 通過DtaFrameReader中load方法通過路徑把傳入過來的輸入變成DataFrame。
/**
* Loads input in as a [[DataFrame]], for data sources that require a path (e.g. data backed by
* a local or distributed file system).
*
* @since 1.4.0
*/
// TODO: Remove this one in Spark 2.0.
def load(path: String): DataFrame = {
option("path", path).load()
}
至此,資料的讀取工作就完成了,下面就對DataFrame進行操作。
下面就是寫操作!!!
1. 呼叫DataFrame中select函式進行對列篩選
/**
* Selects a set of columns. This is a variant of `select` that can only select
* existing columns using column names (i.e. cannot construct expressions).
*
* {{{
* // The following two are equivalent:
* df.select("colA", "colB")
* df.select($"colA", $"colB")
* }}}
* @group dfops
* @since 1.3.0
*/
@scala.annotation.varargs
def select(col: String, cols: String*): DataFrame = select((col +: cols).map(Column(_)) : _*)
2. 然後通過write將結果寫入到外部儲存系統中。
/**
* :: Experimental ::
* Interface for saving the content of the [[DataFrame]] out into external storage.
*
* @group output
* @since 1.4.0
*/
@Experimental
def write: DataFrameWriter = new DataFrameWriter(this)
3. 在保持檔案的時候mode指定追加檔案的方式
/**
* Specifies the behavior when data or table already exists. Options include:
// Overwrite是覆蓋
* - `SaveMode.Overwrite`: overwrite the existing data.
//建立新的檔案,然後追加
* - `SaveMode.Append`: append the data.
* - `SaveMode.Ignore`: ignore the operation (i.e. no-op).
* - `SaveMode.ErrorIfExists`: default option, throw an exception at runtime.
*
* @since 1.4.0
*/
def mode(saveMode: SaveMode): DataFrameWriter = {
this.mode = saveMode
this
}
4. 最後,save()方法觸發action,將檔案輸出到指定檔案中。
/**
* Saves the content of the [[DataFrame]] at the specified path.
*
* @since 1.4.0
*/
def save(path: String): Unit = {
this.extraOptions += ("path" -> path)
save()
}
三:Spark SQL讀寫整個流程圖如下:
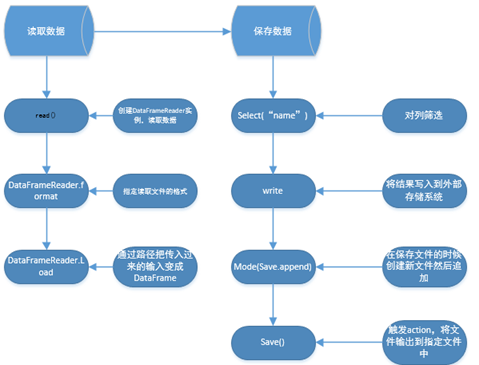
四:對於流程中部分函式原始碼詳解:
DataFrameReader.Load()
1. Load()返回DataFrame型別的資料集合,使用的資料是從預設的路徑讀取。
/**
* Returns the dataset stored at path as a DataFrame,
* using the default data source configured by spark.sql.sources.default.
*
* @group genericdata
* @deprecated As of 1.4.0, replaced by `read().load(path)`. This will be removed in Spark 2.0.
*/
@deprecated("Use read.load(path). This will be removed in Spark 2.0.", "1.4.0")
def load(path: String): DataFrame = {
//此時的read就是DataFrameReader
read.load(path)
}
2. 追蹤load原始碼進去,原始碼如下:
在DataFrameReader中的方法。Load()通過路徑把輸入傳進來變成一個DataFrame。
/**
* Loads input in as a [[DataFrame]], for data sources that require a path (e.g. data backed by
* a local or distributed file system).
*
* @since 1.4.0
*/
// TODO: Remove this one in Spark 2.0.
def load(path: String): DataFrame = {
option("path", path).load()
}
3. 追蹤load原始碼如下:
/**
* Loads input in as a [[DataFrame]], for data sources that don't require a path (e.g. external
* key-value stores).
*
* @since 1.4.0
*/
def load(): DataFrame = {
//對傳入的Source進行解析
val resolved = ResolvedDataSource(
sqlContext,
userSpecifiedSchema = userSpecifiedSchema,
partitionColumns = Array.empty[String],
provider = source,
options = extraOptions.toMap)
DataFrame(sqlContext, LogicalRelation(resolved.relation))
}
DataFrameReader.format()
1. Format:具體指定檔案格式,這就獲得一個巨大的啟示是:如果是Json檔案格式可以保持為Parquet等此類操作。
Spark SQL在讀取檔案的時候可以指定讀取檔案的型別。例如,Json,Parquet.
/**
* Specifies the input data source format.Built-in options include “parquet”,”json”,etc.
*
* @since 1.4.0
*/
def format(source: String): DataFrameReader = {
this.source = source //FileType
this
}
DataFrame.write()
1. 建立DataFrameWriter例項
/**
* :: Experimental ::
* Interface for saving the content of the [[DataFrame]] out into external storage.
*
* @group output
* @since 1.4.0
*/
@Experimental
def write: DataFrameWriter = new DataFrameWriter(this)
2. 追蹤DataFrameWriter原始碼如下:
以DataFrame的方式向外部儲存系統中寫入資料。
/**
* :: Experimental ::
* Interface used to write a [[DataFrame]] to external storage systems (e.g. file systems,
* key-value stores, etc). Use [[DataFrame.write]] to access this.
*
* @since 1.4.0
*/
@Experimental
final class DataFrameWriter private[sql](df: DataFrame) {
DataFrameWriter.mode()
1. Overwrite是覆蓋,之前寫的資料全都被覆蓋了。
Append:是追加,對於普通檔案是在一個檔案中進行追加,但是對於parquet格式的檔案則建立新的檔案進行追加。
/**
* Specifies the behavior when data or table already exists. Options include:
* - `SaveMode.Overwrite`: overwrite the existing data.
* - `SaveMode.Append`: append the data.
* - `SaveMode.Ignore`: ignore the operation (i.e. no-op).
//預設操作
* - `SaveMode.ErrorIfExists`: default option, throw an exception at runtime.
*
* @since 1.4.0
*/
def mode(saveMode: SaveMode): DataFrameWriter = {
this.mode = saveMode
this
}
2. 通過模式匹配接收外部引數
/**
* Specifies the behavior when data or table already exists. Options include:
* - `overwrite`: overwrite the existing data.
* - `append`: append the data.
* - `ignore`: ignore the operation (i.e. no-op).
* - `error`: default option, throw an exception at runtime.
*
* @since 1.4.0
*/
def mode(saveMode: String): DataFrameWriter = {
this.mode = saveMode.toLowerCase match {
case "overwrite" => SaveMode.Overwrite
case "append" => SaveMode.Append
case "ignore" => SaveMode.Ignore
case "error" | "default" => SaveMode.ErrorIfExists
case _ => throw new IllegalArgumentException(s"Unknown save mode: $saveMode. " +
"Accepted modes are 'overwrite', 'append', 'ignore', 'error'.")
}
this
}
DataFrameWriter.save()
1. save將結果儲存傳入的路徑。
/**
* Saves the content of the [[DataFrame]] at the specified path.
*
* @since 1.4.0
*/
def save(path: String): Unit = {
this.extraOptions += ("path" -> path)
save()
}
2. 追蹤save方法。
/**
* Saves the content of the [[DataFrame]] as the specified table.
*
* @since 1.4.0
*/
def save(): Unit = {
ResolvedDataSource(
df.sqlContext,
source,
partitioningColumns.map(_.toArray).getOrElse(Array.empty[String]),
mode,
extraOptions.toMap,
df)
}
3. 其中source是SQLConf的defaultDataSourceName
private var source: String = df.sqlContext.conf.defaultDataSourceName其中DEFAULT_DATA_SOURCE_NAME預設引數是parquet。
// This is used to set the default data source
val DEFAULT_DATA_SOURCE_NAME = stringConf("spark.sql.sources.default",
defaultValue = Some("org.apache.spark.sql.parquet"),
doc = "The default data source to use in input/output.")
DataFrame.scala中部分函式詳解:
1. toDF函式是將RDD轉換成DataFrame
/**
* Returns the object itself.
* @group basic
* @since 1.3.0
*/
// This is declared with parentheses to prevent the Scala compiler from treating
// `rdd.toDF("1")` as invoking this toDF and then apply on the returned DataFrame.
def toDF(): DataFrame = this
2. show()方法:將結果顯示出來
/**
* Displays the [[DataFrame]] in a tabular form. For example:
* {{{
* year month AVG('Adj Close) MAX('Adj Close)
* 1980 12 0.503218 0.595103
* 1981 01 0.523289 0.570307
* 1982 02 0.436504 0.475256
* 1983 03 0.410516 0.442194
* 1984 04 0.450090 0.483521
* }}}
* @param numRows Number of rows to show
* @param truncate Whether truncate long strings. If true, strings more than 20 characters will
* be truncated and all cells will be aligned right
*
* @group action
* @since 1.5.0
*/
// scalastyle:off println
def show(numRows: Int, truncate: Boolean): Unit = println(showString(numRows, truncate))
// scalastyle:on println
追蹤showString原始碼如下:showString中觸發action收集資料。
/**
* Compose the string representing rows for output
* @param _numRows Number of rows to show
* @param truncate Whether truncate long strings and align cells right
*/
private[sql] def showString(_numRows: Int, truncate: Boolean = true): String = {
val numRows = _numRows.max(0)
val sb = new StringBuilder
val takeResult = take(numRows + 1)
val hasMoreData = takeResult.length > numRows
val data = takeResult.take(numRows)
val numCols = schema.fieldNames.length
相關推薦
Spark SQL資料載入和儲存實戰
一:前置知識詳解: Spark SQL重要是操作DataFrame,DataFrame本身提供了save和load的操作, Load:可以建立DataFrame, Save:把DataFrame中的資料儲存到檔案或者說與具體的格式來指明我們要讀取的
Spark SQL 的資料載入與儲存(load , )
Spark SQL主要是操作DataFrame,DataFrame本身提供了save和load的操作. Load:可以建立DataFrame; Save:把DataFrame中的資料儲存到檔案或者說與具體的格式來指明我們要讀取的檔案的型別以及與具體的格式來指出我
(六)Hive SQL之資料型別和儲存格式
(六)Hive SQL之資料型別和儲存格式 目錄 一、資料型別 1、基本資料型別 2、複雜型別 二、儲存格式 (1)textfile (2)SequenceFile
Hive-5-Hive SQL之資料型別和儲存格式
原文地址:https://www.cnblogs.com/qingyunzong/p/8733924.html 一、資料型別 1.1、基本資料型別 Hive 支援關係型資料中大多數基本資料型別,和其他的SQL語言一樣,這些都是保留字。需要注意的是所有的這些資料型別都是對Java中介面的實
瞭解Spark SQL,DataFrame和資料集
關於Datasets和DataFrame API存在很多混淆,因此在本文中,我們將瞭解Spark SQL,DataFrames和Datasets。 Spark SQL 它是一個用於結構化資料處理的Spark模組,它允許您編寫更少的程式碼來完成工作,並且在底層,它可以智慧地
Spark Sql,Dataframe和資料集指南
概述 Spark SQL是一個spark模組,主要用於結構化資料的處理。不像基礎的spark RDD的API那麼抽象,該介面能夠對資料和資料的計算提供更多的資訊。Spark SQL使用這些額外的資
Spark SQL初始化和創建DataFrame的幾種方式
hdf per () med 分析 exception vat 都是 tty 一、前述 1、SparkSQL介紹 Hive是Shark的前身,Shark是SparkSQL的前身,SparkSQL產生的根本原因是其完全脫離了Hive的限制。
Beginning Data Exploration and Analysis with Apache Spark 使用Apache Spark開始資料探索和分析 中文字幕
使用Apache Spark開始資料探索和分析 中文字幕 Beginning Data Exploration and Analysis with Apache Spark 無論您是想要探索資料還是開發複雜的機器學習模型,資料準備都是任何資料專業人士的主要任務 Spark是一種引擎,它
python包-numpy資料讀取和儲存(二)
目錄 0.為什麼要使用numpy儲存資料 1.儲存為二進位制檔案(.npy/.npz)並讀取 numpy.save和numpy.load numpy.savez numpy.savez_compressed 2.儲存到文字檔案 numpy.savetxt nump
資料基礎---《利用Python進行資料分析·第2版》第6章 資料載入、儲存與檔案格式
之前自己對於numpy和pandas是要用的時候東學一點西一點,直到看到《利用Python進行資料分析·第2版》,覺得只看這一篇就夠了。非常感謝原博主的翻譯和分享。 訪問資料是使用本書所介紹的這些工具的第一步。我會著重介紹pandas的資料輸入與輸出,雖然別的庫中也有不少以此為目的的工具
pytorch中資料載入和處理例項
pytorch中資料載入和處理例項 **A lot of effort in solving any machine learning problem goes in to preparing the data. PyTorch provides many tools to make d
redis的資料型別和儲存結構
一,什麼是redis Redis(remote dictionary server)是一個基於KEY-VALUE的高效能的 儲存系統,通過提供多種鍵值資料型別來適應不同場景下的快取與儲存需求 。 二。redis的儲存結構 Redis比memached提供了更豐富
Spark SQL中thriftserver和beeline的使用
使用的前提是你已經安裝好了spark,在這裡我使用的版本是spark-2.0.2-bin-hadoop2.7,建議使用該版本,因為試了幾個版本都不理想,最後找到了這個版本感覺挺好的,學習Spark SQL很方便. 1. 首先是啟動thriftserver服務端:
ARM彙編:載入和儲存指令集(六大類)---LDR、LDRB、LDRH、STR、STRB、STRH
ARM的六大類指令集---LDR、LDRB、LDRH、STR、STRB、STRH ARM微處理器支援載入/儲存指令用於在暫存器和儲存器之間傳送資料,載入指令用於將儲存器中的資料傳送到暫存器,儲存指令則完成相反的操作。常用的載入儲存指令如下: — LDR 字資料載
ch6_01 Pandas 資料載入、儲存&檔案格式
輸入輸出通常分為以下幾大類:讀取文字檔案和其他的更高效的磁碟儲存格式、載入資料庫中的資料、利用Web API操作網路資源 6.1讀寫文字格式的資料 pandas提供了一些用於將表格型資料讀取為D
java 資料結構和儲存方式
Collection ├List │├LinkedList │├ArrayList │└Vector │ └Stack └Set Map ├Hashtable ├HashMap └WeakHashMap 通常linked開頭的都是雙向鏈。 ArrayList 和Ve
第80課:Spark SQL網站搜尋綜合案例實戰
內容: 1.案例分析 2.案例實戰 一、案例分析 專案:以京東找出搜尋平臺排名的產品,The hottest 元資料:date,u
第71課:Spark SQL視窗函式解密與實戰
內容: 1.SparkSQL視窗函式解析 2.SparkSQL視窗函式實戰 一、SparkSQL視窗函式解析 1.spark支援兩種方式使用視窗函式: &nb
ECharts官方教程(五)【非同步資料載入和更新】
非同步載入 入門示例中的資料是在初始化後setOption中直接填入的,但是很多時候可能資料需要非同步載入後再填入。ECharts 中實現非同步資料的更新非常簡單,在圖表初始化後不管任何時候只要通過 jQuery 等工具非同步獲取資料後通過 setOption
單機鬥地主——牌的資料分析和儲存
1.牌的花色 public enum Color{ Square, //方片 Club, //梅花 Heart, //紅桃 Spade, //黑桃 None //大王,小王 } 2.牌的大小 public enum Weight{ Three,