
【中文分詞】條件隨機場CRF
之前介紹的MMEM存在著label bias問題,因此Lafferty et al. [1] 提出了CRF (Conditional Random Field). BTW:比較有意思的是,這篇文章的二作與三作同時也是MEMM的作者。
1. 前言
本節將遵從tutorial [2] 的論文結構,從概率模型(Probabilistic Models)與圖表示(Graphical Representation)兩個方面引出CRF。
概率模型
Naïve Bayes(NB)是分類問題中的生成模型(generative model),以聯合概率\(P(x,y)=P(x|y)P(y)\)建模,運用貝葉斯定理求解後驗概率\(P(y|x)\)
\begin{equation}
P(x|y) P(y) = P(y) \prod _{j} P(x^{(j)}|y)
\label{eq:nb}
\end{equation}
HMM是用於對序列資料\(X\)做標註\(Y\)的生成模型,用馬爾可夫鏈(Markov chain)對聯合概率\(P(X,Y)\)建模:
\begin{equation}
P(X,Y) = \prod_t P(y_t|y_{t-1}) P(x_t|y_t)
\label{eq:hmm}
\end{equation}
然後,通過Viterbi演算法求解\(P(Y|X)\)的最大值。LR (Logistic Regression)模型是分類問題中的判別模型(discriminative model),直接用logistic函式建模條件概率\(P(y|x)\)。實際上,logistic函式是softmax的特殊形式(證明參看ufldl教程),並且LR等價於最大熵模型(這裡給出了一個簡要的證明),完全可以寫成最大熵的形式:
\begin{equation}
P_w(y|x) = \frac{exp \left( \sum_i w_i f_i(x,y) \right)}{Z_w(x)}
\label{eq:me}
\end{equation}
其中,\(Z_w(x)\)為歸一化因子,\(w\)為模型的引數,\(f_i(x,y)\)為特徵函式(feature function)——描述\((x,y)\)的某一事實。
CRF便是為了解決標註問題的判別模型,於是就有了下面這幅張圖(出自 [3]):
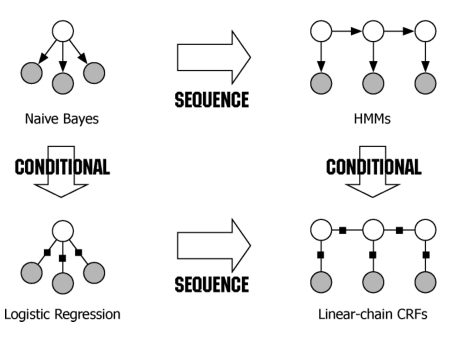
圖表示
概率模型可以用圖表示變數的相關(依賴)關係,所以概率模型常被稱為概率圖模型(probabilistic graphical model, PGM)。PGM對應的圖有兩種表示形式:independency graph, factor graph. independency graph直接描述了變數的條件獨立,而factor graph則是通過因子分解( factorization)的方式暗含變數的條件獨立。比如,NB與HMM所對應的兩種圖表示如下(圖出自[2]):
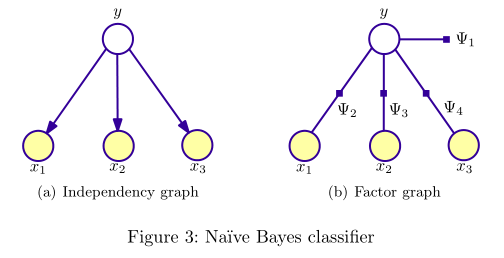
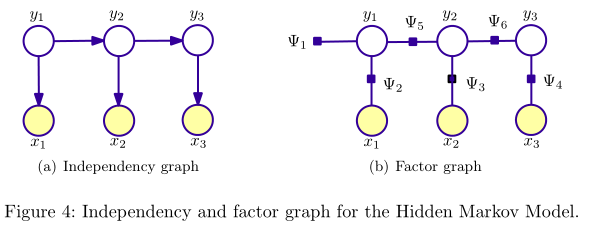
可以看出,NB與HMM所對應的independency graph為有向圖,圖\((V, E)\)所表示的聯合概率\(P(\overrightarrow{v})\)計算如下:
\[ P(\overrightarrow{v}) = \prod_k P(v_k|v_k^p) \]
其中,\(v_k\)為圖\((V, E)\)中一個頂點,其parent節點為\(v_k^p\)。根據上述公式,則上圖中NB模型的聯合概率:
\[ P(y,x_1, x_2, x_3) = P(y)P(x_1|y)P(x_2|y)P(x_3|y) \]
有別於NB模型,最大熵則是從全域性的角度來建模的,“保留儘可能多的不確定性,在沒有更多的資訊時,不擅自做假設”;特徵函式則可看作是人為賦給模型的資訊,表示特徵\(x\)與\(y\)的某種相關性。有向圖無法表示這種相關性,則採用無向圖表示最大熵模型:
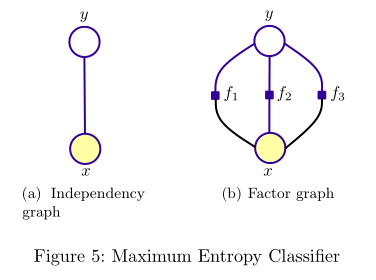
最大熵模型與馬爾可夫隨機場(Markov Random Field, MRF)所對應factor graph都滿足這樣的因子分解:
\begin{equation}
P(\overrightarrow{v}) = \frac{\prod_C \Psi_C(\overrightarrow{v_C})}{Z}
\label{eq:mrf}
\end{equation}
其中,\(C\)為圖的團(即連通子圖),\(\Psi_C\)為勢函式( potential function)。在最大熵模型中,勢函式便為\(exp(w_i f_i(x,y))\)的形式了。
2. CRF
前面提到過,CRF(更準確地說是Linear-chain CRF)是最大熵模型的sequence擴充套件、HMM的conditional求解。CRF假設標註序列\(Y\)在給定觀察序列\(X\)的條件下,\(Y\)構成的圖為一個MRF,即可表示成圖:
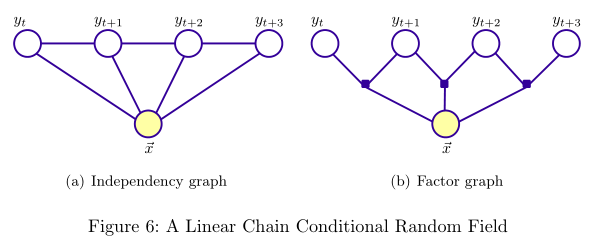
根據式子\eqref{eq:mrf},則可推匯出條件概率:
\[ P(Y|X) = \frac{\prod_j \Psi_j(\overrightarrow{x}, \overrightarrow{y})}{Z(\overrightarrow{x})} \]
同最大熵模型一樣,因子\(\Psi_j(\overrightarrow{x}, \overrightarrow{y})\)亦可以寫成特徵函式的exp形式:
\[ \Psi_j(\overrightarrow{x}, \overrightarrow{y}) = \exp \left( \sum_i \lambda_i f_i(y_{j-1}, y_j, \overrightarrow{x}) \right) \]
特徵函式之所以定義成\(f_i(y_{j-1}, y_j, \overrightarrow{x})\)而非$ f_i(y_j, \overrightarrow{x})$,是因為Linear-chain CRF對隨機場做了Markov假設。那麼,CRF建模的式子可改寫為
\[ \begin{aligned} P(Y|X) & = \frac{\exp \left( \sum_{i,j} \lambda_i f_i(y_{j-1}, y_j, \overrightarrow{x}) \right)}{Z(\overrightarrow{x})} \\ & = \frac{1}{Z(\overrightarrow{x})} \prod_j \exp \left( \sum_{i} \lambda_i f_i(y_{j-1}, y_j, \overrightarrow{x}) \right) \end{aligned} \]
MMEM也是用最大熵模型建模\(P(Y|X)\), 不同於CRF的是其採用有向圖模型,只考慮\(x_j\)對\(y_j\)的影響,而沒有把\(x\)作為整體來考慮,導致的是本地歸一化:
\[ P(Y|X) = \prod_j \frac{\exp \left( \sum_{i} \lambda_i f_i(y_{j-1}, y_j, \overrightarrow{x}) \right)}{Z(y_{j-1},\overrightarrow{x})} \]
而CRF做的則是全域性的歸一化,避免了label bias的問題。
3. 開源實現
Genius是一個基於CRF的開源中文分詞工具,採用了Wapiti做訓練與序列標註。
import genius
text = "深夜的穆赫蘭道發生一樁車禍,女子麗塔在車禍中失憶了"
seg_list = genius.seg_text(text)
print('/'.join([w.text for w in seg_list]))
# 深夜/的/穆赫蘭道/發生/一/樁/車禍/,/女子/麗塔/在/車禍/中/失憶/了 [CRF]
# 深夜/的/穆赫/蘭/道/發生/一/樁/車禍/,/女子/麗塔/在/車禍/中/失憶/了 [2-HMM]
# 深夜/的/穆赫蘭道/發生/一樁/車禍/,/女子麗塔/在/車禍/中/失憶/了 [HMM]可以看出,CRF在處理未登入詞比HMM的效果是要好的。當然,你可以用CRF++自己擼一箇中文分詞器。正好,52nlp的有一篇教程教你如何擼,用的是bakeoff2005 的訓練語料 msr_training.utf8。
Footnote: CRF原論文 [1] 與李航老師的《統計學習方法》關於CRF的推導引出,顯得比較突兀。相反,tutorial [2] 將NB、HMM、maxent (LR)與CRF串聯在一起,從Probabilistic Models、Graphical Representation的角度論述,非常容易理解——CRF是如何在考慮\(Y\)的相關性時對條件概率\(P(Y|X)\)建模的;為一篇不得不讀的經典的CRF tutorial。
4. 參考資料
[1] Lafferty, John, Andrew McCallum, and Fernando Pereira. "Conditional random fields: Probabilistic models for segmenting and labeling sequence data." Proceedings of the eighteenth international conference on machine learning, ICML. Vol. 1. 2001.
[2] Klinger, Roman, and Katrin Tomanek. Classical probabilistic models and conditional random fields. TU, Algorithm Engineering, 2007.
[3] Sutton, Charles, and Andrew McCallum. "An Introduction to Conditional Random Fields." Machine Learning 4.4 (2011): 267-373.
[4] shinchen2, 統計模型之間的比較. (為轉載連結)
[5] KevinXU, 如何理解馬爾可夫隨機場裡因子的表達?
相關推薦
【中文分詞】條件隨機場CRF
之前介紹的MMEM存在著label bias問題,因此Lafferty et al. [1] 提出了CRF (Conditional Random Field). BTW:比較有意思的是,這篇文章的二作與三作同時也是MEMM的作者。 1. 前言 本節將遵從tutorial [2] 的論文結構,從概率模型(Pr
【中文分詞】結構化感知器SP
結構化感知器(Structured Perceptron, SP)是由Collins [1]在EMNLP'02上提出來的,用於解決序列標註的問題。中文分詞工具THULAC、LTP所採用的分詞模型便是基於此。 1. 結構化感知器 模型 CRF全域性化地以最大熵準則建模概率\(P(Y|X)\);其中,\(X\)為
【中文分詞】隱馬爾可夫模型HMM
Nianwen Xue在《Chinese Word Segmentation as Character Tagging》中將中文分詞視作為序列標註問題(sequence tagging problem),由此引入監督學習演算法來解決分詞問題。 1. HMM 首先,我們將簡要地介紹HMM(主要參考了李航老師的《
【中文分詞】簡單高效的MMSeg
最近碰到一個分詞匹配需求——給定一個關鍵詞表,作為自定義分詞詞典,使用者query文字分詞後,是否有詞落入這個自定義詞典中?現有的大多數Java系的分詞方案基本都支援新增自定義詞典,但是卻不支援HDFS路徑的。因此,我需要尋找一種簡單高效的分詞方案,稍作包裝即可支援HDFS。MMSeg分詞演算法正是完美地契合
【中文分詞】二階隱馬爾可夫模型2-HMM
在前一篇中介紹了用HMM做中文分詞,對於未登入詞(out-of-vocabulary, OOV)有良好的識別效果,但是缺點也十分明顯——對於詞典中的(in-vocabulary, IV)詞卻未能很好地識別。主要是因為,HMM本質上是一個Bigram的語法模型,未能深層次地考慮上下文(context)。對於此,
【中文分詞】最大熵馬爾可夫模型MEMM
Xue & Shen '2003 [2]用兩種序列標註模型——MEMM (Maximum Entropy Markov Model)與CRF (Conditional Random Field)——用於中文分詞;看原論文感覺作者更像用的是MaxEnt (Maximum Entropy) 模型而非MEM
用條件隨機場CRF進行字標註中文分詞(Python實現)
本文運用字標註法進行中文分詞,使用4-tag對語料進行字標註,觀察分詞效果。模型方面選用開源的條件隨機場工具包“CRF++: Yet Another CRF toolkit”進行分詞。 本文使用的中文語料資源是SIGHAN提供的backof
【中文分詞系列】 8 更好的新詞發現演算法
分享一下我老師大神的人工智慧教程!零基礎,通俗易懂!http://blog.csdn.net/jiangjunshow 也歡迎大家轉載本篇文章。分享知識,造福人民,實現我們中華民族偉大復興!
Hadoop學習之自己動手做搜尋引擎【網路爬蟲+倒排索引+中文分詞】
一、使用技術 Http協議 正則表示式 佇列模式 Lucenne中文分詞 MapReduce 二、網路爬蟲 專案目的 通過制定url爬取介面原始碼,通過正則表示式匹配出其中所需的資源(這裡是爬取csdn部落格url及部落格名),將爬到的資源存
【中文分詞系列】 5. 基於語言模型的無監督分詞
轉載:https://spaces.ac.cn/archives/3956/ 迄今為止,前四篇文章已經介紹了分詞的若干思路,其中有基於最大概率的查詞典方法、基於HMM或LSTM的字標註方法等。這些都是已有的研究方法了,筆者所做的就只是總結工作而已。查詞典方法和字
條件隨機場CRF介紹
family play 存在 分布 als 建立 geo 捕捉 times 鏈接:https://mp.weixin.qq.com/s/BEjj5zJG3QmxvQiqs8P4-w softmax CRF主要用於序列標註問題,可以簡單理解為是給序列中的
簡明條件隨機場CRF介紹(附帶純Keras實現)
筆者去年曾寫過博文《果殼中的條件隨機場(CRF In A Nutshell)》,以一種比較粗糙的方式介紹了一下條件隨機場(CRF)模型。然而那篇文章顯然有很多不足的地方,比如介紹不夠清晰,也不夠完整,還沒有實現,在這裡我們重提這個模型,將相關內容補充完成。 本文是對CRF基本原理的一個簡明的介紹
概率模型(四):條件隨機場(CRF)
條件隨機場(Conditional Random Field,CRF)是一個比較重要的概率模型,在詳細介紹CRF之前,首先簡單介紹一下概率圖(Probabilistic Graphical Model,PGM),有時候簡稱圖模型(Graphical Model,
NLP --- 條件隨機場CRF(預測演算法詳解)
前幾節我們大概的介紹了學習演算法,即GIS和IIS的演算法,這兩個演算法在最大熵模型中講的比較詳細,想要深入理解這兩個演算法,需要你理解動態規劃演算法。這裡的條件隨機場實際上是根據最大熵模型的思想過來的,因為通過前面我們可以看出CRF演算法的目標公式就是按照最大熵演算法構造而來的,不同的是特徵函
NLP --- 條件隨機場CRF(概率計算問題)
上一節詳解的闡述了條件隨機場的定義和簡單的學習演算法推倒,這裡不懂的前翻看前兩節的部落格,這裡不再贅述,本節將主要求期望的問題,為什麼要求解期望?本節主要參考的內容是一篇論文和李航的書,論文是《Conditional Random Fields: An Introduction》 Hanna M
NLP --- 條件隨機場CRF背景
上一節我們主要講解了最大熵模型的原理,主要是解釋了什麼是最大熵,已經最大熵的背景知識,其實還是多建議大家讀讀論文,如果讀英語有點難度,那就看李航的《統計學習方法》的最大熵模型和條件隨機場,這本書的質量很高,本節主要講一些條件隨機場的背景知識,解釋為什麼需要引入條件隨機場,廢話不多說,下面開始:
機器學習 條件隨機場CRF
原文:http://blog.csdn.net/u010487568/article/details/46485673 CRF由來 條件隨機場(CRF)這種用來解決序列標註問題的機器學習方法是由John Lafferty於2001年發表在國際機器學習大
NLP-初學條件隨機場(CRF)
說明:學習筆記,內容參考《機器學習》《數學之美》和七月線上課件 條件隨機場 定義1: 條件隨機場(conditional random field,簡稱CRF)是一種判別式無向圖模型。生成式模型是直接對聯合分佈進行建模,而判別式模型則是對條件分佈
隱馬爾可夫(HMM)/感知機/條件隨機場(CRF)----詞性標註
筆記轉載於GitHub專案:https://github.com/NLP-LOVE/Introduction-NLP 7. 詞性標註 7.1 詞性標註概述 什麼是詞性 在語言學上,詞性(Par-Of-Speech, Pos )指的是單詞的語法分類,也稱為詞類。同一個類別的詞語具有相似的語法性質,所有詞性的集
【轉】中文分詞之HMM模型詳解
實現 含義 jieba 順序 清晰 bsp 中國 matrix 統計 關於HMM模型的介紹,網上的資料已經爛大街,但是大部分都是在背書背公式,本文在此針對HMM模型在中文分詞中的應用,講講實現原理。 盡可能的撇開公式,撇開推導。結合實際開源代碼作為例子,爭取做到雅俗共賞,