
Hive安裝及與HBase的整合
1 Hive簡介
Hive是一個基於Hadoop的開源資料倉庫工具,用於儲存和處理海量結構化資料。它把海量資料儲存於Hadoop檔案系統,而不是資料庫,但提供了一套類資料庫的資料儲存和處理機制,並採用類SQL語言對這些資料進行自動化管理和處理。我們可以把Hive中海量結構化資料看成一個個的表,而實際上這些資料是分散式儲存在HDFS 中的。Hive經過對語句進行解析和轉換,最終生成一系列基於Hadoop 的MapReduce任務,通過執行這些任務完成資料處理。
使用Hive的命令列介面,感覺很像操作關係資料庫,但是Hive和關係資料庫還是有很大的不同,具體總結如下:
一是儲存檔案的系統不同。Hive使用的是Hadoop的HDFS,關係資料庫則是伺服器本地的檔案系統。
二是計算模型不同。Hive使用MapReduce計算模型,而關係資料庫則是自己設計的計算模型。
三是設計目的不同。關係資料庫都是為實時查詢的業務設計的,而Hive則是為海量資料做資料探勘設計的,實時性很差。實時性的區別導致Hive的應用場景和關係資料庫有很大的不同。
四是擴充套件能力不同。Hive通過整合Hadoop使得很容易擴充套件自己的儲存能力和計算能力,而關係資料庫在這個方面要比資料庫差很多。
Hive的技術架構如下圖所示。
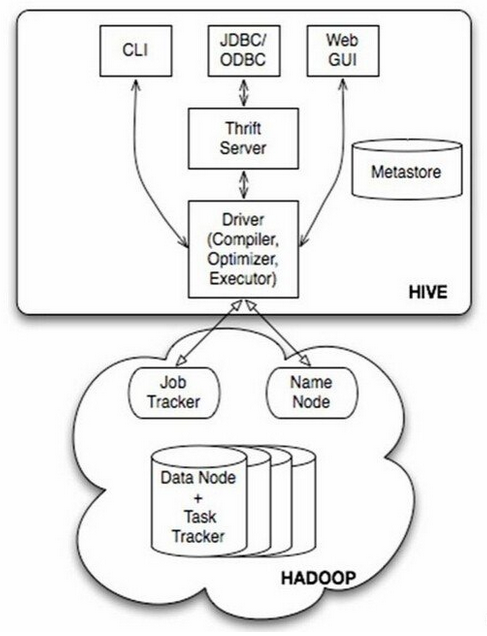
由上圖可知,Hadoop和MapReduce是Hive架構的根基。Hive架構包括如下元件:CLI(command line interface)、JDBC/ODBC、Thrift Server、Web GUI、Metastore和Driver(Complier、Optimizer和Executor),這些元件可分為服務端元件和客戶端元件兩大類。
首先來看服務端元件:
Driver元件包括Complier、Optimizer和Executor,它的作用是將我們寫的HiveQL語句進行解析、編譯優化,生成執行計劃,然後呼叫底層的MapReduce計算框架。
Metastore元件是元資料服務元件,它儲存Hive的元資料,Hive的元資料儲存在關係資料庫裡,支援的關係資料庫有derby和mysql。元資料對於Hive十分重要,因此Hive支援把Metastore服務獨立出來,安裝到遠端的伺服器叢集裡,從而解耦Hive服務和Metastore服務,保證Hive執行的健壯性。
Thrift Server是Facebook開發的一個軟體框架,它用來進行可擴充套件且跨語言的服務的開發,Hive集成了該服務,能讓不同的程式語言呼叫Hive的介面。
再來看看客戶端元件:
CLI即command lineinterface,命令列介面。
JDBC/ODBC 是Thrift的客戶端。
Web GUI是Hive客戶端提供的一種通過網頁的方式訪問Hive的服務。這個介面對應Hive的hwi元件,使用前要啟動hwi服務。
2 Hive內建服務
Hive自帶了許多服務,可在執行時通過service選項來明確指定使用什麼服務,或通過--service help來檢視幫助。下面介紹最常用的一些服務。
(1)CLI:這是Hive的命令列介面,用的比較多。這是預設的服務,直接可以在命令列裡面使用。
(2)hiveserver:這個可以讓Hive以提供Trift服務的伺服器形式來執行,可以允許許多不同語言編寫的客戶端進行通訊。可以通過設定HIVE_PORT環境變數來設定伺服器所監聽的埠號,在預設的情況下,埠為 10000。最新版本(hive1.2.1)用hiveserver2取代了原有的hiveserver。
(3)hwi:它是Hive的Web介面,是hive cli的一個web替換方案。
(4)jar:與Hadoop jar等價的Hive介面,這是執行類路徑中同時包含Hadoop和Hive類的Java應用程式的簡便方式。
(5)Metastore:用於連線元資料庫(如mysql)。在預設情況下,Metastore和Hive服務執行在同一個程序中,埠號為9083。使用這個服務,可以讓Metastore作為一個單獨的程序執行,我們可以通過METASTORE_PORT來指定監聽的埠號。
3 Metastore部署模式
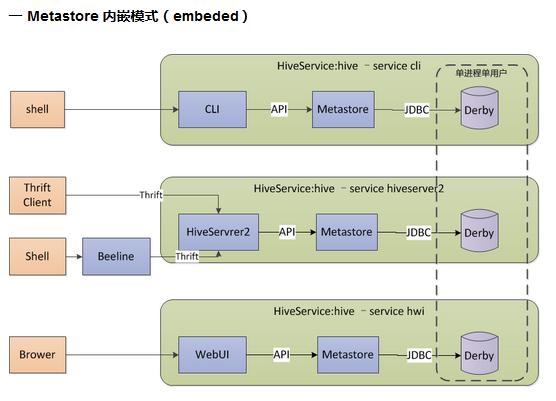
3.1 內嵌模式
內嵌模式使用內嵌的Derby資料庫儲存元資料,只能單使用者操作,一般用於單元測試。其架構圖如下所示。
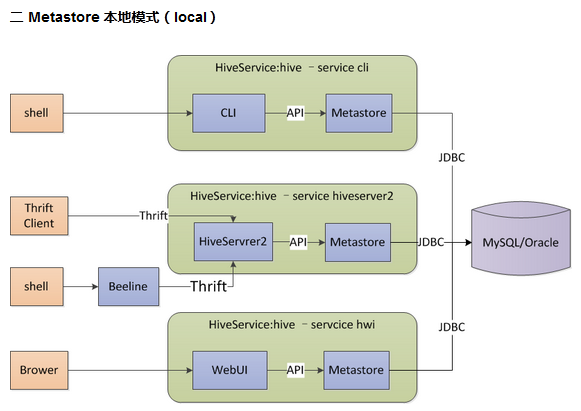
3.2 本地模式
本地模式與內嵌模式最大的區別在於資料庫由內嵌於hive服務變成獨立部署(一般為mysql資料庫),hive服務使用jdbc訪問元資料,多個服務可以同時訪問。mysql資料庫用於儲存元資料,可安裝在本地或遠端伺服器上,在配置檔案hive-site.xml中指定jdbc URL、驅動、使用者名稱、密碼等屬性。其中屬性hive.metastore.uris的值為空,表示為嵌入模式或本地模式。在本地模式中,每種hive服務(如cli、hiveserver2、hwi)都內建啟動了一個metastore服務,用於連線mysql元資料庫。其架構圖如下所示。
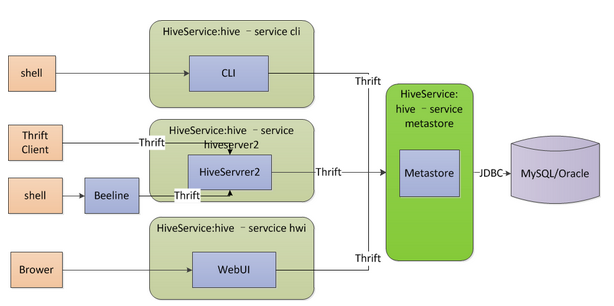
3.3 遠端模式
遠端模式將原內嵌於hive服務中的metastore服務獨立出來單獨執行,hive服務通過thrift訪問metastore,這種模式可以控制到資料庫的連線等。其中,metastore伺服器需要通過hive-site.xml配置jdbc URL、驅動、使用者名稱、密碼等屬性,hiveserver2伺服器和cli客戶端需要通過hive-site.xml配置hive.metastore.uris屬性,用於指定metastore服務地址(如thrift://localhost:9083),metastore伺服器通過./hive --service metastore開啟metastore服務,hiveserver2伺服器通過./hive --service hiveserver2開啟hiveserver服務,客戶端通過./hive shell 或./beeline進行連線。其架構圖如下所示。
遠端模式下可以按如下部署規劃:
(1)元資料伺服器:部署metastore服務和mysql資料庫。
(2)hiveserver伺服器:用於部署hiveserver2服務,可通過thrift訪問metastore。
(3)客戶伺服器:部署hive客戶端,可以基於cli、beeline或直接使用thrift訪問hiveserver2。
4 Hive本地模式的安裝
作業系統為ubuntu14.04,需要安裝並啟動Hadoop及HBase。
4.1 安裝MySQL
// 切換root使用者
$ su root
// 檢查mysql是否安裝
# netstat -tap | grep mysql
// 線上安裝mysql
# apt-get install mysql-server mysql-client
// 啟動mysql
# start mysql
// 設定開機自啟動
# /etc/init.d/mysql start
// 設定root使用者密碼
# mysqladmin -u root password 'root'
// 使用客戶端登入mysql
$ mysql -u root -p
// 建立hive使用者,密碼為hive
> create user 'hive' identified by 'hive';
// 建立資料庫hivemeta,用於存放hive元資料
> create database hivemeta;
// 將hivemeta資料庫的所有許可權賦予hive使用者,並允許遠端訪問
> grant all privileges on hivemeta.* to 'hive'@'%' identified by 'hive';
> flush privileges;
// 可檢視使用者hive的許可權情況
> use mysql;
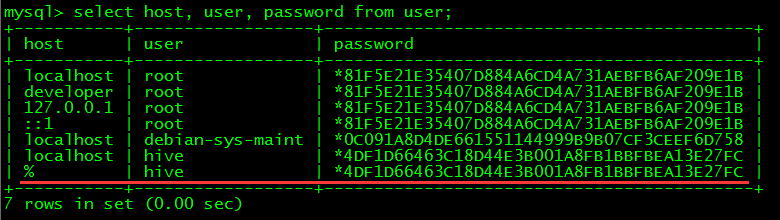
> select host, user, password from user;
4.2 安裝Hive
// 解壓安裝包
$ tar -xvf hive-1.1.0-cdh5.7.1.tar.gz
// 進入hive的配置目錄
$ cd hive-1.1.0-cdh5.7.1/conf/
// 修改hive-env.sh檔案
$ cp hive-env.sh.template hive-env.sh
$ vim hive-env.sh
HADOOP_HOME=/home/developer/app/hadoop-2.6.0-cdh5.7.1
// 建立hive-site.xml檔案並配置
$ vimhive-site.xml
<configuration>
<!-- 指定HDFS中的hive倉庫地址 -->
<property>
<name>hive.metastore.warehouse.dir</name>
<value>/hive/warehouse</value>
</property>
<!-- 該屬性為空表示嵌入模式或本地模式,否則為遠端模式 -->
<property>
<name>hive.metastore.uris</name>
<value></value>
</property>
<!-- 指定mysql的連線 -->
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://localhost:3306/hivemeta?createDatabaseIfNotExist=true</value>
</property>
<!-- 指定驅動類 -->
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.jdbc.Driver</value>
</property>
<!-- 指定使用者名稱 -->
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>hive</value>
</property>
<!-- 指定密碼 -->
<property>
<name>javax.jdo.option.ConnectionPassword</name>
<value>hive</value>
</property>
</configuration>
// 修改hive-log4j.properties指定日誌輸出路徑
$ cp hive-log4j.properties.template hive-log4j.properties
$ vim hive-log4j.properties
hive.root.logger=info,DRFA
hive.log.dir=/home/developer/app/hive-1.1.0-cdh5.7.1/logs
// 在http://www.mysql.com/products/connector/下載JDBC Driver for MySQL並複製到hive的lib目錄中
$ cp mysql-connector-java-5.1.39-bin.jar/home/developer/app/hive-1.1.0-cdh5.7.1/lib/
4.3 配置環境變數
$ cd ~
$ vim.bashrc
export HIVE_HOME=/home/developer/app/hive-1.1.0-cdh5.7.1
export PATH=$PATH:$HIVE_HOME/bin
$ source.bashrc
4.4 使用Hive Cli
// 啟動hive的cli服務
$ hive
// 測試
> show databases;

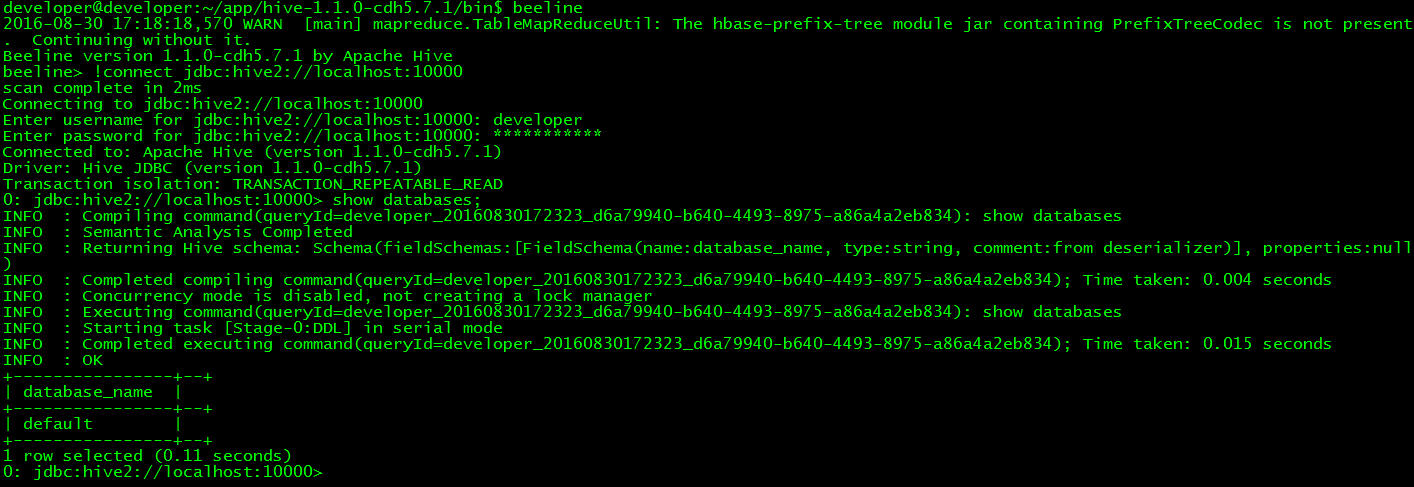
4.5 使用Beeline
// 後臺啟動hiveserver2
$nohup hive --service hiveserver2 &
注:beeline依賴hiveserver2提供的thirft服務,必須啟動,其預設埠為10000
// 使用beeline
$beeline
// 連線hive
> !connectjdbc:hive2://localhost:10000
注:需要通過hadoop使用者登入,否則沒有hdfs操作許可權
// 測試
> show databases;
4.6 功能測試
// 啟動hive的cli服務
$ hive
// 建立表
> create table user(id string,name string,age string) row format delimited fields terminated by '\t';
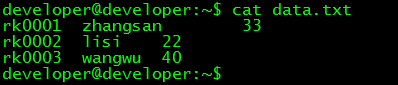
// 檢視測試資料
$ cat data.txt
// 將本地資料匯入hive
> load data local inpath '/home/developer/data.txt' overwrite into table user;
// 檢視匯入的資料
> select * from user;

// 檢視資料條數
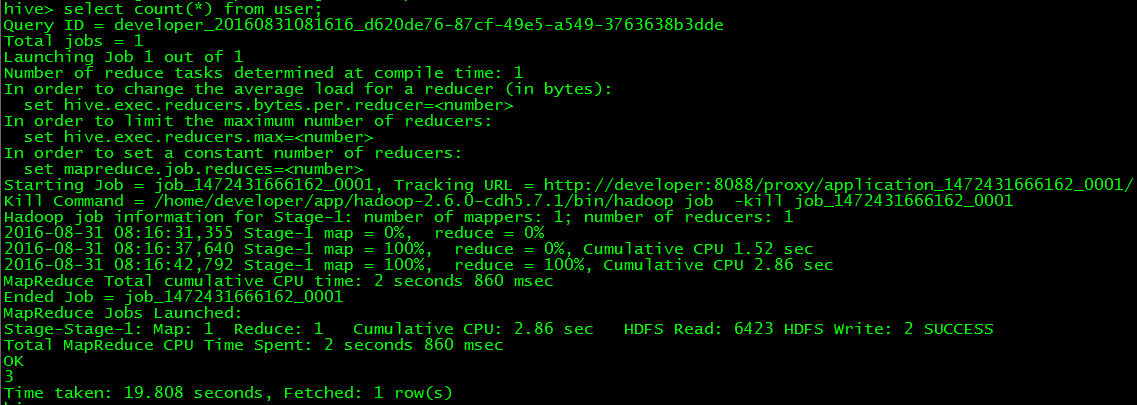
> select count(*) from user;
5 Hive整合HBase原理
Hive與HBase整合的實現是利用兩者本身對外的API介面互相通訊來完成的,其具體工作交由Hive的lib目錄中的hive-hbase-handler-*.jar工具類來實現,通訊原理如下圖所示。
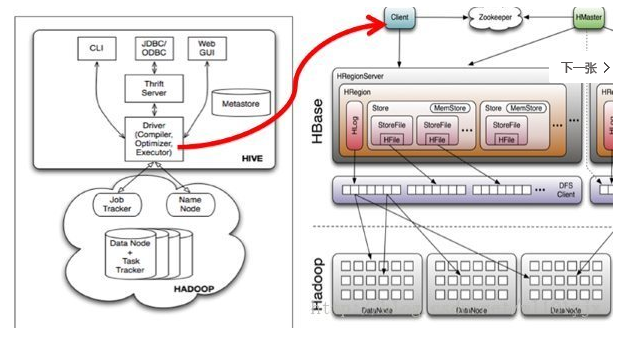
Hive整合HBase後的使用場景:
(一)通過Hive把資料載入到HBase中,資料來源可以是檔案也可以是Hive中的表。
(二)通過整合,讓HBase支援JOIN、GROUP等SQL查詢語法。
(三)通過整合,不僅可完成HBase的資料實時查詢,也可以使用Hive查詢HBase中的資料完成複雜的資料分析。
6 Hive整合HBase配置
6.1 Hive對映HBase表
// 如果hbase是叢集,需要修改hive-site.xml檔案配置
$ vim hive-site.xml
<property>
<name>hbase.zookeeper.quorum</name>
<value>node1,node2,node3</value>
</property>
// 將hbase lib目錄下的所有檔案複製到hive lib目錄中
$ cd app/hive-1.1.0-cdh5.7.1/
$ cp ~/app/hbase-1.2.0-cdh5.7.1/lib/* lib/
// 在hive中建立對映表
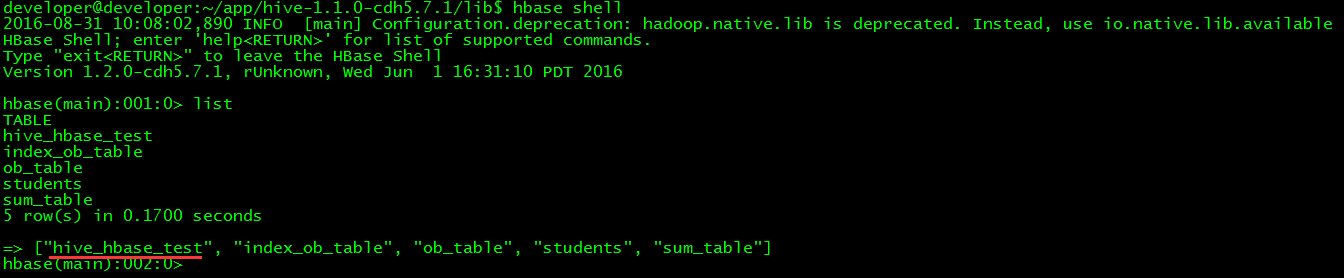
$ hive shell
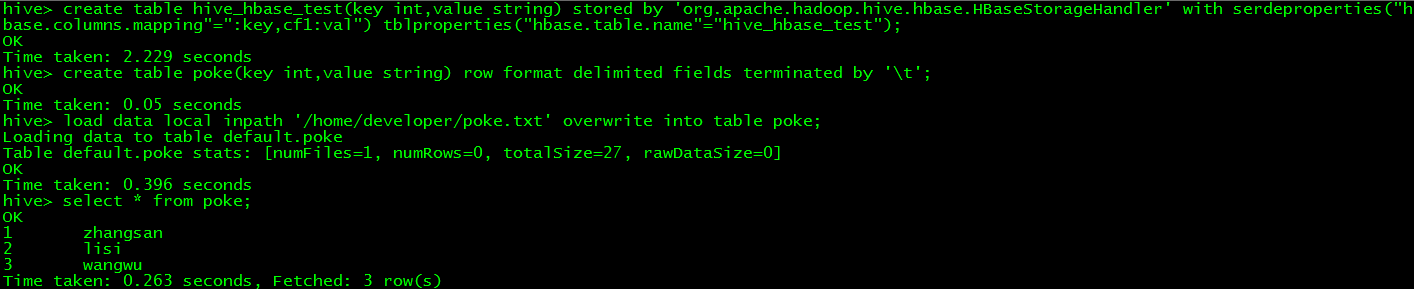
> create table hive_hbase_test(key int,value string) stored by 'org.apache.hadoop.hive.hbase.HBaseStorageHandler' with serdeproperties("hbase.columns.mapping"=":key,cf1:val") tblproperties("hbase.table.name"="hive_hbase_test");
備註:在hive中建立表hive_hbase_test,這個表包括兩個欄位(int型的key和string型的value),對映為hbase中的表hive_hbase_test,key對應hbase的rowkey,value對應hbase的cf1:val列。

// 在hbase中檢視是否存在對映表
$ hbase shell
> list
6.2 整合後功能測試
// 建立測試資料
$ vim poke.txt
1 zhangsan
2 lisi
3 wangwu

// 在hive中建立一個poke表並載入測試資料
> create table poke(key int,valuestring) row format delimited fields terminated by '\t';
> load data local inpath'/home/developer/poke.txt' overwrite into table poke;
> select * from poke;
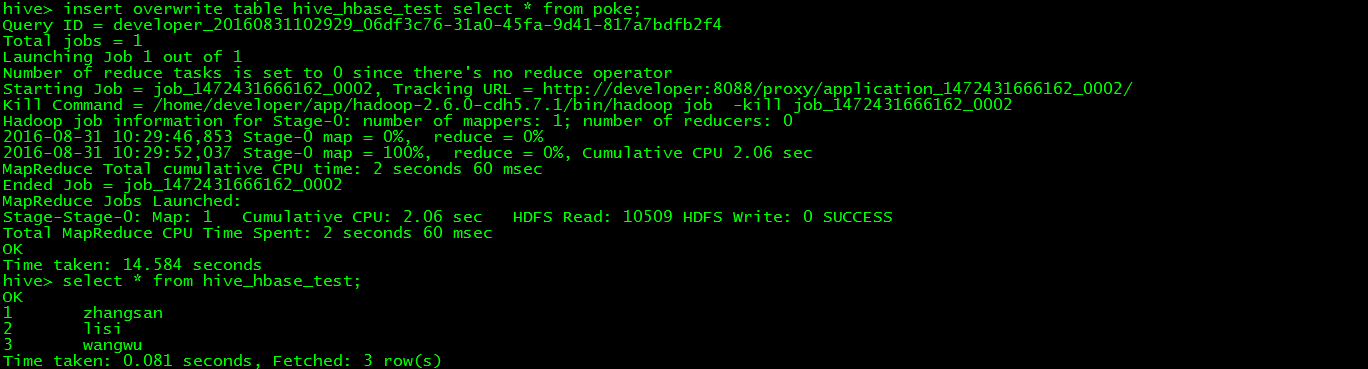
// 將hive的poke表中的資料載入到hive_hbase_test表
> insert overwrite table hive_hbase_test select * from poke;
> select * from hive_hbase_test;
// 檢視hbase的hive_hbase_test表中是否有同樣的資料
> scan 'hive_hbase_test'

需要說明以下幾點:
(一)Hive對映表的欄位是HBase表字段的子集。整合之後的Hive表不能被修改。
(二)Hive中的對映表不能直接插入資料,所以需要通過將資料載入到另一張poke表,然後通過查詢poke表將資料載入到對映表。
(三)上述示例是通過建立內部表的方式將Hive表對映到HBase表,HBase表會自動建立,而且Hive表被刪除後HBase表也會自動刪除。
(四)如果HBase表已有資料,可以通過建立Hive外部表的方式將Hive表對映到HBase表,通過HQLHive表實現對HBase表的資料分析。Hive表刪除將不會對HBase表造成影響。建立外部表的方法如下:
> create external table hive_hbase_test(key int,value string)stored by 'org.apache.hadoop.hive.hbase.HBaseStorageHandler' with serdeproperties("hbase.columns.mapping"=":key,cf1:val") tblproperties("hbase.table.name"="hive_hbase_test");
相關推薦
Hive安裝及與HBase的整合
1 Hive簡介 Hive是一個基於Hadoop的開源資料倉庫工具,用於儲存和處理海量結構化資料。它把海量資料儲存於Hadoop檔案系統,而不是資料庫,但提供了一套類資料庫的資料儲存和處理機制,並採用類SQL語言對這些資料進行自動化管理和處理。我們可以把Hive中海量結構化
mycat安裝及與springboot整合
1. mycat下載http://dl.mycat.io/1.6-RELEASE/2.解壓,配置環境變數,path=D:\software\Mycat-server-1.6-RELEASE-20161028204710-win\mycat\bin[mycat安裝地址]3.修改
Hadoop Hive與Hbase整合+thrift
分享一下我老師大神的人工智慧教程!零基礎,通俗易懂!http://blog.csdn.net/jiangjunshow 也歡迎大家轉載本篇文章。分享知識,造福人民,實現我們中華民族偉大復興!
Kafka的安裝及與Spring Boot的整合
安裝JDK 下載jdk-8u202-ea-bin-b03-linux-x64-07_nov_2018.tar.gz 解壓 配置 $ vi /etc/profile,在最後加入下面兩行 export JAVA_HOME=/usr/local/bigdata/jdk
elasticsearch安裝及與springboot2.x整合
關於elasticsearch是什麼、elasticsearch的原理及elasticsearch能幹什麼,就不多說了,主要記錄下自己的一個使用過程。 1、安裝 elasticsearch是用java編寫的,所以它的執行離不開jdk,jdk的安裝這裡不再囉嗦,我使用的是虛擬機器是centos7
Hive 1.x升級hive2.1.1全過程及與HBase的互通
1. 問題背景 在構建的大資料平臺上(相關元件版本Hadoop 2.8, hive 1.2.2, hbase 1.2.6) 利用hive-hbase-handler.jar實現hive和hbase的資料互通時,在hive中輸入命令後總是報錯, 先是Cannot find c
kafka安裝配置及與logstash整合
1、kafka安裝 下載 wget http://mirror.bit.edu.cn/apache/kafka/0.8.2.2/kafka_2.9.1-0.8.2.2.tgz 配置zookeeper vim bin/zookeeper-server-start.
Hive與HBase整合(例項)
例項1 1.先在Hbase中建立表(三列族): create 'ceshi7', {NAME=>'TIME',VERSIONS=>1,BLOCKCACHE=>true,BLOOMFILTER=>'ROW',COMPRESSION=>'SNA
Redis原理實戰安裝配置及與LAMP整合
Redis介紹 在大使用者量場景下,WEB系統如果每次都從資料庫裡獲取資料庫,將嚴重影響使用者體驗,為了提高使用者體驗,我們可以將使用者資料儲存在快取中。 常用的快取工具有:memcache和redis。 Redis是一個開源的使用ANSI C語言編寫、支援網路、可基於記憶
【伊利丹】Hadoop-2.5.0-CDH5.2.0/Hive與Hbase整合實驗
<value>file:///home/kkzhangtao/hive-0.13.1-cdh5.2.0/lib/hive-hbase-handler-0.8.0.jar,file:///home/kkzhangtao/hive-0.13.1-cdh5.2.0/lib/hbase-common-0.
hive與hbase整合
Hive整合HBase原理Hive與HBase整合的實現是利用兩者本身對外的API介面互相通訊來完成的,其具體工作交由Hive的lib目錄中的hive-hbase-handler-*.jar工具類來實現,通訊原理如下圖所示。Hive整合HBase後的使用場景:(一)通過Hiv
grafana安裝使用及與zabbix整合
開發十年,就只剩下這套架構體系了! >>>
Hive(一)---- Hive安裝及配置
joins hist query mysqld onf pass chmod 客戶 主機 Hive安裝及配置 下載hive安裝包 此處以hive-0.13.1-cdh5.3.6版本的為例,包名為:hive-0.13.1-cdh5.3.6.tar.gz 解壓Hive到安裝目錄
Kafka的安裝及與Spring Boot的集成
gin 消費者 ole 輸入 beginning bin tis sed 解壓 安裝JDK 下載jdk-8u202-ea-bin-b03-linux-x64-07_nov_2018.tar.gz 解壓 配置 $ vi /etc/profile,在最後加入下面兩行
Hive安裝及使用簡介
Hive簡介: 1、Hive在hadoop生態圈中屬於資料倉庫的角色。他能夠管理hadoop中的資料,同時可以查詢hadoop中的資料。 2、Hive其本質來講,是一個SQL解析引擎。Hive可以把SQL查詢轉換為MapReduce中的Job來執行(將HQL轉化成MR程式
fastdfs安裝和與nginx整合
完全參考部落格:https://blog.csdn.net/m0_37797991/article/details/73385161。有些自己遇到坑的地方記錄一下。 1.安裝依賴: yum install git gcc gcc-c++ make automake autoconf li
JDK安裝及與環境變數配置(親測有效)
裝JDK 選擇安裝目錄 安裝過程中會出現兩次 安裝提示 。第一次是安裝 jdk ,第二次是安裝 jre 。建議兩個都安裝在同一個java資料夾中的不同資料夾中。(不能都安裝在java資料夾的根目錄下,jdk和jre安裝在同一資料夾會出錯)。 我的安裝目錄如下: 第一步
hadoop學習筆記-hive安裝及操作
軟體下載: Mysql: Hive: 安裝環境: OS:Oracle redhad 5.6 x86 64bit Hadoop: hadoop-0.20.2 Mysql:mysql-5.5.24 Hive:hive-0.8.1 1. 安裝mysql -
hive安裝及mysql配置
一、Hive安裝 1.解壓hive,移動到指定目錄下 配置環境變數 export HIVE_HOME=/usr/local/hive export PATH=$PATH:$HIVE_HOME/bin 2.在hive/conf目錄下 cp hive-en
Hive安裝及啟動異常解決
前期準備 1、關於Hive的安裝包和文件可以從這裡獲取: 2、Hive依賴於Hadoop,關於Hadoop的安裝可以檢視這裡: 3、安裝mysql 由於Hive需要在資料庫中儲存元資料資訊,所以安裝hive之前需要先安裝mysql。h