
MySQL優化--索引
一、什麼是索引?
索引用來快速地尋找那些具有特定值的記錄,所有MySQL索引都以B-樹的形式儲存。如果沒有索引,執行查詢 時MySQL必須從第一個記錄開始掃描整個表的所有記錄,直至找到符合要求的記錄。表裡面的記錄數量越多,這個操作的代價就越高。如果作為搜尋條件的列上 已經建立了索引,MySQL無需掃描任何記錄即可迅速得到目標記錄所在的位置。如果表有1000個記錄,通過索引查詢記錄至少要比順序掃描記錄快100 倍。
假設我們建立了一個名為people的表:
CREATE TABLE people ( peopleid SMALLINT NOT NULL, name CHAR(50) NOT NULL );
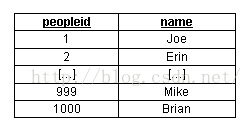
可以看到,在資料檔案中name列沒有任何明確的次序。如果我們建立了name列的索引,MySQL將在索引中排序name列:
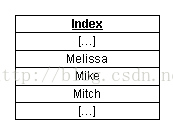
解釋:
對於索引中的每一項,MySQL在內部為它儲存一個數據檔案中實際記錄所在位置的“指標”。因此,如果我們要查詢name等於“Mike”記錄的peopleid(SQL命令為“SELECT peopleid FROM people WHERE name='Mike';”),MySQL能夠在name的索引中查詢“Mike”值,然後直接轉到資料檔案中相應的行,準確地返回該行的 peopleid(999)。在這個過程中,MySQL只需處理一個行就可以返回結果。如果沒有“name”列的索引,MySQL要掃描資料檔案中的所有 記錄,即1000個記錄!顯然,需要MySQL處理的記錄數量越少,則它完成任務的速度就越快。
二、索引型別
1、普通型索引
這是最基本的索引型別,而且它沒有唯一性之類的限制。普通索引可以通過以下幾種方式建立:
(1)建立索引,例如CREATE INDEX 索引的名字 ON tablename (列名1,列名2,...);
(2)修改表,例如ALTER TABLE tablename ADD INDEX 索引的名字 (列名1,列名2,...);
(3)建立表的時候指定索引,例如CREATE TABLE tablename ( [...], INDEX 索引的名字 (列名1,列名
2,...) );
2、唯一索引
這種索引和前面的“普通索引”基本相同,但有一個區別:索引列的所有值都只能出現一次,即必須唯一。唯一性索引可以用以下幾種方式建立:
(1)建立索引,例如CREATE UNIQUE INDEX 索引的名字 ON tablename (列的列表);
(2)修改表,例如ALTER TABLE tablename ADD UNIQUE 索引的名字 (列的列表);
(3)建立表的時候指定索引,例如CREATE TABLE tablename ( [...], UNIQUE 索引的名字 (列的列
表) );
3、主鍵
主 鍵是一種唯一性索引,但它必須指定為“PRIMARY KEY”。如果你曾經用過AUTO_INCREMENT型別的列,你可能已經熟悉主鍵之類的概念了。主鍵一般在建立表的時候指定,例如“CREATE TABLE tablename ( [...], PRIMARY KEY (列的列表) ); ”。但是,我們也可以通過修改表的方式加入主鍵,例如“ALTER TABLE tablename ADD PRIMARY KEY (列的列表); ”。每個表只能有一個主鍵。 (主鍵相當於聚合索引,是查詢最快的索引)
三、單列索引與多列索引
1,簡單介紹
索引可以是單列索引,也可以是多列索引。
(1)單列索引就是常用的一個列欄位的索引,常見的索引。
(2)多列索引就是含有多個列欄位的索引
下面就詳細介紹下這兩者的區別
假設有這樣一個people表:
CREATE TABLE people ( peopleid SMALLINT NOT NULL AUTO_INCREMENT, firstname CHAR(50) NOT NULL, lastname CHAR(50) NOT NULL, age SMALLINT NOT NULL, townid SMALLINT NOT NULL, PRIMARY KEY (peopleid) );對應結構如下:
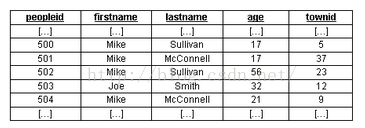
解釋:
這個資料片段中有四個名字為“Mikes”的人(其中兩個姓Sullivans,兩個姓McConnells),有兩個年齡為17歲的人,還有一個名字與眾不同的Joe Smith。這個表的主要用途是根據指定的使用者姓、名以及年齡返回相應的peopleid。
例如,我們可能需要查詢姓名為Mike Sullivan、年齡17歲使用者的peopleid(SQL命令為SELECT peopleid FROM people WHERE firstname='Mike' AND lastname='Sullivan' AND age=17;)。由於我們不想讓MySQL每次執行查詢就去掃描整個表,這裡需要考慮運用索引。
首先,我們可以考慮在單個列上建立索引,比如firstname、lastname或者age列。如果我們建立firstname列的索引(ALTER TABLE people ADD INDEX firstname (firstname);),MySQL將通過這個索引迅速把搜尋範圍限制到那些firstname='Mike'的記錄,然後再在這個“中間結果集”上進行其他條件的搜尋:它首先排除那些lastname不等於“Sullivan”的記錄,然後排除那些age不等於17的記錄。當記錄滿足所有搜尋條件之後,MySQL就返回最終的搜尋結果。
由於建立了firstname列的索引,與執行表的完全掃描相比,MySQL的效率提高了很多,但我們要求MySQL掃描的記錄數量仍舊遠遠超過了實際所需要的。雖然我們可以刪除firstname列上的索引,再建立lastname或者age列的索引,但總地看來,不論在哪個列上建立索引搜尋效率仍舊相似。
為了提高搜尋效率,我們需要考慮運用多列索引。如果為firstname、lastname和age這三個列建立一個多列索引,MySQL只需一次檢索就能夠找出正確的結果!下面是建立這個多列索引的SQL命令:
ALTER TABLE people ADD INDEX fname_lname_age (firstname,lastname,age);由於索引檔案以B-樹格式儲存,MySQL能夠立即轉到合適的firstname,然後再轉到合適的lastname,最後轉到合適的age。在沒有掃描資料檔案任何一個記錄的情況下,MySQL就正確地找出了搜尋的目標記錄!
那麼,如果在firstname、lastname、age這三個列上分別建立單列索引,效果是否和建立一個firstname、lastname、age的多列索引一樣呢?答案是否定的,兩者完全不同。當我們執行查詢的時候,MySQL只能使用一個索引。如果你有三個單列的索引,MySQL會試圖選擇一個限制最嚴格的索引。但是,即使是限制最嚴格的單列索引,它的限制能力也肯定遠遠低於firstname、lastname、age這三個列上的多列索引。
2,最左字首
多列索引還有另外一個優點,它通過稱為最左字首(Leftmost Prefixing)的概念體現出來。繼續考慮前面的例子,現在我們有一個firstname、lastname、age列上的多列索引,我們稱這個索引為fname_lname_age。當搜尋條件是以下各種列的組合時,MySQL將使用fname_lname_age索引:
- firstname,lastname,age
- firstname,lastname
- firstname
從另一方面理解,它相當於我們建立了(firstname,lastname,age)、(firstname,lastname)以及(firstname)這些列組合上的索引。下面這些查詢都能夠使用這個fname_lname_age索引:
SELECT peopleid FROM people WHERE firstname='Mike' AND lastname='Sullivan' AND age='17';
SELECT peopleid FROM people WHERE firstname='Mike' AND lastname='Sullivan';
SELECT peopleid FROM people WHERE firstname='Mike';以下查詢不能夠使用這個fname_lname_age索引:
SELECT peopleid FROM people WHERE lastname='Sullivan';
SELECT peopleid FROM people WHERE age='17';
SELECT peopleid FROM people WHERE lastname='Sullivan' AND age='17';總結:多列索引只有在where條件中含有索引中的首列欄位時才有效。
四、選擇索引列
在效能優化過程中,選擇在哪些列上建立索引是最重要的步驟之一。可以考慮使用索引的主要有兩種型別的列:在WHERE子句中出現的列,在join子句中出現的列。請看下面這個查詢:
SELECT age ## 不使用索引
FROM people WHERE firstname='Mike' ## 考慮使用索引
AND lastname='Sullivan' ## 考慮使用索引這個查詢與前面的查詢略有不同,但仍屬於簡單查詢。由於age是在SELECT部分被引用,MySQL不會用它來限制列選擇操作。因此,對於這個查詢來說,建立age列的索引沒有什麼必要。下面是一個更復雜的例子:
SELECT people.age, ##不使用索引
town.name ##不使用索引
FROM people LEFT JOIN town ON
people.townid=town.townid ##考慮使用索引
WHERE firstname='Mike' ##考慮使用索引
AND lastname='Sullivan' ##考慮使用索引與前面的例子一樣,由於firstname和lastname出現在WHERE子句中,因此這兩個列仍舊有建立索引的必要。除此之外,由於town表的townid列出現在join子句中,因此我們需要考慮建立該列的索引。
那麼,我們是否可以簡單地認為應該索引WHERE子句和join子句中出現的每一個列呢?差不多如此,但並不完全。我們還必須考慮到對列進行比較的操作符型別。MySQL只有對以下操作符才使用索引:<,<=,=,>,>=,BETWEEN,IN,以及某些時候的LIKE。可以在LIKE操作中使用索引的情形是指另一個運算元不是以萬用字元(%或者_)開頭的情形。例如,“SELECT peopleid FROM people WHERE firstname LIKE 'Mich%';”這個查詢將使用索引,但“SELECT peopleid FROM people WHERE firstname LIKE '%ike';”這個查詢不會使用索引。
五、分析索引效率
現在我們已經知道了一些如何選擇索引列的知識,但還無法判斷哪一個最有效。MySQL提供了一個內建的SQL命令幫助我們完成這個任務,這就是EXPLAIN命令。EXPLAIN命令的一般語法是:EXPLAIN <SQL命令>。你可以在MySQL文件找到有關該命令的更多說明。下面是一個例子:
EXPLAIN SELECT peopleid FROM people WHERE firstname='Mike' AND lastname='Sullivan' AND age='17';這個命令將返回下面這種分析結果:

下面我們就來看看這個EXPLAIN分析結果的含義:
- table:這是表的名字。
- type:連線操作的型別。下面是MySQL文件關於ref連線型別的說明:
“對於每一種與另一個表中記錄的組合,MySQL將從當前的表讀取所有帶有匹配索引值的記錄。如果連線操作只使用鍵的最左字首,或者如果鍵不是UNIQUE或PRIMARY KEY型別(換句話說,如果連線操作不能根據鍵值選擇出唯一行),則MySQL使用ref連線型別。如果連線操作所用的鍵只匹配少量的記錄,則ref是一種好的連線型別。”
在本例中,由於索引不是UNIQUE型別,ref是我們能夠得到的最好連線型別。
如果EXPLAIN顯示連線型別是“ALL”,而且你並不想從表裡面選擇出大多數記錄,那麼MySQL的操作效率將非常低,因為它要掃描整個表。你可以加入更多的索引來解決這個問題。預知更多資訊,請參見MySQL的手冊說明。 - possible_keys:
可能可以利用的索引的名字。這裡的索引名字是建立索引時指定的索引暱稱;如果索引沒有暱稱,則預設顯示的是索引中第一個列的名字(在本例中,它是“firstname”)。預設索引名字的含義往往不是很明顯。 - Key:
它顯示了MySQL實際使用的索引的名字。如果它為空(或NULL),則MySQL不使用索引。 - key_len:
索引中被使用部分的長度,以位元組計。在本例中,key_len是102,其中firstname佔50位元組,lastname佔50位元組,age佔2位元組。如果MySQL只使用索引中的firstname部分,則key_len將是50。 - ref:
它顯示的是列的名字(或單詞“const”),MySQL將根據這些列來選擇行。在本例中,MySQL根據三個常量選擇行。 - rows:
MySQL所認為的它在找到正確的結果之前必須掃描的記錄數。顯然,這裡最理想的數字就是1。 - Extra:
這裡可能出現許多不同的選項,其中大多數將對查詢產生負面影響。在本例中,MySQL只是提醒我們它將用WHERE子句限制搜尋結果集。
六、索引的缺點
首先,索引要佔用磁碟空間。通常情況下,這個問題不是很突出。但是,如果你建立每一種可能列組合的索引,索引檔案體積的增長速度將遠遠超過資料檔案。如果你有一個很大的表,索引檔案的大小可能達到作業系統允許的最大檔案限制。
其次,對於需要寫入資料的操作,比如DELETE、UPDATE以及INSERT操作,索引會降低它們的速度。這是因為MySQL不僅要把改動資料寫入資料檔案,而且它還要把這些改動寫入索引檔案。
【結束語】在大型資料庫中,索引是提高速度的一個關鍵因素。不管表的結構是多麼簡單,一次500000行的表掃描操作無論如何不會快。如果你的網站上也有這種大規模的表,那麼你確實應該花些時間去分析可以採用哪些索引,並考慮是否可以改寫查詢以優化應用。
相關推薦
MySQL優化——索引
即使 sel 屬於 能力 來看 yun 特定 比較 ont 內容來自:https://yq.aliyun.com/articles/214494?utm_content=m_31338 對此我們來詳細分析下(也就是大家在面試時需要說的): 場景一,數據表規模不大,就
6.MySQL優化索引合併優化
介紹 索引合併訪問方法檢索具有多個範圍掃描的行併合並其結果合而為一。 此訪問方法僅合併來自單個表的索引掃描,而不是跨多個掃描表。 合併可以生成其基礎掃描的聯合,交叉或交叉聯合。 下面舉個例子介紹一下如何使用: SELECT * FROM tbl_name WHERE key1 =
MySQL優化索引及優化漢字模糊查詢語句
利用MySQL這種關係型資料庫來做索引,的確有些勉強了,也只能看情況來說了,有些簡單的功能還是可以考慮的。 對於模糊查詢語句,最不利的情況是要like '%key%'這樣的查詢,但是如果是like 'key%'這種情況,那麼mysql的索引在些查詢方式上還是可以優化的。 網
MySQL優化----索引
一、主鍵索引 建立主鍵索引 索引名規範:ix_表名_欄位名 語法: create index 索引名 on 表名(欄位名) 檢視索引是否建立成功 show index from 表名\G; 二、
MySQL優化--索引
一、什麼是索引? 索引用來快速地尋找那些具有特定值的記錄,所有MySQL索引都以B-樹的形式儲存。如果沒有索引,執行查詢 時MySQL必須從第一個記錄開始掃描整個表的所有記錄,直至找到符合要求的記錄。表裡面的記錄數量越多,這個操作的代價就越高。如果作為搜尋條件的列上 已經
mysql優化-索引
一、什麼是索引? 索引用來快速地尋找那些具有特定值的記錄,所有MySQL索引都以B-樹的形式儲存。如果沒有索引,執行查詢時MySQL必須從第一個記錄開始掃描整個表的所有記錄,直至找到符合要求的記錄。表裡面的記錄數量越多,這個操作的代價就越高。如果作為搜尋條件的列上已經建
MySql優化-索引命中
在專案開發中SQL是必不可少的,表索也一樣.這些SQL的執行效能不知道嗎?有多少是命中了索引的?命中哪個索引?索引中有哪個是無效索引?這些無效索引是否會影響系統的效能?帶著這些問題我們一起來學習一下. MySql中是通過 Explain 命令來分析低效SQL
mysql優化 索引基本用法
說起提高資料庫效能,索引是最物美價廉的東西了。不用加記憶體,不用改程式,不用調sql,只要執行個正確的’create index’,查詢速度就可能提高百倍千倍,這可真有誘惑力。可是天下沒有免費的午餐,查詢速度的提高是以插入、更新、刪除的速度為代價的,這些寫
mysql優化 索引優化策略
索引優化策略 1:索引型別 1.1 B-tree索引 注: 名叫btree索引,大的方面看,都用的平衡樹,但具體的實現上, 各引擎稍有不同,比如,嚴格的說,NDB引擎,使用的是T-tree,而Myisam,innodb中,預設用B-
MySQL優化索引
1. MySQL如何使用索引 索引用於快速查詢具有特定列值的行。如果沒有索引,MySQL必須從第一行開始,然後遍歷整個表以找到相關的行。表越大,花費越多。如果表中有相關列的索引,MySQL可以快速確定要在資料檔案中間查詢的位置,而不必檢視所有資料。這比順序讀取每一行要快得多。 大多數MySQL索引
MySQL的索引及其優化
告訴 出現 緩存 tab 關鍵字 忽略 primary lba lec 前言 索引對查詢的速度有著至關重要的影響,理解索引也是進行數據庫性能調優的起點。考慮如下情況,假設數據庫中一個表有10^6條記錄,DBMS的頁面大小為4K,並存儲100條記錄。如果沒有索引,查詢將對整個
mysql-優化班學習-8-20170606-MySQL索引
ng- 文件 mar 索引 b+樹 xtend pen 自增列 .net MySQL索引 索引、事務、鎖、InnoDB引擎 tablespace\segment\extended\page\row gao
MySQL性能優化的21個最佳實踐 和 mysql使用索引
oct 靜態 state zid 希望 lte 適合 實踐 打開 今天,數據庫的操作越來越成為整個應用的性能瓶頸了,這點對於Web應用尤其明顯。關於數據庫的性能,這並不只是DBA才需要擔心的事,而這更是我 們程序員需要去關註的事情。當我們去設計數據庫表結構,對操作數據庫時(
mysql優化之索引
總結 例如 drop mysql5 建立 語句 運算操作 空間 耗時 Mysql優化之使用索引 1,索引簡介 索引是單獨一種數據結構,單獨存在的一個空間。可以把數據表裏的建立了索引的字段,進和物理地址,存在在一塊,這塊空間就是‘索引’。 查詢數據先從索引中查詢,查詢到之後,
mysql 優化策略(如何利用好索引)
i/o 建立索引 lar .net https 壓縮 oracle 包括 analyze 命名規則:表名_字段名1、需要加索引的字段,要在where條件中2、數據量少的字段不需要加索引3、如果where條件中是OR關系,加索引不起作用4、符合最左原則https://segm
mysql優化和索引
索引 mysql優化 表的優化1.定長與變長分離 如 int,char(4),time核心且常用字段,建成定長,放在一張表; 而varchar,text,blob這種變長字段適合單放一張表,用主鍵與核心表關聯。2.常用字段和不常用字段要分離3.在 1 對多需要關聯統計的字段上,添加冗余字段
「mysql優化專題」90%程序員面試都用得上的索引優化手冊(5)
根據 eat index 重要 進行 需要 範圍查詢 記錄 文件的 目錄(技術文) 多關於索引,分為以下幾點來講解: 一、索引的概述(什麽是索引,索引的優缺點) 二、索引的基本使用(創建索引) 三、索引的基本原理(面試重點) 四、索引的數據結構(B樹,hash) 五、創建索
「mysql優化專題」單表查詢優化的一些小總結,非索引設計(3)
flush src innodb atp show 優化 ase 驗證 where子句 單表查詢優化:(關於索引,後面再開單章講解) (0)可以先使用 EXPLAIN 關鍵字可以讓你知道MySQL是如何處理你的SQL語句的。這可以幫我們分析是查詢語句或是表結構的性能瓶頸。
3.MySQL優化---單表查詢優化的一些小總結(非索引設計)
sql優化 所有 結果集 單表 搜索 結果 查詢語句 cnblogs sel 整理自互聯網.摘要: 接下來這篇是查詢優化。其實,大家都知道,查詢部分是遠遠大於增刪改的,所以查詢優化會花更多篇幅去講解。本篇會先講單表查詢優化(非索引設計)。然後講多表查詢優化。索引優化設計以及
MySQL 之 索引原理與慢查詢優化
英文 borde 發生 聚集 引擎 返回 位置 時間 pro 一 索引介紹 二 索引類型 三 索引分類 四 聚合索引和輔助索引 五 測試索引 六 正確使用索引 七 組合索引 八 註意事項 九 查詢計劃 十 慢日誌查詢 十一 大數據量分頁優化 1. 索引介紹