
TensorFlow (一) 從入門到實踐
一、TnesorFlow 計算模型————計算圖
1、 計算圖概念
1.1 Tensor
Tensor就是張量, 可以簡單理解為多維陣列,表明了資料結構
1.2 Flow
Flow 表達了張量之間通過計算相互轉化的過程,體現了資料模型
1.3 資料流圖基礎
資料流圖是每個 TensorFlow 程式的核心,用於定義計算結構
每一個節點都是一個運算,每一條邊代表了計算之間的依賴關係
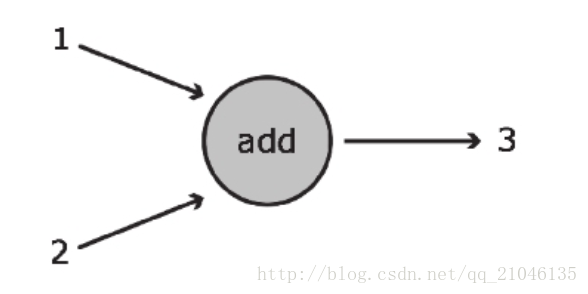
上圖展示了可完成基本加法運算的資料流圖。在該圖中,加法運算是用圓圈表示的,它可接收兩個輸入 (以指向該函式的箭頭表示),並將 1 和 2 之和 3 輸出 (對應從該函式引出的箭頭)。該函式的運算結果可傳遞給其他函式,也可直接返回給客戶。
節點(node) :
在資料流圖的語境中,節點通常以圓圈、橢圓和方框表示,代表了對資料所做的運算或某種操作。在上例中,“add”對應於一個孤立節點。
邊(edge) :
對應於向Operation傳入和從Operation傳出的實際數值,通常以箭頭表示。在“add”這個例子中,輸入1和2均為指向運算節點的邊,而輸出3則為 從運算節點引出的邊。可從概念上將邊視為不同Operation之間的連線,因為它們將資訊從一個節點傳輸到另一個節點。
2、計算圖的使用
TensorFlow 程式一般可以分成兩個階段
第一階段 定義計算圖中的所有計算
第二階段 為執行計算
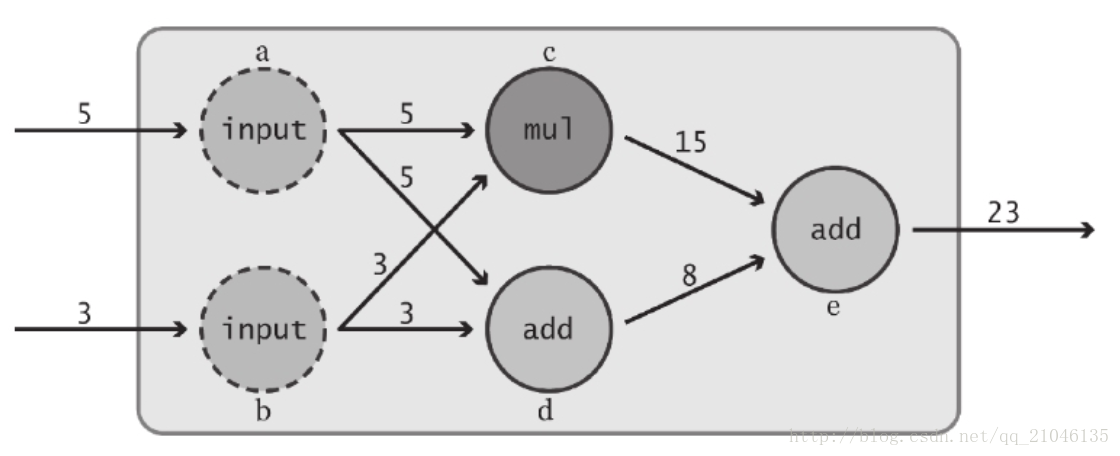

這裡定義了 “input” 節點 a 和 b。語句第一次引用了 TensorFlow Operation:tf.constant()。在 TensorFlow 中,資料流圖中的每個節點都被稱為一個 Operation (簡記為 Op )。各 Op 可接收 0 個或多個 Tensor 物件作為輸入,並輸出 0 個或多個 Tensor 物件。要建立一個 Op,可呼叫與其關聯的 Python 構造方法,在本例中,tf.constant() 建立了一個 “常量” Op,它接收單個張量值,然後將同樣的值輸出給與其直接連線的節點。為方便起見,該函式自動將標量值 6 和 3 轉換為 Tensor 物件。此外,我們還為這個構造方法傳入了一個可選的字串引數 name,用於對所建立的節點進行標識。
3、資料流圖的視覺化
3.1 新增程式碼
writer = tf.summary.FileWriter('./my_graph', sess.graph)
3.2 在 Terminal 輸入命令
tensorboard --logdir="my_graph"如圖所示即成功
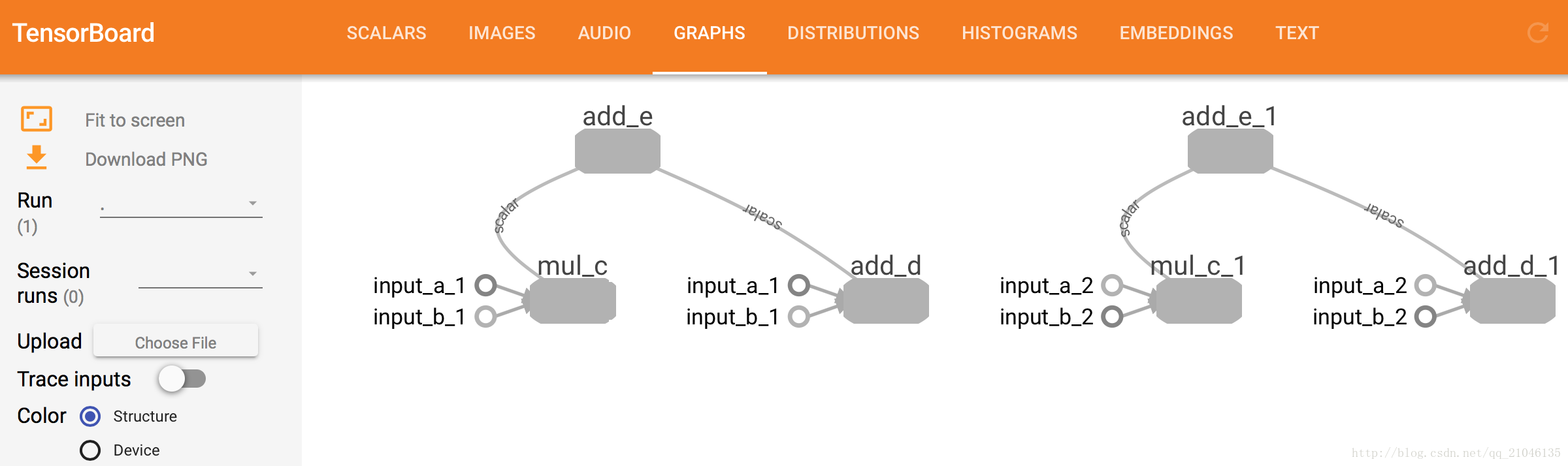
切換到 GRAPHS 導航欄,就能看到資料流圖
二、TnesorFlow 資料模型————張量
2.1 Python原生型別
TensorFlow 可接收 Python 數值、布林值、字串或由它們構成的列表。單個數值將被轉化為 0 階張量(或標量),數值列表將被轉化為 1 階張量(向量),由列表構成的列表將被轉化為 2 階張量(矩陣),以此類推。下面給出一些例子。

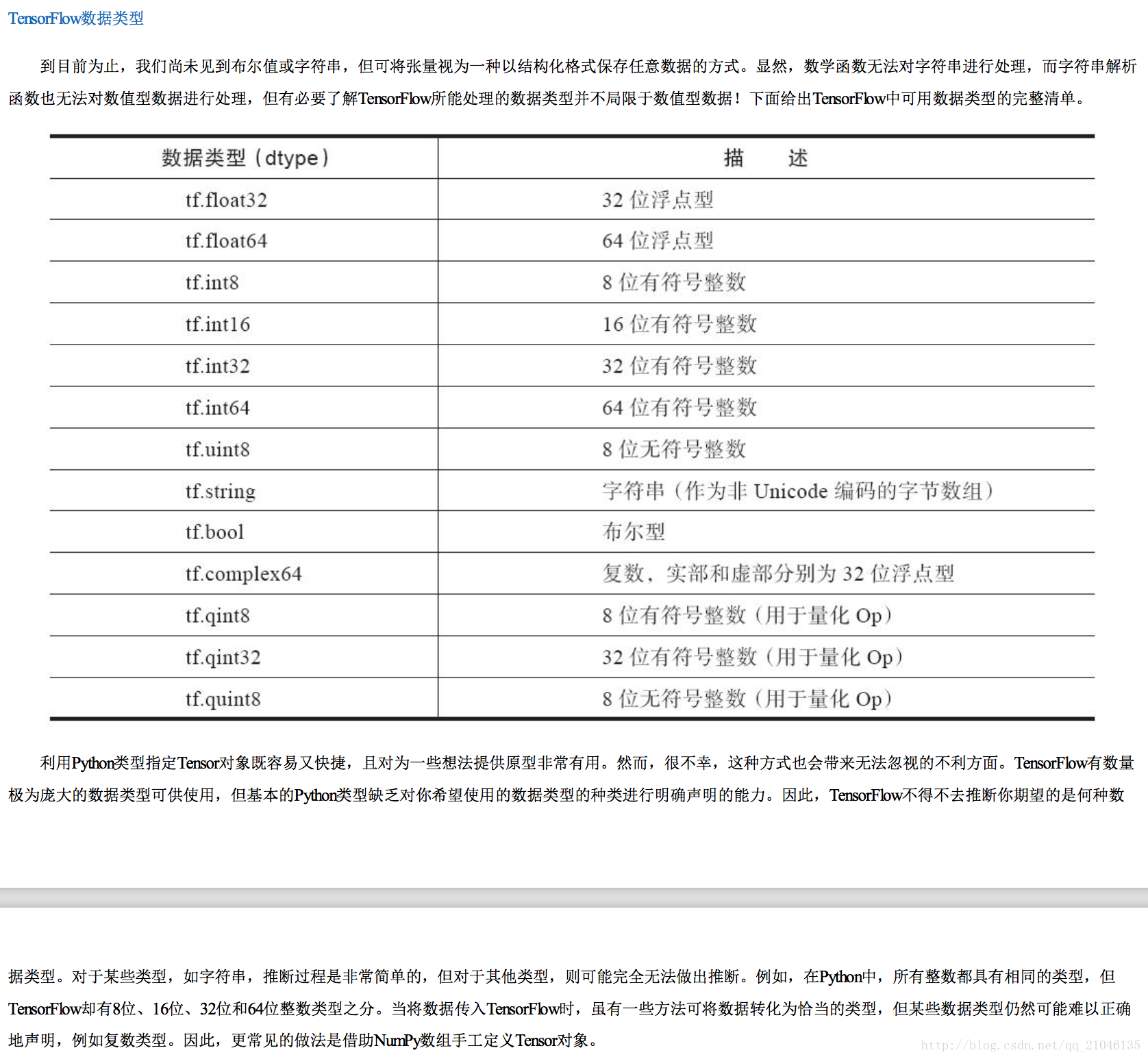
2.2 Numpy 型別
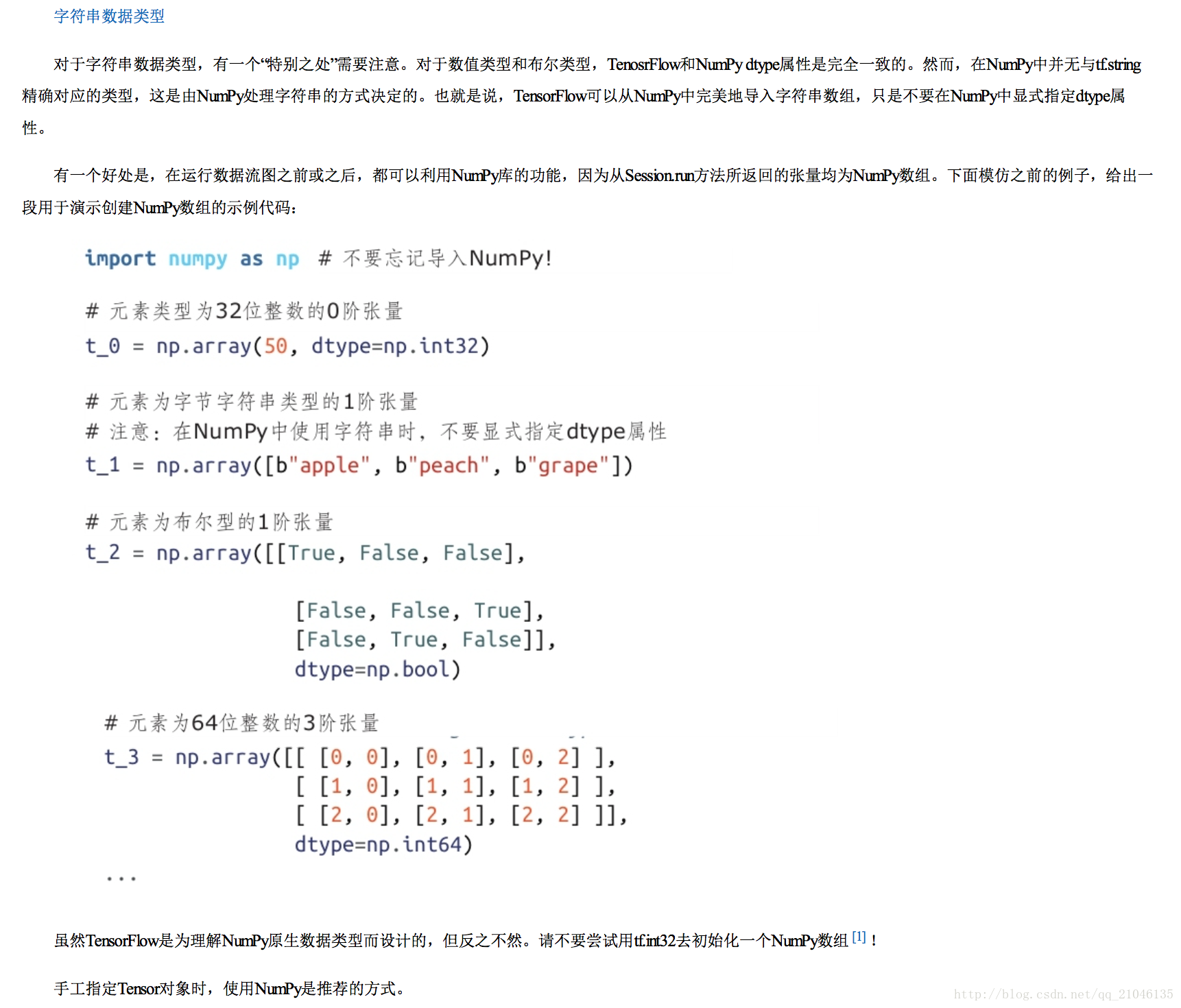
2.3 張量的形狀
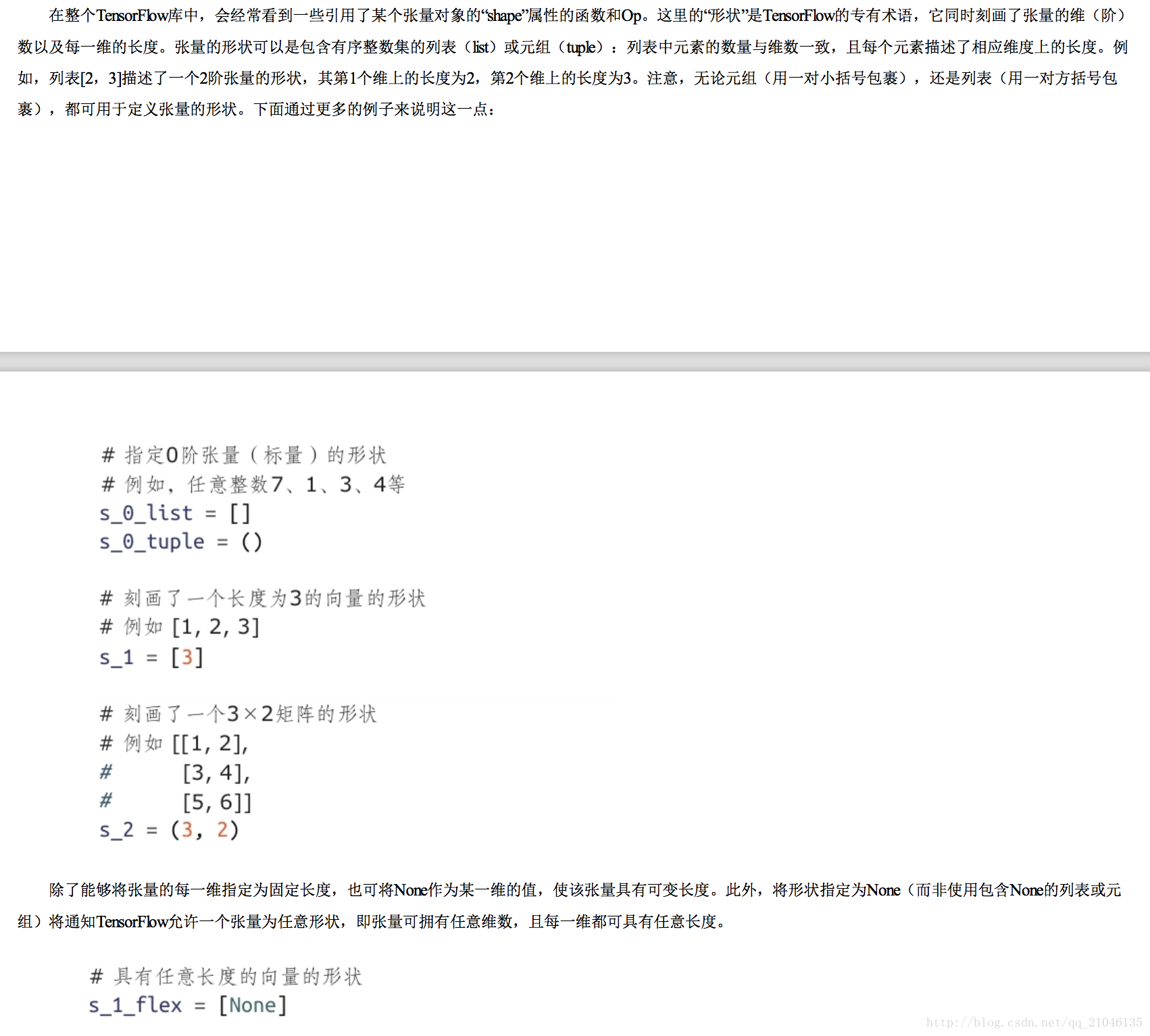
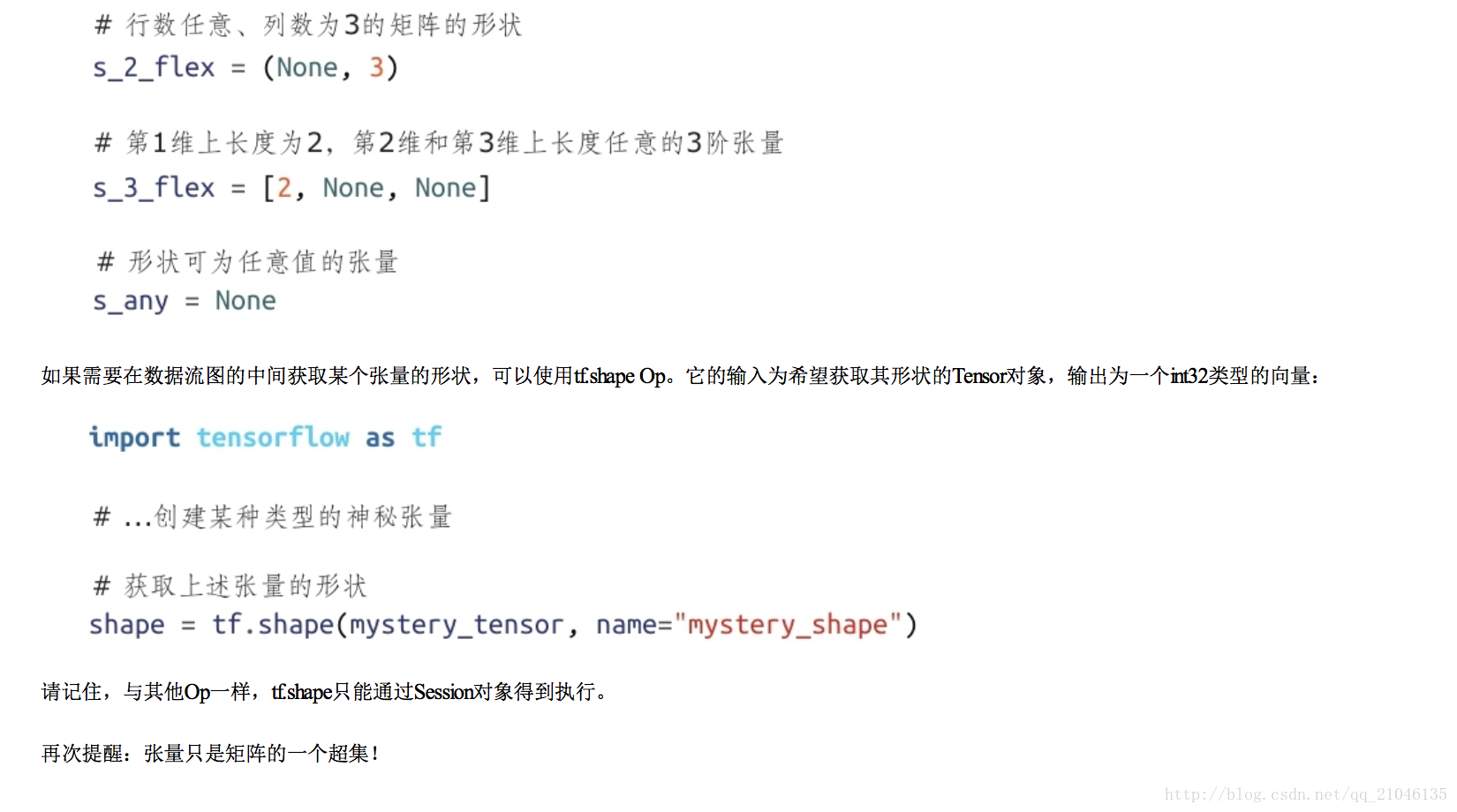
2.4 張量的使用

從上面的程式碼可以看出 TensorFlow 中的張量和 Numpy 中的陣列不同,TensorFlow 計算的結果不是一個具體的數字, 而是一個張量的結構。
一個張量中主要儲存了三個屬性:名字(name),緯度(shape)和型別(type)。
名字(name):張量的第一個屬性名字不僅是一個張量的唯一識別符號,它同樣也給出了這個張量是如何計算出來的
緯度(shape):描述了一個張量的維度資訊
型別(type):每個張量會有一個唯一的型別
三、TnesorFlow 執行模型————會話
會話用來執行定義好的運算
3.1 使用會話的模式一般有兩種,第一種是需要明確呼叫會話生成函式和關閉會話函式
程式碼:
import tensorflow as tf
a = tf.constant([1.0, 2.0], name = 'a')
b = tf.constant([3.0, 4.0], name = 'b')
c = tf.add(a, b, name = 'c')
# 建立一個會話
sess = tf.Session()
sess.run(c)
# 關閉會話使得本次執行中使用到的資源可以被釋放
sess.close()
然而,第一種模式在程式因異常退出時,關閉會話的函式可能不被執行從而導致資源洩漏, 第二種模式是通過上下文管理器來管理
import tensorflow as tf
a = tf.constant([1.0, 2.0], name = 'a')
b = tf.constant([3.0, 4.0], name = 'b')
c = tf.add(a, b, name = 'c')
# 通過 python 中的上下文管理器來管理這個會話
with tf.Session() as sess:
sess.run()
# 當上下文退出時會話關閉和資源釋放也自動完成3.2 互動式會話
在互動式環境下,通過設定預設會話的方式來獲取張量的取值更加方便,使用 tf.InteractiveSession 會自動將生成的會話註冊成為預設會話

四、利用佔位節點新增輸入
4.1 feed_dict 引數
引數 feed_dict 用於覆蓋資料流圖中的 Tensor 物件值,它需要 Python 字典物件作為輸入。字典中的“鍵”為指向應當被覆蓋的 Tensor 物件的控制代碼,而字典的“值”可以是 數字、字串、列表或 NumPy 陣列(之前介紹過)。這些“值”的型別必須與 Tensor 的“鍵”相同,或能夠轉換為相同的型別。下面通過一些程式碼來展示如何利用 feed_dict 重寫之前的資料流圖中a的值:
import tensorflow as tf
a = tf.add(2, 5)
b = tf.multiply(a, 3)
sess = tf.Session()
replace_dict = {a:15}
sess.run(b, feed_dict=replace_dict)
4.2 佔位節點應用
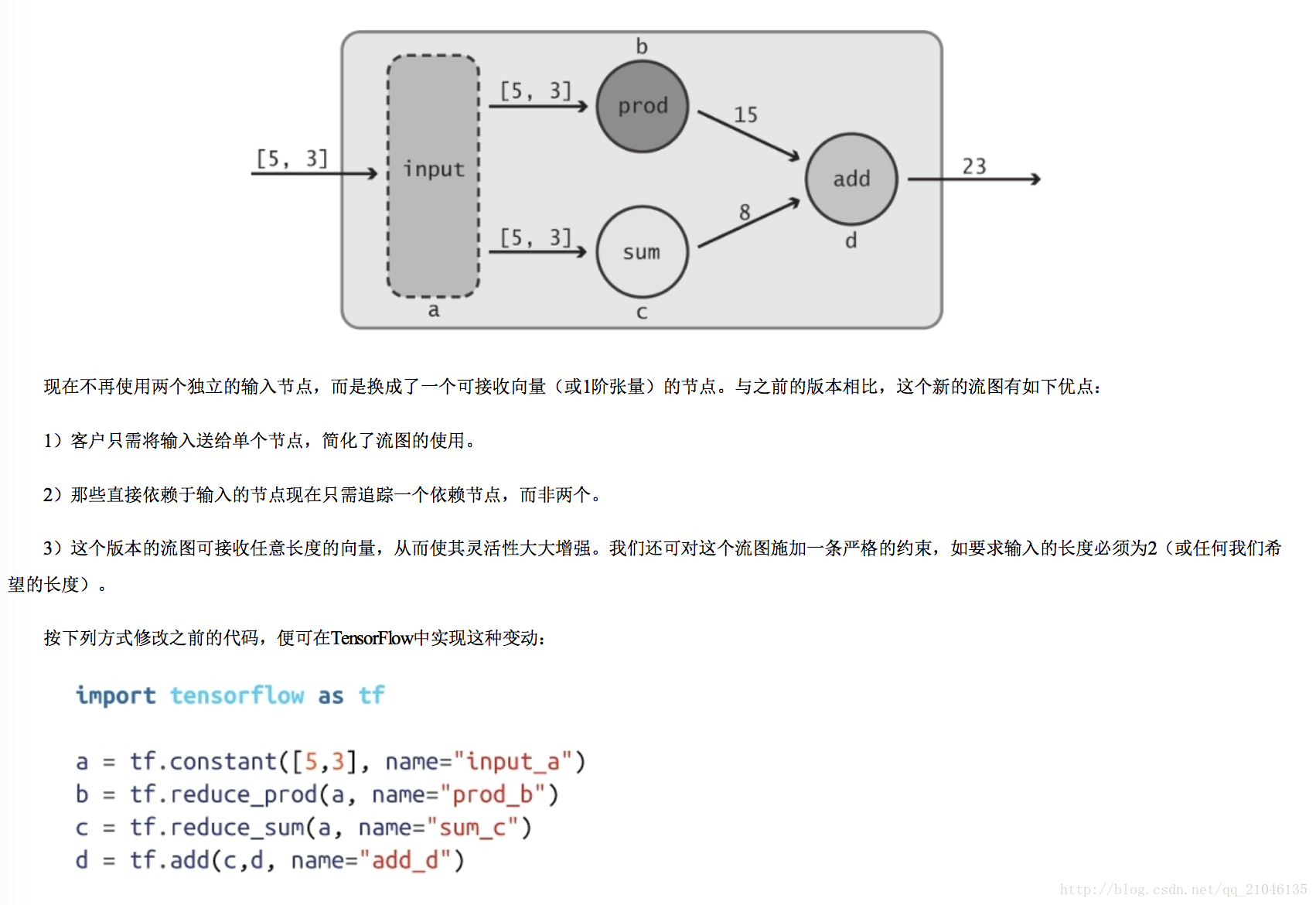
之前定義的資料流圖並未使用真正的“輸入”,它總是使用相同的數值 5 和 3。我們真正希望做的是從客戶那裡接收輸入值,這樣便可對資料流圖中所描述的變換 以各種不同型別的數值進行復用,藉助“佔位符”可達到這個目的。正如其名稱所預示的那樣,佔位符的行為與 Tensor 物件一致,但在建立時無須為它們指定具體的 數值。它們的作用是為執行時即將到來的某個 Tensor 物件預留位置,因此實際上變成了“輸入”節點。利用 tf.placeholder Op 可建立佔位符:
import tensorflow as tf
import numpy as np
a = tf.placeholder(tf.int32, shape=[2], name = 'my_input')
b = tf.reduce_prod(a, name = 'prod_a')
c = tf.reduce_sum(a, name = 'sum_c')
d = tf.add(b, c, name = 'add_d')
sess = tf.Session()
input_dict = {a : np.array([5, 3], dtype = np.int32)}
sess.run(d, feed_dict = input_dict)
輸出:23
五、Variable 物件






六、名稱作用域(name scope)
現實世界中的模型往往會包含幾十或上百個節點,以及數以百萬計的引數。為使這種級別的複雜性可控,TensorFlow當前提供了一種幫助使用者組織資料流圖的機制 ——名稱作用域(name scope)。
程式1:
import tensorflow as tf
with tf.name_scope('scope_a'):
a = tf.add(1,2, name = 'a')
b = tf.multiply(3, 4, name = 'b')
with tf.name_scope('scope_b'):
c = tf.add(4, 5, name = 'c')
d = tf.multiply(6, 7, name = 'd')
writer = tf.summary.FileWriter('./name_scope_1', graph = tf.get_default_graph())
writer.close()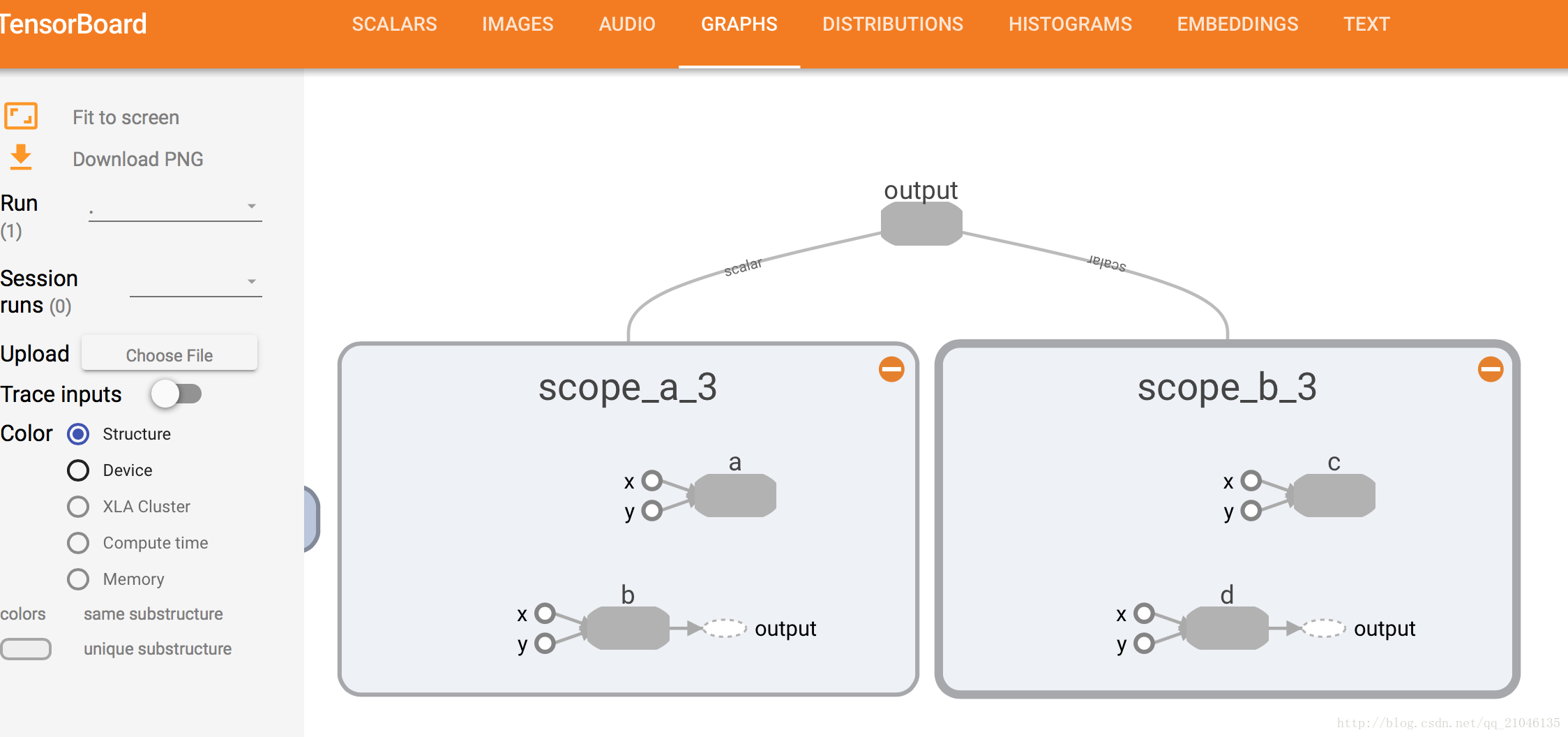
程式2:
import tensorflow as tf
graph = tf.Graph()
with graph.as_default():
in_1 = tf.placeholder(tf.float32, shape = [], name = 'input_a')
in_2 = tf.placeholder(tf.float32, shape = [], name = 'input_b')
const = tf.constant(3, dtype = tf.float32, name = 'static_value')
with tf.name_scope('Transformation'):
with tf.name_scope('A'):
A_mul = tf.multiply(in_1, const)
A_out = tf.subtract(A_mul, in_1)
with tf.name_scope('B'):
B_mul = tf.multiply(in_2, const)
B_out = tf.subtract(B_mul, in_2)
with tf.name_scope('C'):
C_div = tf.div(A_out, B_out)
C_out = tf.add(C_div, const)
with tf.name_scope('D'):
D_div = tf.div(B_out, A_out)
D_out = tf.add(D_div, const)
out = tf.maximum(C_out, D_out)
writer = tf.summary.FileWriter('./name_scope_2', graph = graph)
writer.close()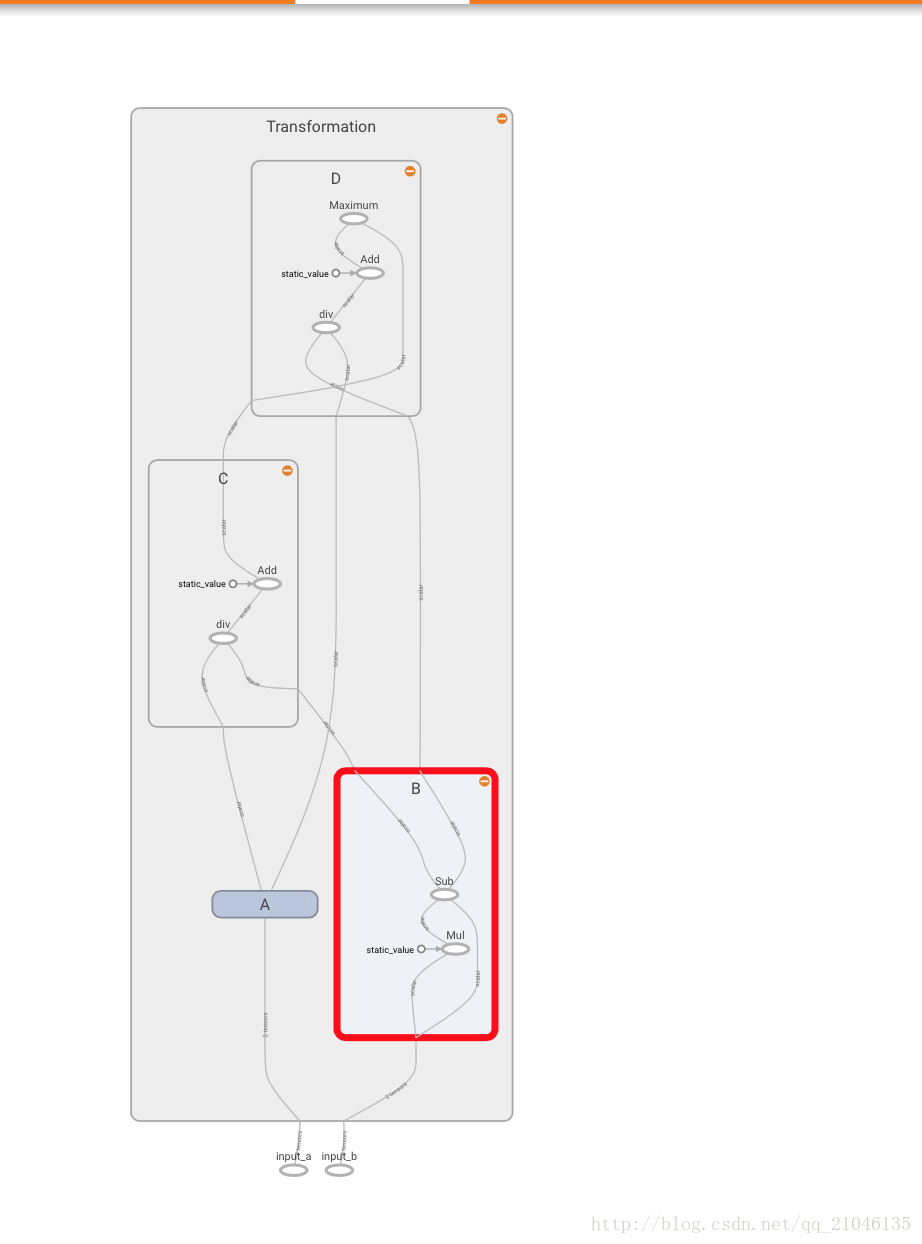
七、綜合運用各種元件
7.1 資料流圖
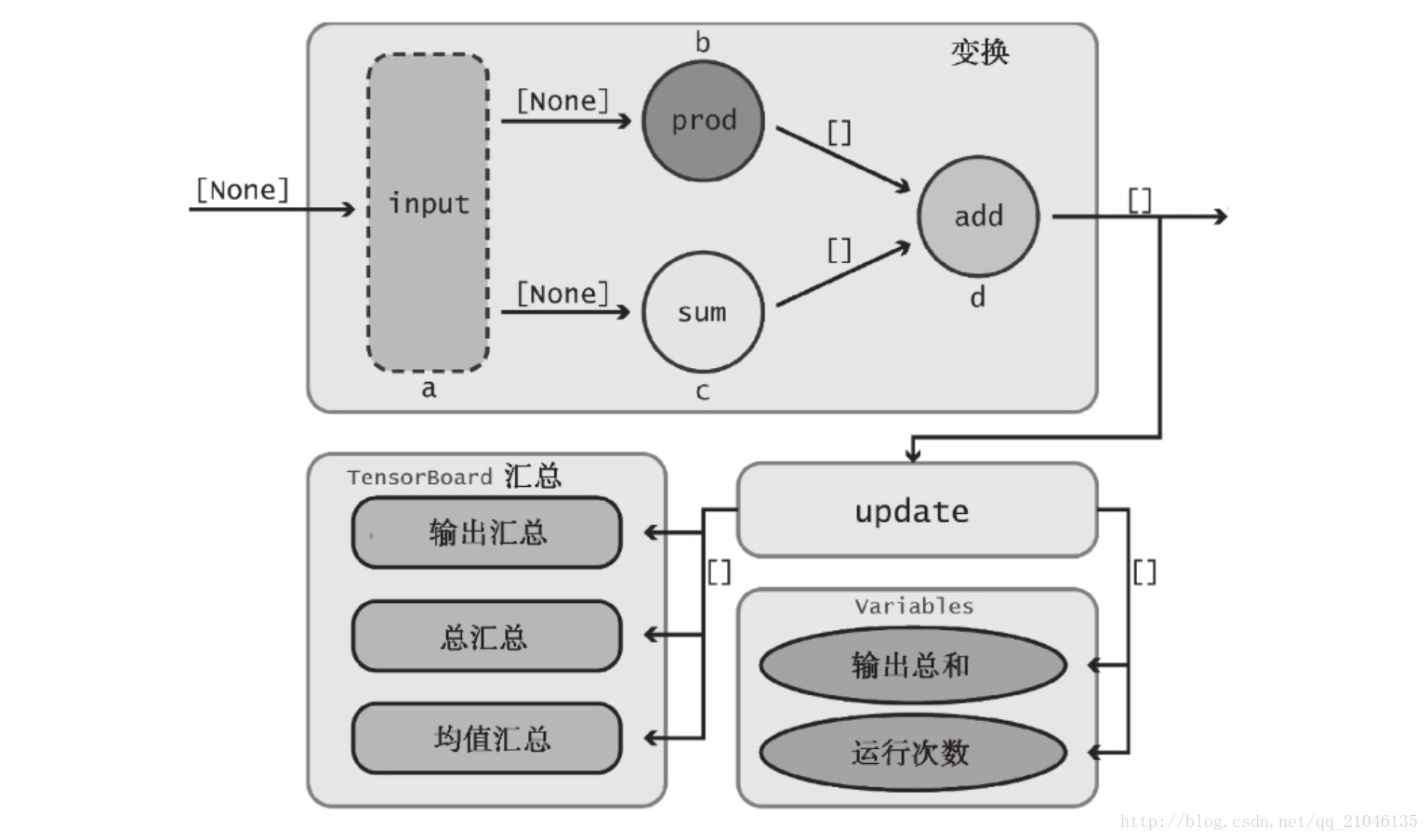
import tensorflow as tf
graph = tf.Graph()
with graph.as_default():
with tf.name_scope("variables"):
# 追蹤資料流圖執行次數
global_step = tf.Variable(0, dtype = tf.int32, trainable = False, name = 'global_step')
# 所有輸出隨時間的累加和
total_output = tf.Variable(0.0, dtype = tf.float32, trainable = False, name = 'total_output')
# 主要變換的 OP
with tf.name_scope("transformation"):
with tf.name_scope("input"):
# 獨立的輸入層
# 建立一個可以接收變數的佔位符
a = tf.placeholder(tf.float32, shape = [None], name = 'input_placeholder_a')
# 獨立的中間層
with tf.name_scope("intermediate_layer"):
b = tf.reduce_prod(a, name = 'b')
c = tf.reduce_sum(a, name = 'c')
# 獨立的輸出層
with tf.name_scope("output"):
output = tf.add(b, c, name = 'output')
# 更新全域性變數
with tf.name_scope("update"):
update_total = total_output.assign_add(output)
increment_step = global_step.assign_add(1)
#
with tf.name_scope("summaries"):
# 計算平均值
avg = tf.div(update_total, tf.cast(increment_step, tf.float32), name = 'average')
tf.summary.scalar('output', output)
tf.summary.scalar('sum_of_outputs_overtime', update_total)
tf.summary.scalar('average_of_outputs_over_time', avg)
with tf.name_scope('global_ops'):
# 初始化 OP
init = tf.global_variables_initializer()
# 將所有彙總資料合併到一個 OP 中
merged_summaries = tf.summary.merge_all()
sess = tf.Session(graph = graph)
writer = tf.summary.FileWriter('./improved_graph', graph)
sess.run(init)
# 1)首先建立一個賦給Session.run()中feed_dict引數的字典,這對應於tf.placeholder節點,並用到了其控制代碼a。
# 2)然後,通知Session物件使用feed_dict執行資料流圖,我們希望確保output、increment_step以及merged_summaries Op能夠得到執行。為寫入彙總資料,需要儲存 global_step和merged_summaries的值,因此將它們儲存到Python變數step和summary中。這裡用下劃線“_”表示我們並不關心output值的儲存。
# 3)最後,將彙總資料新增到SummaryWriter物件中。global_step引數非常重要,因為它使TensorBoard可隨時間對資料進行圖示(稍後將看到,它本質上建立了一 個折線圖的橫軸)。
def run_graph(input_tensor):
feed_dict = {a : input_tensor}
_, step, summary = sess.run([output, increment_step, merged_summaries], feed_dict = feed_dict)
writer.add_summary(summary, global_step = step)
run_graph([2, 8])
run_graph([3, 1, 1, 3])
writer.flush()
在 TensorBoard 顯示為
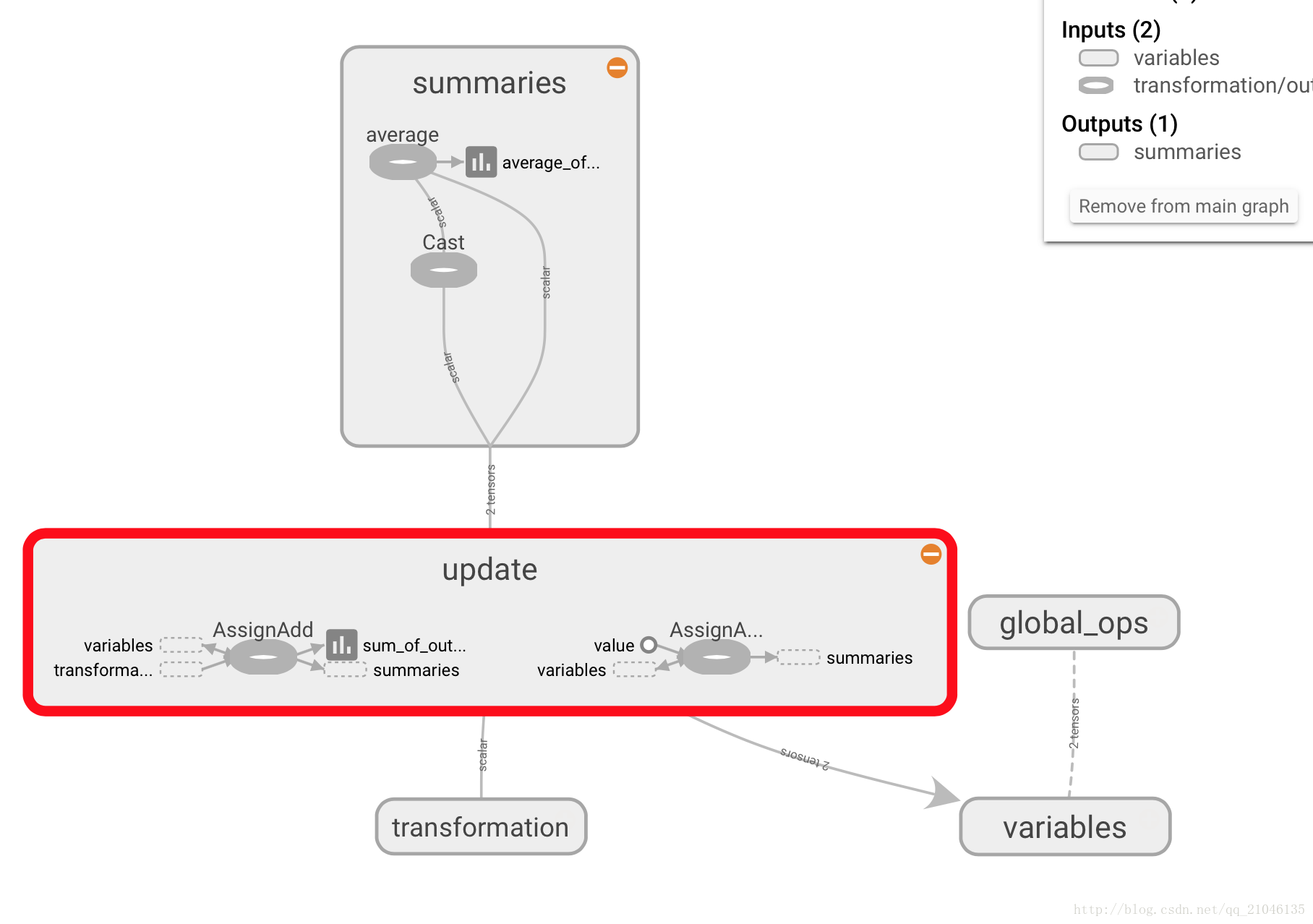
八、TensorFlow 實現神經網路
8.1 神經網路解決分類問題主要步驟
1、提取問題中實體的特徵向量作為神經網路的輸入。不同的實體可以提取不同的特徵向量
2、定義神經網路的結構,並定義如何從神經網路的輸入得到輸出,這個過程就是神經網路的前向傳播演算法
3、通過訓練資料來調整神經網路中引數的取值
4、使用訓練好的神經網路來預測未知的資料
8.2 神經網路前向傳播
示意圖:
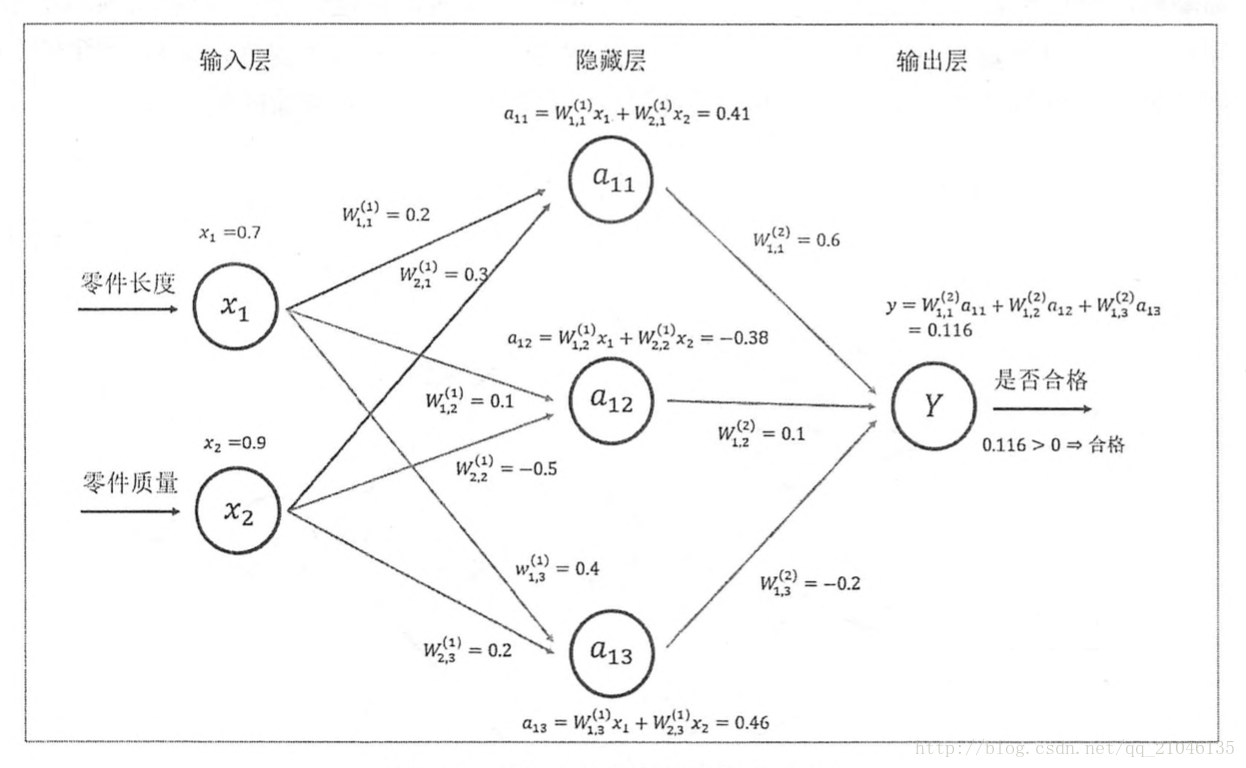

程式碼1:
import tensorflow as tf
w1 = tf.Variable(tf.random_normal([2, 3], stddev = 1, seed = 1))
w2 = tf.Variable(tf.random_normal([3, 1], stddev = 1, seed = 1))
x = tf.constant([[0.7, 0.9]])
a = tf.matmul(x, w1)
y = tf.matmul(a, w2)
sess = tf.Session()
sess.run(w1.initializer)
sess.run(w2.initializer)
print(sess.run(y))
sess.close()程式碼2:使用佔位函式,就不需要生成大量常量來提供輸入資料
import tensorflow as tf
w1 = tf.Variable(tf.random_normal([2, 3], stddev = 1, seed = 1))
w2 = tf.Variable(tf.random_normal([3, 1], stddev = 1, seed = 1))
x = tf.placeholder(tf.float32, shape = (3, 2), name = 'input')
a = tf.matmul(x, w1)
y = tf.matmul(a, w2)
sess = tf.Session()
init = tf.initialize_all_variables()
sess.run(init)
print(sess.run(y, feed_dict = {x : [[0.7, 0.9], [0.1, 0.4], [0.5, 0.8]]}))
sess.close()8.3 反向傳播演算法
在神經網路優化演算法中,最常用的就是反向傳播演算法
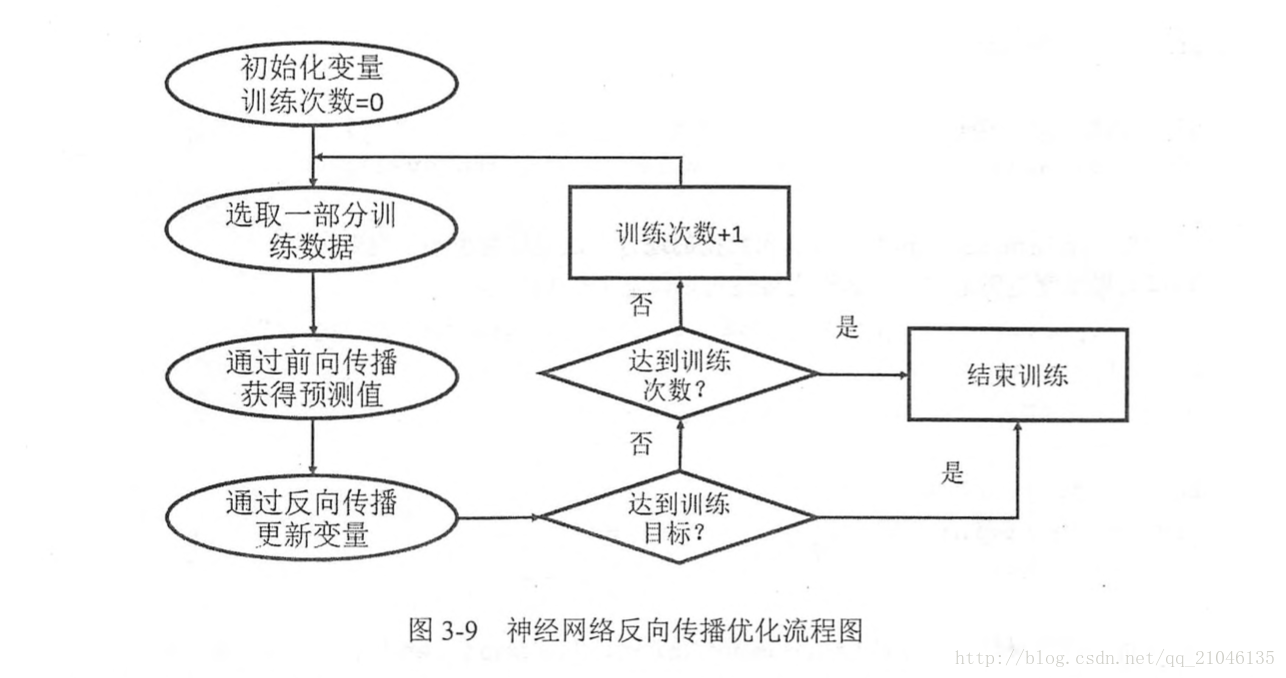
8.4 神經網路完整程式
import tensorflow as tf
from numpy.random import RandomState
# 定義訓練資料 batch 的大小
batch_size = 8
w1 = tf.Variable(tf.random_normal([2, 3], stddev = 1, seed = 1))
w2 = tf.Variable(tf.random_normal([3, 1], stddev = 1, seed = 1))
x = tf.placeholder(tf.float32 ,shape = (None, 2), name = 'x-input')
y_ = tf.placeholder(tf.float32, shape = (None, 1) ,name = 'y-input')
# 定義神經網路前向傳播過程
a = tf.matmul(x, w1)
y = tf.matmul(a, w2)
# 定義損失函式和反向傳播演算法
cross_entropy = -tf.reduce_mean(y_ * tf.log(tf.clip_by_value(y, 1e-10, 1.0)))
train_step = tf.train.AdamOptimizer(0.001).minimize(cross_entropy)
# 通過隨機數生成一個模擬資料集
rdm = RandomState(1)
dataset_size = 128
X = rdm.rand(dataset_size, 2)
Y = np.array([[int(x1 + x2 < 1) for (x1, x2) in X]]).reshape(128, 1)
with tf.Session() as sess:
init = tf.initialize_all_variables()
sess.run(init)
print(sess.run(w1))
print(sess.run(w2))
# 設定訓練輪數
STEPS = 5000
for i in range(STEPS):
# 每次選取 batch_size 個樣本進行訓練
start = (i * batch_size) % dataset_size
end = min(start + batch_size, dataset_size)
# 通過選取的樣本訓練神經網路並更新引數
sess.run(train_step, feed_dict = {x : X[start : end], y_ : Y[start : end]})
if i % 1000 == 0:
# 每隔一段時間計算在所有資料上的交叉熵並輸出
total_cross_entropy = sess.run(cross_entropy, feed_dict = {x : X, y_ : Y})
print("After %d training steps, cross entropy on all data is %g" % (i, total_cross_entropy))
print(sess.run(w1))
print(sess.run(w2))輸出:
[[-0.81131822 1.48459876 0.06532937]
[-2.44270396 0.0992484 0.59122431]]
[[-0.81131822]
[ 1.48459876]
[ 0.06532937]]
After 0 training steps, cross entropy on all data is 0.0674925
After 1000 training steps, cross entropy on all data is 0.0163385
After 2000 training steps, cross entropy on all data is 0.00907547
After 3000 training steps, cross entropy on all data is 0.00714436
After 4000 training steps, cross entropy on all data is 0.00578471
[[-1.9618274 2.58235407 1.68203783]
[-3.4681716 1.06982327 2.11788988]]
[[-1.8247149 ]
[ 2.68546653]
[ 1.41819501]]相關推薦
TensorFlow (一) 從入門到實踐
一、TnesorFlow 計算模型————計算圖 1、 計算圖概念 1.1 Tensor Tensor就是張量, 可以簡單理解為多維陣列,表明了資料結構 1.2 Flow Flow 表達了張量之間通過計算相互轉化的過程,體現了資料模型 1.3
tensorflow學習 從入門到實戰(轉)
原文作者:zhaozhengcoder連結:https://www.jianshu.com/p/27a2fb320934來源:簡書簡書著作權歸作者所有,任何形式的轉載都請聯絡作者獲得授權並註明出處。 前一段時間比較系統的學習了一下tensorflow,從安裝tensorflow到實
Jmeter(十一) - 從入門到精通 - JMeter邏輯控制器 - 下篇(詳解教程)
1.簡介 Jmeter官網對邏輯控制器的解釋是:“Logic Controllers determine the order in which Samplers are processed.”。 意思是說,邏輯控制器可以控制取樣器(samplers)的執行順序。由此可知,控制器需要和取
Jmeter(二十一) - 從入門到精通 - JMeter斷言 - 上篇(詳解教程)
1.簡介 最近由於巨集哥在搭建自己的個人部落格可能更新的有點慢。斷言元件用來對伺服器的響應資料做驗證,常用的斷言是響應斷言,其支援正則表示式。雖然我們的通過響應斷言能夠完成絕大多數的結果驗證工作,但是JMeter還是為我們提供了適合多個場景的斷言元件,輔助我們來更好的完成結果驗證工作。在使用JMeter進
Python編程:從入門到實踐——【作業】——第十一章(測試代碼)
stc 增加 收集 得到 width .com ast 接受 ted 第十一章 11-1 城市和國家 : 編寫一個函數, 它接受兩個形參: 一個城市名和一個國家名。 這個函數返回一個格式為City, Country 的字符串, 如Santiago, Chile 。 將這個函
python程式設計:從入門到實踐學習筆記-Django開發使用者賬戶(一)
讓使用者能夠輸入資料(表單) 在建立使用者賬戶身份驗證系統之前,先新增幾個頁面,讓使用者能偶輸入資料。新增新主題、新增新條目以及編輯既有條目。 新增新主題 1.用於新增主題的表單 建立一個forms.py檔案與models.py放在同一目錄下。 from django import
python程式設計:從入門到實踐學習筆記Django入門(一)
建立應用程式 django專案由一系列應用程式組成,他們協同工作,讓專案稱謂一個整體。首先我們執行命令python manage.py startapp learning_logs。 定義模型 開啟剛剛我們建立的資料夾,並修改mod
Python程式設計從入門到實踐課後答案:第十一章
11-1 城市和國家 :編寫一個函式,它接受兩個形參:一個城市名和一個國家名。這個函式返回一個格式為City, Country 的字串,如Santiago, Chile 。將 這個函式儲存在一個名為city_functions.py的模組中。 建立一個名為test_cities.py的程式,
《Python程式設計從入門到實踐》第10章檔案和異常動手試一試答案(附程式碼)
目錄 10-3 訪客 10-4 訪客名單 10-6 加法運算 10-7 加法計算器 10-8 貓和狗 10-9 沉默的貓和狗 10-3 訪客 #!/usr/bin/env python # -*- coding:utf-8 -*- user = input
《Python 程式設計:從入門到實踐》第十一章(測試程式碼)練習題答案
# -*- coding: gbk -*- def country_city(country,city,population=''): return(country.title()+","+city.title()+population) #11-2 imp
Python程式設計從入門到實踐筆記——測試程式碼(一篇足夠)
11 測試程式碼 編寫函式或類時,還可為其編寫測試。通過測試,可確定程式碼面對各種輸入都能夠按要求的那樣工作。在程式中新增新程式碼時,你也可以對其進行測試,確認它們不會破壞程式既有的行為。 在本章中,你將學習如何使用Pyt
《Python程式設計 從入門到實踐》13-1練習題(建立一組星星)錯誤摘記
正確程式碼 import pygame, sys from pygame.sprite import Group from settings import Settings from star import Star def run_game():
關於一本書的《python程式設計+從入門到實踐》
2018年11月03日 16:13:56 qq_43594537 閱讀數:5 個人分類: 程式設計
Python程式設計:從入門到實踐的動手試一試答案(第三章)
#3-1 姓名 names = ['Qiqi','Danliang','Mingliang','Peng'] for x in range(0,4): print(names[x]) #3
Python從入門到實踐習題、一
個性化訊息: 將使用者的姓名存到一個變數中,並向該使用者顯示一條訊息。顯示的訊息應非常簡單,如“Hello Eric, would you liketo learn some Python today?”。 調整名字的大小寫: 將一個人名儲存到一個變數中,再以小寫、大寫和首字母大寫的方式顯示這個
TensorFlow 從入門到精通(一):安裝和使用
安裝過程 目前較為穩定的版本為 0.12,本文以此為例。其他版本請讀者自行甄別安裝步驟是否需要根據實際情況修改。 TensorFlow 支援以下幾種安裝方式: PIP 安裝 原始碼編譯安裝 Docker 映象安裝 PIP 安裝
Python程式設計:從入門到實踐的動手試一試答案(第十章)
#10-1 Python學習筆記 with open('learning_python.txt') as file_object: contents = file_object.read() print(contents) ----------------
Python程式設計:從入門到實踐的動手試一試答案(第四章)
#4-1 比薩 pizzas = ['apple pizza','banana pizza','chili pizza'] for pizza in pizzas: print('I like
Python程式設計:從入門到實踐的動手試一試答案(第五章)
#5-1 條件測試 car = 'subaru' print("Is car == 'subaru'? I predict True.") if car == 'subaru': print(c
《Python從入門到實踐》第八章動手試一試
參數 int 第八章 print e-book play ret 調用 code 8-1 消息 :編寫一個名為display_message() 的函數,它打印一個句子,指出你在本章學的是什麽。調用這個函數,確認顯示的消息正確無誤。 def display_message(