
系統學習機器學習之特徵工程(一)--維度歸約
這裡,我們討論特徵選擇和特徵提取,前者選取重要的特徵子集,後者由原始輸入形成較少的新特徵,理想情況下,無論是分類還是迴歸,我們不應該將特徵選擇或特徵提取作為一個單獨的程序,分類或者回歸方法應該能夠利用任何必要的特徵,而丟棄不相關的特徵。但是,考慮到演算法儲存量和時間的複雜度,或者輸入不必要的特徵等原因,還是需要降維。較簡單的模型在小資料上更為魯棒,有小方差,模型的變化更依賴於樣本的特殊性,包括噪聲,離群點等。同時,低緯度描述資料,方便我們隊資料繪圖,視覺化分析資料結構和離群點。
降低方法,一般為特徵選擇,特徵提取,按監督和非監督分:
非監督:PCA、FA ,LLE
監督:LDA,MDS
其中,PCA,FA,MDS,LDA,都是線性投影方法,非線性維度規約有等距特徵對映,區域性線性嵌入LLE。
維度歸約使用資料編碼或變換,以便得到原資料的歸約或“壓縮”表示。如果原資料可以由壓縮資料重新構造而不丟失任何資訊,則該資料歸約是無損的。如果我們只能重新構造原資料的近似表示,則該資料歸約是有損的。有一些很好的串壓縮演算法。儘管它們通常是無損的,但是隻允許有限的資料操作。
一.先說特徵選擇,即子集選擇。
在子集選擇中,我們選擇最佳子集,其含的維度最少,但對正確率的貢獻最大。在維度較大時,採用啟發式方法,在合理的時間內得到一個合理解(但不是最優解)。維度較小時,對所有子集做檢驗。
有兩種方法,向前選擇,即從空集開始逐漸增加特徵,每次新增一個降低誤差最多的變數,直到進一步新增不會降低誤差或者降低很少。同時,可以用浮動搜尋,每一步可以改變增加和去掉的特徵數量,以此來加速。
向後選擇中,從所有變數開始,逐個排除他們,每次排除一個降低誤差最多的變數,直到進一步的排除會顯著提高誤差。如果我們預料有許多無用特徵時,向前選擇更可取。
在兩種情況下,誤差檢測都應在不同於訓練集的驗證集上做,因為我們想要檢驗泛化準確率。使用更多的特徵,我們一般會有更低的訓練誤差,但不一定有更低的驗證誤差。
像人臉識別這樣的應用中,特徵選擇不是很好的降維方法,因為個體畫素本身並不攜帶很多識別資訊,攜帶臉部識別資訊的是許多畫素值的組合。這可以用特徵提取來歸約。
二. 主成分分析(PCA)
1. 問題
真實的訓練資料總是存在各種各樣的問題:
1、 比如拿到一個汽車的樣本,裡面既有以“千米/每小時”度量的最大速度特徵,也有“英里/小時”的最大速度特徵,顯然這兩個特徵有一個多餘。
2、 拿到一個數學系的本科生期末考試成績單,裡面有三列,一列是對數學的興趣程度,一列是複習時間,還有一列是考試成績。我們知道要學好數學,需要有濃厚的興趣,所以第二項與第一項強相關,第三項和第二項也是強相關。那是不是可以合併第一項和第二項呢?
3、 拿到一個樣本,特徵非常多,而樣例特別少,這樣用迴歸去直接擬合非常困難,容易過度擬合。比如北京的房價:假設房子的特徵是(大小、位置、朝向、是否學區房、建造年代、是否二手、層數、所在層數),搞了這麼多特徵,結果只有不到十個房子的樣例。要擬合房子特徵->房價的這麼多特徵,就會造成過度擬合。
4、 這個與第二個有點類似,假設在IR中我們建立的文件-詞項矩陣中,有兩個詞項為“learn”和“study”,在傳統的向量空間模型中,認為兩者獨立。然而從語義的角度來講,兩者是相似的,而且兩者出現頻率也類似,是不是可以合成為一個特徵呢?
5、 在訊號傳輸過程中,由於通道不是理想的,通道另一端收到的訊號會有噪音擾動,那麼怎麼濾去這些噪音呢?
回顧我們之前介紹的《模型選擇和規則化》,裡面談到的特徵選擇的問題。但在那篇中要剔除的特徵主要是和類標籤無關的特徵。比如“學生的名字”就和他的“成績”無關,使用的是互資訊的方法。
而這裡的特徵很多是和類標籤有關的,但裡面存在噪聲或者冗餘。在這種情況下,需要一種特徵降維的方法來減少特徵數,減少噪音和冗餘,減少過度擬合的可能性。
下面探討一種稱作主成分分析(PCA)的方法來解決部分上述問題。PCA的思想是將n維特徵對映到k維上(k<n),這k維是全新的正交特徵。這k維特徵稱為主元,是重新構造出來的k維特徵,而不是簡單地從n維特徵中去除其餘n-k維特徵。
2. PCA計算過程
首先介紹PCA的計算過程:
假設我們得到的2維資料如下:
![clip_image001[4]](http://images.cnblogs.com/cnblogs_com/jerrylead/201104/201104182110393017.png)
行代表了樣例,列代表特徵,這裡有10個樣例,每個樣例兩個特徵。可以這樣認為,有10篇文件,x是10篇文件中“learn”出現的TF-IDF,y是10篇文件中“study”出現的TF-IDF。也可以認為有10輛汽車,x是千米/小時的速度,y是英里/小時的速度,等等。
第一步分別求x和y的平均值,然後對於所有的樣例,都減去對應的均值。這裡x的均值是1.81,y的均值是1.91,那麼一個樣例減去均值後即為(0.69,0.49),得到
![clip_image002[4]](http://images.cnblogs.com/cnblogs_com/jerrylead/201104/201104182110402112.png)
第二步,求特徵協方差矩陣,如果資料是3維,那麼協方差矩陣是
![clip_image003[4]](http://images.cnblogs.com/cnblogs_com/jerrylead/201104/201104182110404031.png)
這裡只有x和y,求解得
![clip_image004[4]](http://images.cnblogs.com/cnblogs_com/jerrylead/201104/201104182110417586.png)
對角線上分別是x和y的方差,非對角線上是協方差。協方差大於0表示x和y若有一個增,另一個也增;小於0表示一個增,一個減;協方差為0時,兩者獨立。協方差絕對值越大,兩者對彼此的影響越大,反之越小。
第三步,求協方差的特徵值和特徵向量,得到
![clip_image005[4]](http://images.cnblogs.com/cnblogs_com/jerrylead/201104/201104182110413965.png)
上面是兩個特徵值,下面是對應的特徵向量,特徵值0.0490833989對應特徵向量為![]() ,這裡的特徵向量都歸一化為單位向量。
,這裡的特徵向量都歸一化為單位向量。
第四步,將特徵值按照從大到小的順序排序,選擇其中最大的k個,然後將其對應的k個特徵向量分別作為列向量組成特徵向量矩陣。
這裡特徵值只有兩個,我們選擇其中最大的那個,這裡是1.28402771,對應的特徵向量是![]() 。
。
第五步,將樣本點投影到選取的特徵向量上。假設樣例數為m,特徵數為n,減去均值後的樣本矩陣為DataAdjust(m*n),協方差矩陣是n*n,選取的k個特徵向量組成的矩陣為EigenVectors(n*k)。那麼投影后的資料FinalData為
![]()
這裡是
FinalData(10*1) = DataAdjust(10*2矩陣)×特徵向量![]()
得到結果是
![clip_image012[4]](http://images.cnblogs.com/cnblogs_com/jerrylead/201104/201104182110427737.png)
這樣,就將原始樣例的n維特徵變成了k維,這k維就是原始特徵在k維上的投影。
上面的資料可以認為是learn和study特徵融合為一個新的特徵叫做LS特徵,該特徵基本上代表了這兩個特徵。
上述過程有個圖描述:
![clip_image013[4]](http://images.cnblogs.com/cnblogs_com/jerrylead/201104/201104182110437355.png)
正號表示預處理後的樣本點,斜著的兩條線就分別是正交的特徵向量(由於協方差矩陣是對稱的,因此其特徵向量正交),最後一步的矩陣乘法就是將原始樣本點分別往特徵向量對應的軸上做投影。
如果取的k=2,那麼結果是
![clip_image014[4]](http://images.cnblogs.com/cnblogs_com/jerrylead/201104/201104182110442489.png)
這就是經過PCA處理後的樣本資料,水平軸(上面舉例為LS特徵)基本上可以代表全部樣本點。整個過程看起來就像將座標系做了旋轉,當然二維可以圖形化表示,高維就不行了。上面的如果k=1,那麼只會留下這裡的水平軸,軸上是所有點在該軸的投影。
這樣PCA的過程基本結束。在第一步減均值之後,其實應該還有一步對特徵做方差歸一化。比如一個特徵是汽車速度(0到100),一個是汽車的座位數(2到6),顯然第二個的方差比第一個小。因此,如果樣本特徵中存在這種情況,那麼在第一步之後,求每個特徵的標準差![]() ,然後對每個樣例在該特徵下的資料除以
,然後對每個樣例在該特徵下的資料除以![]() 。
。
歸納一下,使用我們之前熟悉的表示方法,在求協方差之前的步驟是:
![clip_image017[4]](http://images.cnblogs.com/cnblogs_com/jerrylead/201104/201104182110465879.png)
其中![]() 是樣例,共m個,每個樣例n個特徵,也就是說
是樣例,共m個,每個樣例n個特徵,也就是說![]() 是n維向量。
是n維向量。![]() 是第i個樣例的第j個特徵。
是第i個樣例的第j個特徵。![]() 是樣例均值。
是樣例均值。![]() 是第j個特徵的標準差。
是第j個特徵的標準差。
整個PCA過程貌似及其簡單,就是求協方差的特徵值和特徵向量,然後做資料轉換。但是有沒有覺得很神奇,為什麼求協方差的特徵向量就是最理想的k維向量?其背後隱藏的意義是什麼?整個PCA的意義是什麼?
3. PCA理論基礎
要解釋為什麼協方差矩陣的特徵向量就是k維理想特徵,我看到的有三個理論:分別是最大方差理論、最小錯誤理論和座標軸相關度理論。這裡簡單探討前兩種,最後一種在討論PCA意義時簡單概述。
3.1 最大方差理論
在訊號處理中認為訊號具有較大的方差,噪聲有較小的方差,信噪比就是訊號與噪聲的方差比,越大越好。如前面的圖,樣本在橫軸上的投影方差較大,在縱軸上的投影方差較小,那麼認為縱軸上的投影是由噪聲引起的。
因此我們認為,最好的k維特徵是將n維樣本點轉換為k維後,每一維上的樣本方差都很大。
比如下圖有5個樣本點:(已經做過預處理,均值為0,特徵方差歸一)
![clip_image026[4]](http://images.cnblogs.com/cnblogs_com/jerrylead/201104/201104182110512941.png)
下面將樣本投影到某一維上,這裡用一條過原點的直線表示(前處理的過程實質是將原點移到樣本點的中心點)。
![clip_image028[4]](http://images.cnblogs.com/cnblogs_com/jerrylead/201104/201104182110514304.jpg)
假設我們選擇兩條不同的直線做投影,那麼左右兩條中哪個好呢?根據我們之前的方差最大化理論,左邊的好,因為投影后的樣本點之間方差最大。
這裡先解釋一下投影的概念:

紅色點表示樣例![]() ,藍色點表示
,藍色點表示![]() 在u上的投影,u是直線的斜率也是直線的方向向量,而且是單位向量。藍色點是
在u上的投影,u是直線的斜率也是直線的方向向量,而且是單位向量。藍色點是![]() 在u上的投影點,離原點的距離是
在u上的投影點,離原點的距離是![]() (即
(即![]() 或者
或者![]() )由於這些樣本點(樣例)的每一維特徵均值都為0,因此投影到u上的樣本點(只有一個到原點的距離值)的均值仍然是0。
)由於這些樣本點(樣例)的每一維特徵均值都為0,因此投影到u上的樣本點(只有一個到原點的距離值)的均值仍然是0。
回到上面左右圖中的左圖,我們要求的是最佳的u,使得投影后的樣本點方差最大。
由於投影后均值為0,因此方差為:
![clip_image042[4]](http://images.cnblogs.com/cnblogs_com/jerrylead/201104/201104182110572804.png)
中間那部分很熟悉啊,不就是樣本特徵的協方差矩陣麼(![]() 的均值為0,一般協方差矩陣都除以m-1,這裡用m)。
的均值為0,一般協方差矩陣都除以m-1,這裡用m)。
用![]() 來表示
來表示![]() ,
,![]() 表示
表示![]() ,那麼上式寫作
,那麼上式寫作
![]()
由於u是單位向量,即![]() ,上式兩邊都左乘u得,
,上式兩邊都左乘u得,![]()
即![]()
We got it!![]() 就是
就是![]() 的特徵值,u是特徵向量。最佳的投影直線是特徵值
的特徵值,u是特徵向量。最佳的投影直線是特徵值![]() 最大時對應的特徵向量,其次是
最大時對應的特徵向量,其次是![]() 第二大對應的特徵向量,依次類推。
第二大對應的特徵向量,依次類推。
因此,我們只需要對協方差矩陣進行特徵值分解,得到的前k大特徵值對應的特徵向量就是最佳的k維新特徵,而且這k維新特徵是正交的。得到前k個u以後,樣例![]() 通過以下變換可以得到新的樣本。
通過以下變換可以得到新的樣本。
![clip_image059[4]](http://images.cnblogs.com/cnblogs_com/jerrylead/201104/201104182111054945.png)
其中的第j維就是![]() 在
在![]() 上的投影。
上的投影。
通過選取最大的k個u,使得方差較小的特徵(如噪聲)被丟棄。
這是其中一種對PCA的解釋
3.2 最小平方誤差理論

假設有這樣的二維樣本點(紅色點),回顧我們前面探討的是求一條直線,使得樣本點投影到直線上的點的方差最大。本質是求直線,那麼度量直線求的好不好,不僅僅只有方差最大化的方法。再回想我們最開始學習的線性迴歸等,目的也是求一個線性函式使得直線能夠最佳擬合樣本點,那麼我們能不能認為最佳的直線就是迴歸後的直線呢?迴歸時我們的最小二乘法度量的是樣本點到直線的座標軸距離。比如這個問題中,特徵是x,類標籤是y。迴歸時最小二乘法度量的是距離d。如果使用迴歸方法來度量最佳直線,那麼就是直接在原始樣本上做迴歸了,跟特徵選擇就沒什麼關係了。
因此,我們打算選用另外一種評價直線好壞的方法,使用點到直線的距離d’來度量。
現在有n個樣本點![]() ,每個樣本點為m維(這節內容中使用的符號與上面的不太一致,需要重新理解符號的意義)。將樣本點
,每個樣本點為m維(這節內容中使用的符號與上面的不太一致,需要重新理解符號的意義)。將樣本點![]() 在直線上的投影記為
在直線上的投影記為![]() ,那麼我們就是要最小化
,那麼我們就是要最小化
![]()
這個公式稱作最小平方誤差(Least Squared Error)。
而確定一條直線,一般只需要確定一個點,並且確定方向即可。
第一步確定點:
假設要在空間中找一點![]() 來代表這n個樣本點,“代表”這個詞不是量化的,因此要量化的話,我們就是要找一個m維的點
來代表這n個樣本點,“代表”這個詞不是量化的,因此要量化的話,我們就是要找一個m維的點![]() ,使得
,使得
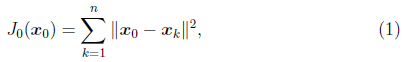
最小。其中![]() 是平方錯誤評價函式(squared-error criterion function),假設m為n個樣本點的均值:
是平方錯誤評價函式(squared-error criterion function),假設m為n個樣本點的均值:

那麼平方錯誤可以寫作:

後項與![]() 無關,看做常量,而
無關,看做常量,而![]() ,因此最小化
,因此最小化![]() 時,
時,
![]()
![]() 是樣本點均值。
是樣本點均值。
第二步確定方向:
我們從![]() 拉出要求的直線(這條直線要過點m),假設直線的方向是單位向量e。那麼直線上任意一點,比如
拉出要求的直線(這條直線要過點m),假設直線的方向是單位向量e。那麼直線上任意一點,比如![]() 就可以用點m和e來表示
就可以用點m和e來表示
![]()
其中![]() 是
是![]() 到點m的距離。
到點m的距離。
我們重新定義最小平方誤差:
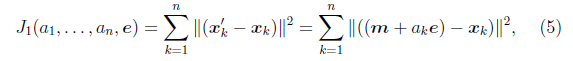
這裡的k只是相當於i。![]() 就是最小平方誤差函式,其中的未知引數是
就是最小平方誤差函式,其中的未知引數是![]() 和e。
和e。
實際上是求![]() 的最小值。首先將上式展開:
的最小值。首先將上式展開:

我們首先固定e,將其看做是常量,![]() ,然後對
,然後對![]() 進行求導,得
進行求導,得
![]()
這個結果意思是說,如果知道了e,那麼將![]() 與e做內積,就可以知道了
與e做內積,就可以知道了![]() 在e上的投影離m的長度距離,不過這個結果不用求都知道。
在e上的投影離m的長度距離,不過這個結果不用求都知道。
然後是固定![]() ,對e求偏導數,我們先將公式(8)代入
,對e求偏導數,我們先將公式(8)代入![]() ,得
,得
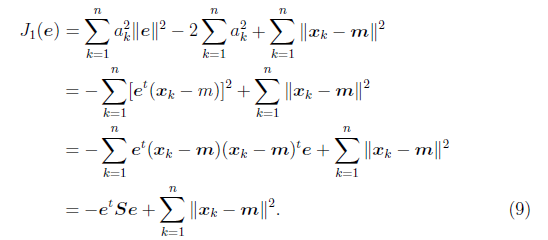
其中![]() 與協方差矩陣類似,只是缺少個分母n-1,我們稱之為雜湊矩陣(scatter matrix)。
與協方差矩陣類似,只是缺少個分母n-1,我們稱之為雜湊矩陣(scatter matrix)。
然後可以對e求偏導數,但是e需要首先滿足![]() ,引入拉格朗日乘子
,引入拉格朗日乘子![]() ,來使
,來使![]() 最大(
最大(![]() 最小),令
最小),令
![]()
求偏導
![]()
這裡存在對向量求導數的技巧,方法這裡不多做介紹。可以去看一些關於矩陣微積分的資料,這裡求導時可以將![]() 看作是
看作是![]() ,將
,將![]() 看做是
看做是![]() 。
。
導數等於0時,得
![]()
兩邊除以n-1就變成了,對協方差矩陣求特徵值向量了。
從不同的思路出發,最後得到同一個結果,對協方差矩陣求特徵向量,求得後特徵向量上就成為了新的座標,如下圖:
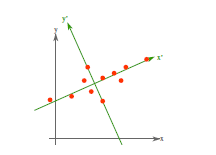
這時候點都聚集在新的座標軸周圍,因為我們使用的最小平方誤差的意義就在此。
4. PCA理論意義
PCA將n個特徵降維到k個,可以用來進行資料壓縮,如果100維的向量最後可以用10維來表示,那麼壓縮率為90%。同樣影象處理領域的KL變換使用PCA做影象壓縮。但PCA要保證降維後,還要保證資料的特性損失最小。再看回顧一下PCA的效果。經過PCA處理後,二維資料投影到一維上可以有以下幾種情況:
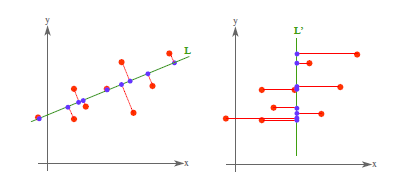
我們認為左圖好,一方面是投影后方差最大,一方面是點到直線的距離平方和最小,而且直線過樣本點的中心點。為什麼右邊的投影效果比較差?直覺是因為座標軸之間相關,以至於去掉一個座標軸,就會使得座標點無法被單獨一個座標軸確定。
PCA得到的k個座標軸實際上是k個特徵向量,由於協方差矩陣對稱,因此k個特徵向量正交。看下面的計算過程。
假設我們還是用![]() 來表示樣例,m個樣例,n個特徵。特徵向量為e,
來表示樣例,m個樣例,n個特徵。特徵向量為e,![]() 表示第i個特徵向量的第1維。那麼原始樣本特徵方程可以用下面式子來表示:
表示第i個特徵向量的第1維。那麼原始樣本特徵方程可以用下面式子來表示:
前面兩個矩陣乘積就是協方差矩陣![]() (除以m後),原始的樣本矩陣A是第二個矩陣m*n。
(除以m後),原始的樣本矩陣A是第二個矩陣m*n。
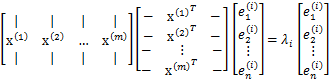
上式可以簡寫為![]()
我們最後得到的投影結果是![]() ,E是k個特徵向量組成的矩陣,展開如下:
,E是k個特徵向量組成的矩陣,展開如下:
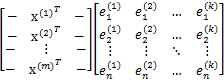
得到的新的樣例矩陣就是m個樣例到k個特徵向量的投影,也是這k個特徵向量的線性組合。e之間是正交的。從矩陣乘法中可以看出,PCA所做的變換是將原始樣本點(n維),投影到k個正交的座標系中去,丟棄其他維度的資訊。舉個例子,假設宇宙是n維的(霍金說是11維的),我們得到銀河系中每個星星的座標(相對於銀河系中心的n維向量),然而我們想用二維座標去逼近這些樣本點,假設算出來的協方差矩陣的特徵向量分別是圖中的水平和豎直方向,那麼我們建議以銀河系中心為原點的x和y座標軸,所有的星星都投影到x和y上,得到下面的圖片。然而我們丟棄了每個星星離我們的遠近距離等資訊。

5. 總結與討論
PCA技術的一大好處是對資料進行降維的處理。我們可以對新求出的“主元”向量的重要性進行排序,根據需要取前面最重要的部分,將後面的維數省去,可以達到降維從而簡化模型或是對資料進行壓縮的效果。同時最大程度的保持了原有資料的資訊。
PCA技術的一個很大的優點是,它是完全無引數限制的。在PCA的計算過程中完全不需要人為的設定引數或是根據任何經驗模型對計算進行干預,最後的結果只與資料相關,與使用者是獨立的。
但是,這一點同時也可以看作是缺點。如果使用者對觀測物件有一定的先驗知識,掌握了資料的一些特徵,卻無法通過引數化等方法對處理過程進行干預,可能會得不到預期的效果,效率也不高。
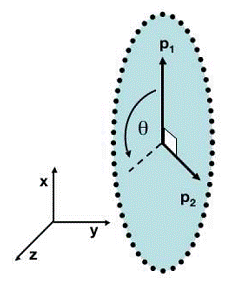
圖表 4:黑色點表示取樣資料,排列成轉盤的形狀。
容易想象,該資料的主元是![]() 或是旋轉角
或是旋轉角![]() 。
。
如圖表 4中的例子,PCA找出的主元將是![]() 。但是這顯然不是最優和最簡化的主元。
。但是這顯然不是最優和最簡化的主元。![]() 之間存在著非線性的關係。根據先驗的知識可知旋轉角
之間存在著非線性的關係。根據先驗的知識可知旋轉角![]() 是最優的主元(類比極座標)。則在這種情況下,PCA就會失效。但是,如果加入先驗的知識,對資料進行某種劃歸,就可以將資料轉化為以
是最優的主元(類比極座標)。則在這種情況下,PCA就會失效。但是,如果加入先驗的知識,對資料進行某種劃歸,就可以將資料轉化為以![]() 為線性的空間中。這類根據先驗知識對資料預先進行非線性轉換的方法就成為kernel-PCA,它擴充套件了PCA能夠處理的問題的範圍,又可以結合一些先驗約束,是比較流行的方法。
為線性的空間中。這類根據先驗知識對資料預先進行非線性轉換的方法就成為kernel-PCA,它擴充套件了PCA能夠處理的問題的範圍,又可以結合一些先驗約束,是比較流行的方法。
有時資料的分佈並不是滿足高斯分佈。如圖表 5所示,在非高斯分佈的情況下,PCA方法得出的主元可能並不是最優的。在尋找主元時不能將方差作為衡量重要性的標準。要根據資料的分佈情況選擇合適的描述完全分佈的變數,然後根據概率分散式
![]()
來計算兩個向量上資料分佈的相關性。等價的,保持主元間的正交假設,尋找的主元同樣要使![]() 。這一類方法被稱為獨立主元分解(ICA)。
。這一類方法被稱為獨立主元分解(ICA)。
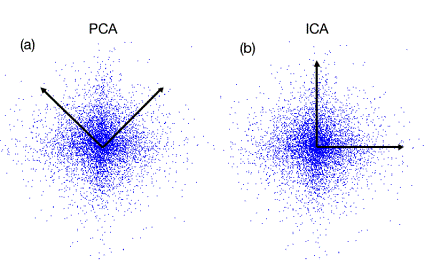
圖表 5:資料的分佈並不滿足高斯分佈,呈明顯的十字星狀。
這種情況下,方差最大的方向並不是最優主元方向。
另外PCA還可以用於預測矩陣中缺失的元素。
6. 其他參考文獻
所謂主成分,就是在某方向上樣本投影之後,被廣泛散佈,使得樣本之間的差別變得最明顯。為了得到唯一解並且使得該方向成為最重要因素,要求該向量長度為1,利用拉格朗日,計算出在方差最大情況下,我們選擇具有最大特徵值的特徵向量為該投影向量。後面次方差最大。。。如此類推。由於協方差矩陣是對稱的,因此,對於兩個不同的特徵值,特徵向量是正交的。
通常情況下,我們考慮貢獻90%以上方差的前K個分量,或者利用斜坡圖,目視化分析拐點k,也可以忽略特徵值小於平均輸入方差的特徵向量。
當然,如果原維之間不相關,則PCA就沒有收益。在許多影象和語音處理任務中,鄰近的輸入時高度相關的。
如果原維的方差變化顯著,則他們對主成分方向的影響比相關性大。因此,一般在PCA之前預處理下,使得每個維都具有0均值和單位方差。或者,為了使協方差而不是個體方差起作用,我們用協相關矩陣R而不是協方差矩陣S的本徵向量。
離群點對方差有很大影響,從而影響特徵向量,魯棒的估計方法是允許計算離群點存在時的引數,如計算資料的馬氏距離,丟棄哪些遠離的孤立點資料。
當原維度很大時,我們可以直接從資料計算特徵向量,特徵值,不必計算協方差矩陣。
在所有正交線性投影中,PCA最小化重構誤差。
這裡,作為一種維度歸約方法,我們直觀地介紹主成分分析。
假定待歸約的資料由n個屬性或維描述的元組或資料向量組成。主成分分析(principal components analysis)或PCA(又稱Karhunen-Loeve或K-L方法)搜尋k個最能代表資料的n維正交向量,其中k≤n。這樣,原來的資料投影到一個小得多的空間,導致維度歸約。不像屬性子集選擇通過保留原屬性集的一個子集來減少屬性集的大小,PCA通過建立一個替換的、更小的變數集“組合”屬性的基本要素。原資料可以投影到該較小的集合中。PCA常常揭示先前未曾察覺的聯絡,並因此允許解釋不尋常的結果。
基本過程如下:
(1)對輸入資料規範化,使得每個屬性都落入相同的區間。此步有助於確保具有較大定義域的屬性不會支配具有較小定義域的屬性。
(2)PCA計算k個標準正交向量,作為規範化輸入資料的基。這些是單位向量,每一個方向都垂直於另一個。這些向量稱為主成分。輸入資料是主成分的線性組合。
(3)對主成分按“重要性”或強度降序排列。主成分基本上充當資料的新座標軸,提供關於方差的重要資訊。也就是說,對座標軸進行排序,使得第一個座標軸顯示資料的最大方差,第二個顯示次大方差,如此下去。例如,圖2-17顯示原來對映到軸X1和X2的給定資料集的前兩個主成分Y1和Y2。這一資訊幫助識別資料中的分組或模式。
(4)既然主成分根據“重要性”降序排列,就可以通過去掉較弱的成分(即方差較小)來歸約資料的規模。使用最強的主成分,應當能夠重構原資料的很好的近似。
圖2-17 主成分分析。Y1和Y2是給定資料的前兩個主成分
PCA計算開銷低,可以用於有序和無序的屬性,並且可以處理稀疏和傾斜資料。多於2維的多維資料可以通過將問題歸約為2維問題來處理。主成分可以用作多元迴歸和聚類分析的輸入。與小波變換相比,PCA能夠更好地處理稀疏資料,而小波變換更適合高維資料。
三.FA
FA也是非監督的,但與PCA相反,其旨在找到較少數量的因子,刻畫觀測變數之間的依賴性。但是,對於維度歸約,除了因子可解釋性,允許識別公共原因,簡單解釋,知識提取外,FA與PCA相比,並無優勢。
1 問題
之前我們考慮的訓練資料中樣例![]() 的個數m都遠遠大於其特徵個數n,這樣不管是進行迴歸、聚類等都沒有太大的問題。然而當訓練樣例個數m太小,甚至m<<n的時候,使用梯度下降法進行迴歸時,如果初值不同,得到的引數結果會有很大偏差(因為方程數小於引數個數)。另外,如果使用多元高斯分佈(Multivariate Gaussian distribution)對資料進行擬合時,也會有問題。讓我們來演算一下,看看會有什麼問題:
的個數m都遠遠大於其特徵個數n,這樣不管是進行迴歸、聚類等都沒有太大的問題。然而當訓練樣例個數m太小,甚至m<<n的時候,使用梯度下降法進行迴歸時,如果初值不同,得到的引數結果會有很大偏差(因為方程數小於引數個數)。另外,如果使用多元高斯分佈(Multivariate Gaussian distribution)對資料進行擬合時,也會有問題。讓我們來演算一下,看看會有什麼問題:
多元高斯分佈的引數估計公式如下:
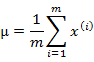
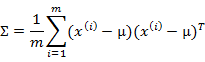
分別是求mean和協方差的公式,![]() 表示樣例,共有m個,每個樣例n個特徵,因此
表示樣例,共有m個,每個樣例n個特徵,因此![]() 是n維向量,
是n維向量,![]() 是n*n協方差矩陣。
是n*n協方差矩陣。
當m<<n時,我們會發現![]() 是奇異陣(
是奇異陣(![]() ),也就是說
),也就是說![]() 不存在,沒辦法擬合出多元高斯分佈了,確切的說是我們估計不出來
不存在,沒辦法擬合出多元高斯分佈了,確切的說是我們估計不出來![]() 。
。
如果我們仍然想用多元高斯分佈來估計樣本,那怎麼辦呢?
2 限制協方差矩陣
當沒有足夠的資料去估計![]() 時,那麼只能對模型引數進行一定假設,之前我們想估計出完全的
時,那麼只能對模型引數進行一定假設,之前我們想估計出完全的![]() (矩陣中的全部元素),現在我們假設
(矩陣中的全部元素),現在我們假設![]() 就是對角陣(各特徵間相互獨立),那麼我們只需要計算每個特徵的方差即可,最後的
就是對角陣(各特徵間相互獨立),那麼我們只需要計算每個特徵的方差即可,最後的![]() 只有對角線上的元素不為0
只有對角線上的元素不為0
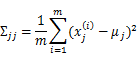
回想我們之前討論過的二維多元高斯分佈的幾何特性,在平面上的投影是個橢圓,中心點由![]() 決定,橢圓的形狀由
決定,橢圓的形狀由![]() 決定。
決定。![]() 如果變成對角陣,就意味著橢圓的兩個軸都和座標軸平行了。
如果變成對角陣,就意味著橢圓的兩個軸都和座標軸平行了。
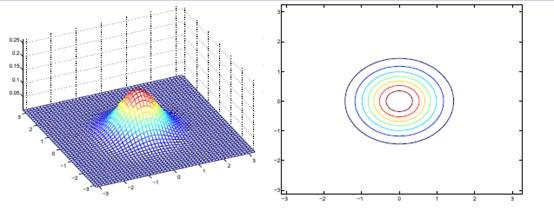
如果我們想對
這裡,我們討論特徵選擇和特徵提取,前者選取重要的特徵子集,後者由原始輸入形成較少的新特徵,理想情況下,無論是分類還是迴歸,我們不應該將特徵選擇或特徵提取作為一個單獨的程序,分類或者回歸方法應該能夠利用任何必要的特徵,而丟棄不相關的特徵。但是,考慮到演算法儲存量和時間的複雜度,
在特徵處理中,會有空值的刪除或者填充。
一:刪除
1一般刪除是最簡單的,用na.omit(data)就搞定,但是太粗暴了。
2若是有的觀測量空缺值太多的話,確實需要刪除,因為用別的方法填充反而會導致模型偏差。
那麼腫麼統計觀測量的空值的個數捏?可以參
轉自:https://www.cnblogs.com/lianyingteng/p/7792693.html
在機器學習問題中,我們通過訓練資料集學習得到的其實就是一組模型的引數,然後通過學習得到的引數確定模型的表示,最後用這個模型再去進行我們後續的預測分類等工作。在模型訓練過程中,我們會對訓練
'''
將原始資料的word特徵數字化為countvector特徵,並將結果儲存到本地
article特徵可做類似處理
'''
import pandas as pd
from sklearn.feature_extraction.text import c
對於64128的影象而言,每88的畫素組成一個cell,每22個cell組成一個塊,也就是說,64128的圖片,總共有36715=3780個特徵。
單個cell的9個特徵,每個block(掃描視窗)包含22個cell也就是229=36個特徵,一個64128大小的
HOG方向梯度直方圖:
(1)具體在HOG中方向梯度的實現:首先用[-1,0,1]梯度運算元對原影象做卷積運算,得到x方向(水平方向,以向右為正方向)的梯度分量gradscalx,然後用[1,0,-1]T梯度運算元對原影象做卷積運算,得到y方向(豎直方向,以向上為正方向)的 上圖是一張行人圖的四種表示方式,原三色圖,灰度圖,邊緣圖,梯度圖,人腦根據前期學習與先驗知識很容易理解到影象中包含著一個行人,並可以根據一定情況將其從影象中摳選出來,但計算機是怎麼思考的呢?怎樣讓計算機理解以上影象中包含的是一個行人呢?前三個影象現在情況不適用,所以選取梯度圖,現在的梯度圖同樣也是人腦處理
主成分分析(Principal Component Analysis,PCA), 將多個變數通過線性變換以選出較少個數重要變數的一種多
元統計分析方法.
--------------------------------------------目錄--------------
基礎的線性判別式,這裡不做說明。主要是邏輯斯蒂判別式的說明和梯度下降迭代求解演算法。
1.邏輯斯蒂方程(Logistic Equation)
邏輯斯蒂方程的推導
當一種新產品剛面世時,廠家和商家總是採取各種措施促進銷售。他們都希望對這種產品的推銷速度做到心中有數,這 gis 引入 定義 增加 2017年 理論值 nbsp 得到 正數 矩陣求導
目錄
一、 矩陣求導的基本概念
1. 一階導定義
2. 二階導數
二、 梯度下降
1. 方向導數.
1.1 定義
1.2 方向導數的計算公式.
1.3 梯度下降最快的方向
1. 系列 學習 python 機器學習 自然語言處理 圖片 clas 數學基礎 記錄 學習python快一年了,因為之前學習python全棧時,沒有記錄學習筆記想回顧發現沒有好的記錄,目前主攻python自然語言處理方面,把每天的學習記錄記錄下來,以供以後查看,和交流分享。~~
1.對於矩陣的認識應當把它看成是多個向量的排列表或把矩陣看成行向量,該行向量中的每個元素都是一個列向量,即矩陣是複合行向量。如下圖所示。 2.對於下面這個矩陣的乘法有兩種看法: (1)矩陣將向量[b1,b2,b3].T進行了運動變換,這種變換可以是同空間內變換,也可以是不同空間間的變換;
這兩篇內容為西瓜書第 6 章支援向量機 6.1,6.2,6.4,6.3 的內容:
6.1 間隔與支援向量
6.2 對偶問題
6.4 軟間隔與正則化
6.3 核函式
由於本章內容較多,分為兩篇來敘述。本篇所包含內容為間隔與支援向量和對偶問題。
如移動端無法正常
作為一名初學框架的菜鳥,記錄這一次在慕課學習整個框架基礎功能的過程,與大家共勉!
本專案利用SSM框架,完成了秒殺專案簡單的增刪改查功能,對初學框架的小菜鳥(比如我)有非常好的指導作用。
專案開發所用工具:IDEA開發環境,jdk1.8,Mysql 8.0.
1、演算法介紹決策樹是一種基本的分類和迴歸方法,決策樹模型呈樹形結構,在分類問題中,表示基於特徵對例項進行分類的過程。決策樹學習通常包括三個步驟:特徵選擇、決策樹的生成和決策樹的修剪。決策樹的本質是從訓練資料集中歸納出一組分類規則。本文主要是對決策樹的ID3演算法的介紹,後文會介紹C4.5和CART演算 environ 電子 6.0 run javase 有一點 架構 spa form 一、Java的三種技術架構:
JAVAEE:Java Platform Enterprise Edition,開發企業環境下的應用程序,主要針對web程序開發;
JAVASE:Java P pac 本質 uid spa album 空間 矩陣 amp .com 目錄 一、線性空間 1. 線性空間的概念 (1) 線性空間的定義 (2) 線性空間的本質 2. 線性空間的基 (1) 線性表示 (2) 線性相關 (3) 線性無關 (4) 線性空間基的定義 (5) 坐標 邏輯 style 發的 nfa 不同的 構建 john 局限 認識 首先聲明,我是一個spring初學者,寫這篇blog的目的是為了能和大家交流。文中不當之處還望大佬指出,不勝感激!
好了,現在我們開始進入正題。
很多小夥伴在學習Java的時候都會有人建議你去學 plot 我們 all 查看 學習 ear tla clear 但是 一.清除命令。
1.clear all;%清除所有變量,通常在matlab的工作區;另外斷點也會被清除掉
2.close all;%關閉所有窗口(除了編輯器窗口、命令窗口、幫助窗口)
3.cl
linux 檔案許可權相關
Linux使用者分為: 擁有者、組群(Group)、其他(Other) linux檔案的許可權總共有10位,如 -rwxrwxr-x ,分為4段。 第一段 佔1位 表示檔案的型別 - :表示普通檔案 d :表示資料夾、目錄 l :表示連結檔案,類似window ![clip_image010[9]](http://images.cnblogs.com/cnblogs_com/jerrylead/201105/20110511155700700.png)
相關推薦
系統學習機器學習之特徵工程(一)--維度歸約
R讀書筆記之特徵工程(一)空值處理
系統學習機器學習之特徵工程(二)--離散型特徵編碼方式:LabelEncoder、one-hot與啞變數*
特徵工程(一)countvectororizer
影象處理之特徵提取(一)之HOG特徵 特徵數的計算
影象處理之特徵提取(一):HOG特徵
影象處理之特徵提取(一)之HOG特徵簡單梳理
SparkML之特徵提取(一)主成分分析(PCA)
系統學習機器學習之線性判別式(一)
機器學習數學基礎之矩陣理論(三)
機器學習之數學基礎(一)-微積分,概率論和矩陣
機器學習之數學系列(一)矩陣與矩陣乘法
【資料科學系統學習】機器學習演算法 # 西瓜書學習記錄 [7] 支援向量機(一)
記慕課學習秒殺系統之DAO層(一)
機器學習之決策樹(一)
JavaSE 學習筆記之Java概述(一)
器學習數學基礎之矩陣理論(二)
我們一起學習Spring之Spring簡介(一)
matlab學習筆記之常用命令(一)
嵌入式linux學習之基礎知識(一) linux檔案許可權