
記因併發事物引起死鎖後所展開的問題定位及解決過程
講一些題外話,沒興趣的可直接跳過.
首先非常感謝並宣傳一波常常被罵的狗血淋頭卻又覺得異常可愛的暗滅大人. 教會我的太多太多, 但最重要的也是和這篇文章有關聯的就是讓我明白該如何去思考問題, 定位問題, 解決問題.
首先介紹下背景, 這邊做的是一對多(包括一對一)的私信功能,那麼自然而然對應的就需要幾個api其中包括
1.傳送私信
2.略略略
表結構如下:
groups表
用於儲存使用者組資訊, 使用者組是由兩個或多個使用者組成的
| COLUMN | TYPE | REQURIED | COMMENT |
| id | Bigint | true | 自增id |
| code | Varchar | true | 組員id正序排序特 殊符號分割後加密 |
| latest_message_id | Bigint | true | 傳送給當 前所有組員的 最新訊息id |
user_group_relations表
因為一個使用者可能有多個組所以使用一張表來儲存使用者與組的關係
| COLUMN | TYPE | REQURIED | COMMENT |
| id | BigInt | true | 自增id |
| user_id | BigInt | true | 使用者id |
| unread_message_counts | Integer | true | 對應group中 未讀訊息總數 |
| group_id | BigInt | true | groupId |
messages表
用於儲存私信
| COLUMN | TYPE | REQURIED | COMMENT |
| id | BigInt | true | 自增id |
| sender_id | BigInt | true | 私信傳送方id |
| content | Varchar | true | 私信內容 |
| group_id | BigInt | true | 傳送給使用者組中成員 的組id |
對應業務層介面如下:
/** * * 將訊息儲存到db * 儲存成功後更新對應userGroup表的latestMessageId * 更新userGroupRelation表中對應使用者的未讀訊息數量 * * 以上三步操作必須保證原子性, 因此執行在一個事物中. * @param receiverIds 接收訊息使用者id * @param message 訊息實體 * @return 成功建立後的message實體. */ Message sendMessage(List<Long> receiverIds, Message message);
可能各位看官會有疑問, 為何沒有senderId, senderId是通過springSecurity中的上下文獲取當前使用者id的,包含在實現中.
寫這篇部落格時才想到這樣不太好, 依賴於springSecurity,萬一不用springSecurity又得改程式碼 (記下, 馬上去重構 )
)
簡單來說傳送一個私信需要做如下步驟
1.通過將senderId和receiverIds排序分割加密後作為group的code
2.通過code獲取Group(code對應那條記錄加s鎖)
3.messages表中有group的外來鍵, 因為使用的orm所以呼叫new出來message瞬態物件的setGroup方法, 引數為第2步中code查詢出來的結果
4.save第3步中的瞬態message物件到messages表中 (新增成功後獲取該行記錄的x鎖)
5.更新第二步中group那條記錄的latest_message_id為第4步中插入成功後的id (code對應那條記錄的x鎖)
6.更新user_group_relations中的n條unread_message_counts為+1
實現程式碼如下
/**
*
* 高併發下會產生多個事物,若將{@link com.hikedu.backend.model.UserGroup#latestMessageId}的更新邏輯放置在傳送訊息邏輯中
* 不僅影響效能, 而且會造成死鎖.
* 鑑於上述原因, 暫不更新該冗餘欄位, 後續可採用訊息佇列的形式在訊息傳送完畢後進行更新
*
* @param receiverIds 接收訊息使用者id
* @param message 訊息實體
* @return
*/
@Transactional(isolation = Isolation.READ_COMMITTED, rollbackFor = Throwable.class, propagation = Propagation.REQUIRED)
@NotNull
@Override
public Message sendMessage(List<Long> receiverIds, Message message) {
//TODO 優化高併發下的效能. 目前一秒內產生400個併發請求,90%Line平均為2500, tps平均為10.2/s, error%為2.25或0
log.info("The user {} sending a message", message.getSender().getId());
log.info("The receiverIds is {}", receiverIds);
log.info("The message content is {}", message.getContent());
List<Long> copyReceiverIds = new ArrayList<>(receiverIds);
if (message.getSender() == null) {
throw new RuntimeException("The sender can not be null");
}else {
Message fullMessage;
if (isSendMessageAllowed(copyReceiverIds, message)) {
//將獲取UserGroup的s鎖
message = fillUpForSendMessage(copyReceiverIds, message);
//將獲取UserGroup的s鎖和插入message的x鎖
fullMessage = messageRepository.saveAndFlush(message);
log.info("The inserted message id is {}", fullMessage.getId());
//獲取userGroup的s鎖和x鎖
userGroupRelationService.
addUnreadMessageCounts(receiverIds, message.getUserGroup().getId(), 1);
return fullMessage;
} else {
throw new RuntimeException("The current operation not allowed, cause - unknown");
}
}
}以上是解決完死鎖後的程式碼, 其中去掉了如下userGroupService方法的呼叫
/**
* 更新最新訊息id
* @param userGroupIds 需要更新的使用者組id
* @param latestMessageId 最新訊息id
* @return 更新後的所有使用者組
*/
List<UserGroup> changeLatestMessageId(List<Long> userGroupIds, Long latestMessageId);以上就是整個的需求加實現方案及實現程式碼,非併發下執行ok.
鑑於上家公司養成了對api進行壓力測試觀察併發下執行情況的習慣(再次感謝暗滅大人), 開啟jmeter開400個併發,一秒內全部發送出去.
此時,問題就是出現了, error百分率為80%多, 嚇得我趕緊檢視日誌.
Deadlock found when trying to get lock; try restarting transaction趕緊google一波,發現是死鎖. 咦, 死鎖是啥沒遇到過啊
google一波死鎖,找到好幾篇這篇講的ok
死鎖產生的必要條件也知道了,也知道了s鎖和x鎖的定義和概念
又google找到其他人解決死鎖過程的部落格
沒啥收穫, 但是知道了怎麼去看mysql最新的死鎖日誌
也知道了怎麼閱讀mysql死鎖日誌
隨後,瘋狂操作一波,看到了dead lock 日誌
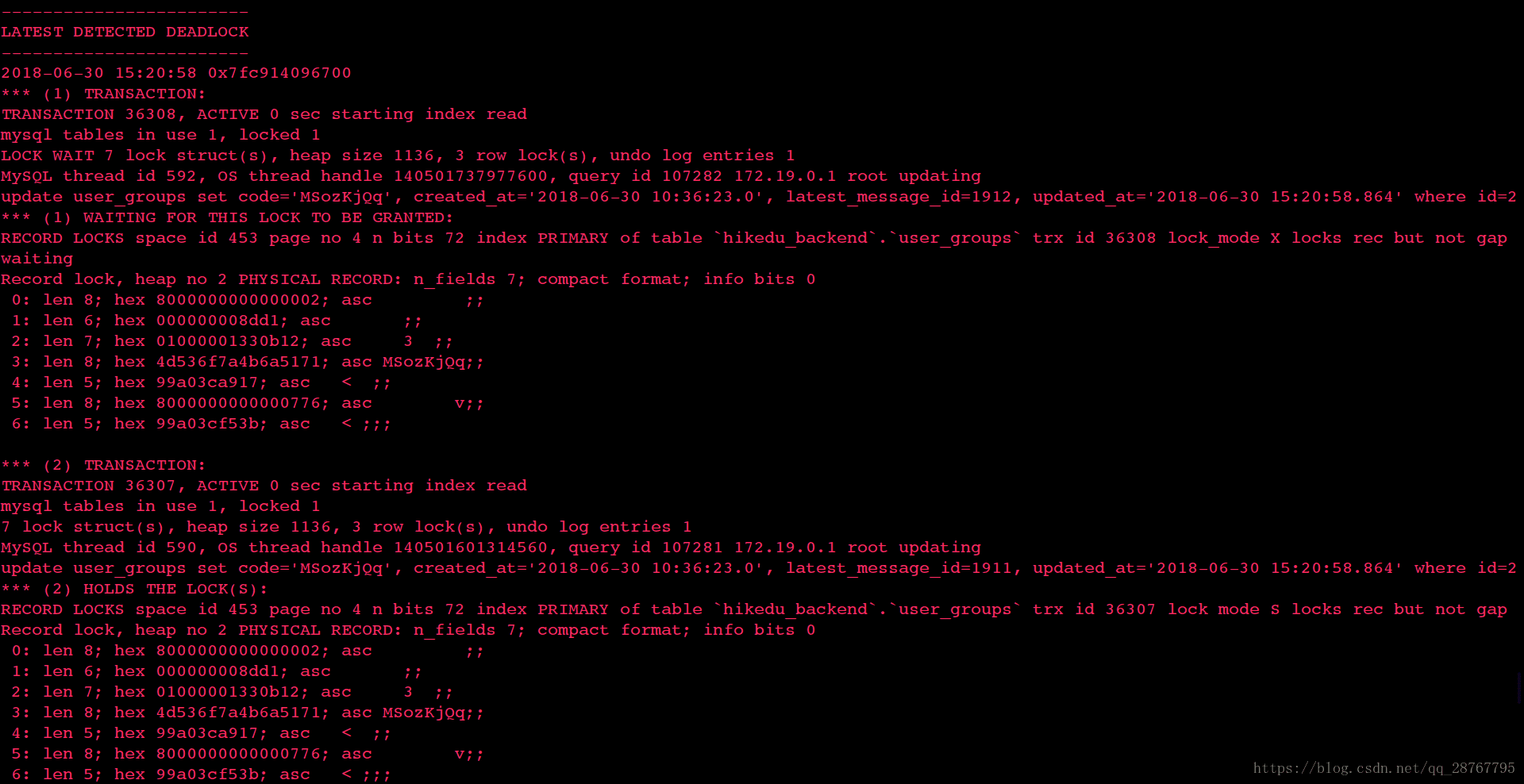
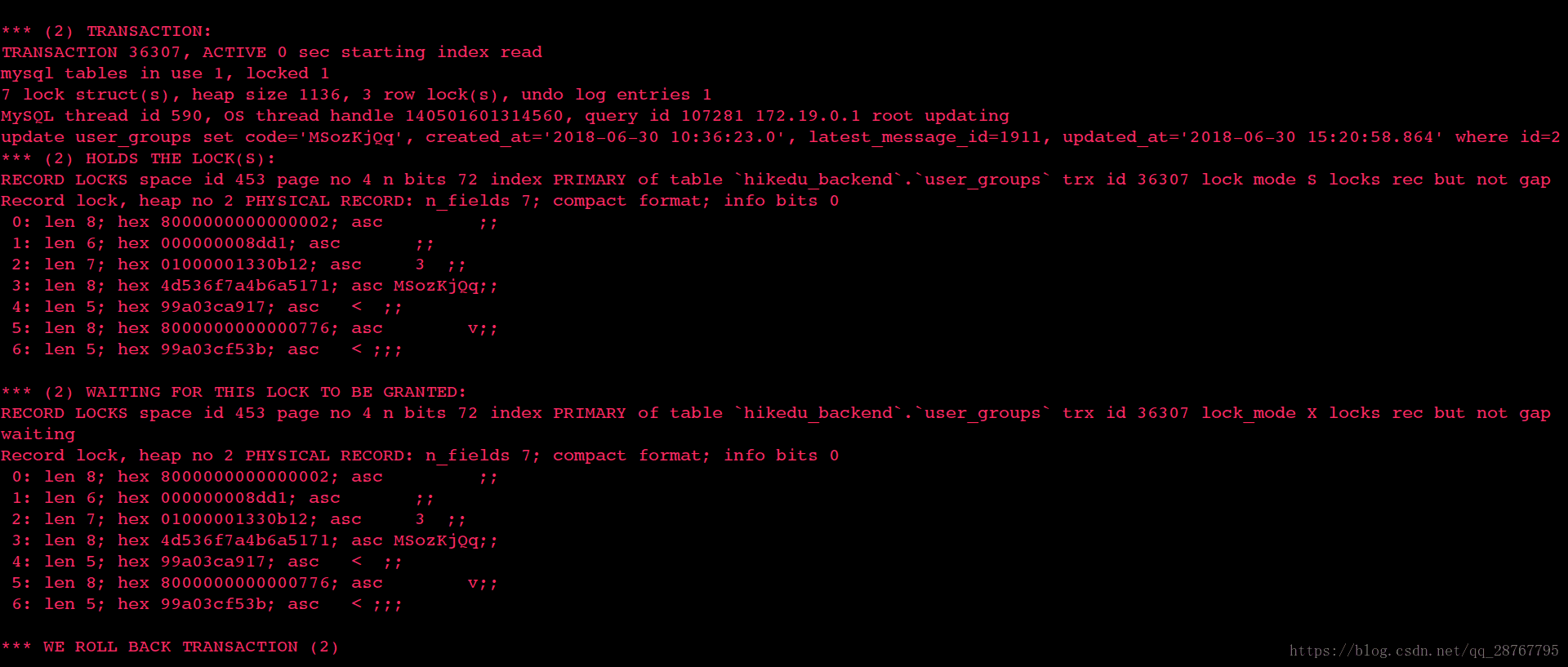
查閱以上dead lock日誌可知
事物1在等待user_groups(對應當前文章中的group)表中記錄為主鍵為2那行的x鎖, 本身不持有其他鎖 (實際持有該行記錄的s鎖)
事物2也在等待user_groups(對應當前文章中的group)表中記錄為主鍵為2那行的x鎖,本身擁有正在等待獲取x鎖那行記錄的s鎖
s鎖,x鎖的定義如下
以上定義轉載自其他部落格, 已標記為超連結.
根據s鎖x鎖的定義和當前事物持有的鎖和等待的鎖可知如下事實
1.事物1持有group表中id為2那行記錄的s鎖, 在等待x鎖
2.事物2持有group表中id為2那行記錄的s鎖,在等待x鎖
3.事物1和事物2永遠無法提交, 因為兩者均需要獲取x鎖, 又都持有s鎖, 因事物未結束,又無法釋放s鎖.
4.MySQL會介入並將其中一個事物回滾, 回滾後的事物釋放s鎖, 另一個事物能夠獲得x鎖.
so, 這就是為什麼會出現error率為80%多的原因, 那麼我們回到程式碼中看看為何會出現這種情況.
以下程式碼為會對錶進行操作的方法呼叫
userGroup = userGroupService.getByCode(userGroupCode); (獲取group表中id為2那行記錄的s鎖)
//將獲取gropup表中id為2那行記錄的s鎖和插入message的x鎖
fullMessage = messageRepository.saveAndFlush(message);
//獲取group為2那行記錄的x鎖
userGroupService.changeLatestMessageId(savedUserGroup, fullMessage.getId());在併發下有兩個執行緒同時進行, 因為sendMessage方法開啟了事物,因此也產生了兩個事物.
事物1執行完第一步操作後執行第二步操作, 在第三步操作執行前事物2執行了如下步驟
事物2執行完了第一步獲得了group為2那條記錄的s鎖 (此時事物1也已獲得).
有趣的事情發生了
事物1在等事物2釋放group主鍵為2那行記錄的s鎖以便獲取x鎖
事物2也在等待事物1釋放group主鍵為2那行記錄的s鎖以便獲取x鎖
最終死鎖.
那麼解決方法還是有幾個的,但是好幾個都行不通
一.將事物的粒度縮小, 也就是巢狀事物
將以上三步呼叫的方法上都啟用事物, 並對事物做如下設定
將傳播級別設定為PROPAGATION_REQUIRES_NEW
隔離界別設定為READ_COMMITTED
很傻很天正, 這樣會出現兩種情況
1.lock wait time out 鎖等待超時
因為外層的事物也就是sendMessage被掛起, sendMessage中獲取了幾行記錄的s鎖或x鎖
該事物不結束不會釋放鎖,而在其他三個獨立的事物中也需要獲取sendMessage事物中加鎖那行記錄的鎖,最終一直等啊等啊等啊等, tiem out ,game over.
2.因事物隔離級別,無法查詢到sendMessage事物中更改或新增的記錄
sendMessage這個事物中對錶中的記錄進行了更改或新增, 隨後被巢狀在sendMessage事物中的事物掛起, 掛起後執行巢狀中的事物,巢狀中的事物無法查詢到sendMessage事物中對於表進行的更改,所以,就是各種NotFoudException.
其實上述問題可以通過調整隔離級別來實現, 但是考慮到不能產生髒讀,最終放棄.
二. 強制執行緒同步
執行緒同步,也就是保證事物有序執行. 這樣是ok的, 但是不管是非併發還是併發下效能堪憂,最終放棄
三.精確定位導致死鎖的程式碼行,並考慮進行移除或優化解決死鎖 (最終解決方案)
最終定位到引起死鎖的那行程式碼如下
//獲取group為2那行記錄的x鎖
userGroupService.changeLatestMessageId(savedUserGroup, fullMessage.getId());這步是更新group表中的冗餘欄位latest_message_id,
想到可以加入到佇列或redis快取中來非同步處理, 最終刪除該行程式碼, 趕緊瘋狂操作壓測了一波
最後各項資料還算說的過去,資料如下:
非併發請求平均響應在200ms以下
400個請求,1秒之內全部發送出去., 因為是本地所以效能太差, 但是不會死鎖. 90%Line在2250ms, tps在10條/s error率 0%,
同時保證了傳送私信三步操作的原子性,在異常時能夠正常回滾.
最後說下花費將近1.3小時寫這篇部落格的收穫吧.
蚊子特別喜歡我, 親了我好幾下.
剿滅蚊子2只.
note: 有哪裡講的不對的,還請各位大佬指正.
相關推薦
記因併發事物引起死鎖後所展開的問題定位及解決過程
講一些題外話,沒興趣的可直接跳過.首先非常感謝並宣傳一波常常被罵的狗血淋頭卻又覺得異常可愛的暗滅大人. 教會我的太多太多, 但最重要的也是和這篇文章有關聯的就是讓我明白該如何去思考問題, 定位問題, 解決問題.首先介紹下背景, 這邊做的是一對多(包括一對一)的私信功能,
死鎖、死鎖的四個必要條件、死鎖預防、死鎖避免和銀行家演算法及解題過程
死鎖: 死鎖是指多個程序因競爭資源而造成的一種僵局(互相等待),每個程序都在等待某個事件發生,而只有這組程序中的其他程序才能觸發該事件,這就稱這組程序發生了死鎖。若無外力作用,這些程序都將無法向前推進。 如,在某一個計算機系統中只有一臺印表機和一臺輸入 裝置,程序P1正佔
一個多執行緒死鎖案例,如何避免及解決死鎖問題?
多執行緒死鎖在java程式設計師筆試的時候時有遇見,死鎖概念在之前的文章有介紹,大家應該也都明白它的概念,不清楚的去翻看歷史文章吧。 下面是一個多執行緒死鎖的例子 輸出 thread1 get lock1 thread2 get lock2 兩個執行緒相互得到鎖1,鎖2,然後
select 時進行update的操作,在高並發下引起死鎖
xxxx 數據 高並發 select 聚集索引 操作 加鎖 content 其他 場景:當用戶查看帖子詳情時,把帖子的閱讀量:ReadCount+1 select title,content,readcount from post where id=‘xxxx‘ --根
第六章—併發性:死鎖和飢餓【計算機作業系統】
6.1 給出可重用資源和可消費資源的例子。 可重用資源:處理器,I/O通道,主存和輔存,裝置以及諸如檔案,資料庫和訊號量之類的資料結構。 可消費資源:中斷,訊號,訊息和I/O緩衝區中的資訊。 6.2 可能發生死鎖所必須的三個條件是什麼? 互斥,佔有且等待,非搶佔。 6.
一個AMS、PMS、WMS競爭鎖引起死鎖無法開啟問題的分析過程
問題:在工廠段出現,一直提示“android 正在啟動”,長按開機鍵恢復。由於產線生產機器都是按K計算,所以概率問題會放大,此問題大約1000臺機器會出現10臺左右的卡在android正在啟動,由於到了量產階段,問題緊急,無奈我還被緊急派去生產車間解決問題,最快
GCD dispatch_sync同步引起死鎖的問題
截圖中可以看到程式執行到主執行緒同步執行時出現崩潰,下面來分析一下崩潰原因:首先了解一下dispatch_sync:第一個引數 queue 為佇列物件,第二個引數block為block物件。這個介面是同步將block扔到佇列queue中去執行,即扔了我就等著,等到queue排
入坑JAVA多執行緒併發(六)死鎖
在多執行緒的中,因為要保證執行緒安全,需要對一些操作進行加鎖,但是如果操作不當,會造成死鎖,導致程式無法執行下去。 形成死鎖的場景:如果有兩個執行緒,執行緒1和執行緒2,執行緒1執行,獲得鎖A,執行緒2執行,獲得B,執行緒1等待鎖B的釋放,執行緒2等待
SqlServer 併發事務:死鎖跟蹤(二)確定死鎖鎖定的資源
--測試示例: CREATE TABLE mytest ( id INT, name VARCHAR(20), info VARCHAR(20), ) INSERT INTO mytest VALUES(1,
查詢引起死鎖的SQL
SELECT XEvent.query('(event/data/value/deadlock)[1]') AS DeadlockGraph FROM ( SELECT XEvent.query('.') AS XEvent FROM ( SELECT CAST
pb中如何控制併發和控制死鎖
鎖的概述 一. 為什麼要引入鎖 多個使用者同時對資料庫的併發操作時會帶來以下資料不一致的問題: 丟失更新 A,B兩個使用者讀同一資料並進行修改,其中一個使用者的修改結果破壞了另一個修改的結果,比如訂票系統 髒讀 A使用者修改了資料,隨後B使用者又讀出該資料,但
記一次Mysql線上死鎖
Mysql死鎖日誌解讀(SHOW ENGINE INNODB STATUS;)2018-02-01 09:20:25 2b113e040700 INNODB MONITOR OUTPUT ===================================== Per se
工作執行緒操作主介面控制元件引起死鎖及解決
問題描述: 在監控程式中,設計一監控迴圈。 標頭檔案 .h HANDLE m_hEventExit; CWinThread*
【Java併發基礎】死鎖
前言 我們使用加鎖機制來保證執行緒安全,但是如果過度地使用加鎖,則可能會導致死鎖。下面將介紹關於死鎖的相關知識以及我們在編寫程式時如何預防死鎖。 什麼是死鎖 學習作業系統時,給出死鎖的定義為兩個或兩個以上的執行緒在執行過程中,由於競爭資源而造成的一種阻塞的現象,若無外力作用,它們都將無法推進下去。簡化一點說就
併發程式設計中死鎖、遞迴鎖、程序/執行緒池、協程TCP伺服器併發等知識點
1、死鎖 定義; 類似兩個人分別被囚禁在兩間房子裡,A手上拿著的是B囚禁房間的鑰匙,而B拿著A的鑰匙,兩個人都沒法出去,沒法給對方開鎖,進而造成死鎖現象。具體例子程式碼如下: # -*-coding:utf-8 -*- from threading import Thread,Lock,RLoc
一個罕見的MySQL redo死鎖問題排查及解決過程
作者:張青林,騰訊雲佈道師、MySQL架構師,隸屬騰訊TEG-基礎架構部-CDB核心開發團隊,專注於MySQL核心研發&相關架構工作,有著服務多個10W級QPS客戶的資料庫優化及穩定性維護經驗。騰訊雲資料庫團隊:繼承騰訊資料庫團隊十多年海量儲存的內部資料庫運營和運維經驗,推出一系列高效能
MSSQL死鎖進程查看及關閉
tab kill sql int rom 鎖表 arc ted soc select request_session_id spid,OBJECT_NAME(resource_associated_entity_id) tableName from sys.dm_tran_
死鎖的原因,避免及預防
我們可以把作業系統看作是銀行家,作業系統管理的資源相當於銀行家管理的資金,程序向作業系統請求分配資源相當於使用者向銀行家貸款。 為保證資金的安全,銀行家規定: (1) 當一個顧客對資金的最大需求量不超過銀行家現有的資金時就可接納該顧客; (2) 顧客可以分期貸款,但貸款的總數不能超過最大需求量; (3) 當
死鎖的四個必要條件和解決辦法
這樣雖然避免了迴圈等待,但是這種方法是比較低效的,資源的執行速度回變慢,並且可能在沒有必要的情況下拒絕資源的訪問,比如說,程序c想要申請資源1,如果資源1並沒有被其他程序佔有,此時將它分配個程序c是沒有問題的,但是為了避免產生迴圈等待,該申請會被拒絕,這樣就降低了資源的利用率
ride.py在執行python3.×版本後導致無法執行及解決辦法
最近一直在自學python自動化,網上看到rf框架挺適合初學自動化測試,於是通過蟲師的搭建了rf框架, 但是在使用過程中遇到了一個問題,在網上沒有找到明確解決辦法於是想到記錄一下 之前為了搭建rf框架下載了python2.7版本,後面又想玩下爬蟲於是下了python3.4版本結果出現了下面的問題:和往常一樣切