
鄧仰東專欄|機器學習的那些事兒(一)
目錄
1.緒論
1.1.概述
1.2 機器學習簡史
1.3 機器學習改變世界:基於GPU的機器學習例項
1.3.1 基於深度神經網路的視覺識別
1.3.2 AlphaGO
1.3.3 IBM Waston
1.4 機器學習方法分類和本書組織
在這一章裡面,我們首先審視正在高歌猛進的資料科學,瞭解使用GPU進行機器學習計算的重要性。接下來,我們回顧機器學習的發展歷程,並且檢閱當前機器學習技術的幾項最高成就:人工智慧圍棋(AlphaGo)、深度神經網路影象識別(ImageNet)和IBM Waston人工智慧系統,從而領略機器學習技術震撼世界的腳步。第三部分,我們對機器學習演算法進行概略分類,並且根據分類結果介紹本書內容。
1.1 概述
我們生活在一個偉大的時代,人類文明史上最卓越的心智成就以前所未有的深度、廣度和速度交匯融合,催生出潛力無限的資料科學(data science)。資料科學是在人類社會數字化程度充分發展的前提下,綜合電腦科學、數學和神經科學等領域的理論和技術成果,以資料探勘作為應用形式,通過對資料進行儲存、分析和視覺化等各種處理,從中提煉資訊並形成知識,從而引導優化決策的科學。簡單說來,資料科學就是針對大資料的理論和方法。
當前,資料科學已經深度融入我們的日常生活,我們可以從一天的平凡生活中檢查一下資料科學在怎樣發揮作用的:上下班路上,導航系統會分析資料告訴我們不同路線的擁堵情況並且實時預測預計行程時間,如果乘坐公車的話,還可以通過歷史資料和實時路況預報公車到站時間;我們打電話時,電信運營商會通過採集我們打電話的模式,諸如地點、時間段和服務套餐情況(但是不能使用時頻、語音和個人帳號資訊),推斷我們的身份、生活習慣和經濟狀況,從而確定相應的推送內容;
我們上網衝浪時,搜尋引擎提供的內容當然是對海量網頁進行分析處理的結果,而且也會我把我們的搜尋內容拿去分析,從中提煉熱點搜尋趨勢,並且對我們的行為進行推斷;購物時,無論是電商還是傳統商戶,都可能分析我們的購物歷史決定向我們推薦商品,而在付款之中或之後,銀行的資料分析系統會判斷這是一次正常消費還是一次欺詐;
工作時,即使我們不直接使用資料分析工具,也幾乎不可避免地在產生或者消費資料,有些公司(例如惠普)甚至使用預測軟體分析每個僱員辭職的可能性( 有趣的是,資料分析師自己經常被判別為潛在離職風險較高的僱員,因為社會需求極為迫切。)
除此之外,還有更多的資料分析系統在暗中“琢磨”我們,比如說醫療保險公司在算計我們未來的健康趨勢,由此決定保費應該怎樣變化,社交網路公司在計算是否發現了你的同學或者熟人,或者怎樣讓你的社交圈通過最短路徑和其它群落連線起來,還有基金公司會分析社交網路上大家的情感趨勢,以此作為預測證券價格漲落的依據,如果你是單身而且在徵婚網站登記的話,還會有資料分析引擎根據你的資料進行分類和匹配,為你尋找合適的另一半。
資料科學向社會生活的滲透正在以不可阻擋的勢頭在更大範圍上更加深化。表1-1是遠不完全(實際上完整列舉資料應用已經成為不可能完成的任務)的典型資料科學應用的清單。
表1.1 典型資料應用
|
公司/組織 |
代表性資料應用 |
亮點 |
|
谷歌Google |
對全球35萬億個網頁進行索引,並形成1億G位元組的索引記錄 |
全部Internet搜尋服務的89%由Google提供 |
|
亞馬遜Amazon |
採集並分析其7.5億顧客的購物行為(包括購物和瀏覽),分析顧客的收入和偏好,從而為顧客進行商品推薦 |
Amazon的推薦系統是其成為美國最大線上零售商(年產值900億美元)的主要助力,也是其品牌的重要標誌 |
|
網飛Netflix |
根據電影內容進行分類,並根據使用者觀看電影的歷史進行喜好分析並推薦電影 |
非結構化資料學習的經典技術,是Netflix使用者和流量繼續加速增長的主要動力 |
|
沃爾瑪 Walmart |
利用購物籃分析推薦商品,使用社會和環境資料預測購買需求 |
沃爾瑪自行開發的Data Café資料分析系統處理一個擁有2000億組交易資料的資料庫,能夠把銷售問題平均解決時間從2~3周降低至20分鐘左右 |
|
歐洲核子研究組織CERN |
分析資料中的特殊能量特徵,從中確定是否發現特定粒子 |
每年產生30PB資料,主要是粒子對撞機中粒子碰撞時產生的光訊號,2013年通過分析資料發現了希格斯玻色子 |
|
羅爾斯-羅伊斯Rolls-Royce |
分析發動機實時監控資料,確定優化維護和修理方案 |
支撐全球500家以上航空公司和150多支空軍的航空發動機,大資料技術顯著降低了運維成本 |
|
殼牌石油Shell |
分析地址資料發現油田 |
大幅度提高了勘探精度 |
|
蓮花F1車隊 Lotus F1 Team |
分析賽場資料實時調整塞車引數,利用資料建立模擬模型優化賽車設計 |
把青年車手Marlon Stockinger的賽季總成績從2013年的全球第18名提高到2014年的第9名 |
|
臉書 |
分析使用者資料推送廣告 |
2014年佔據美國24%的線上廣告份額,創收53億美元;預計2017年市場份額達到27%,創收100億美元 |
|
皇家蘇格蘭銀行 Royal Bank of Scotland |
分析交易資料最大化客戶盈利以及支撐各種客戶關係管理需求 |
通過海量資料探勘支撐金融個性化服務 |
|
目標超市 Target |
分解消費者行為預測懷孕可能性並據此推送產品推薦 |
能夠比以往多發現30%以上孕婦 |
|
匹茲堡大學醫療中心 |
出院前預測病人未來30天再次住院的可能性 |
降低治療風險 |
|
倫敦股票交易所 |
分析資料決定投資方案 |
約40%的股票交易由資料應用自行驅動 |
|
大陸航空公司 |
分析航班資料 |
有效降低航班延誤和航線利用率 |
|
奧巴馬競選團隊 |
分析選民資料推測哪些選民更容易被競選活動影響 |
取得了驚人的程式 |
|
惠普 HP |
分析全球35萬名員工的辭職風險 |
預計收益3億美元 |
|
美國國稅局 |
分析納稅人資料發現水手欺詐 |
在不增加工作人時的前提下提升發現逃稅率25倍 |
隨著人類社會數字化程度的迅速提升,目前全球資料規模已經達到44萬億GB。資料增長的速度更是驚人,我們可以從圖1-1中看看當前各大網站一分鐘的資料量。讀者可以想象一下,在閱讀這一頁的過程中,全球資料又增加了多少。
資料產生的來源和數量增長之快,以至於2013年的一份分析報告指出全球資料的90%是在此前兩年中產生的([1] SINTEF. "Big Data, for better or worse: 90% of world's data generated over last two years." Science Daily, 22 May 2013.)也就是說每兩年產生的資料是此前全部資料的10倍,而且我們可以大膽的猜測到本書出版之時,95%甚至更多的資料實在過去三年內產生的。
資料規模是如此之大,種類又是如此之多,以至於一般認為當前我們能夠分析的資料只是全部資料的0.5%。那麼我們怎樣才能充分利用海量資料,而不是“湮沒在資料中卻飢渴於無法獲得知識(Drowning in Data yet Starving for Knowledge)”呢?答案是顯然的,機器學習演算法必須藉助更強勁的計算硬體(嚴格講應該是能效比更高的硬體。)和更加靈活的程式設計技術。
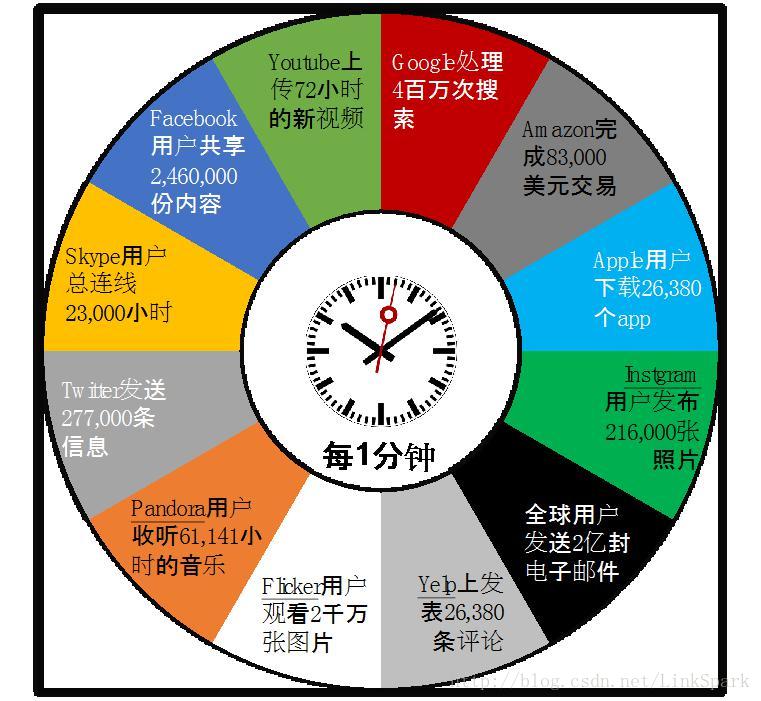
圖1-1 全球1分鐘內產生的資料
然而,我們手中並沒有一種硬體能夠同時在上述兩項要求上都能表現最佳。圖1-2是對常見計算平臺的比較。在圖1-2的左側,是執行順序程式的CPU,其程式設計模式符合人類的思維方式,程式設計工具完備而成熟,然而效能相對有限。
特別是自從2000年以後,傳統上以增加時鐘頻率提升CPU效能的方法已經遇到瓶頸,繼續提高頻率提升效能有限,反而帶來功耗的大幅度增加。數字訊號處理器是對CPU進行訂製,針對特定應用引入專用指令和硬體從而提高效能的處理器,其程式設計靈活性有所下降,但是能夠提高相應應用的效能。數字訊號處理器曾經是高效能的標誌,但是隨著多核CPU的出現,已經逐漸退出高效能運算市場,主要用於嵌入式產品。
多核CPU是在積體電路工藝的整合能力繼續提升而單核效能飽和的產物,通過引入多個並行執行指令的CPU核心保證整體效能的增加。多核CPU必須使用並行程式才能獲得更好的效能,其程式設計靈活性有所限制。
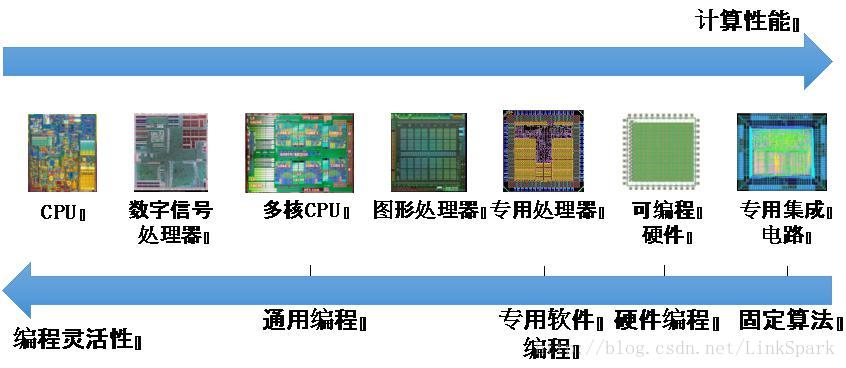
圖1-2 常見計算平臺的計算能力和可程式設計性
在圖1-2的右端是專用積體電路,即針對特定應用採用特定演算法而設計的硬體平臺,完全不具備程式設計能力,但是效能可以達到極致。
在當前市場需求多元化並且高速變化的背景下,缺乏可程式設計能力是嚴重的缺陷,因此專用積體電路只有在用量極大的前提下才具有競爭力,越來越多的電子產品使用系統晶片,即整合專用積體電路和嵌入式處理器的晶片。以FPGA為代表的可程式設計硬體比專用積體電路效能低一個檔次,但是具有硬體程式設計能力,因此也成為一種重要的計算平臺。
專用處理器也是折衷可程式設計性和效能的產物,其思想是針對特定應用設計指令集,其中某些指令可以通過專用硬體直接執行,從而在保持一定程式設計靈活性的基礎上改善效能。然而,專用處理器的應用範圍比較窄,因此程式設計工具極為有限、使用人群較小,因而也限制了靈活性。
圖1-2的中央是圖形處理器(Graphics Processing Unit,簡稱GPU),其前身是為圖形渲染應用而設計的專用處理器,但是經過30年的發展,隨著圖形應用的複雜度越來越高、效能要求越來越突出,已經演變為具有高度計算能力和高度可程式設計能力的計算平臺。
在各種計算硬體中,GPU比較完美地折衷了效能和靈活性。注意以上討論中,我們所說的效能其實指特定製造工藝下單位面積提供的效能,不同製造工藝下的不同類硬體平臺的效能錯綜複雜。
由於GPU擁有圖形渲染市場的支援,能夠保證其出貨量,因此能夠使用最先進的製造工藝並且製造較大的晶片,從而能夠提供極高的單片效能,在較低工藝下製造的專用積體電路和FPGA反而不容易達到使用最新工藝的GPU的效能。從2006年開始,NVIDIA和AMD等GPU製造商意識到GPU可以成為一種與CPU互補的通用計算平臺,相繼退出一系列程式設計工具,從而極大地開闊了GPU的應用。
從2010年開始,機器學習成為全球化熱點,眾多企業、科研和政府機構開始在日常工作中大量使用資料探勘工具,而機器學習演算法普遍具有計算密集特點,特別適合GPU硬體執行,因此,圖形處理器幾乎一夜之間成為機器學習最重要的應用平臺。
參考文獻
[1] SINTEF. "Big Data, for better or worse: 90% of world's data generated over last two years." Science Daily, 22 May 2013.
關注LinkSpark公眾號,瞭解更多人工智慧相關資訊!
相關推薦
鄧仰東專欄|機器學習的那些事兒(一)
目錄 1.緒論 1.1.概述 1.2 機器學習簡史 1.3 機器學習改變世界:基於GPU的機器學習例項 1.3.1 基於深度神經網路的視覺識別 1.3.2 AlphaGO 1.3.3 IBM Waston 1.4 機器學習方
中國mooc北京理工大學機器學習第一周(一)
lib odi pen 運行 numpy 聚類 準則 ++ mooc 從今天開始跟著北理工的老師走一遍sklearn,在這裏做筆記。 一、聚類 1、K-Means方法 先貼代碼,所有數據的下載地址:http://pan.baidu.com/s/1hrO5NW4
中國mooc北京理工大學機器學習第二周(一):分類
kmeans 方法 輸入 nump arr mod 理工大學 each orm 一、K近鄰方法(KNeighborsClassifier) 使用方法同kmeans方法,先構造分類器,再進行擬合。區別是Kmeans聚類是無監督學習,KNN是監督學習,因此需要劃分出訓練集和測試
機器學習入門點滴(一)(待補充完整)
arr intro 統計 int ica nts 機器學習算法 .com 場景 Step1-知識準備: 1. 數學:線性代數,概率論和統計,高數 2. 程序語言:Matlab R 或 Python(只用於學習入門,不是實現的最佳語言) 3. 推薦書籍:選擇一到兩本公式較少、
《Python 機器學習》筆記(一)
環境 成功 設定 相關 reward 能力 學習 一定的 env 賦予計算機學習數據的能力涵蓋:1.機器學習的一般概念2.機器學習方法的三種類型和基本術語3.成功構建機器學習系統所需的模塊機器學習的三種不同方法1.監督學習2.無監督學習3.強化學習通過監督學習對未來事件進行
機器學習實戰教程(一):線性回歸基礎篇(上)
學習 reg style spa 目標 pub auto 機器 輸入 一 什麽是回歸? 回歸的目的是預測數值型的目標值,最直接的辦法是依據輸入,寫入一個目標值的計算公式。 假如你想預測小姐姐男友汽車的功率,可能會這麽計算: Ho
吳恩達老師機器學習筆記SVM(一)
時隔好久沒有再拾起機器學習了,今日抽空接著學 今天是從最簡單的二維資料分類開始學習SVM~ (上圖為原始資料) SVM的代價函式 這裡套用以前logistic迴歸的模板改一下下。。 load('ex6data1.mat'); theta=rand(3,1); [
機器學習基礎概念(一)
“無監督學習”是指人們在獲得訓練的向量資料後在沒有標籤的情況下嘗試找出其內部蘊含關係的一種挖 掘工作,這個過程中使用者除了可能要設定一些必要的超引數( hyper-parameter)以外,不 用對這些樣本做任何的標記甚至是過程干預; “有監督學習”與此不同,每一個樣本都有著 明確的標籤,最
系統學習機器學習之總結(一)--常見分類演算法優缺點
主要是參考網上各種資源,做了整理。其實,這裡更多的是從基礎版本對比,真正使用的時候,看資料,看改進後的演算法。 1. 五大流派 ①符號主義:使用符號、規則和邏輯來表徵知識和進行邏輯推理,最喜歡的演算法是:規則和決策樹 ②貝葉斯派:獲取發生的可能性來進行概率推理,最喜歡的演算法是:樸素貝葉
跨平臺機器學習實踐小結(一)
一、問題來源: 如何在node web服務下呼叫sklearn的模型結果來進行實時模型預測? 二、問題分析: 1、sklearn的模型結果有幾種儲存方式: (1)pickle.dumps ,結果通過變數儲存在記憶體中 附上pickle文件:https://docs.pytho
機器學習速成筆記(一): 主要術語
機器學習研究如何通過計算的方式,利用資料集來改善系統自身的效能。 而深度學習是屬於機器學習的一個子分支。 機器學習的通用的兩種型別: 無監督學習:事先並沒有任務訓練資料的樣本,需要直接對資料進行建模型。 監督學習:通過已經有的訓練樣本(即輸入資訊和對應的輸出)來訓練,得到一個
機器學習實戰筆記(一)- 使用SciKit-Learn做回歸分析
err 皮爾遜 練習 using flow 相關 一個數 ocean 針對 一、簡介 這次學習的書籍主要是Hands-on Machine Learning with Scikit-Learn and TensorFlow(豆瓣:https://book.douban.co
機器學習:SVM(一)——線性可分支援向量機原理與公式推導
原理 SVM基本模型是定義在特徵空間上的二分類線性分類器(可推廣為多分類),學習策略為間隔最大化,可形式化為一個求解凸二次規劃問題,也等價於正則化的合頁損失函式的最小化問題。求解演算法為序列最小最優化演算法(SMO) 當資料集線性可分時,通過硬間隔最大化,學習一個線性分類器;資料集近似線性可分時,即存在一小
《機器學習實戰》(一)knn演算法
K最近鄰(k-Nearest Neighbor,KNN)分類演算法可以說是最簡單的機器學習演算法了。它採用測量不同特徵值之間的距離方法進行分類。它的思想很簡單:存在一個樣本資料集合,也稱作訓練樣本集,並且樣本集中每個資料都存在標籤,即我們知道樣本集中每一個數據與所屬分類的對應關係。輸入沒有標
Coursera吳恩達機器學習教程筆記(一)
人工智慧行業如火如荼,想要入門人工智慧,吳恩達老師的機器學習課程絕對是不二之選(當然,這不是我說的,是廣大網友共同認為的) 教程的地址連結: 有的同學可能進不去這個網站,解決辦法參照如下連結: 這個辦法本人親測有效,因為我看的時候也打不開(囧!!)
機器學習之路(一)---支援向量機SVM
##什麼是支援向量機(SVM)? 支援向量機 (SVM) 是一個類分類器,正式的定義是一個能夠將不同類樣本在樣本空間分隔的超平面。 換句話說,給定一些標記(label)好的訓練樣本 (監督式學習), SVM演算法輸出一個最優化的分隔超平面。 如何來界定一個超
機器學習scikit-learn(一)
機器學習scikit-learn 在資料分析過程中,我們經常會碰到各種各樣的問題。如何獲取外部資料?如何處理髒資料?如何處理缺失值?若有許多特徵,我們減少特徵?建立各種模型中演算法的細節?到最後,面對多種模型,我們該如何選擇?這些問題,都將在此文中得到解答。此
【機器學習】吳(一)
什麼是機器學習?①Two definitions of Machine Learning are offered. Arthur Samuel described it as: "the field of study that gives computers the abil
【科普周】機器學習掃盲篇(一)
給大家舉個例子:以我們之前做的波士頓房價視覺化迴歸預測來看,如果告訴機器一棟房子所在地區的住宅地比例、環保的指標、自住的比例、便利的指數、以及不動產稅率等指標,以及不同指標下房屋的價格,這樣機器就能學習這些指標的特點和房價的關係,而給出當前指標下具體的房屋價格。但是這個價格準確率的問題要看機器通過不同模型和演
機器學習實戰ByMatlab(一)KNN演算法
KNN 演算法其實簡單的說就是“物以類聚”,也就是將新的沒有被分類的點分類為周圍的點中大多數屬於的類。它採用測量不同特徵值之間的距離方法進行分類,思想很簡單:如果一個樣本的特徵空間中最為臨近(歐式距