
Android OCR文字識別 實時掃描手機號(極速掃描單行文字方案)
遇到一個需求,要用手機掃描紙質面單,獲取面單上的手機號,最後決定用tesseract這個開源OCR庫,移植到Android平臺是tess-two
評論裡有人想要我訓練的數字字型檔,這裡貼出來(只訓練了 黑體、微軟雅黑、宋體 0-9的數字,其他字型識別率會降低)
數字字型檔地址:http://download.csdn.net/download/mr_sk/10186145 (現在上傳資源好像不能免費下載了,至少要收兩個積分….)
這篇部落格主要是記錄我的思路,大多是散亂的筆記,所以大家遇到報錯什麼的不要急,看看demo和Log總能找到問題
我遇到的坑(只想瞭解用法的可以跳過)
Tesseract雖然是個很強大的庫,但直接使用的話,並不適用於連續識別的需求,因為tess-two對解析影象的清晰度
所以在沒有優化的情況下,直接用tess-two 來作文字識別,只能是拍一張照,然後等待識別結果,比如識別文章、掃描身份證等,如果像我的需求,需要識別面單上的手機號,可能一分鐘需要掃描幾十個手機號,那就必須要達到毫秒級的解析速度,直接使用常規的方法肯定是不行的,那怎麼辦呢?
tess-two的識別演算法當然是沒辦法處理了,那就得從其他方面去想辦法
第一個:是在字型檔方面,官方的一個英文字型檔 30M,但是你面臨的需求需要這麼重量級的字型檔嗎?比如我掃描手機號的功能,面單上都是黑體字,手機號只有純數字, 就這麼點識別範圍去檢索一個30M的字型檔,顯然多了很多無用功
解決辦法就是:
訓練自己的字型檔,如果你需要毫秒級的掃描速度,那你的需求涉及的掃描內容 範圍一定很小(前面說過,如果你要做文章識別之類的,那就用官方字型檔,拍一張照片,等幾秒鐘,完全是可以接受的),這樣就可以根據需求範圍內 常見的 ”字型“ 和 ”字元“來訓練專門的字型檔,這樣你就能使用一個輕量級的定製字型檔,極大的減少了解析時間,比如我手機號的數字子庫,只有100KB,識別我處理後的圖片,從官方字型檔的1.5-3秒,減少到了300-500ms
第二個: 就是在把圖片交給tess-two解析之前,先進行簡單的內容過濾,如上面所說的,即便是我把一張圖片的解析速度壓縮到了300-500ms,依然存在一個問題,那就是識別頻率,要做連續掃描,相機肯定是一直開著的,那一秒鐘幾十幀的圖片,你該解析哪一張呢?
每一張都解析的話,對效能是很大的消耗,也要考慮一些用低端機的使用者,而且每次解析的時間不等,識別結果也很混亂,那就只有每次取一幀解析,拿到解析結果後,再去解析下一幀那麼問題又來了:相機一秒幾十幀,一開啟相機,第一幀就開始解析了,這樣下一次開始解析就在300-500ms之後了,如果使用者在對準手機號的前一刻,正好開始了一幀畫面的解析,那等到開始解析手機號,至少也在幾百毫秒以後了,加上手機號本身的解析時間,從對準到拿到結果,隨隨便便就超過了1秒,加上每次識別速度不定,可能特殊情況耗時更久,這樣必然會感到很明顯的延遲,那該怎麼處理呢?
解決辦法就是:
在圖片交給tess-two之前,先進行圖片二級裁切,第一次裁切就是利用介面的掃描框,拿到需要掃描的區域,然後進行內容過濾,把明顯不可能包含手機號的影象直接忽略,不進行解析,這個過程需要遍歷圖片的畫素,用jni處理時間不超過10ms,即便是用java處理,也只有10-50ms,只要能忽略大部分的無用的影象,那就解決了這個延遲的問題,並且在過濾的同時,如果被判斷為有用圖片,那就能同時拿到需要解析的文字塊,然後進行第二次裁切,拿到更小的圖片,進一步提升解析速度至於過濾的方式,我寫了針對手機號的過濾,在文章最下面的單行文字優化方案部分,有相似需求的可以看看,然後針對自己的需求,來寫過濾演算法
至於最後掃描的內容的提取,可以用正則公式來篩選關鍵資訊如:手機號、網址、郵箱、身份證、銀行卡號 等
Demo截圖
圖一

圖二

圖三
水印清除
圖四

圖五

圖一:是掃描線沒有對準手機號碼,未捕捉到手機號的狀態,這種狀態下,每一幀都會在10-30ms之內被確定掃描線沒有對準一個手機號而被過濾掉,不交給tess-two解析,直接放棄這一幀資料
圖二:是掃描線對準了手機號,經過過濾演算法後,捕捉到一個包含11位字元的蚊子塊,基本確認存在手機號
圖三:是 圖二 狀態下的識別結果
圖四:是被水印干擾的手機號所得到的二值化圖片
圖五:是清除水印後取到的手機號區域(只適用於圖五這種文字底部的干擾)
tess-two基本使用
這裡是基本用法,我最早寫的,效率不高但程式碼易讀,是tess-two的使用方法,識別還是有明顯延遲,優化方案我放在了文章後面的優化部分,Demo也更新了最新的優化方案,如果對這方面比較熟練,可以從後面開始看,這裡由簡入繁
整合很簡單,build.gradle中加入:
compile ‘com.rmtheis:tess-two:6.0.0’
//後面我已經換到8.0.0,上傳的demo是在6.0.0下執行的
compile ‘com.rmtheis:tess-two:8.0.0’
編譯一下,框架的整合就ok了,不過tess-two的文字型檔是需要另外下載的,我們一般只需要中文和英文兩種就可以了,特殊需求可以自己訓練
字型庫下載地址:https://github.com/tesseract-ocr/tessdata
英文:eng.traineddata
簡體中文:chi_sim.traineddata
將這兩個字型庫檔案,放到sd卡,路徑必須為 **/tessdata/
路徑為什麼一定要為**/tessdata/呢?在TessBaseApi類的初始化方法中會檢查你的文字型檔目錄,程式碼如下
/**
* datapath是你傳入的文字型檔路徑,可以看到這裡在傳入的datapath後加了一個"tessdata"目錄
* 然後驗證了這個目錄是否存在,如果不在,就會報錯"資料目錄必須包含tessdata目錄"
*/
File tessdata = new File(datapath + "tessdata");
//tessdata是否存在且是個目錄
if (!tessdata.exists() || !tessdata.isDirectory())
throw new IllegalArgumentException("Data path must contain subfolder tessdata!");然後就是使用了,這裡我的字型庫檔案都放在 “根目錄/Download/tessdata“中
解析圖片程式碼如下:
public class OcrUtil {
//字型庫路徑,此路徑下必須包含tessdata資料夾,但不用把tessdata寫上
static final String TESSBASE_PATH = Environment.getExternalStorageDirectory() + File.separator + "Download" + File.separator;
//英文
static final String ENGLISH_LANGUAGE = "eng";
//簡體中文
static final String CHINESE_LANGUAGE = "chi_sim";
/**
* 識別英文
*
* @param bmp 需要識別的圖片
* @param callBack 結果回撥(攜帶一個String 引數即可)
*/
public static void ScanEnglish(final Bitmap bmp, final MyCallBack callBack) {
new Thread(new Runnable() {
@Override
public void run() {
TessBaseAPI baseApi = new TessBaseAPI();
//初始化OCR的字型資料,TESSBASE_PATH為路徑,ENGLISH_LANGUAGE指明要用的字型庫(不用加字尾)
if (baseApi.init(TESSBASE_PATH, ENGLISH_LANGUAGE)) {
//設定識別模式
baseApi.setPageSegMode(TessBaseAPI.PageSegMode.PSM_AUTO);
//設定要識別的圖片
baseApi.setImage(bmp);
//開始識別
String result = baseApi.getUTF8Text();
baseApi.clear();
baseApi.end();
callBack.response(result);
}
}
}).start();
}
}好了,識別工具寫好了,接下要做的就是,開啟相機、獲取預覽圖、裁切出需要的區域,然後交給tess-two識別,這裡我直接吧SurfaceView封裝了一下,自動開啟相機開始預覽,下面是掃描手機號的程式碼:
public class CameraView extends SurfaceView implements SurfaceHolder.Callback, Camera.PreviewCallback {
private final String TAG = "CameraView";
private SurfaceHolder mHolder;
private Camera mCamera;
private boolean isPreviewOn;
//預設預覽尺寸
private int imageWidth = 1920;
private int imageHeight = 1080;
//幀率
private int frameRate = 30;
public CameraView(Context context) {
super(context);
init();
}
public CameraView(Context context, AttributeSet attrs) {
super(context, attrs);
init();
}
public CameraView(Context context, AttributeSet attrs, int defStyleAttr) {
super(context, attrs, defStyleAttr);
init();
}
private void init() {
mHolder = getHolder();
//設定SurfaceView 的SurfaceHolder的回撥函式
mHolder.addCallback(this);
mHolder.setType(SurfaceHolder.SURFACE_TYPE_PUSH_BUFFERS);
}
@Override
public void surfaceCreated(SurfaceHolder holder) {
//Surface建立時開啟Camera
openCamera();
}
@Override
public void surfaceChanged(SurfaceHolder holder, int format, int width, int height) {
//設定Camera基本引數
if (mCamera != null)
initCameraParams();
}
@Override
public void surfaceDestroyed(SurfaceHolder holder) {
try {
release();
} catch (Exception e) {
}
}
private boolean isScanning = false;
/**
* Camera幀資料回撥用
*/
@Override
public void onPreviewFrame(byte[] data, Camera camera) {
//識別中不處理其他幀資料
if (!isScanning) {
isScanning = true;
new Thread(new Runnable() {
@Override
public void run() {
try {
//獲取Camera預覽尺寸
Camera.Size size = camera.getParameters().getPreviewSize();
//將幀資料轉為bitmap
YuvImage image = new YuvImage(data, ImageFormat.NV21, size.width, size.height, null);
if (image != null) {
ByteArrayOutputStream stream = new ByteArrayOutputStream();
//將幀資料轉為圖片(new Rect()是定義一個矩形提取區域,我這裡是提取了整張圖片,然後旋轉90度後再才裁切出需要的區域,效率會較慢,實際使用的時候,照片預設橫向的,可以直接計算逆向90°時,left、top的值,然後直接提取需要區域,提出來之後再壓縮、旋轉 速度會快一些)
image.compressToJpeg(new Rect(0, 0, size.width, size.height), 80, stream);
Bitmap bmp = BitmapFactory.decodeByteArray(stream.toByteArray(), 0, stream.size());
//這裡返回的照片預設橫向的,先將圖片旋轉90度
bmp = rotateToDegrees(bmp, 90);
//然後裁切出需要的區域,具體區域要和UI佈局中配合,這裡取圖片正中間,寬度取圖片的一半,高度這裡用的適配資料,可以自定義
bmp = bitmapCrop(bmp, bmp.getWidth() / 4, bmp.getHeight() / 2 - (int) getResources().getDimension(R.dimen.x25), bmp.getWidth() / 2, (int) getResources().getDimension(R.dimen.x50));
if (bmp == null)
return;
//將裁切的圖片顯示出來(測試用,需要為CameraView setTag(ImageView))
ImageView imageView = (ImageView) getTag();
imageView.setImageBitmap(bmp);
stream.close();
//開始識別
OcrUtil.ScanEnglish(bmp, new MyCallBack() {
@Override
public void response(String result) {
//這是區域內掃除的所有內容
Log.d("scantest", "掃描結果: " + result);
//檢索結果中是否包含手機號
Log.d("scantest", "手機號碼: " + getTelnum(result));
isScanning = false;
}
});
}
} catch (Exception ex) {
isScanning = false;
}
}).start();
}
}
/**
* 獲取字串中的手機號
*/
public String getTelnum(String sParam) {
if (sParam.length() <= 0)
return "";
Pattern pattern = Pattern.compile("(1|861)(3|5|8)\\d{9}$*");
Matcher matcher = pattern.matcher(sParam);
StringBuffer bf = new StringBuffer();
while (matcher.find()) {
bf.append(matcher.group()).append(",");
}
int len = bf.length();
if (len > 0) {
bf.deleteCharAt(len - 1);
}
return bf.toString();
}
/**
* Bitmap裁剪
*
* @param bitmap 原圖
* @param width 寬
* @param height 高
*/
public static Bitmap bitmapCrop(Bitmap bitmap, int left, int top, int width, int height) {
if (null == bitmap || width <= 0 || height < 0) {
return null;
}
int widthOrg = bitmap.getWidth();
int heightOrg = bitmap.getHeight();
if (widthOrg >= width && heightOrg >= height) {
try {
bitmap = Bitmap.createBitmap(bitmap, left, top, width, height);
} catch (Exception e) {
return null;
}
}
return bitmap;
}
/**
* 圖片旋轉
*
* @param tmpBitmap
* @param degrees
* @return
*/
public static Bitmap rotateToDegrees(Bitmap tmpBitmap, float degrees) {
Matrix matrix = new Matrix();
matrix.reset();
matrix.setRotate(degrees);
return Bitmap.createBitmap(tmpBitmap, 0, 0, tmpBitmap.getWidth(), tmpBitmap.getHeight(), matrix,
true);
}
/**
* 攝像頭配置
*/
public void initCameraParams() {
stopPreview();
//獲取camera引數
Camera.Parameters camParams = mCamera.getParameters();
List<Camera.Size> sizes = camParams.getSupportedPreviewSizes();
//確定前面定義的預覽寬高是camera支援的,不支援取就更大的
for (int i = 0; i < sizes.size(); i++) {
if ((sizes.get(i).width >= imageWidth && sizes.get(i).height >= imageHeight) || i == sizes.size() - 1) {
imageWidth = sizes.get(i).width;
imageHeight = sizes.get(i).height;
//
break;
}
}
//設定最終確定的預覽大小
camParams.setPreviewSize(imageWidth, imageHeight);
//設定幀率
camParams.setPreviewFrameRate(frameRate);
//啟用引數
mCamera.setParameters(camParams);
mCamera.setDisplayOrientation(90);
//開始預覽
startPreview();
}
/**
* 開始預覽
*/
public void startPreview() {
try {
mCamera.setPreviewCallback(this);
mCamera.setPreviewDisplay(mHolder);//set the surface to be used for live preview
mCamera.startPreview();
mCamera.autoFocus(autoFocusCB);
} catch (IOException e) {
mCamera.release();
mCamera = null;
}
}
/**
* 停止預覽
*/
public void stopPreview() {
if (mCamera != null) {
mCamera.setPreviewCallback(null);
mCamera.stopPreview();
}
}
/**
* 開啟指定攝像頭
*/
public void openCamera() {
Camera.CameraInfo cameraInfo = new Camera.CameraInfo();
for (int cameraId = 0; cameraId < Camera.getNumberOfCameras(); cameraId++) {
Camera.getCameraInfo(cameraId, cameraInfo);
if (cameraInfo.facing == Camera.CameraInfo.CAMERA_FACING_BACK) {
try {
mCamera = Camera.open(cameraId);
} catch (Exception e) {
if (mCamera != null) {
mCamera.release();
mCamera = null;
}
}
break;
}
}
}
/**
* 攝像頭自動聚焦
*/
Camera.AutoFocusCallback autoFocusCB = new Camera.AutoFocusCallback() {
public void onAutoFocus(boolean success, Camera camera) {
postDelayed(doAutoFocus, 1000);
}
};
private Runnable doAutoFocus = new Runnable() {
public void run() {
if (mCamera != null) {
try {
mCamera.autoFocus(autoFocusCB);
} catch (Exception e) {
}
}
}
};
/**
* 釋放
*/
public void release() {
if (isPreviewOn && mCamera != null) {
isPreviewOn = false;
mCamera.setPreviewCallback(null);
mCamera.stopPreview();
mCamera.release();
mCamera = null;
}
}
}
佈局檔案:
<?xml version="1.0" encoding="utf-8"?>
<RelativeLayout xmlns:android="http://schemas.android.com/apk/res/android"
android:layout_width="match_parent"
android:layout_height="match_parent"
android:gravity="center_horizontal">
<!--相機預覽視窗,上面設定的預覽大小是1080x1920,為保證比例,記得Activity的style不要加ActionBar,保證全屏顯示-->
<test.com.ocrtest.CameraView
android:id="@+id/main_camera"
android:layout_width="match_parent"
android:layout_height="match_parent" />
<!--掃描框,和上面裁切規則一樣,寬度為螢幕的一半,高度對應上面的x50(1080P解析度下為168px)-->
<TextView
android:layout_width="@dimen/x160"
android:layout_height="@dimen/x50"
android:layout_centerInParent="true"
android:background="@drawable/fillet_gray_border_btn" />
<!--顯示被裁切出的圖片,需要setTag到CameraView中,詳見上面CameraView程式碼-->
<ImageView
android:id="@+id/main_image"
android:layout_width="wrap_content"
android:layout_height="wrap_content"
android:layout_centerHorizontal="true" />
</RelativeLayout>
更新
對於文字識別這塊,我之後還嘗試了幾種方案,這裡列舉一下
1、tess-two
適用場景:小區域連續掃描解析 (比如識別手機號、單詞 等)
優點:免費開源、本地解析、英文數字識別率可觀
缺點:識別速度慢、需要做大量優化(下面我會貼出我針對自己的專案做出的一些優化,避免解析大部分無意義的畫面,二值化提高識別率等)
2、各個平臺的OCR API,比如百度、騰訊、合合資訊 等
適用場景:識別頻率不高、需要識別大圖(比如拍一張照,點確認,拿到結果,就OK了 像身份證 銀行卡識別)
優點:識別率高
缺點: 收費(費用不高)、解析速度太依賴網路質量、無本地解析SDK,需要上傳圖片然後獲取解析結果,因為不能每一幀都上傳解析,所以不能用作連續掃描
我之前嘗試過百度ocr,方案是給使用者一個按鈕,使用者點選之後,取相機最近的一幀照片上傳給百度,然後跳過其他幀,等待使用者下一次點選解析按鈕。通過壓縮裁切圖片,我已經把圖片壓縮到10+kb、在網速良好的情況下,解析速度能達到0.5秒,但如果網速不好,體驗急劇下降
3、有一些平臺提供本地Ocr解析的SDK(比如合合資訊)
適用場景:大部分需求都能實現
優點: 解析速度快、識別率高
缺點: 費用奇高 -_-(企業合作級別的費用)
對於tess-two的進一步優化(這裡針對我的需求,只識別單行手機號):
文章開頭說過了,提高效率最重要的就是訓練出為自己需求量身定做的字型檔,我需要識別的面單上的手機號,全部是黑體的數字,那我就針對“黑體 數字”來訓練我的字型檔,我訓練出來的字型檔大小100+KB,識別優化後的手機號圖片,只要300-500ms,再過濾掉大部分無意義影象,就可以實現連續掃描,而官方的包識別至少1.5-3秒,如果再無法過濾無意義影象,那識別一個手機號10秒鐘能搞定你就謝天謝地了
訓練方法在文章開頭有連結,至於訓練用的模板圖片,文章最下面的優化程式碼中,把最終取到的影象儲存下來去訓練就好了
對於把圖片交給tess-two之前的優化
主要包括:減小圖片的尺寸大小、二值化圖片使文字黑白分明、判斷圖片內容是否無意義
1、裁切圖片
根據上面文章的程式碼,是先把一幀的資料轉為圖片,然後旋轉90°,然後根據掃描框在介面上的位置,裁切出需要的區域,如下
ByteArrayOutputStream stream = new ByteArrayOutputStream();
//將幀資料轉為圖片
image.compressToJpeg(new Rect(0, 0, size.width, size.height), 80, stream);
Bitmap bmp = BitmapFactory.decodeByteArray(stream.toByteArray(), 0, stream.size());
//這裡返回的照片預設橫向的,先將圖片旋轉90度
bmp = rotateToDegrees(bmp, 90);
//然後裁切出需要的區域,具體區域要和UI佈局中配合,這裡取圖片正中間,寬度取圖片的一半,高度這裡用的適配資料,可以自定義
bmp = bitmapCrop(bmp, bmp.getWidth() / 4, bmp.getHeight() / 2 - (int) getResources().getDimension(R.dimen.x25), bmp.getWidth() / 2, (int) getResources().getDimension(R.dimen.x50));那麼問題就在裁切和旋轉的時候了,假如相機一幀的畫素是1920*1080,而我需要的只是掃描框內的一點內容,把一整張圖片都提取出來,加上旋轉這張大圖片,然後再裁切,無疑浪費了很多時間
解決辦法:
直接計算逆向90°情況下的提取區域
上邊裁切範圍是:螢幕正中間、寬度為螢幕的一半、高度為R.dimen.x50 的一個矩形
那麼矩形的位置就取圖片正中間
left=bmp.getWidth() / 4
top=bmp.getHeight()/ 2 - R.dimen.x25
width=bmp.getWidth() / 2
height= R.dimen.x50如果逆向90°,長寬倒轉,矩形的位置就變成
left=bmp.getWidth()/ 2 - R.dimen.x25 (原來的top)
top=bmp.getHeight()/4 (原來的right)
width=R.dimen.x50 (原來的height)
height= bmp.getHeight()/2 (原來的width)ByteArrayOutputStream stream = new ByteArrayOutputStream();
image.compressToJpeg(new Rect(left , top, left+width, top+height), 80,
stream);
Bitmap bmp = BitmapFactory.decodeByteArray(stream.toByteArray(), 0, stream.size());
這樣直接提取需要的區域,就節省了整張圖片旋轉和第二次裁切的時間
2、旋轉、二值化 圖片,過濾無用內容
接下來的旋轉和二值化,是純畫素演算法,如果能放在jni中實現更好,經過我測試效率會快好幾倍(Java大概10-50ms,Jni基本在10ms以下,雖然幾十毫秒的時間差,跟tess-two的解析時間比,效果不明顯),這裡還是用Java來表現邏輯
上面已經直接提取出了需要解析的矩形區域,接下來只需要旋轉一張畫素小了很多倍的圖片 還是上面文章中的方法
rotateToDegrees(bmp, 90)旋轉之後,就是一張方向正確的識別區域了,現在需要做的就是二值化,將圖片變為黑白兩色,提高識別率(因為要遍歷所有的畫素,為了節省時間,在二值化的同時,同步進行無用內容過濾)
無用內容過濾:
如文章開頭介紹,在相機開啟之後,每一秒都有幾十幀資料,什麼時候解析呢?這裡我做出了一些過濾(下面的過濾演算法,只適用於和我的需求類似的場景(掃描手機號、單行文字))
怎麼過濾呢?先來想想場景,什麼樣的圖片可以認為圖中可能有手機號呢?
第一:手機號完整的在矩形區域內,不會有超出矩形區域的部分,也就是說手機號部分不會有貼邊的畫素
第二:如果要掃描手機號,肯定會將手機號至少填充掃描框的50%高度(這個比例自己掌握,看你的掃描距離,我後來減到了10%,捕捉手機號依然很準確)
有了這兩個條件,就有了判斷標準,圖片中必須有 上下左右沒有貼邊,且高度大於50%的有色區域,才能初步判斷圖中可能存在手機號碼然後我就實現方式,我的思路是:
這裡實現一個單行文字捕捉,首先準備 left、top、right、bottom 四個變數,就是最終需要的單行文字區域1、先黑白化圖片,這個過程需要遍歷畫素,在遍歷期間,同時來做過濾,這裡遍歷是一行一行的,所以在第一次遍歷中,能判斷文字行數:比如在遍歷某一行的畫素時,只要發現一個黑色畫素,說明這一行不是空行,那就記錄一下這裡已經有文字佔了一行畫素,下一行如果還是找到黑色畫素,那就把當前記錄的文字加一行畫素高度,直到某一行全部是白色畫素,說明這一行文字結束了,下面再有黑色畫素就算是第二行文字了
2、如果第一行畫素就發現了黑色畫素點,說明這行文字是貼著文字上邊緣的,八成是隻露出了一半的文字,肯定不是解析物件,那就不用記錄他,直到遇到一行全是白色畫素,表示這行貼邊的文字結束了,接下來的文字就要開始記錄了(沒錯,如果有一條豎著的黑線,從上貫穿到下,那這個圖片肯定被認為全是貼邊文字,直接過濾掉,我的識別環境不會有這個情況,所以沒有做更細緻的過濾,需要判斷這種情況的,自己寫演算法 -_-)
3、每一行文字記錄結束都跟上一行文字比較,選高度更高的一行文字留下,其他的跳過(前面說了這裡是單行識別,只選沒有貼邊的文字最高的一行),等遍歷結束,最高的一行的top 和 bottom留下,就得到的解析物件的上下邊緣
4、需要留意的是,上一個過濾貼邊文字的條件,只過濾了超出上邊緣的文字,那超出下邊緣的文字呢?很簡單,每行文字記錄完成後才會和上一行比較,就是說每次遇到一整行白色畫素的空白行時,才會更新top和bottom,如果最後一行貼邊了那就不會再遇到空白行,自動就放棄了
下面在程式碼中解釋細節
/**
* 轉為二值影象 並判斷影象中是否可能有手機號
*
* @param bmp 原圖bitmap
* @param tmp 二值化閾值 超出閾值的畫素置為白色,否則為黑色
* @return
*/
public Bitmap convertToBMW(final Bitmap bmp, int tmp) {
int width = bmp.getWidth(); // 獲取點陣圖的寬
int height = bmp.getHeight(); // 獲取點陣圖的高
int[] pixels = new int[width * height]; // 通過點陣圖的大小建立畫素點陣列
bmp.getPixels(pixels, 0, width, 0, 0, width, height);//得到圖片的所有畫素
int lineHeight = 0;//當前記錄的一行文字已經累計的高度,每次遇到一行有黑色畫素點時 +1
//目標行,每遇到一個黑色畫素,就會+1,本行就不會在記錄lineHeight,下一行在遇到黑色畫素,就繼續+1,保證每行lineHeight最多 +1 一次
int row = 0;
//當前記錄的一行文字是否超出邊緣(如果第一行就發現黑色畫素,就為true了,直到遇到空白行,還原false)
boolean isOutOfRect= false;
//最終捕捉到的單行文字在圖片中的矩形區域
int left = 0;
int top = 0;
int right = 0;
int bottom = 0;
int alpha = 0xFF << 24;
for (int i = 0; i < height; i++) {
for (int j = 0; j < width; j++) {
int grey = pixels[width * i + j];
// 分離三原色
alpha = ((grey & 0xFF000000) >> 24);
int red = ((grey & 0x00FF0000) >> 16);
int green = ((grey & 0x0000FF00) >> 8);
int blue = (grey & 0x000000FF);
if (red > tmp) {
red = 255;
} else {
red = 0;
}
if (blue > tmp) {
blue = 255;
} else {
blue = 0;
}
if (green > tmp) {
green = 255;
} else {
green = 0;
}
pixels[width * i + j] = alpha << 24 | red << 16 | green << 8
| blue;
//這裡是二值化化的判斷,if裡是白色,else裡是黑色
if (pixels[width * i + j] == -1 || (i == height - 1 && j == width - 1)) {
//將當前畫素賦值為白色
pixels[width * i + j] = -1;
/**
lineHeight>0 : 如果當前記錄行的文字高度大於0
row == i : 當前是不是目標行,每行第一次發現黑色畫素就會+1,所以只有當前行還沒出現黑色畫素時,才會 == i
j == width - 1 : 當前畫素是不是本行的最後一個畫素點
綜上所述,這裡的判斷條件為 : 已經捕捉到一行文字,而且這一行已經結束了還沒發現黑色畫素,這行文字該結束了
*/
if (lineHeight > 0 && row == i && j == width - 1) {
//這行文字是不是超出邊緣的文字,如果是,直接跳過,開始記錄下一行
if (!isOutOfBorder) {
//跟上一行的文字高度比較,記錄下高度更高的一行文字的top 和 bottom
int h = bottom - top;
if (lineHeight > h) {
//這裡我把top 和 bottom 都加了1/4的行高,為了有一點留白,其實加不加無所謂
top = i - lineHeight - (lineHeight / 4);
bottom = i - 1 + (lineHeight / 4);
}
}
//這行文字既然已經結束了,下一行文字肯定不是超出邊緣的了
isOutOfRect= false;
//上一行文字已經處理完成,行高歸0,開始記錄下一行
lineHeight = 0;
}
} else {
//這裡是黑色畫素,將當前畫素點賦值為黑色
pixels[width * i + j] = -16777216;
//如果當前行 = 目標行(遇到這行第一個黑色畫素就會+1,到下一行才會相等)
if (i >= row) {
//如果當前的黑色畫素 位於第一行畫素 或 最後一行畫素,那就是超出邊緣的文字
if (i == 0 || i == height - 1)
isOutOfRect= true;
//行高+1
lineHeight++;
//目標行轉移到下一行
row = i + 1;
}
}
}
}
/** 如果通過第一次過濾後,沒有找到一行有意義的文字,或者找到了,文字高度佔比還不到解析圖片的20%,
那這張圖片八成是無意義的圖片,不用解析,直接下一幀(當你對著牆或者什麼無聊的東西掃描的時候,
這裡就會直接結束,不會浪費時間去做文字識別)
*/
if (bottom - top < height * 0.2f) {
isScanning = false;
return null;
}
/**
到這裡,上面的篩選已經通過了,我們已經定位到了一行目標文字的 top 和 bottom
接下來就要定位left 和 right 了
還是需要遍歷一次,不過只需要 top-bottom 正中間的一行畫素,思路同上,通過文字間距
來將這一行文字分成橫向的幾個文字塊,至於區分條件,就看文字間的間隔,超過正常寬度就
算是一個文字塊的結束,至於正常的文字間隔就要按需求而定了,比如這裡掃描手機號,手機
號是11位的,那兩個數字之間的距離說破天也不會超過圖片寬度的 1/11,那我就定為1/11
那問題又來了,如果剛好手機號在這塊影象右邊的上半部分,下半部分是在手機號左邊的無用文字,
只是因為高度重疊,上面取行高時被當成了一行,那這裡只取top-bottom正中間的一條畫素,
遍歷到手機號所在的右邊一半時,不是隻能找到空白畫素?
這就沒辦法了,只取一條畫素行,一是為了減少耗時,二是讓我的腦細胞少死一點,你要掃描手機號,
還非要把手機號完美躲開正中間,那我就不管了.....
*/
//文字間隔,每次遇到白色畫素點+1,每次遇到黑色畫素點歸0,當space > 寬度的1/11時,就算超過正常文字間距了
int space = 0;
//當前文字塊寬度,每當遇黑色畫素點時,更新寬度,space 超過寬度的1/11時,歸0,文字塊結束
int textWidth = 0;
//當前文字開始X座標,文字塊寬度 = 結束點 - startX
int startX = 0;
//遍歷top-bottom 正中間一行畫素
for (int j = 0; j < width; j++) {
//如果是白色畫素
if (pixels[width * (top + (bottom - top) / 2) + j] == -1) {
/**
如果已經捕捉到了文字塊,而且space > width / 11 或者已經遍歷結束了,
那這個文字塊的寬度就取到了
*/
if (textWidth > 0 && (space > width / 11 || j == width - 1)) {
//同高度一樣,比較上一個文字塊的寬度,留下最大的一個 top 和 bottom
if (textWidth > right - left) {
//這裡取left 和 right 一樣加了一個space/2的留白
left = j - space - textWidth - (space / 2);
right = j - 1;
}
//既然當前文字塊已經結束,就把引數重置,繼續捕捉下一個文字塊
space = 0;
startX = 0;
}
space++;
} else {
//這裡是黑色畫素
//記錄文字塊的開始X座標
if (startX == 0)
startX = j;
//文字塊當前寬度
textWidth = j - startX;
//文字間隔歸0
space = 0;
}
}
//如果最終捕捉到的文字塊,寬度還不到圖片寬度的30%,同樣跳過,八成不是手機號,就不要浪費時間識別了
if (right - left < width * 0.3f) {
isScanning = false;
return null;
}
/**
到這裡 已經捕捉到了一個很可能是手機號碼的文字塊,區域就是 left、top、right、bottom
把這個區域的畫素,取出來放到一個新的畫素陣列
*/
int targetWidth = right - left;
int targetHeight = bottom - top;
int[] targetPixels = new int[targetWidth * targetHeight];
int index = 0;
for (int i = top; i < bottom; i++) {
for (int j = left; j < right; j++) {
if (index < targetPixels.length)
targetPixels[index] = pixels[width * i + j];
index++;
}
}
//銷燬之前的圖片
bmp.recycle();
// 新建圖片
final Bitmap newBmp = Bitmap.createBitmap(targetWidth, targetHeight, Bitmap.Config.ARGB_8888);
//把捕捉到的圖塊,寫進新的bitmap中
newBmp.setPixels(targetPixels, 0, targetWidth, 0, 0, targetWidth, targetHeight);
//將裁切的圖片顯示出來(測試用,需要為CameraView setTag(ImageView))
//主執行緒 {
// @Override
// public void run() {
// ImageView imageView = (ImageView) getTag();
// imageView.setVisibility(View.VISIBLE);
// imageView.setImageBitmap(newBmp);
// }
//};
//這裡可以把這塊影象儲存到本地,可以做個按鈕,點選時把saveBmp=true,就可以採集一張,採集幾張之後,拿去做tesseract 訓練,訓練出適合自己需求的字型檔,才是提高效率的關鍵
// if (saveBmp) {
// saveBmp = false;
// ImageUtils.saveBitmap(scanBmp, System.currentTimeMillis() + ".jpg");
// }
//返回需要交給tess-two識別的內容
return newBmp;
}
更新
圖1:捕捉到有 11 位字元的文字塊,取到文字塊的精準位置,交給tess-two解析
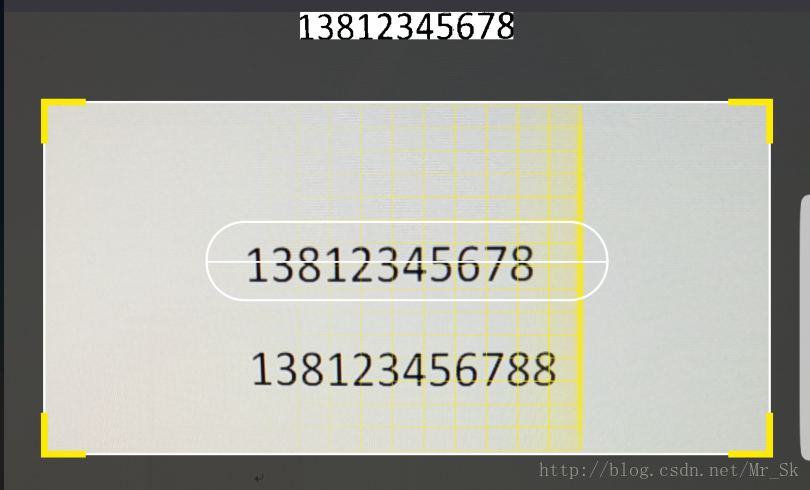
圖2:捕捉到有 12 位字元的文字塊,不符合手機號碼特徵,則不進行位置獲取和內容識別,直接跳過
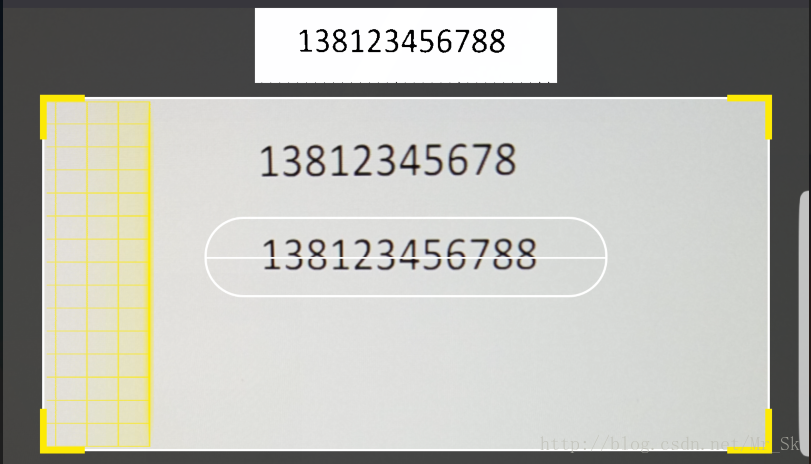
之前的演算法還有一些缺陷,會有少數不符合手機號特徵的文字塊也被捕捉到了,我又換了一種演算法,可以捕捉到文字塊的精準位置,和包含多少個字元(字元數量不符合特徵就也可以過濾掉,如上圖2),且有一定的抗干擾能力(效果一般,主要解決我遇到的水印問題)
這裡先封裝一個工具類,直接呼叫catchPhoneRect(bitmp,imageView)方法,即可獲取一個只包含手機號的精準bitmap,如果返回null,表示沒有發現符合手機號特徵的文字塊(這裡捕獲時,是先取圖片中間一行的畫素來初步判斷手機號位置,所以UI上需要一條中間線類輔助掃描,如上圖1)
我遇到的水印問題:有些面單上的手機號,會被一種免單編號的水印遮住底邊,手機號還是能看清楚,但是少數數字的底部被水印連在了一起,導致tesseract 無法識別
這裡解決辦法就是:通過遞迴演算法,獲取每一個字元的精準位置,在獲取位置的過程中,如果發現寬度或高度延伸到了不合理的範圍,即視為被水印干擾的字元,先跳過這個字元,繼續捕捉下一個,直到捕捉到一個沒有發現干擾的字元,就可以確定這個文字塊中每個字元的正確寬高,這時從頭再遍歷一次,根據正確的寬高範圍來清除水印部分畫素
public class TesseractUtil {
private static TesseractUtil mTesseractUtil = null;
private float proportion = 0.5f;
private TesseractUtil() {
}
public static TesseractUtil getInstance() {
if (mTesseractUtil == null)
<