
從零開始使用tensorflow(2)——詞向量
前面記錄了安裝過程,現在開始使用詞向量。
一.對tf的膚淺認識
首先是tf的基本總結(時間有限,認識比較膚淺):
(1). 使用圖來表示計算;
(2). 在session中執行圖;
(3). 使用tensor來表示資料;
(4). Variable維護狀態
(5). 使用feed和fetch可以為任意的操作賦值和獲取資料。
看起來是不是蠻簡單的,但其實用起來不容易(可能本人道行太低)。
1. 跑tf的過程:
(1). 構建圖
構圖過程就是自己建立網路的過程。主要構建op和op之間的傳遞,op之間通過tensor實現資料傳輸。Op右構造器構造(tf.constent、tf.Variable、tf.matmul等),構造器的輸入是op的輸入。
庫裡有一個預設的圖,一般是在預設圖中新增op。
(2). 執行圖
構造完成後,可以啟動圖,首先建立一個session,建立是無引數傳入,則表示啟動預設圖。
通過session.run()來執行圖,可以新增引數,引數為op,執行完後返回op的執行後的結果。
(3). 儲存圖
在訓練建立圖時,可以定義saver=tf.train.saver(),如果沒有加引數,則會預設把所有變數全部儲存,此時,儲存的是圖中的變數。
在執行完圖後,做saver.save(session,save_path,…)即可把整個模型儲存下來。
(4). 恢復模型
訓練並儲存一次模型後,模型可重複恢復,使用。在恢復模型前,也要先建圖,在圖中部署使用模型做計算的op和計算過程,此時定義的op需要與訓練時定義的op對應(可以不完全複製,但此時要用的op要包含在訓練op中),然後任然定義saver=tf.train.saver(),儲存變數。
然後用saver.restore(session,save_path,…)載入模型,接下來,可以用session.run()執行圖。
二.詞向量
之前已經理過一次word2vec的演算法了,單獨的word2vec和tf均採用的mikolov大神的wordembedding演算法,所以,這裡只是操作,不做演算法分析。
Tf中包含的word2vec例子一共3個,word2vec_basic.py(examples/tutorial/word2vec)、word2vec_optimized.py、word2vec.py(models/embedding),
word2vec_basic.py比較簡單,下載text8然後選擇詞頻較高的5個詞訓練和測試,用distance來測試。完成後不儲存模型,用t分佈將詞的分佈用matplot顯示出來。
word2vec_optimized.py和word2vec.py的過程幾乎是一樣的,只是後者要做summary,會儲存日誌,可以通過tensorboard來視覺化,兩者都要儲存模型。
用word2vec_optimized.py和word2vec.py來訓練中文語料,epoch選擇15次效果就很好了。(效果如下)
葫蘆娃
=====================================
葫蘆娃 1.0000
葫蘆兄弟 0.5317
小葫蘆 0.4907
金剛葫蘆娃 0.4874
狩獵季節 0.4858
黑貓警長 0.4719
哪吒鬧海 0.4711
奧創紀元 0.4701
戰象 0.4530
美少女戰士 0.4506
葫蘆小金剛 0.4506
童年 0.4491
虹貓藍兔七俠傳 0.4428
沙人 0.4428
]] 0.4372
西遊記 0.4351
變種時代 0.4334
新女婿時代 0.4330
電影版 0.4323
法櫃奇兵 0.4302
之前使用word2vec時,一直只全域性迭代(epoch)5次,在tf中迭代15次,效果明顯比5次好很多。說明,裡面那些預設引數也是需要調一調的。
用tensorboard視覺化如下:
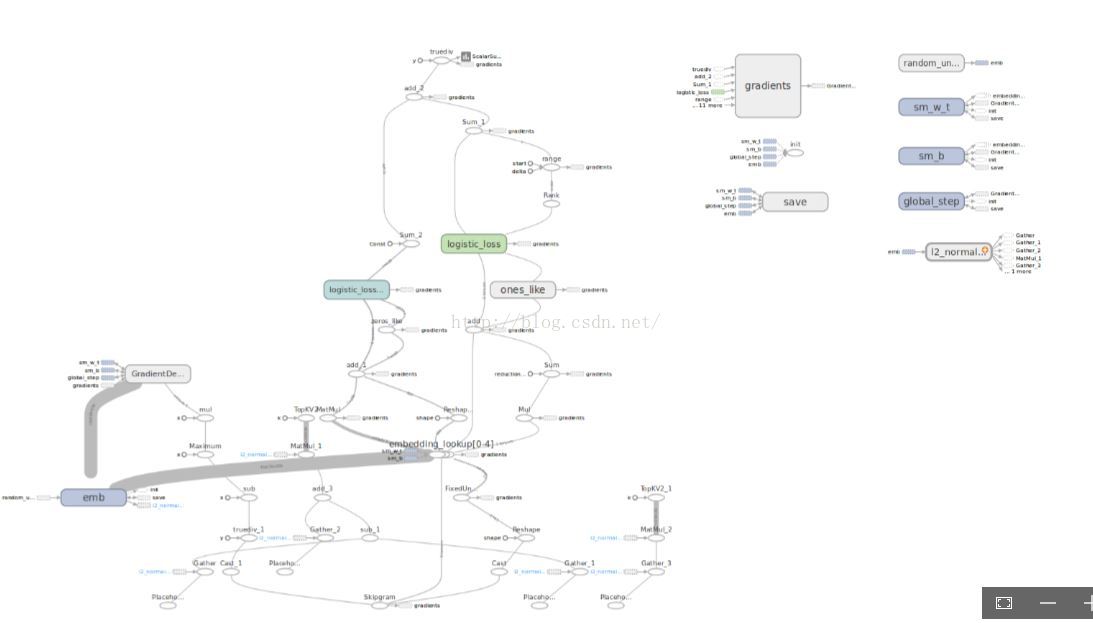
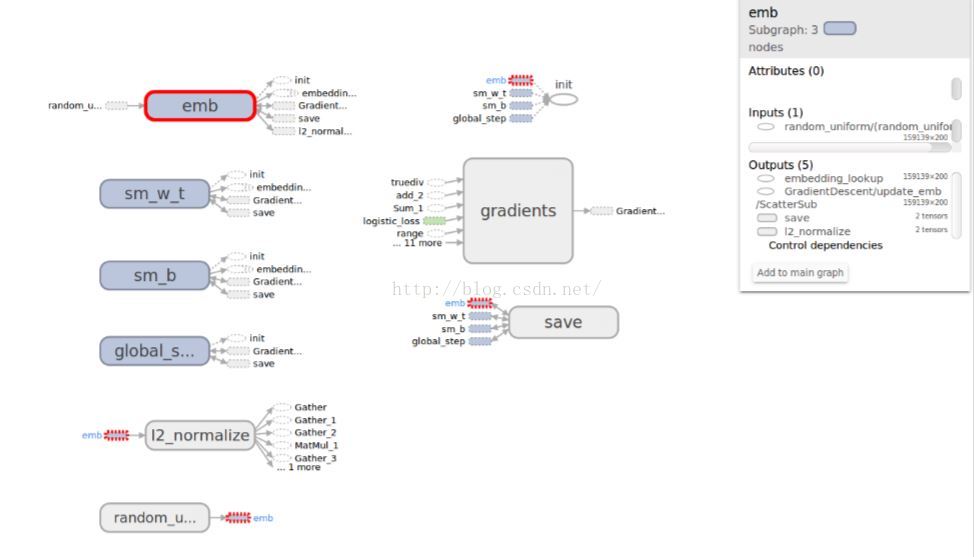
其中,emb、swm_w_t、sm_b、gloab_step建圖時新增的。可以對比程式和圖看看。圖中,每個op的輸入、輸出、涉及到的網路都可以點選檢視細節,這點真的很好。
三.此次使用遇到的問題總結
(1). 對tensor和op的混淆。
在c系程式設計中,很容易把資料傳輸跟變數、指標等有實際名字的東西結合起來,因此,不自覺的把op當成tensor來呼叫。
從圖中取tensor的時候,名字實際上是<op>:<out_idx>,前面是op的名字,後面是第幾路輸出。液就是說tensor實際上是op的某一路輸出或者輸入,tensor就是一股資料。
(2). 被placeholder坑了。以為佔位符也相當於是變數,所以在建圖的時候把某些op定義成佔位符,結果在save的時候,placeholder根本不被儲存,導致在載入模型時,用placeholder定義的假op是不存在的。
(都是很二的錯誤啊!)
四.Caffe和tf的不成熟對比
之前用過caffe,所以,這裡就caffe和tf的使用(僅僅只敢評價使用)做個比較。
(1). Caffe開源更早,早期使用的人多一些,可找到的使用心得也多一些,像薛開宇的“caffe學習筆記”、知名博主卜居的書“21天實戰caffe”,寫得都很好。可以讓我等小菜很順利的跑很多例子。而tf除了中文的官方文件,其他中文資料較少。本人在幾天的使用過程中就遇到諸多問題,而無法查詢。
(2). Caffe使用prototxt就可以設定網路引數,並建立網路;而tf是用python先建立圖,然後執行的,對python和指令碼務必陌生的我,也覺得有點頭大。
(3). Caffe在執行時,日誌輸出比tf清晰一些,但是tf有視覺化工具,tensorBoard,這個如果想掌握細節,tfboard真的很詳細清晰。
(4). Tf雖然操作不那麼友好,但是,在操作過程中真的能學到很多東西。
相關推薦
從零開始使用tensorflow(2)——詞向量
前面記錄了安裝過程,現在開始使用詞向量。 一.對tf的膚淺認識 首先是tf的基本總結(時間有限,認識比較膚淺): (1). 使用圖來表示計算; (2). 在session中執行圖; (3). 使用tensor來表示資料; (4). Variable維護狀態 (5). 使用
JAVA從零開始學習(2)
一、JAVA基本資料型別 JAVA的兩大資料型別 內建資料型別 引用資料型別 內建資料型別 Java語言提供了八種基本型別。六種數字型別(四個整數型,兩個浮點型),一個字元型別,還有一種布林型。 byte:(類比char) byte資料型別是8位,有符號的,以二進
從零開始VUE(一)運行Vue項目
cnpm htm sta cnp 進入 org 成功 div 設置 1、安裝nodejs,可以去官網下載,安裝完成後在命令行輸入node -v或npm -v,若正確顯示版本,表示安裝成功。 2、設置國內鏡像(老外的網站有點慢) npm install -g cnpm --
資料結構與演算法——從零開始學習(三)棧和佇列
系列文章 第一章:基礎知識 第二章:線性表 第三章:棧和佇列 第一節:棧(Stack) 是限制在表一端進行插入和刪除操作的線性表。允許進行插入、刪除操作的這一端稱為棧頂(Top),另一個固定端稱為棧底。例如棧中有三個元素,近棧的順序是a1、a2、a3,當
Photon Server遊戲伺服器從零開始學習(一)部署第一個伺服器程式
概述 Photon引擎是一款實時的Socket伺服器和開發框架,快速、使用方便、容易擴充套件。 服務端架構在windows系統平臺上,採用C#語言編寫。 客戶端SDK提供了多種平臺的開發API,包括DotNet、Unity3D、C/C++以及ObjC等。
Unity_2D遊戲例項從零講起(2)——手遊開場動畫的實現
一個酷炫的開場動畫多多少少可以讓遊戲高大上起來(對於外行來說…)不管怎麼說,我們發現基本上任何一款遊戲都有自己獨特的開場動畫用來顯示自己的品牌logo。所以 接著我們上次教程,開始和大家分享如何製作出手遊的開場動畫。主要有以下內容: a.安卓Apk檔案的釋出生成 b.如何在
Photon Server遊戲伺服器從零開始學習(六)遊戲登入與註冊操作
為了在客戶端與伺服器端使用共同的code,建立共有引用Common: public enum OperationCode:byte //區分請求和響應的型別 { Default,//預設請求 Login, //登入 Register
flutter之從零開始搭建(三)之 網路請求
專案還是在原來的基礎上搭建,具體的可以看上面的連線 這次,我們來介紹下網路請求,並且將請求到的資料設定到ListView列表中。老規矩,先來看下效果圖 頁面看起來不錯吧,在動手之前還是得說一下,首頁資料來自wanandroid提供,畢竟用了別人的
【工作筆記】ElasticSearch從零開始學(二)—— 入門(搜尋)
建立一個員工目錄 假設我們剛好在Megacorp工作,這時人力資源部門出於某種目的需要讓我們建立一個員工目錄,這個目錄用於促進人文關懷和用於實時協同工作,所以它有以下不同的需求 資料能夠包含多個值的標籤、數字和純文字。 檢索任何員工的所有資訊。 支援結構化
python從零開始學習(三)--os模組
學習python的話,os模式必須是第一個學習的模組,我學習python主要是用途是寫一些小的指令碼,所以對語法上面的要求不是很高。有些基礎就好了,注重實用性。基礎庫的學習是實用python的第一個目標。 Python os模組包含普遍的作業系統功能。如果你希望你的程式能夠與平臺無關的話,這個模組是尤為重要的
【工作筆記】ElasticSearch從零開始學(六)—— JavaAPI_Aggregation
StructAggregation SearchResponse sr = client.prepareSearch() .addAggregation(
對於python的從零開始學習(自定義函式)
基於py3相信自己,每天多學一點。#這塊我認為是整個學習中比較重要得一塊,能不能靈活的程式設計,滿足需求,很關鍵。#lambda函式#又名匿名函式,是一種精簡的小函式#可以直接非常方便的巢狀在任何地方#需要注意,parameters形參可以是多個,用英文逗號隔開就好#引數與函
從零開始搭建系統2.7——Quartz安裝及配置
get AR blank 安裝 pos html uart body cnblogs 從零開始搭建系統2.7——Quartz安裝及配置從零開始搭建系統2.7——Quartz安裝及配置
從零開始搭建系統2.3——Cat安裝及配置
AR lan tar gpo 從零開始 系統 .com .html log 從零開始搭建系統2.3——Cat安裝及配置從零開始搭建系統2.3——Cat安裝及配置
從零開始搭建系統2.5——Apollo安裝及配置
logs OS get html .cn apol blog class AR 從零開始搭建系統2.5——Apollo安裝及配置從零開始搭建系統2.5——Apollo安裝及配置
從零開始搭建系統2.4——Jenkins安裝及配置
AR gpo blank .cn 安裝 jenkin cnblogs 搭建 pro 從零開始搭建系統2.4——Jenkins安裝及配置從零開始搭建系統2.4——Jenkins安裝及配置
從零開始搭建系統2.1——Nexus安裝及配置
安裝 nexus pos HR class .html ref 系統 href 從零開始搭建系統2.1——Nexus安裝及配置從零開始搭建系統2.1——Nexus安裝及配置
C語言從初識到認識(2)
C語言程式的注意事項 函式總是從main()函式開始執行的 程式中要求計算機的操作是由函式中的c語句完成的 每個資料宣告語句的最後必須有一個分號 C語言本身不提供輸入輸出語句 程式應當包括註釋 接下來就是逐條分析 1、在預處理指令中主要需要注
Git 命令總結,從零到熟悉(全)
什麼是 Git? Git 是一個免費的開源分散式版本控制系統,它的設計目的是為了速度和效率的處理從小型到大型的專案;Git 可以幫我們管理我們的程式碼,記錄歷史,只要程式碼提交到 Git 上就永久不會丟失,可以隨時 “穿越”(回到之前的某一個版本);可以多端共享,團隊協作中,多個人操作
Tensorflow(2)儲存模型與恢復
###一、資料模型的儲存 使用saver類,自動儲存tensorflow的圖結構(***.ckpt.meta),引數取值(***.ckpt.data),以及目錄下的檔案列表(***.ckpt.index),還有一個checkpoint檔案。 定義變數 變數操作 變數初