
高併發資料結構Disruptor解析(6)
SequenceBarrier
SequenceBarrier是消費者與Ringbuffer之間建立消費關係的橋樑,同時也是消費者與消費者之間消費依賴的抽象。

SequenceBarrier只有一個實現類,就是ProcessingSequenceBarrier。ProcessingSequenceBarrier由生產者Sequencer,消費定位cursorSequence,等待策略waitStrategy還有一組依賴sequence:dependentSequence組成:
public ProcessingSequenceBarrier(
final Sequencer sequencer,
final 首先,為了實現消費依賴,SequenceBarrier肯定有一個獲取可以消費的sequence方法,就是
long waitFor(long sequence) throws AlertException, InterruptedException, TimeoutException;實現為:
@Override
public long waitFor(final long sequence)
throws 其他方法實現很簡單,功能上分別有:
1. 獲取當前cursorSequence(並沒有什麼用,就是為了監控)
2. 負責中斷和恢復的alert標記
@Override
public long getCursor()
{
return dependentSequence.get();
}
@Override
public boolean isAlerted()
{
return alerted;
}
@Override
public void alert()
{
alerted = true;
waitStrategy.signalAllWhenBlocking();
}
@Override
public void clearAlert()
{
alerted = false;
}
@Override
public void checkAlert() throws AlertException
{
if (alerted)
{
throw AlertException.INSTANCE;
}
}構造SequenceBarrier在框架中只有一個入口,就是AbstractSequencer的:
public SequenceBarrier newBarrier(Sequence... sequencesToTrack)
{
return new ProcessingSequenceBarrier(this, waitStrategy, cursor, sequencesToTrack);
}SequenceProcessor
通過SequenceBarrier,我們可以實現消費之間的依賴關係,但是,消費方式(比如廣播,群組消費等等),需要通過SequenceProcessor的實現類實現:
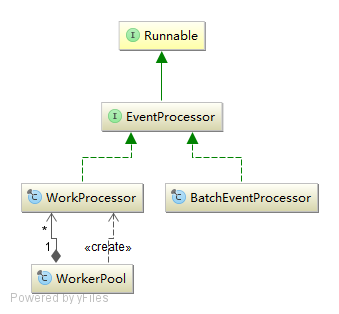
通過類依賴關係我們發現,EventProcessor都是拓展了Runnable介面,也就是我們可以把它們當做執行緒處理。
1. BatchEventProcessor:
它的構造方法:
/**
* 構造一個消費者之間非互斥消費的消費者
*
* @param dataProvider 對應的RingBuffer
* @param sequenceBarrier 依賴關係,通過構造不同的sequenceBarrier用互相的dependentsequence,我們可以構造出先後消費關係
* @param eventHandler 使用者實現的處理消費的event的業務消費者.
*/
public BatchEventProcessor(
final DataProvider<T> dataProvider,
final SequenceBarrier sequenceBarrier,
final EventHandler<? super T> eventHandler)
{
this.dataProvider = dataProvider;
this.sequenceBarrier = sequenceBarrier;
this.eventHandler = eventHandler;
if (eventHandler instanceof SequenceReportingEventHandler)
{
((SequenceReportingEventHandler<?>) eventHandler).setSequenceCallback(sequence);
}
timeoutHandler = (eventHandler instanceof TimeoutHandler) ? (TimeoutHandler) eventHandler : null;
}執行緒為一個死迴圈:
@Override
public void run()
{
//檢查狀態
if (!running.compareAndSet(false, true))
{
throw new IllegalStateException("Thread is already running");
}
//清理
sequenceBarrier.clearAlert();
//如果使用者實現的EventHandler繼承了LifecycleAware,則執行其onStart方法
notifyStart();
T event = null;
//sequence初始值為-1,設計上當前值是已經消費過的
long nextSequence = sequence.get() + 1L;
try
{
while (true)
{
try
{
//獲取當前可以消費的最大sequence
final long availableSequence = sequenceBarrier.waitFor(nextSequence);
while (nextSequence <= availableSequence)
{
//獲取並處理
event = dataProvider.get(nextSequence);
eventHandler.onEvent(event, nextSequence, nextSequence == availableSequence);
nextSequence++;
}
//設定當前sequence,注意,出現異常需要特殊處理,防止重複消費
sequence.set(availableSequence);
}
catch (final TimeoutException e)
{
//wait超時異常
notifyTimeout(sequence.get());
}
catch (final AlertException ex)
{
//中斷異常
if (!running.get())
{
break;
}
}
catch (final Throwable ex)
{
exceptionHandler.handleEventException(ex, nextSequence, event);
//如果出現異常則設定為nextSequence
sequence.set(nextSequence);
nextSequence++;
}
}
}
finally
{
//如果使用者實現的EventHandler繼承了LifecycleAware,則執行其onShutdown方法
notifyShutdown();
running.set(false);
}
}可以看出:
1. BatchEventProcessor可以處理超時,可以處理中斷,可以通過使用者實現的異常處理類處理異常,同時,發生異常之後再次啟動,不會漏消費,也不會重複消費。
2. 不同的BatchEventProcessor之間通過SequenceBarrier進行依賴消費。原理如下圖所示:
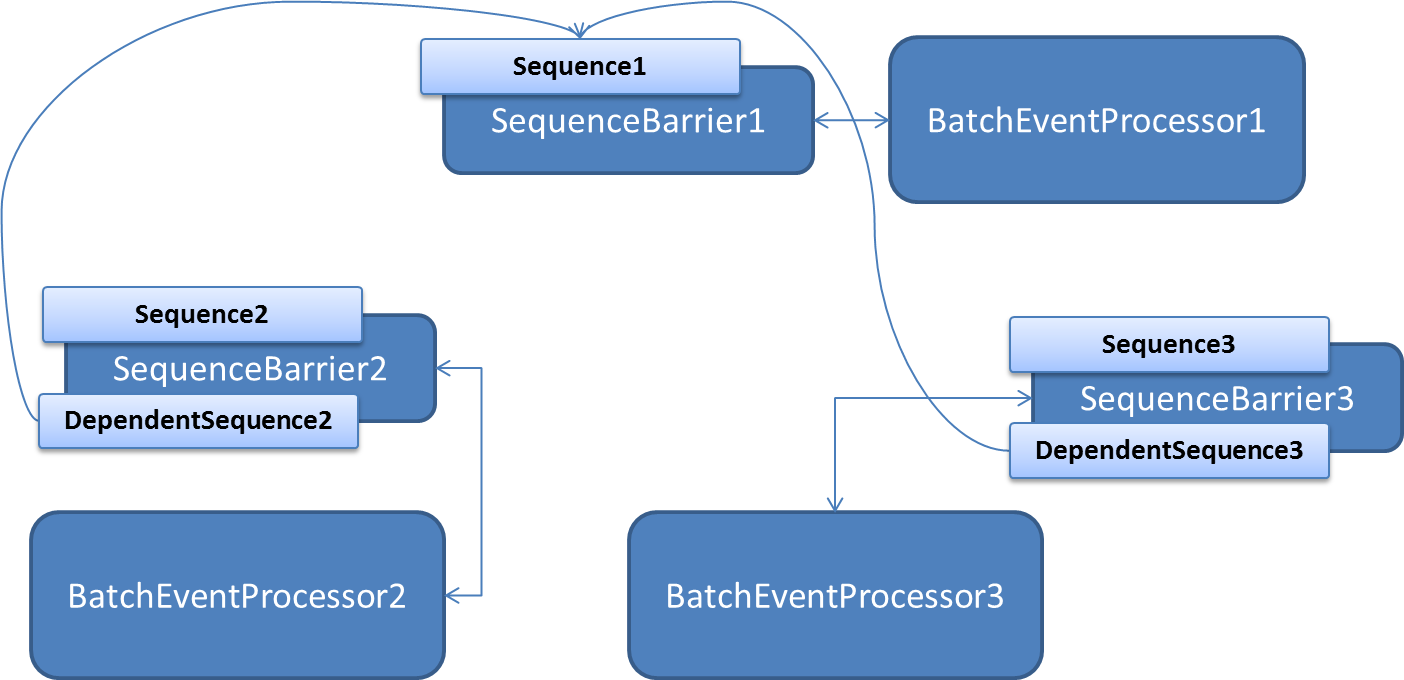
假設我們有三個消費者BatchEventProcessor1,BatchEventProcessor2,BatchEventProcessor3. 1需要先於2和3消費,那麼構建BatchEventProcessor和SequenceBarrier時,我們需要讓BatchEventProcessor2和BatchEventProcessor3的SequenceBarrier的dependentSequence中加入SequenceBarrier1的sequence。
其實這裡2和3共用一個SequenceBarrier就行。
2. WorkProcessor
另一種消費者是WorkProcessor。利用它,可以實現互斥消費,同樣的利用SequenceBarrier可以實現消費順序
public void run()
{
if (!running.compareAndSet(false, true))
{
throw new IllegalStateException("Thread is already running");
}
sequenceBarrier.clearAlert();
notifyStart();
boolean processedSequence = true;
long cachedAvailableSequence = Long.MIN_VALUE;
long nextSequence = sequence.get();
T event = null;
while (true)
{
try
{
if (processedSequence)
{
processedSequence = false;
//獲取下一個可以消費的Sequence
do
{
nextSequence = workSequence.get() + 1L;
sequence.set(nextSequence - 1L);
}
//多個WorkProcessor之間,如果共享一個workSequence,那麼,可以實現互斥消費,因為只有一個執行緒可以CAS更新成功
while (!workSequence.compareAndSet(nextSequence - 1L, nextSequence));
}
if (cachedAvailableSequence >= nextSequence)
{
event = ringBuffer.get(nextSequence);
workHandler.onEvent(event);
processedSequence = true;
}
else
{
cachedAvailableSequence = sequenceBarrier.waitFor(nextSequence);
}
}
catch (final TimeoutException e)
{
notifyTimeout(sequence.get());
}
catch (final AlertException ex)
{
if (!running.get())
{
break;
}
}
catch (final Throwable ex)
{
// handle, mark as processed, unless the exception handler threw an exception
exceptionHandler.handleEventException(ex, nextSequence, event);
processedSequence = true;
}
}
notifyShutdown();
running.set(false);
}3. WorkerPool
多個WorkerProcessor可以組成一個WorkerPool:
public WorkerPool(
final RingBuffer<T> ringBuffer,
final SequenceBarrier sequenceBarrier,
final ExceptionHandler<? super T> exceptionHandler,
final WorkHandler<? super T>... workHandlers)
{
this.ringBuffer = ringBuffer;
final int numWorkers = workHandlers.length;
workProcessors = new WorkProcessor[numWorkers];
for (int i = 0; i < numWorkers; i++)
{
workProcessors[i] = new WorkProcessor<T>(
ringBuffer,
sequenceBarrier,
workHandlers[i],
exceptionHandler,
workSequence);
}
}裡面的 workHandlers[i]共享同一個workSequence,所以,同一個WorkerPool內,是互斥消費。
相關推薦
高併發資料結構Disruptor解析(6)
SequenceBarrier SequenceBarrier是消費者與Ringbuffer之間建立消費關係的橋樑,同時也是消費者與消費者之間消費依賴的抽象。 SequenceBarrier只有一個實現類,就是ProcessingSequenceBarr
高併發資料結構Disruptor解析(2)
Sequence(續) 之前說了Sequence通過給他的核心值value新增前置無用的padding long還有後置無用的padding long來避免對於value操作的false sharing的發生。那麼對於這個value的操作是怎麼操作的呢? 這
野生前端的資料結構基礎練習(6)——集合
網上的相關教程非常多,基礎知識自行搜尋即可。 習題主要選自Orelly出版的《資料結構與演算法javascript描述》一書。 參考程式碼可見:https://github.com/dashnowords/blogs/tree/master/Structure/Set [TOC] 集
python資料結構與演算法(6)
Python中的順序表Python中的list和tuple兩種型別採⽤了順序表的實現技術,具有前⾯討論的順 序表的所有性質。tuple是不可變型別,即不變的順序表,因此不⽀持改變其內部狀態的任何操 作,⽽其他⽅⾯,則與list的性質類似。list的基本實現技術Python標準型別list就是⼀種元素個數可變的
小白的資料結構程式碼實戰(6)----共享棧
共享棧=棧1+棧2 棧1的棧底為共享棧的首,棧2的棧底為共享棧的尾 共享棧滿:S->top1+1==S->top2 //Author:張佳琪 #include <stdio.h> #include <stdlib.h> #define
野生前端的資料結構基礎練習(5)——雜湊
網上的相關教程非常多,基礎知識自行搜尋即可。 習題主要選自Orelly出版的《資料結構與演算法javascript描述》一書。 參考程式碼可見:https://github.com/dashnowords/blogs/tree/master/Structure/Hash 雜湊的基本知識
聊聊高併發系統之降級特技(轉)
在開發高併發系統時有三把利器用來保護系統:快取、降級和限流。之前已經有一些文章介紹過快取和限流了。本文將詳細聊聊降級。當訪問量劇增、服務出現問題(如響應時間慢或不響應)或非核心服務影響到核心流程的效能時,仍然需要保證服務還是可用的,即使是有損服務。系統可以根據一些關鍵資料進行自動降級,也
資料結構與演算法(二)--遞迴
遞迴條件: 1.遞迴條件:每次調自己,然後記錄當時的狀態 2.基準條件:執行到什麼時候結束遞迴,不然遞迴就會無休止的呼叫自己, 遞迴的資料結構:棧(先進先出)和彈夾原理一樣,每一次呼叫自己都記錄了當時的一種狀態,然後把這種狀態的結果返回。 棧相對應的資料結構:佇列(先進後出
資料結構-----------線性表(下篇)之雙向連結串列
//----------雙向連結串列的儲存結構------------ typedef struct DuLNode { ElemType date; struct DoLNode *prior; struct DoLNode *next; } DoLNode,*DoLinkList;
資料結構---------------線性表(下篇)之單鏈表
單鏈表 特點:儲存空間不連續 結點(資料元素組成):資料域(儲存資料)和指標域(指標)A1 若用p來指向 則資料域為p->date 指標域為p->next 鏈式儲存結構: 單鏈表、迴圈連結串列、雙向連結串列根據連
資料結構與演算法(2)—— 棧(java)
1 棧的實現 1.1 簡單陣列實現棧 package mystack; public class ArrayStack { private int top; //當前棧頂元素的下標 private int[] array; public ArraySt
資料結構上機題(週三)
週三,19號的上機題。 題目,如圖: 不多廢話,直接原始碼: #include<iostream> #include<stdlib.h> int a[100]; using namespace std; class node { public: node
hashmap資料結構詳解(五)之HashMap、HashTable、ConcurrentHashMap 的區別
【hashmap 與 hashtable】 hashmap資料結構詳解(一)之基礎知識奠基 hashmap資料結構詳解(二)之走進JDK原始碼 hashmap資料結構詳解(三)之hashcode例項及大小是2的冪次方解釋 hashmap資料結構詳解(四)之has
野生前端的資料結構基礎練習(7)——二叉樹
網上的相關教程非常多,基礎知識自行搜尋即可。 習題主要選自Orelly出版的《資料結構與演算法javascript描述》一書。 參考程式碼可見:https://github.com/dashnowords/blogs/tree/master/Structure/btree 一.二叉樹的
Java資料結構和演算法(一):簡介
本系列部落格我們將學習資料結構和演算法,為什麼要學習資料結構和演算法,這裡我舉個簡單的例子。 程式設計好比是一輛汽車,而資料結構和演算法是汽車內部的變速箱。一個開車的人不懂變速箱的原理也是能開車的,同理一個不懂資料結構和演算法的人也能程式設計。但是如果一個開車的人懂變速箱的原理,比如降低速
3D引擎資料結構與glTF(1):簡介
不是有句老話講“程式 = 演算法 + 資料結構”嘛,對於3D引擎來說也是這樣。學習和掌握3D引擎中的核心資料有哪些,它們直接的關係是怎樣等等問題,對於理解3D引擎的架構和圖形渲染關係都有著非常大的幫助。然而,現在的商業3D引擎非常複雜,想要通過學習其原始碼嘛非常困難,那麼你就這樣放棄了嗎
3D引擎資料結構與glTF(2): Scene Graph
圖形學中的 Scene Graph Scene Graph 中文常翻譯為“場景圖”,是一種常用的場景物件組織方式。我們把場景中的物件,按照一定的規則(通常是空間關係)組織成一棵樹,樹上的每個節點代表場景中的一個物件。每個節點都可以有零到多個子節點,但只有一個父節點。 每個節點都包含一
Java高併發程式設計之synchronized關鍵字(二)
上一篇文章講了synchronized的部分關鍵要點,詳見:Java高併發程式設計之synchronized關鍵字(一) 本篇文章接著講synchronized的其他關鍵點。 在使用synchronized關鍵字的時候,不要以字串常量作為鎖定物件。看下面的例子: public class
Java高併發程式設計之synchronized關鍵字(一)
首先看一段簡單的程式碼: public class T001 { private int count = 0; private Object o = new Object(); public void m() { //任何執行緒要執行下面這段程式碼
JavaEE-SSM:009 Mybatis的配置檔案解析(6)
檔案型別轉換器(不常用) 假設資料庫有blob格式的欄位儲存需求: 對應著POJO的byte陣列: ResultMap中有對應的typeHandler配置: 當然,我們可以在POJO中使用InputStream替代byte陣列,但