
Mahout駕馭hadoop之詳解
眾所周知,Mahout是基於Hadoop分散式系統的,要想看懂Mahout的原始碼,首先得明白mahout是如何使用hadoop的!
首先,在我的<<Hadoop執行原理詳解>>一篇中,詳細介紹了hadoop的執行機制,這裡就不多說了!下面我就以Kmeans聚類演算法為例,講講mahout如何利用hadoop實現資料探勘演算法並行化.如以下類圖所示,
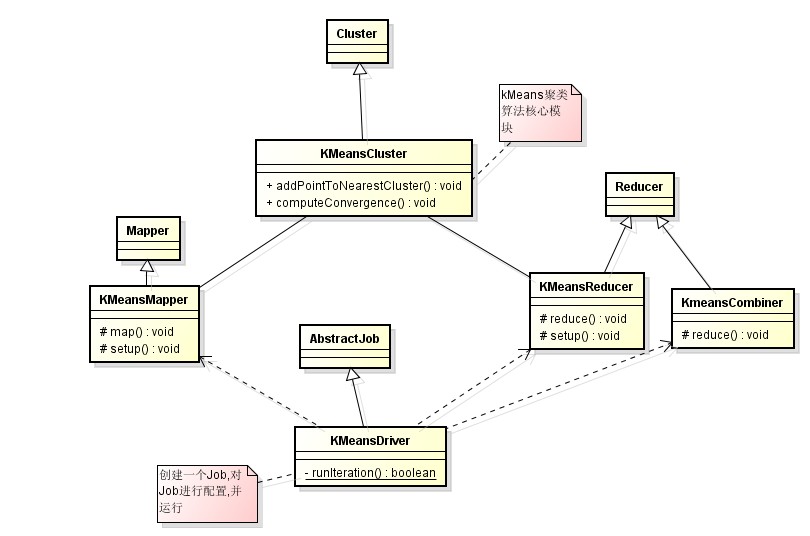
該圖描述了整個mahout實現Kmeans演算法的架構圖,首先KmeansCluster繼承Cluster,在KmeansCluster中有幾個比較重要的方法,首先clusterPoints()是實現Kmeans聚類演算法的方法,而其中呼叫了runKMeansIteration()方法,該方法是單次聚類迭代方法.
尤其可見,這塊演算法實現和普通kmeans演算法沒有太大差別!在Mahout針對每個演算法都有一個Driver,這個東西是幹什麼的啊?
我們先看看KMeansDriver原始碼,KmeansDriver繼承了AbstractJob.我們知道Hadoop上的任務都是以Job的形式啟動的!我們要使用某個演算法進行一項資料探勘工作,因此就要啟動一個Job.因此,KmeansDriver就是建立一個Job,然後對Job的屬性進行配置,然後執行該Job.

上圖反映了KMeansDriver工作原理.
相關推薦
Mahout駕馭hadoop之詳解
眾所周知,Mahout是基於Hadoop分散式系統的,要想看懂Mahout的原始碼,首先得明白mahout是如何使用hadoop的! 首先,在我的<<Hadoop執行原理詳解>>一篇中,詳細介紹了ha
大數據hadoop入門之hadoop家族詳解
集成 查詢工具 人員 進一步 容錯 基礎知識 不同的 ima nbsp 大數據hadoop入門之hadoop家族詳解 大數據這個詞也許幾年前你聽著還會覺得陌生,但我相信你現在聽到hadoop這個詞的時候你應該都會覺得“熟悉”!越來越發現身邊從事hadoop開發或者是正在學習
hadoop家族學習路線圖之hadoop產品詳解
大資料這個詞也許幾年前你聽著還會覺得陌生,但我相信你現在聽到hadoop這個詞的時候你應該都會覺得“熟悉”!越來越發現身邊從事hadoop開發或者是正在學習hadoop的人變多了。作為一個hadoop入門級的新手,你會覺得哪些地方很難呢?執行環境的搭建恐怕就已經足夠讓新手頭疼
Hadoop原始碼詳解之DBOutputFormat類
Hadoop 原始碼詳解之 DBOutputFormat 類 1. 類釋義 A OutputFormat that sends the reduce output to a SQL table. 一種將Reduce 輸出到一個SQL表中的輸出格式。 DB
Hadoop原始碼詳解之Mapper類
Hadoop原始碼詳解之Mapper類 1. 類釋義 Maps input key/value pairs to a set of intermediate key/value pairs. 將輸入的鍵值對應成一系列的中間鍵值對 Maps are the
Hadoop原始碼詳解之FileOutputFormat 類
Hadoop 原始碼詳解之FileOutputFormat 類 1. 類釋義 A base class for OutputFormats that read from FileSystems. 一個類從FileSystems讀取 用於OutputFormats 【實在翻
Hadoop 原始碼詳解之FileInputFormat類
Hadoop 原始碼詳解之FileInputFormat類【updating…】 1. 類釋義 A base class for file-based InputFormats. 針對基於檔案的 InputFormats 一個基類 FileInputFo
Hadoop 原始碼詳解之RecordReader介面
Hadoop 原始碼詳解之RecordReader介面 1. 類釋義 RecordReader reads <key, value> pairs from an InputSplit. RecordReader 從InputSplit中讀取<key,va
Hadoop原始碼詳解之Job 類
Hadoop原始碼詳解之Job類 1. 原始碼 包:org.apache.hadoop.mapreduce 繼承的介面有:AutoCloseable,JobContext,org.apache.hadoop.mapreduce.MRJobConfig
hadoop框架詳解
con 完成 shu ati 默認 logs 應用 sso 分布式存 Hadoop學習隨筆(參考:http://blog.csdn.net/mobanchengshuang/article/details/78786652) Hadoop項目主要包括以下四個模塊 ◆ Had
Java 基礎之詳解 Java 反射機制
一行代碼 strac classname for 內部 系統資源 用戶 管理 ann 一、什麽是 Java 的反射機制? ??反射(Reflection)是Java的高級特性之一,是框架實現的基礎,定義:JAVA反射機制是在運行狀態中,對於任意一個類,都能夠知道這個類的所有
DOS攻擊之詳解--轉載
DOS攻擊之詳解--轉載 DoS到底是什麼? 一、概念理解 二、攻擊流程: 三、攻擊手段: 四、常見的DoS攻擊與防護 DoS到底是什麼? 接觸PC機較早的同志會直接想到微軟磁碟作業系統的DOS--
JavaWeb開發之詳解Servlet及Servlet容器
由於 servlet開發 遊戲 metadata 移動互 -o 每一個 web開發 port 自JavaEE誕生伊始,Servlet容器和Servlet技術,就構成了JavaEE應用的核心,配合其它組件,它們完善了Java企業級開發的全套解決方案。小到一個靜態博客網站,大到
GC之詳解CMS收集過程和日誌分析
話題引入 讓我們先簡單的看下整個堆年輕代和年老代的垃圾收集器組合(以下配合java8完美支援,其他版本可能稍有不同),其中標紅線的則是我們今天要著重講的內容: ParNew and CMS "Concurrent Mark and Sweep" 是CMS的全稱,官方給予的名稱是:“Mostly Co
php 擴充套件開發講解網址 菜鳥學php擴充套件 之 hello world(一) 菜鳥學php擴充套件 之 自動生成的擴充套件框架詳解(二) 菜鳥學php擴充套件 之 詳解擴充套件函式的傳參(如何獲取引數)(三) 菜鳥學php擴充套件 之 詳解php擴充套件的變數(四) 菜鳥學php擴充套件 之
菜鳥學php擴充套件 之 hello world(一) https://blog.csdn.net/u011957758/article/details/72234075 菜鳥學php擴充套件 之 自動生成的擴充套件框架詳解(二) https://blog.csdn.net/u
HADOOP IO詳解——序列化(1)
什麼是IO? I:input 輸入 通常做讀取操作(將不同資料來源的資料讀入到記憶體中,也叫讀取流) O:output 輸出 通常做寫入操作(將記憶體中的資料寫入到不同的資料來源,也叫寫入流)(出記憶體到別的地方) 序列化的作用是什麼?1 資料通訊 2 持久化儲存 為什
HADOOP IO詳解——序列化(2)舉列
package com.hadoop.tv; import java.io.DataInput; import java.io.DataOutput; import java.io.IOException; import org.apache.hadoop.io.Writ
設計模式之詳解——單例模式
單例模式 你要做的只是複製程式碼去一步步驗證,至於原因程式碼中有;不懂可以聯絡我進行交流。 文中每一塊程式碼你可以直接複製貼上,不必要分開復制貼上單獨創捷類去執行。 /** * 單例模式總結: 單例模式優點 1、某些類建立比較頻繁,對於一些
設計模式之詳解——介面卡模式
介面卡模式 介面卡模式將某個類的介面轉換成客戶端期望的另一個介面表示,目的是消除由於介面不匹配所造成的類的相容性問題。主要分為三類:類的介面卡模式、物件的介面卡模式、介面的介面卡模式。 類的介面卡模式 當希望將一個類轉換成滿足另一個新介面的類時,可以使用類的介面
設計模式之詳解——裝飾模式
裝飾模式 就是給一個物件增加一些新的功能,而且是動態的,要求裝飾物件和被裝飾物件實現同一個介面,裝飾物件持有被裝飾物件的例項。 用處: 需要擴充套件一個類的功能。 動態的為一個物件增加功能,而且還能動態撤銷。(繼承不能做到這一點,繼承的功能是靜態的,不能