
讀取螞蜂窩某分類下問答瀏覽數
http://www.upqq.net/java/189.html
1,向String surl = "http://www.mafengwo.cn/qa/ajax_pager.php?type=0&mddid=10184&tids=0&action=question_index&start="+start;傳送連線請求。
2,獲取到的輸出流(如下,裡面中文機標點符號之類會用/u表示),拼接成字串(StringBuilder)。
{"payload":{"list_html":"\u003cli class=\"item clearfix _j_question_item\" data-qid=\"1826184\"\u003e\n \u003cdiv class=\"wen\"\u003e\n \u003cdiv class=\"label\"\u003e\n \u003cspan class=\"avatar avatar32\"\u003e\u003ca href=\"\/wenda\/u\/31175432.html\" class=\"_j_filter_click\"
target=\"_blank\"\u003e\n \u003cimg class=\"_j_filter_click\" src=\"http:\/\/file28.mafengwo.net\/M00\/F8\/23\/wKgB6lRMvDmAZG2JAADRVqH0XuY02.head.w48.jpeg\" height=\"32\" width=\"32\"\u003e\n \u003c\/a\u003e\u003c\/span\u003e\n \u003cspan class=\"icon icon-gl\"\u003e\u003c\/span\u003e\n
\u003c\/div\u003e\n \u003cdiv class=\"title\"\u003e\n \u003ca href=\"\/wenda\/detail-1826184.html\"(部分)
3,將這個Json字串解析(要下jar包,可通過http://json.cn/,線上解析看到如下,此時/u已經被解析為可理解的字元了),獲取"payload"裡“list-item"的字串,即為我們需要提取的資料來源。
{
"payload":Object{...},
"resource":{
"css":[
],
"js":[
]
}
}
{
"payload":{
"list_html":"<li class="item clearfix _j_question_item" data-qid="1826184"> <div class="wen"> <div
class="label"> <span class="avatar avatar32"><a href="/wenda/u/31175432.html" class="_j_filter_click" target="_blank"> <img class="_j_filter_click" (部分)
java程式碼如下:
JSONObject dataJson=JSONObject.fromObject(sb.toString());
JSONObject response=dataJson.getJSONObject("payload");
String info=response.getString("list_html");
4,json返回的字串包裝成InputStreamReader,便於按行讀取。java程式碼如下:
InputStreamReader isr=new InputStreamReader(new ByteArrayInputStream(info.getBytes(Charset.forName("utf8"))),
Charset.forName("utf8"));
5,寫正則表示式,抓取資料來源中的資料(問題,釋出時間,瀏覽量)。java程式碼如下:
String pattern = "<li class=\"item clearfix _j_question_item\" data-qid=\"\\d+\">";
String regularQues = "<a href=\"/wenda/detail-\\d+.html\" class=\"_j_filter_click\" target=\"_blank\">[^<>]*</a>";
String regularDate = ">\\d{4}\\-\\d{1,2}\\-\\d{1,2} \\d{1,2}\\:\\d{1,2}";//日期
String regularViewNum = "<a>瀏覽[^<>]*</a>";
int index=0;
6,將結果寫入excel中(要下jar包)。java程式碼如下:
static WritableWorkbook wwb;
static WritableSheet ws;
File fileWrite = new File("testWrite.xls");
fileWrite.createNewFile();
OutputStream os = new FileOutputStream(fileWrite);
wwb=Workbook.createWorkbook(os);
ws=wwb.createSheet("問答瀏覽數目統計",0);
ws.addCell(new Label(0,0,"問題"));
ws.addCell(new Label(1,0,"釋出時間"));
ws.addCell(new Label(2,0,"瀏覽量"));
問題總結:
1,開始直接向http://www.mafengwo.cn/wenda/10184-0/hot.html傳送請求,發現只能分析出不到20條記錄。然後才發現,網頁底端,有個“點選載入”,點選後新載入20條記錄。用瀏覽器的審查元素,檢視,可獲得如下:
- Request URL: http://www.mafengwo.cn/qa/ajax_pager.php?type=0&mddid=10184&tids=0&app_link=&action=question_index&start=40
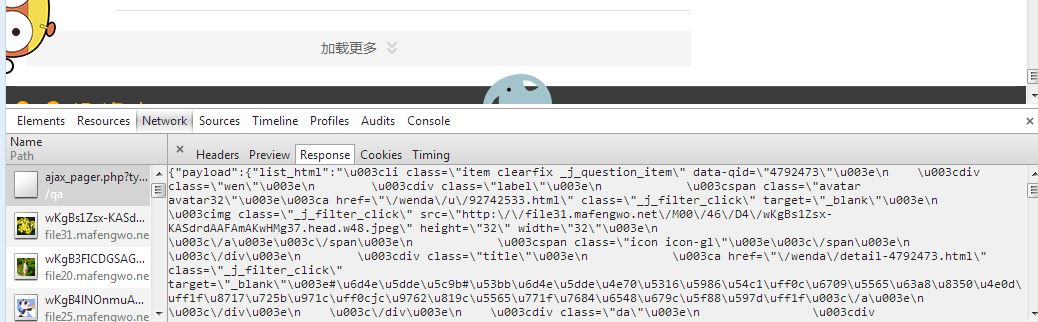
3,當start大於400多時,返回的json為如下:
{"payload":{"list_html":"\u003cdiv class=\"qa-empty\"\u003e\n \u003ci class=\"icon-empty\"\u003e\u003c\/i\u003e\n \u003cp\u003e\u65e0\u76f8\u5173\u95ee\u9898\u003c\/p\u003e\n\u003c\/div\u003e\n","total":500,"page_html":"","ret":1},"resource":{"css":[],"js":[]}}
看來看不到網頁列的2萬多條記錄,只能看到四百多條。
4,單箇中文的匹配就是那個中字,程式中用index標記開始讀的每一塊。[^<>]*這種型別的正則挺好用的。
相關推薦
讀取螞蜂窩某分類下問答瀏覽數
http://www.upqq.net/java/189.html 1,向String surl = "http://www.mafengwo.cn/qa/ajax_pager.php?type=0&mddid=10184&tids=0&acti
java使用jsoup,多執行緒批量爬取天極網某分類下的圖片
小Demo轉自csdn某作者, 本例子只作為測試,頁面個數直接設定了100個,可以可能會少或者多,容易報錯,更優化的一種方式是獲取“下一頁”按鈕的地址,然後再訪問,當訪問不到“下一頁”的內容時跳出 多執行緒只體現在檔案提取,也可以在elements迴圈中再加一個多執行緒
java使用jsoup,多執行緒批量爬取天極網某分類下的美女圖片
本例子只作為測試,頁面個數直接設定了100個,可以可能會少或者多,容易報錯,更優化的一種方式是獲取“下一頁”按鈕的地址,然後再訪問,當訪問不到“下一頁”的內容時跳出 多執行緒只體現在檔案提取,也可以在elements迴圈中再加一個多執行緒訪問頁面的 本案例需要jsoup包的
java將文件夾md5為名的圖片與數據庫查詢對應md5後導入相應圖片到某分類下
getc selectall height user save etc jpg span filter public class FolderUtil { /** * @param path * @return * 得到目錄下的文件
ecshop呼叫指定商品分類下固定條數的商品品牌列表
通過二次開發可以實現ECSHOP首頁呼叫指定分類下的品牌列表。 第一步: 開啟根目錄下的index.php 在最後面 ?> 前面加入以下程式碼: /** * 獲得某個分類下的品
Python3原生爬蟲獲取熊貓直播某一分類下的主播人氣並儲存到Excel
import re import openpyxl from urllib import request # 斷點除錯 class Spider: url = 'https://www.panda.tv/cate/lol' root_pattern = '<di
用shell查找某目錄下的最大文件(轉)
log 異常 nbsp 過濾 exe -type 信息 int div 這是一個很有趣的問題,因為作為一個shell菜鳥,我第一時間是沒有任何想法的。心裏納悶為什麽這樣的操作Linux居然沒有直接的命令實現這樣的查詢。 很自然地,第一感覺就是用awk去實現,因為菜鳥我看aw
Android開發系列(十七):讀取assets文件夾下的數據庫文件
pack 取數 code ada tracking 編寫 數據庫 sdn where 在做Android應用的時候,不可避免要用到數據庫。可是當我們把應用的apk部署到真機上的時候,已經創建好的數據庫及其裏邊的數據是不能隨著apk一起安裝到真機上的。 (PS:這篇
掃描某目錄下的所有文件的MD5碼並導出文件【可執行jar】
output clean mvn clean hot sts balance tid eat .get pom <?xml version="1.0" encoding="UTF-8"?> <project xmlns="http://maven.
讀取某個文件夾下的所有文件
tab stat ioe message delete catch dex 文件 exce import java.io.FileNotFoundException;import java.io.IOException;import java.io.File;public
SQL SERVER 下:1、遞歸查詢父分類下的各個子分類。 2、查詢每個商品分類中最貴的前兩個商品SQL
nio span clas 適用於 商品 一行 class com 分享圖片 1、遞歸查詢父分類下的各個子分類。表設計: SQL: --CTE 語句(適用於MSSQL2005以後版本) with cte_testNavi(Id,Name,Pid ) as ( --這是查
3.3.5 高效讀取:不變模式下的CopyOnWriteArrayList
true ray 新的 nts ont image public bool write 源碼分析:讀寫(get,add) 一:get 方法 private E get(Object[] a, int index) { return (E) a[index];}可
Python讀取指定文件夾下的文件
for 指定 append color return Coding user 一個 元組 1 # -*- coding: utf-8 -*- 2 import csv 3 import os 4 import pandas as pd 5 #提取文件夾下的地址+
全路徑無限分類下拉列表的實現
rom fun rep 最終 [] 深度 color -- echo 最終效果圖: 代碼詳情: include(‘db.inc.php‘); function likecate($path=‘‘){ sql = "select id,catename,path
Linux 查找某目錄下包含關鍵詞的所有文件
code 大小 fin int lin django mys bash string 比如, 需要找到Django框架的配置文件, 修改取消debug模式:awk cd mysite awk -F: ‘/DEBUG/{print FILENAME NR $0 }‘ *.
如何通過簡單的java代碼讀取本地磁盤目錄下的所有文件或者文件夾?
宋體 files test out sys nbsp 得到 ring 輸出 public class FileTest { public static void main(String[] args) { //註意:File導 import java.io.File
Spring boot 讀取jar包中resources下的檔案
package com.jiankunking.elasticsearch.extension.util; import org.springframework.core.io.DefaultResourceLoader; import org.springframework.core
判斷檔案是否存在某路徑下
if (System.IO.File.Exists(Server.MapPath("/images/qrcode/vpopc_qrcode/GZ/") + zhbh + ".jpg")) { gzewm.Attributes.Add("src", "/images/qrcode/vpopc_qrcode/GZ
python3-對某目錄下的文字檔案分詞
from pathlib import Path import os import re pathName='./' fnLst=list(filter(lambda x:not x.is_dir(),Path(pathName).glob('**/*.txt'))) print(fnLst) for fn
python3-對某目錄下的文本文件分詞
dynamic rom help any end eal txt orm script from pathlib import Path import os import re pathName=‘./‘ fnLst=list(filter(lambda x:not x.i