
深入理解Lustre檔案系統-第3篇 LNET:Lustre網路
LNET是Lustre Networking的縮寫,是Lustre的網路子系統,負責提供訊息傳遞API。LNET源自於Sandia Portals,但又與之存在著差異。
3.1 結構
LNET由兩部分組成:
- LNET層。它以通訊API的方式,向被稱為LNET客戶端的高層提供一個與網路型別無關的服務。在LNET層,以LNet作為字首的函式名是為高層提供的外部API,而以lnet作為字首的函式則是內部函式,只能被LNET層或下層的LND層呼叫。
- LND(Lustre Network Driver)層。它實現從一般化的LNET層到特定網路驅動之間的介面。那些LNET層可以呼叫的函式都以lnet作為字首。
這裡需要的注意的是,LNET既被用來表示整個網路子系統,又被用來指代LND之上的一個軟體層。我們不應該混淆它們的含義。
LNET可以以核心模組的方式執行,也可以使用者庫的方式執行。因而,其中的LND層可以是核心模組,也可以是使用者層程式。
圖 LND支援的網路型別
|
名字 |
描述 |
|
|
socklnd |
TCP/IP sockets |
|
|
{cib,open}iblnd |
Topspin IB |
|
|
iiblnd |
Silverstorm IB |
|
|
viblnd |
Voltaire IB |
|
|
o2iblnd |
OFA IB |
|
|
ptllnd |
Cray Portals |
|
|
ralnd |
Cray RapidArray |
|
|
qswlnd |
Quadrics Elan |
|
|
gmlnd |
Myricom GM (no RDMA) |
|
|
mxlnd |
Myricom MX |
|
另外,LND還支援TCP/IP sockets、OFA IB、Cray Portals等幾種使用者層網路。在下面的內容中,如果沒有特殊說明,都指的是核心層實現。
LNET的結構圖如下圖所示:
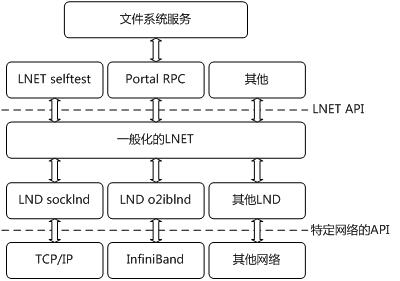
圖 LNET的結構
3.2 網路驅動層
Lustre支援一系列的網路型別。對每種網路型別的支援,都是以核心模組的形式提供的。在這些核心模組的初始化函式中,都會呼叫lnet_register_lnd,註冊一個型別為lnd_t的全域性變數。這個型別為lnd_t的物件,就描述了這個驅動的全部資訊。
表 lnd_t物件提供的方法
|
欄位 |
描述 |
|
|
lnd_startup |
LNET開啟這類網路介面時呼叫 |
|
|
lnd_shutdown |
LNET關閉這類網路介面時呼叫 |
|
|
lnd_ctl |
處理來自使用者空間的ioctl命令。LNET通過一個特殊的裝置檔案,支援許多ioctl,其中一些ioctl命令由LNET直接處理(例如,增加路由),另外一些必須傳遞到LND處理 |
|
|
lnd_send |
傳送正在送出的訊息 |
|
|
lnd_recv |
接收正在來到的訊息 |
|
|
lnd_eager_recv |
訊息的處理由於缺乏資源(轉發緩衝或額度)而被推遲,呼叫此函式以期釋放一些資源。 |
|
|
lnd_notify |
一個peer掛了,呼叫這個函式告知LNET。被LNET路由呼叫 |
|
|
lnd_query |
用來查詢peer是否存活 |
|
|
lnd_accept |
接受新的連線 |
|
3.3 核心資料結構
LNET系統的狀態維持在一個型別為lnet_t的全域性物件the_lnet裡。
the_lnet物件的ln_lnds欄位是系統中LND的連結串列。在每類網路的LND模組載入時,會呼叫lnet_register_lnd,在這個連結串列中新增一個專案。而在LND模組解除安裝時,則呼叫lnet_unregister_lnd,從這個連結串列中刪除其所對應的一項。當LNET層需要使用合適的網路時,會首先從這個連結串列中查詢並匹配到對應的項。用這種方法,LNET提供了對多種網路型別的支援。
the_lnet物件的ln_portals欄位是一個lnet_portal_t的物件陣列。在Portal RPC一章,我們認識到,正確的portal是請求能夠被髮送到對應服務執行緒的關鍵。每個portal都由一個型別為lnet_portal_t的物件來描述。系統中使用的所有lnet_portal_t物件都被放置在the_lnet物件的ln_portals陣列中。
lnet_portal_t物件擁有兩個欄位ptl_mlist和ptl_mhash。前者是一個連結串列,後者是一個連結串列陣列。它們都被用來把所有屬於該portal的匹配項(Matching Entry,ME)組織起來。具體使用哪一個,可以通過設定lnet_portal_t物件的ptl_options欄位來決定。如果使用後者,那麼在定位匹配項鍊表時,需要通過計算雜湊值來確定使用的是ptl_mhash的哪個元素。
匹配項通過型別為lnet_me_t的物件來描述。通過me_list欄位,它被加入到對應的lnet_portal_t物件的匹配項鍊表中。它的me_md欄位,是一個型別為lnet_libmd的物件指標,指向該匹配項管理的記憶體描述符(memory descriptor,MD)。匹配項還定義了64位元的匹配位(me_match_bits欄位)和忽略位(me_ignore_bits欄位),用來確定達到的訊息是否可以使用記憶體描述符中的緩衝空間。
記憶體描述符通過型別為lnet_libmd的物件來描述。與此相關的,還有一種lnet_md_t型別。它們共有一些欄位,但lnet_libmd_t為了進行內部管理維護了更多的狀態。lnet_md_t則被用在LNET客戶端,即ptlrpc層,使得lnet_libmd_t對之不透明,從而避免對LNET的內部狀態產生干擾。
lnet_libmd_t物件用一個I/O向量md_iov來描述緩衝區。這個I/O向量的型別是md_iov聯合體中的struct iovec型別或lnet_kiov_t型別。具體使用那一種由lnet_libmd_t物件的md_options欄位來決定。一般來說,核心中使用lnet_kiov_t來描述緩衝區,而使用者使用struct iovec。正如我們前面所提到的,LNET是一個使用者層和核心層通用的元件。
lnet_libmd_t物件中緩衝區的大小由md_length欄位給出。md_offset欄位則給出了這個緩衝區的有效偏移量。為了描述這個欄位的用法,我們假設請求緩衝大小是4KB,而每個請求最多是1KB。當第一個訊息到達時,這個偏移量增加到1KB,而當第二個訊息到達時,偏移量設定為2KB,如此繼續。因此,從本質上說,偏移量是為避免覆蓋寫而用來追蹤寫位置的。
lnet_libmd_t物件中的另外一個重要的欄位是型別為lnet_eq_t的md_eq欄位。在Portal RPC一章,我們提到,訊息傳送/接受完成或超時,都會在記憶體描述符的事件佇列中產生一個事件。每個事件的處理都是通過呼叫回撥函式來完成的,而回調函式則是把訊息從LNET傳遞到Portal RPC的關鍵。
注意到,記憶體描述符可能被關聯到某個匹配項上,也有可能沒有。這一點,將在下面的內容中涉及到。
下圖給出了上面提到的幾個物件之間的關係。
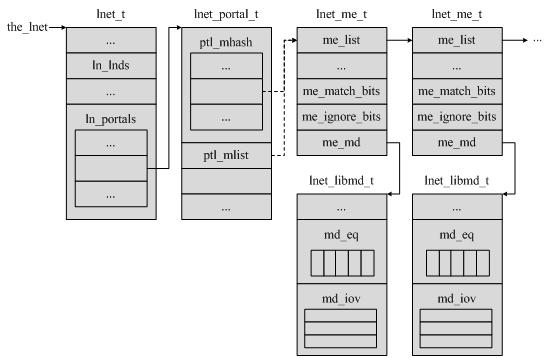
圖 關於LNET的各個物件之間的關係
3.4 塊傳輸的流程
在Portal RPC一章,我們知道ptlrpc_main()函式是所有服務執行緒池共同執行的主函式。在這個函式裡進行的一項重要操作就是呼叫ptlrpc_server_post_idle_rqbds()函式釋出一組請求緩衝描述符(request buffer descriptor,簡寫為rqbd)。請求緩衝描述符是由型別為ptlrpc_request_buffer_desc的物件描述的。每個請求緩衝描述符釋出通過ptlrpc_register_rqbd()函式來完成。在這個函式裡,它進行了一系列操作,包括:
- 建立一個匹配項,並將這個匹配項關聯到服務對應lnet_portal_t物件的匹配項鍊表中。這一任務由LNetMEAttach()函式完成。我們在Portal RPC一章已經知道每種服務都對應一個portal。匹配項的各個欄位被設定為確定的值。例如,由於服務對請求來自何方並無限制,因此匹配項的me_match_id欄位被設定為{LNET_NID_ANY, LNET_PID_ANY}。其意義是不管全域性程序ID(globalprocess ID)是什麼值,具體地,不管它的節點ID欄位nid是什麼值,也不管它的程序ID欄位pid是什麼值,都將請求匹配到這個匹配項。全域性程序ID由型別為lnet_process_id_t的物件描述,它是LNET對端(peer)的唯一區分標識。
- 建立一個記憶體描述符,並將它關聯到上面提到的匹配項上。這一任務由LNetMDAttach ()函式完成。
通過上述活動,伺服器已完成了接受請求的準備。
同樣是在Portal RPC一章,我們分析到所有請求傳送都是通過ptl_send_rpc()發起的。這個函式將型別為ptlrpc_request 的物件作為一個輸入引數。我們假設客戶端在傳送請求,此時ptl_send_rpc()函式可能進行如下操作:
- 如果請求的塊緩衝不為空,即ptlrpc_request 物件的rq_bulk不為NULL,客戶端通過ptlrpc_register_bulk()釋出一個塊緩衝。這個函式將通用呼叫LNetMEAttach()和LNetMDAttach()函式。
- 客戶端通過LNetMEAttach()和LNetMDAttach()函式釋出回覆緩衝,這個操作是在客戶端期望得到回覆訊息的時候才被執行(即輸入引數noreply被設定為0時)。
- 客戶端通過ptl_send_buf()函式傳送請求。這個函式將首先呼叫LNetMDBind(),然後呼叫LNetPut()函式。LNetMDBind()函式將會新建一個“自由漂浮”(free floating)的記憶體描述符,即這個新建的記憶體描述符沒有被關聯到哪個匹配項上。這些記憶體描述符最終將在傳送完成或失敗後,被LNetMDUnlink()函式釋放。LNetPut()函式則負責初始化一個非同步的PUT操作。我們需要注意到,LNetPut()和與之相對的LNetGet()函式都使用一個“自由漂浮”的記憶體描述符作為輸入引數,這個記憶體描述符都由LNetMDBind()函式新建。
在伺服器接受到請求時,會由LNET層發起對request_in_callback()的回撥。這一點在Portal RPC一章也有介紹。這個函式會喚醒等待工作的服務執行緒。服務執行緒根據請求的型別,可能會進行兩個與訊息傳輸有關的動作:
1. 呼叫ptlrpc_start_bulk_transfer()函式進塊傳輸。這個函式通常由target_bulk_io()函式呼叫。在發起塊傳輸之前,還需要做兩件事情:
- 呼叫ptlrpc_prep_bulk_exp()函式為塊傳輸準備好出口。我們在Portal RPC一章瞭解到,一種服務既有請求portal,也有回覆portal,它們都被作為服務的初始化函式ptlrpc_init_svc()的引數。現在,我們又接觸到了服務的另外一種portal,那就是塊傳輸portal,它被用在ptlrpc_prep_bulk_exp()函式的引數中。
- 反覆呼叫ptlrpc_prep_bulk_page()函式為塊傳輸準備好塊傳輸頁。在這個函式中所新建的傳輸頁,最終將被LNetMDBind()函式放入到一個“自由浮動”的記憶體描述符中,並通過LNetGet()函式或LNetPut()函式填充接到或發出的塊資料。
2. 呼叫ptlrpc_reply()函式傳送回覆訊息。
這些訊息返回到客戶端,可能引發多個回撥,如client_bulk_callback()和reply_in_callback()。
為了總結上面的分析結論,我們假設客戶端想要向伺服器讀若干個塊資料。為此,它要準備兩個緩衝:一個是為塊RPC提供的與塊portal相關聯的緩衝,一個是與恢復Portal相關聯的緩衝。然後,它向伺服器傳送一個RPC請求,表明它想讀取若干個塊。接到請求後,伺服器準備好塊緩衝,裝填好資料,然後初始化塊傳輸。當伺服器完成傳輸後,它通過傳送一個回覆來告知客戶端。客戶端在接收完塊資料和回覆訊息後,會通過呼叫回撥函式完成處理。
3.5 啟動
LNET的啟動函式是LNetNIInit()。這個函式裡初始化了LNET網路介面、路由等各種部分,我們這裡指分析初始化網路介面,即lnet_startup_lndnis()函式。這個函式的流程如下:
1. 呼叫lnet_parse_networks()函式來分析使用者提供的模組引數。這些模組引數一般寫在/etc/modprobe.conf檔案中。通過分析這些引數,可以獲得一個需要啟動的網路介面列表。
2. 對上面列表中的所有網路介面進行如下操作。
3. 呼叫lnet_find_lnd_by_type()函式通過網路介面的型別查詢驅動。如果沒有找到驅動,可能是驅動還沒有載入,所以將嘗試呼叫request_module()函式載入模組,然後重試定位驅動。
4. 在定位了網路介面的驅動之後,我們可以將驅動繫結到該介面。
5. 呼叫驅動的lnd_startup方法,啟動該網路介面。
6. 將該網路介面加入到the_lnet全域性變數的網路介面列表中。
至此,所有使用的網路介面都被初始化好了,可以通過這些介面傳送或接受資料。
3.6 傳送
所有LNET訊息都是由LNetPut()函式傳送的。這個函式接受的主要引數包括由lnet_handle_md_t描述的要傳送的記憶體描述符控制代碼,由lnet_nid_t描述的本地介面,由lnet_process_id_t描述的目標程序ID。LNetPut()函式的流程如下:
1. 呼叫lnet_msg_alloc()函式分配一個型別為lnet_msg_t 的物件訊息描述符。這個訊息描述符將傳遞給LND。該物件裡包含的一個重要欄位是型別為lnet_hdr_t的msg_hdr欄位。hdr是訊息頭(header)的縮寫,顧名思義,這個物件描述了訊息頭資訊,它將最終成為傳輸線上的訊息的一部分。
2. 呼叫lnet_commit_md()函式將待發送的記憶體描述符與訊息相關聯。
3. 填入訊息細節。被填入的細節包括是訊息的型別(PUT或者GET)、匹配位、portal索引、偏移量等等。在傳送和接受時都填充的欄位由lnet_prep_send()函式完成,因此這個函式也被LNetGet()函式呼叫。
4. 填入事件資訊。lnet_msg_t 物件的msg_ev欄位是一個型別為lnet_event_t的物件。
5. 呼叫lnet_send()函式傳送這個訊息。
lnet_send()函式的流程如下:
1. 如果訊息要傳送到本地,則選取直連線口作為路由節點。路由節點由型別為lnet_peer_t的物件來描述。
2. 如果訊息要發往網路上的其他節點,則需要根據目標nid選取一個最佳的路由和路由節點。路由節點的是該路由最終到達的目標節點。路由由型別為lnet_route_t的物件來描述。為了選取最佳路由,首先要從目標nid中取得遠端網路,它由型別為lnet_remotenet_t的物件描述。這個物件儲存了從本地到目標的所有可能的路由,因此可以根據這些路由的跳數(hop)、等待發送的位元組數和可用額度(credit)來選取最佳的路由。
3. 呼叫lnet_post_send_locked()函式檢查額度。
4. 呼叫lnet_ni_send()函式傳送訊息。這個函式的引數除了有被髮送的訊息訊息描述符lnet_msg_t物件外,還有一個由lnet_ni_t物件描述的網路介面(network insterface)。lnet_ni_t物件可能直接由lnet_send()函式的輸入引數lnet_nid_t決定,也可能被設定為直連線口,還可能由選取的路由決定。
lnet_post_send_locked()函式的流程如下:
1. 檢查目標路由節點是否活躍,不活躍則返回節點無法連線的錯誤。
2. 為訊息分配一個路由節點發送額度。這個額度將從路由節點的傳送額度中扣除。如果該額度被扣為負數,則返回重新此次操作錯誤。
3. 為訊息分配一個傳送額度。這個額度將從路由節點網路介面(networkinterface)的傳送額度中扣除。如果該額度被扣為負數,則返回重新此次操作錯誤。
4. 如果lnet_post_send_locked()函式的do_send引數被使能,將呼叫lnet_ni_send()函式傳送訊息。但是在lnet_send()函式呼叫lnet_post_send_locked()函式時,並沒有使能這個引數,而是自己呼叫了lnet_ni_send()函式。
lnet_ni_send()函式的流程如下:
1. 呼叫特定網路介面所對應的LND方法lnd_send。
2. 如果該傳送方法返回失敗,呼叫lnet_finalize()函式終止這次傳送。
在以後的某一時間點,在LND傳送訊息結束後,將呼叫lnet_finalize()來告知LNET層,訊息已經發送完畢。
3.6.1 套接字LND的傳送
為了繼續深入分析傳送訊息的過程,我們假設這是一個IP網路。此時使用的是套接字LND,其lnd_send方法是ksocknal_send()。這個函式的流程如下:
1. 呼叫ksocknal_alloc_tx()函式申請一個套接字傳送報文,它由型別為ksock_tx_t的物件描述。
2. 根據LNET訊息填充套接字傳送報文的各個欄位。
3. 呼叫ksocknal_launch_packet()函式發起報文的傳送。
ksocknal_launch_packet()函式的流程如下:
1. 呼叫ksocknal_find_peer_locked(),通過網路介面和目標程序號查詢到套接字端(peer)描述符,這個端描述符由型別為ksock_peer_t的物件描述。
2. 如果找到對應的套接字端描述符,而且已經建立好了連線,就通過ksocknal_queue_tx_locked()把報文加入該連線的傳送佇列中。套接字LND是基於連線的,這種連線由型別為ksock_conn_t的物件描述。
3. 如果沒有找到對應的套接字端描述符,則嘗試通過ksocknal_add_peer()新增這個端描述符。然後回到第1步重試一次。
4. 如果套接字端描述符已存在,但是還未連線好,那麼暫時先將訊息報文排隊到套接字端描述符的等待發送佇列中。這樣當建立了新連線後,從套接字端描述符的等待發送佇列中將報文移至連線的傳送佇列裡,然後將它們傳送出去。
報文的傳送是一個非同步的過程,ksocknal_launch_packet()函式在把報文加入加入連線的傳送佇列中之後就返回了,而實際進行報文的傳送或接收的是一組執行緒名字首為socknal_sd的核心執行緒。這組核心執行緒執行ksocknal_scheduler()函式。這個函式接受一個型別為ksock_sched_t的引數,這個引數描述了該排程器的狀態。這個函式反覆地通過如下流程進行訊息收發:
1. 如果排程器的接收連線連結串列不為空,那麼呼叫ksocknal_process_receive()函式嘗試從連結串列首個連線接受報文,然後把該連線放置到連結串列的尾部。我們可以看到,這是一個近似公平的排程方式。
2. 如果排程器的傳送連線連結串列不為空,那麼呼叫ksocknal_process_transmit()函式嘗試從連結串列首個連線傳送訊息,然後把該連線放置到連結串列的尾部。
3. 如果此次排程沒有任何傳送,那麼就進入睡眠,直到ksocknal_recv()函式ksocknal_queue_tx_locked()把自己喚醒。
4. 如果該流程反覆執行超過了一定次數,則呼叫cond_resched()函式來進行程序切換,並將執行次數清零。
這裡我們只分析傳送過程。ksocknal_process_transmit()函式的流程如下:
1. 如果訊息可以通過零拷貝(zero copy,ZC)方式傳送,那麼將該訊息(由ksock_msg_t物件描述)的ksm_zc_cookies欄位將被設定,並將該報文加入套接字端描述符的零拷貝請求連結串列中。這個連結串列中的所有請求都在等待零拷貝ACK。零拷貝是套接字提供的一種傳送方式,它使得可以不復制緩衝,而直接把報文傳送出去。最終這個報文將通過套接字操作的sendpage方法傳送。而與此相比,非零拷貝方式則是通過套接字操作的sendmsg方法傳送,在這個方法中將進行一次緩衝的複製。不過,零複製也有額外開銷,因此Lustre只用零拷貝方式傳送長度超過一定限度的報文。
2. 呼叫ksocknal_transmit()函式傳送這個訊息。在傳送的時候,就是通過判斷訊息的ksm_zc_cookies欄位來確定是否要進行零拷貝傳送的。
3.6.2 套接字LND的零拷貝傳送
在早先的Lustre版本中(2007年之前),對零拷貝的支援需要向Linux核心打補丁。這樣核心才能告知零拷貝的發起者,被髮送的頁可以被覆蓋寫了。最終,通過引入零拷貝ACK(ZC-ACK),避免了打核心補丁的需要。
零拷貝ACK是一個空的訊息,它的訊息型別是KSOCK_MSG_NOOP。KSOCK_MSG_NOOP這類訊息旨在套接字LND層就被處理了,LNET不知道該訊息的存在。
上面到ksocknal_process_transmit()函式在發現訊息是通過零拷貝方式傳送時,會把該訊息放到套接字端描述符的零拷貝請求連結串列中儲存,以等待接收到零拷貝ACK。接收者接到訊息之後,會回覆一個零拷貝ACK。傳送者接到這個ACK之後,呼叫ksocknal_handle_zcack()函式將該訊息從套接字端描述符的零拷貝請求連結串列中刪除,並減少對這個訊息的引用,如果引用降為零,這個訊息將被ksocknal_tx_done()函式釋放。一般的訊息在被ksocknal_tx_done()函式釋放時會呼叫lnet_finalize()通知LNET層,但由於零拷貝ACK的訊息型別是KSOCK_MSG_NOOP,因此將不會通知到LNET層。
套接字訊息的格式如下所示:

3.7 接收
3.7.1 套接字LND的接收
我們這裡仍以套接字LND為例,分析LNET接收的流程。前面提到,有一組執行緒執行著ksocknal_scheduler()函式。這些執行緒既進行訊息的傳送也進行訊息的接收。在接收訊息時,ksocknal_scheduler()函式呼叫的是ksocknal_process_receive()函式。這個函式實際上是一個根據連線的接收狀態來進行運轉的狀態機。這個狀態機可能出現以下狀態:
- SOCKNAL_RX_KSM_HEADER狀態,表明該連線正準備接收套接字的訊息頭。在每次接收訊息失敗或完成之後,ksocknal_new_packet()函式將狀態機設定為該狀態。在這個狀態下,狀態機期望下次能一次接收到位元組數等於ksock_msg_t物件的訊息頭大小。
- SOCKNAL_RX_LNET_HEADER狀態,表明該連線正準備接收LNET訊息頭。每次狀態機成功的接收了套接字訊息頭之後,進入這一狀態。同時注意到對KSOCK_MSG_NOOP型別的訊息,由於不具有LNET訊息部分,因此不進入SOCKNAL_RX_LNET_HEADER狀態,就直接接收成功了。在這個狀態下,狀態機期望下次能一次接收到位元組數等於ksock_lnet_msg_t物件的大小。
- SOCKNAL_RX_PARSE狀態,表明訊息正在被lnet_parse()函式解析。在狀態機成功接收到了LNET訊息頭,就進入這一狀態。在這種狀態下,會呼叫lnet_parse()函式。這個函式可能會呼叫lnet_ni_recv()函式,最終通過ksocknal_recv()函式把連線狀態改變為SOCKNAL_RX_LNET_PAYLOAD。
- SOCKNAL_RX_LNET_PAYLOAD狀態,表明正在等待接收訊息的有效載荷。我們將在下面的內容中詳細分析lnet_parse()函式。在這種狀態下,狀態機期望下次能一次接收到所有的有效載荷,這個有效載荷被放置在LNET訊息頭物件lnet_hdr_t的payload_length欄位中,由lnet_parse()函式負責解析出來。
- SOCKNAL_RX_SLOP狀態,表明接收訊息的有效載荷出現了意外,如訊息被截斷或校驗和出錯。在這個狀態下,將呼叫ksocknal_new_packet()函式,最終回到SOCKNAL_RX_KSM_HEADER狀態
3.8 基於RMDA的訊息傳輸
上面的分析大多以套接字LND作為例子。在套接字LND的訊息接收中存在者記憶體到記憶體的一次複製。而對於任一支援RDMA的網路,例如o2ib LND,它可以使用RMDA將資料直接傳輸到目的記憶體描述符,從而避免了記憶體到記憶體的拷貝。在這裡我們以o2ibLND為例分析基於基於RDMA的傳送流程。
與套接字LND類似,o2ib LND的傳送方法kiblnd_send()也只是將訊息準備好,放入傳送佇列中就返回了。但與套接字LND不同的是它要項OFED註冊要傳送的記憶體。kiblnd_send()函式在傳送LNET_MSG_PUT和LNET_MSG_GET型別的訊息時所進行的處理是類似的,其流程如下:
1. 取得一個空閒的kib_tx_t型別的物件。
2. 呼叫kiblnd_setup_rd_iov()函式或kiblnd_setup_rd_kiov()函式將存有有效載荷的記憶體描述符中的緩衝註冊到OFED中去。最終這個註冊動作由ib_reg_phys_mr()函式完成。在註冊記憶體後,它取得了一個OFED記憶體ID,它與註冊好的記憶體等價。
3. 呼叫kiblnd_init_tx_msg()函式新建一個IBLND_MSG_PUT_REQ或IBLND_MSG_GET_REQ型別的訊息,並呼叫kiblnd_queue_tx()函式把它加入連線的傳送佇列中。該訊息中攜帶了註冊好的記憶體ID。
4. 呼叫kiblnd_launch_tx()函式。
只將訊息通過kiblnd_init_tx_msg()函式準備好,然後通過kiblnd_launch_tx()函式放入傳送佇列就返回了。實際的傳送操作由執行kiblnd_scheduler()的一組執行緒名字首為kiblnd_sd_的執行緒來完成。
kiblnd_scheduler()函式反覆進行如下流程:
1. 如果型別為kib_data_t的全域性變數kiblnd_data的連線連結串列不為空,取得連結串列首部的連線,並從該連結中刪除。我們可以發現這裡與套接字存在著一些差異。其中之一是,每個套接字排程執行緒獨佔的排程器,它由型別為ksock_sched_t的物件描述,它們各自負責一部分連線,而所有o2ib排程執行緒則共享一個連線連結串列。並且我們應該注意到,kiblnd_scheduler()函式並不會在接受或傳送成功後顯式地把連線放回連結串列尾部,而是交由kiblnd_cq_completion()函式來完成。kiblnd_cq_completion在連線建立的函式kiblnd_create_conn()中就被註冊成傳輸完成時的呼叫的回撥函式,這個註冊動作在ib_create_cq()函式中完成。
2. 呼叫ib_poll_cq()函式等待完成佇列(completion queue)產生完成事件。我們知道Infiniband網路的通訊是通過事件通知的方式來進行的。
3. 如果ib_poll_cq()函式的返回值表明有事件需要處理則呼叫kiblnd_complete()函式處理時間。這裡產生的時間既有可能是RDMA失敗事件(型別為IBLND_WID_RDMA),也有可能是傳送完成事件(型別為IBLND_WID_TX),還有可能是接收完成事件(型別為IBLND_WID_RX)。後兩種時間分別呼叫kiblnd_tx_complete()函式和kiblnd_rx_complete()來進行處理。
kiblnd_tx_complete()函式的處理比較簡單,其中一個操作就是呼叫kiblnd_check_sends()函式把該連線的各種等待發送佇列上所有訊息全都通過kiblnd_post_tx_locked()函式傳送出去。最終的傳送由IB網提供的ib_post_send()函式介面來完成。
我們應該注意到,kiblnd_check_sends()函式不僅會被kiblnd_tx_complete()函式呼叫,在包括接收完成時的其他情況下也會被呼叫。事實上,這個函式一有機會就會被呼叫,以儘快把訊息傳送出去。
kiblnd_rx_complete()函式的流程如下:
1. 呼叫kiblnd_unpack_msg()函式解包收到的訊息。
2. 呼叫kiblnd_handle_rx()函式處理收到的訊息。
kiblnd_handle_rx()函式會根據訊息的型別進行處理。讓我們假設這個訊息的型別是IBLND_MSG_PUT_REQ,此時接收端需要準備接受一個RDMA的推送請求。在這個請求報文裡面有LNET頭資訊,因此kiblnd_handle_rx()函式呼叫lnet_parse()進行解析,由報文中的匹配位匹配到本地的記憶體描述符,這一動作發生在lnet_parse_put()呼叫lnet_match_md()時。在匹配好記憶體描述符時,lnet_parse_put()函式會呼叫lnet_recv_put()來接收這個推送請求。這個函式最終呼叫o2ib LND的kiblnd_recv()函式。
kiblnd_recv()函式會根據訊息的不同型別進行不同的處理。我們這裡只分析訊息是IBLND_MSG_PUT_REQ型別的情況。此時進行的操作流程與上面提到的kiblnd_send()函式在傳送LNET_MSG_GET或LNET_MSG_PUT型別的訊息時所採取的操作流程非常相似,也要把記憶體描述符中的接收緩衝註冊到OFED中去,只不過訊息型別變為IBLND_MSG_PUT_ACK,而且是最後一步發生了變化。在最後一步,kiblnd_recv()不是呼叫kiblnd_launch_tx()函式,而是呼叫kiblnd_queue_tx ()函式。在kiblnd_recv()函式的最後,還將呼叫kiblnd_post_rx()函式。
kiblnd_post_rx()函式首先呼叫ib_post_recv()函式準備接受訊息,然後呼叫kiblnd_check_sends()函式嘗試把所有該連線的訊息傳送出去,其中就包含了前面加入佇列中的IBLND_MSG_PUT_ACK型別的訊息。
我們回到當初IBLND_MSG_PUT_REQ請求的傳送方,它是RDMA推送請求的發起者,此時接到了型別為IBLND_MSG_PUT_ACK的訊息。在kiblnd_handle_rx()函式裡,對這個型別的訊息的處理過程是:
1. 呼叫kiblnd_init_rdma(),初始化RDMA的過程。
2. kiblnd_queue_tx_locked(),將RDMA操作通過ib_post_send()函式介面發起RDMA。
至此,就完成了一次基於RDMA的訊息傳輸流程。
3.9 路由
一般來說,路由器(router)指的是一種通過轉發資料包來實現網路互連的網路層裝置。然而在這裡的路由器指的是LNET提供的一種訊息轉發機制。在一個大型Lustre分散式系統中,可能存在多種型別的混合網路,這些網路中的節點可能作為Lustre的客戶端或伺服器。為了使得這些網路能夠毫無阻礙地進行通訊,LNET提供了路由功能。
我們粗略地把Lustre網路的定義成一組可以相互之間直接通訊而不需路由參與的節點群。那麼LNET路由器就是具有多個網路介面,可以同時與多個Lustre網路網路通訊並連線這些Lustre網路的節點。
下圖給出了一種Lustre叢集的例項,這個例項中有多種型別的Lustre網路,網路之間通過LNET路由器進行通訊。
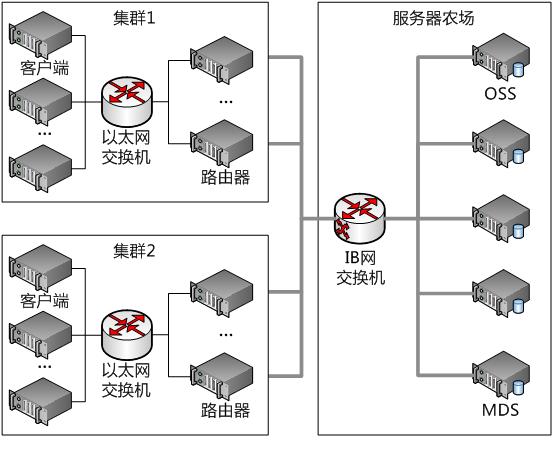
LNET路由是靜態路由,拓撲是靜態配置的,在系統初始化時就已配置分析完畢。在執行時,可以通過lctl的add_route或del_route命令更新LNET路由配置。這些命令最終會通過LNetCtl()函式呼叫相應的路由管理函式。我們可以發現,這種動態更新方式,與基於距離向量或者連結狀態的路由存在著很大的不同。
LNET路由轉發訊息的方式是先把整個訊息接受完畢,然後再轉發出去。我們仍以套接字LND為例分析這個過程。通過前面的分析已經知道,在ksocknal_process_receive()函式發現連線進入SOCKNAL_RX_PARSE狀態時,就開始呼叫lnet_parse()函式。此時已經接收到了LNET的訊息頭,因此lnet_parse()函式可以通過訊息頭的相關資訊知道該訊息是不是最終目的地是自己,如果不是自己,那麼意味著該訊息需要轉發到最終目的地。此時lnet_parse()會呼叫lnet_ni_recv()函式,指明把訊息整個接收下來。在包括有效載荷在內的完整訊息接收完畢後,lnet_finalize()將會被ksocknal_process_receive()函式呼叫。這個函式將呼叫lnet_complete_msg_locked()對接受完畢的訊息做進一步處理。在自身是訊息的LNET路由器的情況下,lnet_complete_msg_locked()函式會把這個訊息轉發到路由的下一跳。通過這個過程,完成了LNET路由的訊息轉發。
在初始化時,LNET路由預分配了一個確定數量的路由緩衝,這個分配發生在lnet_init_rtrpools()函式中。這些路由緩衝的有效載荷大小被分為1MB(一個LNET訊息可以攜帶的最大有效載荷量)、4KB和零,分別為別為大訊息,小訊息和諸如ACK等極小訊息準備。
由於路由緩衝是受限資源,為了防止單一端節點淹沒路由,每個端節點(peer)都給定了一個額度。如果從一個特定端節點的請求超過了它的限額,那麼它的下一個請求將不會被處理,直到路由緩衝被釋放,這就是LNET層進行流控制的原理。更具體一點說,在lnet_parse()函式中,如果它呼叫lnet_post_routed_recv_locked()時發現額度耗盡,將會返回EAGAIN錯誤,該訊息將被推遲處理,直到lnet_finalize()函式呼叫lnet_complete_msg_locked()釋放額度,才重新處理這個轉發訊息。
本文章歡迎轉載,請保留原始部落格連結http://blog.csdn.net/fsdev/article
相關推薦
深入理解Lustre檔案系統-第3篇 LNET:Lustre網路
LNET是Lustre Networking的縮寫,是Lustre的網路子系統,負責提供訊息傳遞API。LNET源自於Sandia Portals,但又與之存在著差異。 3.1 結構 LNET由兩部分組成: LNET層。它以通訊API的方式,向被稱
深入理解Lustre檔案系統-第10篇 LNET:Lustre網路
初始化和拆除 intLNetInit(void)和intLNetFini(void)是用來建立和拆除LNET連線的API。 面向記憶體的通訊語義 如下的API已經由註釋註解了: int LNetGet( lnet_nid_t self, lnet_handle_md_t md_in,
深入理解Lustre檔案系統-第3篇 lustre lite
在file結構體中定義的另外一個欄位是f_dentry,它指向一個儲存在dentry cache(即所謂dcache)中的dentry物件(struct dentry)。實質上,VFS在檔案和資料夾將被首次訪問的時候就會建立一個dentry物件。如果這是一個不存在的檔案/資料夾,那麼將會建立一個無效的de
深入理解Lustre檔案系統-第7篇 MDC和Lustre元資料
7.1 MDC概論 MDC模組是處在Lustre Lite之下的一層。它定義了一些元資料相關的函式, Lustre Lite可以呼叫這些函式來向MDS傳輸元資料請求。這些函式在lustre/mdc中實現,我們將在6.3節討論它們。 Lustre Lite在mdc_op_
深入理解Lustre檔案系統-第12篇 Lustre磁碟檔案系統:ldiskfs
ldiskfs(有些時候被錯誤地稱為Linux ext4檔案系統)是對Linux ext3檔案系統的打了很多補丁的一個版本,由Sun Microsystems公司開發和維護。ldiskfs是Linux ext3和ext4檔案系統的超集。現在它只被Lustre檔案系統用在伺服
深入理解Lustre檔案系統-第2篇 Portal RPC
遠端程序呼叫(Remote Procedure Call,RPC)是構建分散式系統時所使用的一種常見元件。它使得客戶端可以像進行本地呼叫一樣進行遠端的過程呼叫,即客戶端可以忽略訊息傳遞的細節,而專注於過程呼叫的效果。 Portal RPC是Lustre 的R
深入理解Lustre檔案系統-第1篇 跟蹤除錯系統
一直以來,Linus Torvalds對核心偵錯程式都秉持著抵觸態度,並且擺出了我是bastard我怕誰的姿態。他保持了一貫風格,言辭尖銳卻直指本質。相信這是經驗之談。在除錯核心時,最關鍵的問題是如何獲取出錯相關的資訊,準確定位出錯位置。獲取資訊有很多方法,其中核心
深入理解Lustre檔案系統-第9篇 Portal RPC
Portal RPC為如下內容提供了基礎機制: 通過輸入口傳送請求,接受請求通過輸出口接收和處理請求,傳送請求執行塊資料傳輸錯誤恢復 我們將首先探討Portal RPC的介面,而不深入到實現細節中。我們將用LDLM的傳送機製作為例子。對這個例項,LDLM向客戶端傳送一個
深入理解閉包系列第五篇——閉包的10種形式
前面的話 根據閉包的定義,我們知道,無論通過何種手段,只要將內部函式傳遞到所在的詞法作用域以外,它都會持有對原始作用域的引用,無論在何處執行這個函式都會使用閉包。接下來,本文將詳細介紹閉包的10種形式 返回值 最常用的一種形式是函式作為返回值被返回 var F = function()
深入理解閉包系列第四篇——常見的一個迴圈和閉包的錯誤詳解
前面的話 關於常見的一個迴圈和閉包的錯誤,很多資料對此都有文字解釋,但還是難以理解。本文將以執行環境圖示的方式來對此進行更直觀的解釋,以及對此類需求進行推衍,得到更合適的解決辦法 犯錯 function foo(){ var arr = []; for(var i = 0
深入理解定時器系列第三篇——定時器應用(時鐘、倒計時、秒錶和鬧鐘)
前面的話 本文屬於定時器的應用部分,分別用於實現與時間相關的四個應用,包括時鐘、倒計時、秒錶和鬧鐘。與時間相關需要用到時間和日期物件Date,詳細情況移步至此 時鐘 最簡單的時鐘製作辦法是通過正則表示式的exec()方法,將時間物件的字串中的時間部分截取出來,使用定時器重新整理即可 &
深入理解DOM節點型別第三篇——註釋節點和文件型別節點
前面的話 把註釋節點和文件型別節點放在一起是因為IE8-瀏覽器的一個bug。IE8-瀏覽器將標籤名為"!"的元素視作註釋節點,所以文件宣告也被視作註釋節點。本文將詳細介紹這兩部分的內容 註釋節點 【特徵】 註釋在DOM中是通過Comment型別來表示,註釋節點的三個node屬性——node
深入理解DOM節點型別第五篇——元素節點Element
前面的話 元素節點Element非常常用,是DOM文件樹的主要節點;元素節點是HTML標籤元素的DOM化結果。元素節點主要提供了對元素標籤名、子節點及特性的訪問,本文將詳細介紹元素節點的主要內容 特徵 元素節點的三個node屬性——nodeType、nodeName、nodeValue分別是
深入理解javascript物件系列第三篇——神祕的屬性描述符
前面的話 對於作業系統中的檔案,我們可以駕輕就熟將其設定為只讀、隱藏、系統檔案或普通檔案。於物件來說,屬性描述符提供類似的功能,用來描述物件的值、是否可配置、是否可修改以及是否可列舉。本文就來介紹物件中神祕的屬性描述符 描述符型別 物件屬性描述符的型別分為兩種:資料屬性和訪問器屬性 資料屬
深入理解Java虛擬機器 | 第六篇:虛擬機器位元組碼執行引擎
執行引擎是Java虛擬機器最核心的組成部分之一。“虛擬機器”是一個相對於“物理機”的概念,這兩種機器都有程式碼執行能力,其區別是物理機的執行引擎是直接建立在處理器、硬體、指令集和作業系統層面上的,而虛擬機器的執行引擎則是由自己實現的,因此可以自行制定指令集與執行引擎的結構體系
【任務排程系統第三篇】:Azkaban原理介紹
寫在前面 Azkaban官網:https://azkaban.github.io/ 1. azkaban簡單介紹 Azkaban是由Linkedin公司推出的一個批量工作流任務排程器,主要用於在一個工作流內以一個特定的順序執行一組工作和流程。Azkaban使用job配置檔案建
Flask學習【第3篇】:藍圖、基於DBUtils實現資料庫連線池、上下文管理等 基於DBUtils實現資料庫連線池
基於DBUtils實現資料庫連線池 小知識: 1、子類繼承父類的三種方式 class Dog(Animal): #子類 派生類 def
Python學習【第3篇】:Python之運算子 python-----運算子及while迴圈
python-----運算子及while迴圈 一、運算子 計算機可以進行的運算有很多種,不只是加減乘除,它和我們人腦一樣,也可以做很多運算。 種類:算術運
mysql學習【第3篇】:資料庫之增刪改查操作 資料庫之表操作,資料操作
資料庫之表操作,資料操作 注意的幾點:1.如果你在cmd中書命令的時候,輸入錯了就用\c跳出 2.\s檢視配置資訊
Django學習【第3篇】:Django之模板語法
開始 切片 byte 當前 tag targe you 過濾 per Django框架之第三篇模板語法(重要!!!) 一、什麽是模板? 只要是在html裏面有模板語法就不是html文件了,這樣的文件就叫做模板。 二、模板