
Oracle過濾重複資料,取最新的資料
問題:在專案中有一張裝置檢測資訊表DEVICE_INFO_TBL, 每個裝置每天都會產生一條檢測資訊,現在需要從該表中檢索出每個裝置的最新檢測資訊。也就是device_id欄位不能重複,消除device_id欄位重複的記錄,而且device_id對應的檢測資訊test_result是最新的。
解決思路:用Oracle的row_number() over函式來解決該問題。
解決過程:
1.查看錶中的重複記錄
select
t.id,
t.device_id,
t.update_dtm,
t.test_result
from DEVICE_INFO_TBL t 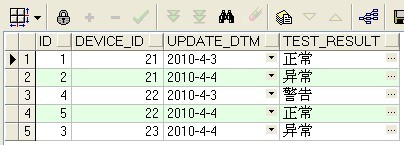
2.標記重複的記錄
select
t.id,
t.device_id,
t.update_dtm,
t.test_result,
row_number() OVER(PARTITION BY device_id ORDER BY t.update_dtm desc) as row_flg
from DEVICE_INFO_TBL t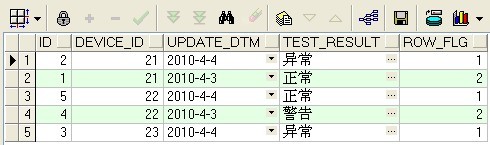
3.過濾重複資料,取得最新的記錄
select
temp.id,
temp.device_id,
temp.update_dtm,
temp.test_result
from 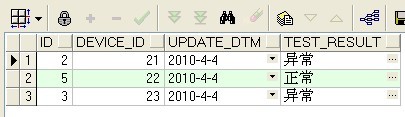
row_number() OVER (PARTITION BY COL1 ORDER BY COL2) 表示根據COL1分組,在分組內部根據 COL2排序,而此函式計算的值就表示每組內部排序後的順序編號(組內連續的唯一的).
與rownum的區別在於:使用rownum進行排序的時候是先對結果集加入偽列rownum然後再進行排序,而此函式在包含排序從句後是先排序再計算行號碼.
row_number()和rownum差不多,功能更強一點(可以在各個分組內從1開時排序).
rank()是跳躍排序,有兩個第二名時接下來就是第四名(同樣是在各個分組內).
dense_rank()是連續排序,有兩個第二名時仍然跟著第三名。相比之下row_number是沒有重複值的 .
lag(arg1,arg2,arg3):
arg1是從其他行返回的表示式
arg2是希望檢索的當前行分割槽的偏移量。是一個正的偏移量,時一個往回檢索以前的行的數目。
arg3是在arg2表示的數目超出了分組的範圍時返回的值。
相關推薦
Oracle過濾重複資料,取最新的資料
問題:在專案中有一張裝置檢測資訊表DEVICE_INFO_TBL, 每個裝置每天都會產生一條檢測資訊,現在需要從該表中檢索出每個裝置的最新檢測資訊。也就是device_id欄位不能重複,消除device_id欄位重複的記錄,而且device_id對應的檢測資訊t
Python----使用正則re查詢文字中特定中文字串,去除重複的資料,取有某個特定字串的前幾位與後幾位數據(適應web回包查詢)
Python----使用正則re查詢文字中特定中文字串例子1:指令碼檔案[email protected]:~/python/dinpay# cat t.py #coding:utf-8 import re source = "s2f程式設計師雜誌一2d3程式
Oracle利用exp和imp,資料泵impdp和expdp匯入匯出資料,spool匯出資料
Oracle利用exp和imp,資料泵impdp和expdp匯入匯出資料,spool匯出資料 注意: (1)imp只能匯入exp匯出的檔案 ,imp,exp是客戶端程式,操作少量資料 (2)impdp只能匯入expdp匯出的檔案,impdp,expdp是伺服器端程式,操作適量大的
Oracle新增一列,並複製資料,批量修改。
新增一列: alter table dt_ck_czry add( jszh varchar2(20) ) 給新增列新增資料: update dt_ck_czry set jszh = czy_dm; 將新增列中是字母的資料修改為空: update( select *
mysql刪除舊資料,保留最新的m條記錄
sql如下: select * from area_table ORDER BY id limit 1670,1 -- 結果id=1671 1條記錄 select * from area_table ORDER BY id limit 10 -- 結果id = 1...1
hive多表聯查實現取最新資料
hive不支援update語句,但我們可以通過增加一個變更表來間接實現update功能。 假設我們有一張user表,對user表的更新都作為新記錄插入到user_delta表中,每條插入都有插入時間欄位updated。獲取最新的user資訊: SELEC
Oracles刪除或查詢條件相同的資料,除了最新那條
例如: 1.刪除 uname=’mm’ 的資料,除了最新那條: DELETE FROM 表名 WHERE uname=’mm’ AND last_modify_time NOT IN (SELECT last_modify_tim
SQL語句怎麼對單個欄位去重,並且要顯示所有列(也可用於去重後,顯示最新資料)
取最大id: select * from 表名 where 主鍵 in(select max(主鍵) from 表名 group by 要去重的欄位 ) 取最新時間:(時間並列會全部展示) select * from 表名 where date in(sel
關於ajax請求資料,並將資料賦值給全域性變數的一些解決方法
在使用ajax請求資料是,開始的時候是打算將ajax的資料取出,並賦予給全域性變數,但是在實際編碼過程中發現並不能將資料賦予給最開始定義的全域性變數,出現這個問題的原因是由於ajax非同步載入的原因,所以只能用其他方法來解決,下來是解決的方法 第一個解決方法沒有使用全域性變數,直接在ajax請求中將請求到的
Spring MVC 模型資料,新增模型資料的5大方式。
Spring MVC 框架作為一個 MVC 框架,很重要的一項工作是在控制器獲取模型資料並返回給前端, 在 JSP 頁面展示模型資料,使用的技術是通過 EL 表示式從域物件中取值; 四大域:pageContext、request、session、application。 我們
列印流printStream:列印流可以列印任意資料,而且列印資料之前會先把資料轉換成字串再進行列印
package printStream; import java.io.File; import java.io.FileOutputStream; import java.io.IOException; import java.io.PrintStream; /* 列印流:(printSt
php後臺查詢出資料,返回json資料,前臺接收並輸出
stu表: index.html <!DOCTYPE html> <html> <head> <meta charset="utf-8"> <script src="http://www.jq22.com/jquery/jquery
ASP.NET MVC + EF 利用儲存過程讀取大資料,1億資料測試很OK
看到本文的標題,相信你會忍不住進來看看! 沒錯,本文要講的就是這個重量級的東西,這個不僅僅支援單表查詢,更能支援連線查詢, 加入一個表10W資料,另一個表也是10萬資料,當你用linq建立一個連線查詢然後
laravel +vue+element-UI如何去取資料和取一行資料
在搭建好laravel+vue+element-UI的專案後,我們在element-UI的元件中我們發現,取後臺資料的方式跟以前的VUE不一樣的。 以前VUE我們用v-for來取資料進行迴圈,在element-UI中用data取資料迴圈:data=""如下: <el-table :
【經典】一篇文章初識大資料,及大資料相關框架Hadoop、spark、flink等
今天看到一篇講得比較清晰的框架對比,這幾個框架的選擇對於初學分散式運算的人來說確實有點迷茫,相信看完這篇文章之後應該能有所收穫。 簡介 大資料是收集、整理、處理大容量資料集,並從中獲得見解所需的非傳統戰略和技術的總稱。雖然處理資料所需的計算能力或儲存容量早已超過一
python讀txt檔案讀資料,然後修改資料,再以矩陣形式儲存在檔案中
import os os.environ['TF_CPP_MIN_LOG_LEVEL'] = '2' # -*- coding: UTF-8 -*- import numpy as np import glob import tensorflow as tf flag=T
前端動態載入(ajax介面連線後臺資料,將後臺資料返回到前端頁面)。
’ text +=’ ‘+result[0].projectCategory+’’ text +=’ ‘+result[0].projectCategory+’’ text +=’ ‘+result[0].projectCategory+’ ’ text +=’ ‘+result[0].project
過濾器通過HttpServletResponseWrapper包裝HttpServletResponse實現獲取response中的返回資料,以及對資料進行gzip壓縮
前幾天我們專案總監給了我一個任務,就是將請求的介面資料進行壓縮,以達到節省流量的目的。 對於實現該功能,有以下思路: 1.獲取到response中的值, 2.對資料進行gzip壓縮(因為要求前端不變,所以只能選在這個瀏覽器都支援的壓縮方式) 3.將資料寫
oracle查詢重複記錄,去除重複記錄
轉載自http://blog.163.com/aner_rui/blog/static/12131232820105901451809/ SELECT * FROM t_info a WHERE ((SELECT COUNT(*) FROM t_i
Python爬蟲:十分鐘實現從資料抓取到資料API提供
依舊先從爬蟲的基本概念說起,你去做爬蟲做資料抓取,第一件事想必是去檢視目標網站是否有api。有且可以使用的話,皆大歡喜。 假如目標網站自身不提供api,但今天你心情不好就想用api來抓資料,那