
搭建4個節點的Hadoop
說明
本博文較長,但是有效,如若計劃安裝多節點的hadoop,請一步一步堅持下去,有問題請留言,我們可以討論來解決問題。
本人將該4個節點的hadoop安裝在了vmware上了,同時支援安裝在物理機或者vmware ESXi上。
| 節點 | 說明 | ip地址 |
|---|---|---|
| hadoop01 | 主節點 | 192.168.10.61 |
| hadoop02 | 從節點 | 192.168.10.62 |
| hadoop03 | 從節點 | 192.168.10.63 |
| hadoop04 | 從節點 | 192.168.10.64 |
請注意以下說明:
以root身份執行的命令為紅色字型
hadoop使用者執行的為黑色字型
環境
其中hadoop2.7.0和Jdk7.9.1兩個軟體我已經做好iso映象,大家可以來百度網盤下載:點選下載
準備模板
由於搭建hadoop過程中有許多地方的配置是重複的,故我們需要做一個模板避免過度重複勞動。
安裝RedhatServer
作業系統的安裝大家可直接從網上尋找,在此不再囉嗦。
關閉防火牆
根據自己的需要執行如下命令
service iptables status –檢視當前防火牆狀態
service iptables stop –關閉防火牆
chkconfig iptables off –永久關閉防火牆
關閉SElinux
執行如下命令
vim /etc/sysconfig/selinux
將SELINUX設定為disabled
開啟rsync
chkconfig rsync on
配置hosts
vim /etc/hosts
新增如下四行資料
192.168.10.61 hadoop01
192.168.10.62 hadoop02
192.168.10.63 hadoop03
192.168.10.64 hadoop04

建立hadoop使用者
執行如下命令建立hadoop使用者並設定其密碼為hadoop123
useradd hadoop
echo “hadoop123” | passwd –stdin hadoop
解壓hadoop、java檔案
本文中我是將所有的軟體包用軟碟通打包到hadoop2.7.1dvd.iso中去,然後掛載到虛擬機器的虛擬光碟機中,大家也可以用FileZilla等工具將軟體上傳到該系統中去,在media中會顯示一個20151220_122127的資料夾。
我的iso檔案如下
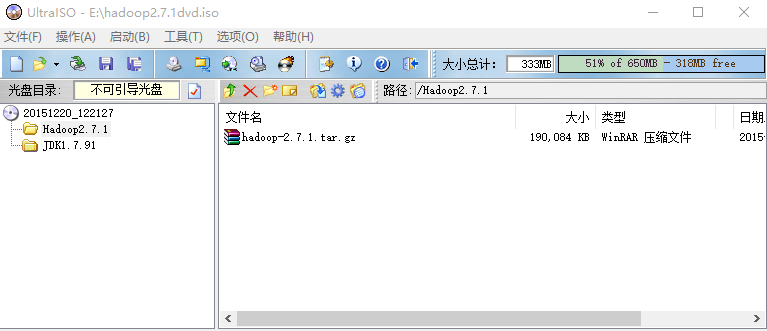
執行如下命令建立相應目錄並將安裝包複製到相應目錄
mkdir /opt/moudles
cd /media/20151220_122127/Hadoop2.7.1/
cp hadoop-2.7.1.tar.gz /opt/moudles/
cd /media/20151220_122127/JDK1.7.91/
cp jdk-7u91-linux-x64.tar.gz /opt/moudles/
執行如下命令將所屬使用者修改為hadoop使用者
chown hadoop /opt/moudles
chown hadoop /opt/moudles/hadoop-2.7.1.tar.gz
chown hadoop /opt/moudles/jdk-7u91-linux-x64.tar.gz
切換到hadoop使用者,對壓縮包進行解壓
su hadoop
cd /opt/moudles/
tar zxvf hadoop-2.7.1.tar.gz
tar zxvf jdk-7u91-linux-x64.tar.gz
配置環境變數
依舊以hadoop身份執行如下命令
cat>>~hadoop/.bashrc <<<EOF
JAVA_HOME=/opt/moudles/jdk1.7.0_91
export JAVA_HOME
HADOOP_HOME=/opt/moudles/hadoop-2.7.1
export HADOOP_HOME
PATH=\$HADOOP_HOME/bin:\$HADOOP_HOME/sbin:\$JAVA_HOME/bin:$PATH
EOF
exit建立臨時目錄
以root使用者身份建立臨時目錄,並賦予hadoop使用者
mkdir -p /hadoopdata/hadoop/temp
chown -R hadoop /hadoopdata
關機,克隆4個節點
克隆4次,分別克隆出hadoop01~hadoop04,其中hadoop01為主節點,hadoop02-04為從節點。
開始安裝hadoop 叢集
對hadoop01~hadoop04修改
對hadoop01~hadoop04分別配置ip地址
| 節點 | 說明 | ip地址 |
|---|---|---|
| hadoop01 | 主節點 | 192.168.10.61 |
| hadoop02 | 從節點 | 192.168.10.62 |
| hadoop03 | 從節點 | 192.168.10.63 |
| hadoop04 | 從節點 | 192.168.10.64 |
執行如下命令分別對各個節點修改主機名
vim /etc/sysconfig/network
將HOSTNAME設定為對應的名稱,如主節點將HOSTNAME設定為hadoop01,從節點分別設定為對應的hadoop02.hadoop03,hadoop04。
修改成功後執行reboot命令重新啟動
reboot
配置ssh
修改配置檔案
對主節點hadoop01進行修改
對環境檔案進行修改
涉及到的檔案主要有:
- /opt/moudles/hadoop-2.7.1/etc/hadoop/hadoop-env.sh
- /opt/moudles/hadoop-2.7.1/etc/hadoop/yarn-env.sh
- /opt/moudles/hadoop-2.7.1/etc/hadoop/mapred-env.sh
- /opt/moudles/hadoop-2.7.1/etc/hadoop/slaves
以hadoop使用者執行如下命令對hadoop-env.sh檔案進行修改
cd /opt/moudles/hadoop-2.7.1
vim etc/hadoop/hadoop-env.sh修改:
export JAVA_HOME=/opt/moudles/jdk1.7.0_91
繼續執行如下命令對yarn-env.sh檔案進行修改
vim etc/hadoop/yarn-env.sh修改:
export JAVA_HOME=/opt/moudles/jdk1.7.0_91
繼續執行如下命令對mapred-env.sh檔案修改
vim etc/hadoop/mapred-env.sh修改:
export JAVA_HOME=/opt/moudles/jdk1.7.0_91
繼續執行如下命令對slaves檔案進行修改
cd /opt/moudles/hadoop-2.7.1/etc/hadoop/
cat>slaves<<EOF
hadoop02
hadoop03
hadoop04
EOF對配置檔案進行修改
主要涉及的檔案有:
- /opt/moudles/hadoop-2.7.1/etc/hadoop/core-site.xml
- /opt/moudles/hadoop-2.7.1/etc/hadoop/hdfs-site.xml
- /opt/moudles/hadoop-2.7.1/ etc/hadoop/mapred-site.xml
- /opt/moudles/hadoop-2.7.1/ etc/hadoop/yarn-site.xml
執行如下命令,對core-site.xml進行修改
cd /opt/moudles/hadoop-2.7.1/etc/hadoop/
vim core-site.xml修改為如下
<configuration>
<property>
<name>hadoop.tmp.dir</name>
<value>/hadoopdata/hadoop/temp</value>
<description>A base for other temporary directories.</description>
</property>
<property>
<name>fs.default.name</name>
<value>hdfs://hadoop01:9000</value>
<description>The name of the default file system.</description>
</property>
<property>
<name>io.file.buffer.size</name>
<value>131072</value>
<description>io file buffer size</description>
</property>
</configuration>
執行如下命令,對hdfs-site.xml進行修改
cd /opt/moudles/hadoop-2.7.1/etc/hadoop/
vim hdfs-site.xml修改為如下
<configuration>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/hadoopdata/hadoop/hdfs/namenode</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value> file:/hadoopdata/hadoop/hdfs/datanode</value>
</property>
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
<property>
<name>dfs.webhdfs.enabled</name>
<value>true</value>
</property>
</configuration>執行如下命令,對mapred-site.xml進行修改
cd /opt/moudles/hadoop-2.7.1/etc/hadoop/
cp mapred-site.xml.template mapred-site.xml
vi mapred-site.xml修改為如下
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapreduce.jobhistory.address</name>
<value>hadoop01:10020</value>
</property>
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value> hadoop01:19888</value>
</property>
</configuration>執行如下命令,對yarn-site.xml進行修改
cd /opt/moudles/hadoop-2.7.1/etc/hadoop/
vim yarn-site.xml修改為如下
<configuration>
<!-- Site specific YARN configuration properties -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.auxservices.mapreduce.shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
<property>
<name>yarn.resourcemanager.address</name>
<value>hadoop01:8032</value>
</property>
<property>
<name>yarn.resourcemanager.scheduler.address</name>
<value>hadoop01:8030</value>
</property>
<property>
<name>yarn.resourcemanager.resource-tracker.address</name>
<value>hadoop01:8031</value>
</property>
<property>
<name>yarn.resourcemanager.admin.address</name>
<value>hadoop01:8033</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address</name>
<value>hadoop01:8088</value>
</property>
</configuration>把配置檔案複製到其他Hadoop叢集節點
執行如下命令將配置檔案打包,然後傳到slave節點上
cd /opt/moudles/hadoop-2.7.1/etc/hadoop/
rm -rf hadoopconf
mkdir hadoopconf
cp hadoop-env.sh hadoopconf
cp core-site.xml hadoopconf
cp mapred-site.xml hadoopconf
cp slaves hadoopconf
cp hdfs-site.xml hadoopconf
cp yarn-site.xml hadoopconf
cp yarn-env.sh hadoopconf
cd hadoopconf
tar cvf hadoopconf.tar *
scp hadoopconf.tar hadoop@hadoop02:/opt/moudles/hadoop-2.7.1/etc/hadoop
scp hadoopconf.tar hadoop@hadoop03:/opt/moudles/hadoop-2.7.1/etc/hadoop
scp hadoopconf.tar hadoop@hadoop04:/opt/moudles/hadoop-2.7.1/etc/hadoop
分別在hadoop02,hadoop03,hadoop04上執行如下命令對其解包,完成Hadoop叢集配置檔案的同步
cd /opt/moudles/hadoop-2.7.1/etc/hadoop/
tar xvf hadoopconf.tar第一次啟動hadoop
格式化namenode
在主節點上執行
cd /opt/moudles/hadoop-2.7.1/
./bin/hdfs namenode -format啟動hdfs
在主節點上執行
cd /opt/moudles/hadoop-2.7.1/
./sbin/start-dfs.sh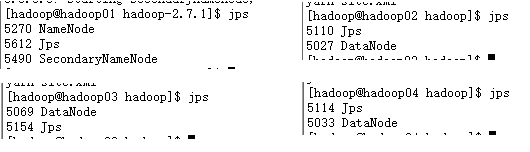
啟動yarn
在主節點上執行
cd /opt/moudles/hadoop-2.7.1/
./sbin/start-yarn.sh
```shell

<div class="se-preview-section-delimiter"></div>
## 驗證安裝成功
<div class="se-preview-section-delimiter"></div>
###瀏覽器檢視
通過瀏覽器訪問http://hadoop01:50070

通過瀏覽器訪問http://hadoop01:8088

<div class="se-preview-section-delimiter"></div>
###程式驗證
執行如下程式碼執行帶有12個map和100個樣本的pi例項
<div class="se-preview-section-delimiter"></div>
```shell
cd /opt/moudles/hadoop-2.7.1/share/hadoop/mapreduce
yarn jar ./hadoop-mapreduce-examples-2.7.1.jar pi 12 100執行結果如下所示:
Number of Maps = 12
Samples per Map = 100
Wrote input for Map #0
Wrote input for Map #1
Wrote input for Map #2
Wrote input for Map #3
Wrote input for Map #4
Wrote input for Map #5
Wrote input for Map #6
Wrote input for Map #7
Wrote input for Map #8
Wrote input for Map #9
Wrote input for Map #10
Wrote input for Map #11
Starting Job
16/06/11 17:07:12 INFO client.RMProxy: Connecting to ResourceManager at hadoop01/192.168.10.61:8032
16/06/11 17:07:12 INFO input.FileInputFormat: Total input paths to process : 12
16/06/11 17:07:12 INFO mapreduce.JobSubmitter: number of splits:12
16/06/11 17:07:12 INFO mapreduce.JobSubmitter: Submitting tokens for job: job_1465618407612_0006
16/06/11 17:07:13 INFO impl.YarnClientImpl: Submitted application application_1465618407612_0006
16/06/11 17:07:13 INFO mapreduce.Job: The url to track the job: http://hadoop01:8088/proxy/application_1465618407612_0006/
16/06/11 17:07:13 INFO mapreduce.Job: Running job: job_1465618407612_0006
16/06/11 17:07:17 INFO mapreduce.Job: Job job_1465618407612_0006 running in uber mode : false
16/06/11 17:07:17 INFO mapreduce.Job: map 0% reduce 0%
16/06/11 17:07:29 INFO mapreduce.Job: map 8% reduce 0%
16/06/11 17:07:30 INFO mapreduce.Job: map 67% reduce 0%
16/06/11 17:07:36 INFO mapreduce.Job: map 75% reduce 0%
16/06/11 17:07:37 INFO mapreduce.Job: map 100% reduce 100%
16/06/11 17:07:37 INFO mapreduce.Job: Job job_1465618407612_0006 completed successfully
16/06/11 17:07:37 INFO mapreduce.Job: Counters: 49
File System Counters
FILE: Number of bytes read=270
FILE: Number of bytes written=1505992
FILE: Number of read operations=0
FILE: Number of large read operations=0
FILE: Number of write operations=0
HDFS: Number of bytes read=3170
HDFS: Number of bytes written=215
HDFS: Number of read operations=51
HDFS: Number of large read operations=0
HDFS: Number of write operations=3
Job Counters
Launched map tasks=12
Launched reduce tasks=1
Data-local map tasks=12
Total time spent by all maps in occupied slots (ms)=157380
Total time spent by all reduces in occupied slots (ms)=5029
Total time spent by all map tasks (ms)=157380
Total time spent by all reduce tasks (ms)=5029
Total vcore-seconds taken by all map tasks=157380
Total vcore-seconds taken by all reduce tasks=5029
Total megabyte-seconds taken by all map tasks=161157120
Total megabyte-seconds taken by all reduce tasks=5149696
Map-Reduce Framework
Map input records=12
Map output records=24
Map output bytes=216
Map output materialized bytes=336
Input split bytes=1754
Combine input records=0
Combine output records=0
Reduce input groups=2
Reduce shuffle bytes=336
Reduce input records=24
Reduce output records=0
Spilled Records=48
Shuffled Maps =12
Failed Shuffles=0
Merged Map outputs=12
GC time elapsed (ms)=3029
CPU time spent (ms)=35170
Physical memory (bytes) snapshot=3409559552
Virtual memory (bytes) snapshot=11427811328
Total committed heap usage (bytes)=2604138496
Shuffle Errors
BAD_ID=0
CONNECTION=0
IO_ERROR=0
WRONG_LENGTH=0
WRONG_MAP=0
WRONG_REDUCE=0
File Input Format Counters
Bytes Read=1416
File Output Format Counters
Bytes Written=97
Job Finished in 25.365 seconds
Estimated value of Pi is 3.14666666666666666667
關閉hadoop
停止yarn
在主節點上執行如下命令
cd /opt/moudles/hadoop-2.7.1/
./sbin/stop-yarn.sh停止hdfs
在主節點執行如下命令
cd /opt/moudles/hadoop-2.7.1/
./sbin/stop-dfs.sh相關推薦
搭建4個節點的Hadoop
說明 本博文較長,但是有效,如若計劃安裝多節點的hadoop,請一步一步堅持下去,有問題請留言,我們可以討論來解決問題。 本人將該4個節點的hadoop安裝在了vmware上了,同時支援安裝在物理機或者vmware ESXi上。 節點 說明
01-搭建一個4個節點的CentOS叢集
步驟 1、在虛擬機器中安裝CentOS 2、在每個CentOS中都安裝Java和Perl 3、在4個虛擬機器中安裝CentOS叢集 4、配置4臺CentOS為ssh免密碼互相通訊 1. 在虛擬機器中安裝CenOS 4臺虛擬機器,每臺虛擬機器是
搭建多個節點的hadoop叢集環境(CDH)
提示:如果還不瞭解Hadoop的,可以下檢視這篇文章Hadoop生態系統,通過這篇文章,我們可以首先大致瞭解Hadoop及Hadoop的生態系統中的工具的使用場景。 搭建一個分散式的hadoop叢集環境,下面是詳細步驟,使用cdh5 。 一、硬體準備
sheepdog+zookeeper儲存叢集搭建:4個節點安裝sheepdog(其中有3個為zookeeper節點)
1、首先在4個儲存節點中的3個節點上安裝3節點zookeeper,詳見 http://blog.csdn.net/u010855924/article/details/52847308 2、第四個儲存節點僅僅需要rpm -ivh zookeeper-3.4.6-redhat
搭建3個節點的hadoop叢集(完全分散式部署)--1 安裝虛擬機器及hadoop元件
昨晚搞到晚上11.30,終於把hadoop元件安裝好了,執行試了下,正常...這裡記錄下完全分散式hadoop叢集的搭建步驟。1.VWMare平臺安裝之前已經安裝好了,這裡不詳細說明。2.安裝CentOS虛擬機器1)下載好centos ISO安裝檔案,我安裝的是centos6
1.從零開始在虛擬機器中一步一步搭建一個4個節點的CentOS叢集
軟體準備 CentOS-6.6-i386-bin-DVD1.iso VMWare 虛擬機器映象安裝 這裡不再贅述 叢集配置 主機 IP hostname eshop-cac
搭建3個節點的hadoop叢集(完全分散式部署)--2安裝mysql及hive
網上下載mysql安裝包檔案,我下載的是:mysql-5.7.21-linux-glibc2.12-x86_64.tar.gz,tar解壓後mv到mysql資料夾,啟動mysql服務service mysqld start登入mysqlmysql -u root -p輸入密碼
手把手在虛擬機器中搭建四個節點的centos叢集
叢集,一個很熟悉的名字,是一種較新的技術,通過叢集技術,可以在付出較低成本的情況下獲得在效能、可靠性、靈活性方面的相對較高的收益,其任務排程則是集群系統中的核心技術。下面手把手教你在虛擬機器中搭建4個節點的centos叢集,跟著步驟操作即可。 工具:virtualbox、cen
7.redis cluster叢集搭建(6個節點)
本文是3臺伺服器,1:7001,7002 ; 2: 7003,7004 ; 3:7005,7006 1.安裝redis,同前面文章所提的安裝過程(僅安裝,暫不配置配置檔案) 注意: (1).在etc目錄下新建幾個資料夾 a. redis 用於存放redis.
es叢集搭建(2個節點)
可以說Elasticsearch就是為分散式而生的,網上的資料很多,但把搭建叢集介 紹的詳細的很少,這裡介紹下2個es節點組成的叢集的搭建(針對5.0及以上版本),針對一些概念性(如單播,組播等)的內容不再贅述 首先需要提醒的是: 1.兩個節點必須能pin
Docker搭建ELK6.4.1以及Elasticsearch6.4.1叢集(三個節點)
轉載請表明出處 https://blog.csdn.net/Amor_Leo/article/details/83144739 謝謝 ELK6.4.1以及Elasticsearch6.4.1叢集Docker搭建 搭建Elasticsearch叢集(三個節點) doc
Docker搭建ELK6.4.1以及Elasticsearch6.4.1叢集(兩個節點)
轉載請表明出處 https://blog.csdn.net/Amor_Leo/article/details/83011372 謝謝 ELK6.4.1以及Elasticsearch6.4.1叢集Docker搭建 搭建Elasticsearch叢集(兩個節點) doc
用Docker在一臺膝上型電腦上搭建一個具有10個節點7種角色的Hadoop叢集(下)-搭建Hadoop叢集
上篇介紹了快速上手Docker部分,下面接著介紹搭建Hadoop叢集部分。 六、搭建Hadoop偽分佈模式 我們先用前面建立的這個容器來搭建Hadoop偽分佈模式做測試,測試成功後再搭建完全分散式叢集。1.SSH這個centos容器可以看做是一個非常精簡的系統,很多功能沒有,需要自己安裝。Hado
用Docker在一臺膝上型電腦上搭建一個具有10個節點7種角色的Hadoop叢集(上)-快速上手Docker
如果想在一臺電腦上搭建一個多節點的Hadoop叢集,傳統的方式是使用多個虛擬機器。但這種方式佔用的資源比較多,一臺筆記本能同時執行的虛擬機器的數量是很有限的。這個時候我們可以使用Docker。Docker可以看做是一種輕量級的虛擬機器,佔用資源少,用起來和傳統的虛擬機器很像,使用的時候可以類比VMware或V
ubuntu18.04 搭建hadoop完全分散式叢集(Master、slave1、slave2)共三個節點
一、硬體配置以及作業系統: 所需要的機器以及作業系統:一臺mac os筆記本、一臺window筆記本(CPU雙核四執行緒,記憶體8G),其中mac os用於遠端操作,window筆記本裝有虛擬機器,虛擬出3個ubuntu18.04系統(配置CPU1個執行緒2個,記憶體1.5G,硬碟分配每個7
從零開始系列之vue全家桶(4)帶新手小白一起搭建第一個個人網站項目
轉載 個人網站 rfi red nbsp oot ott osx 全部 未經允許,嚴禁轉載,全文由blackchaos提供。 在安裝好了前面大部分需要的插件,我們開始進行第一個個人項目。結合vue+vuex+vue-cli+vue-router+webpack使用。
應對Hadoop集群數據瘋長,這裏祭出了4個治理對策!
基於 cin 就是 嚴格 abc dcl bmf bsp 我們 一、背景 在目前規模比較大的互聯網公司中,總數據量能達到10PB甚至幾十PB數據量的公司,我認為中國已經有超過了20家了。而在這些公司中,也有很多家公司的 日數據增長達到100TB+ 了。 所以我們每天都要觀察
(趙強老師原創)搭建CDH實驗環境,三個節點的安裝配置
大數據 CDH 安裝配置 Hadoop Spark 趙強老師簡介-------------------------------------------------------清華大學軟件工程專業畢業。現就職於Oracle(中國)有限公司高級技術顧問,在Oracle公司服務已超過10年。業界
大數據之搭建HDP環境,以三個節點為例
com 新的 防火墻 cdh 實驗環境 只需要 包名 connector start (一)實驗環境l 實驗介質?CentOS-7-x86_64-Everything-1708.iso?jdk-8u144-linux-x64.tar.gz?ambari-2.6.0.0-ce
hadoop生態搭建(3節點)-06.hbase配置
校驗 stc shutdown name daemon 配置環境 val main ica # http://archive.apache.org/dist/hbase/1.2.4/ # ==========================================