
C語言的符號表和型別系統2
閱讀部落格的朋友可以到我的網易雲課堂中,通過視訊的方式檢視程式碼的除錯和執行過程:
這一節,我們繼續就上一節討論的內容,繼續就符號表和型別系統的構建進行深入的探討。
基於上一節的基礎,我們看看,編譯器如何為一個變數構建它在符號表中的記錄和型別系統。假設我們的C語言程式碼中有如下的變數定義:
enum rabbits {
FLOSPY, MOPSEY, PETER
};上面的列舉型別,會被C編譯器轉換成如下形式的C程式碼:
const int FLOSPY = 0;
const int MOPSEY = 0;
const int PETER = 0;編譯器在解析 “const int FLOSPY = 0” 這條語句後,會在符號表中產生以下資料結構:
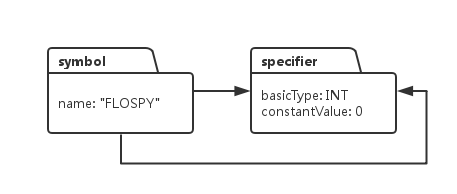
由於變數FLOSPY 沒有*, 沒有[]之類的型別宣告,因此它的型別系統只需要說明符,不需要修飾符,因此它的型別列表中就是由一個specifier.它的資料型別是INT, 由於被初始化成一個常量整形,所以constantValue設定為0.大家注意,從Symbol物件引出兩個箭頭,兩個箭頭都指向specifier物件。之所以需要兩個箭頭是因為,型別系統本質上就是一個連結串列,連結串列連結的是兩種物件,一種是declarator, 一種是specifier, 我們在實現程式碼的時候,需要把declarator放在連結串列的前面,specifier放在連結串列的最末尾。因此從symbol發出的兩個箭頭,一個指向佇列的開頭,這樣從這個箭頭起始就可以逐個訪問連結串列的每個物件,由於declarator放在連結串列的前面,這樣從這個箭頭開始,就可以訪問一系列的declarator, 但是如果我們想要訪問連結串列最末尾的specifier物件,那就得遍歷整個連結串列,這樣效率就太慢了,於是,從symbol物件引出第二個箭頭直接指向連結串列的末尾,也就是specifier物件,這樣想要直接訪問型別系統連結串列的specifier,直接從第二個指標讀取就可以了,不需要遍歷整個連結串列,例如下面這個例子:
long int (*Frollo)[10];編譯器會給上面的變數宣告建立如下的符號表記錄和型別佇列:
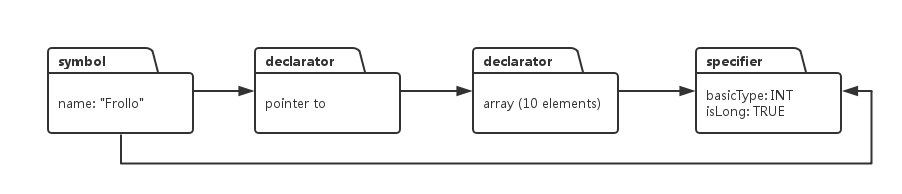
大家看到,型別系統佇列有三個元素,前兩個是declarator, 最後一個是specifier, 從symbol引出的兩個箭頭,一個指向連結串列的開始,第二個直接指向連結串列的末尾,也就是specifier.
這樣,我們就需要在程式碼中,設計一個連結串列來講declarator 和 specifier連線起來,這個連結串列的程式碼如下:
public class TypeLink {
boolean isDeclarator = true; //true 那麼該object 的物件是declarator, false那麼object指向的就是specifier 這樣我們在Symbol類中,要新增兩個成員變數:
public class Symbol {
String name;
String rname;
int level; //變數的層次
boolean implicit; //是否是匿名變數
boolean duplicate; //是否是同名變數
Symbol args; //如果該符號對應的是函式名,那麼args指向函式的輸入引數符號列表
Symbol next; //指向下一個同層次的變數符號
TypeLink typeLinkBegin;
TypeLink typeLinkEnd;
}Struct 型別變數的型別系統
在Specifier 類中,最後一個成員變數StructDefine,我還沒有解釋,這個型別是專門用於處理Struct型別宣告的。由於一個結構體裡面包含了多種變數宣告,所以結構體變數的存在使得型別系統複雜了很多,我們先看看結構體變數型別的程式碼:
/*
* struct argotiers {
* int (*Clopin)();
* double Mathias[5];
* struct argotiers* Guillaume;
* struct pstruct {int a;} Pierre;
* }
*/
public class StructDefine {
private String tag; //結構體的名稱,例如上面的例子中,對應該變數的值為 "argotiers"
private int level; //結構體的間套層次
private Symbol fields; //對應結構體裡的各個變數型別
public StructDefine(String tag, int level, Symbol fields) {
this.tag = tag;
this.level = level;
this.fields = fields;
}
public String getTag() {
return tag;
}
public int getLevel() {
return level;
}
public Symbol getFields() {
return fields;
}
}
我們以一個具體的結構體宣告例子為例,看看它對應的符號表和型別系統是怎樣的:
struct argotiers {
int (*Clopin)();
double Mathias[5];
struct argotiers *Guillaume;
struct pstruct {int a;} Pierre;
} gipsy;它的型別系統如下:
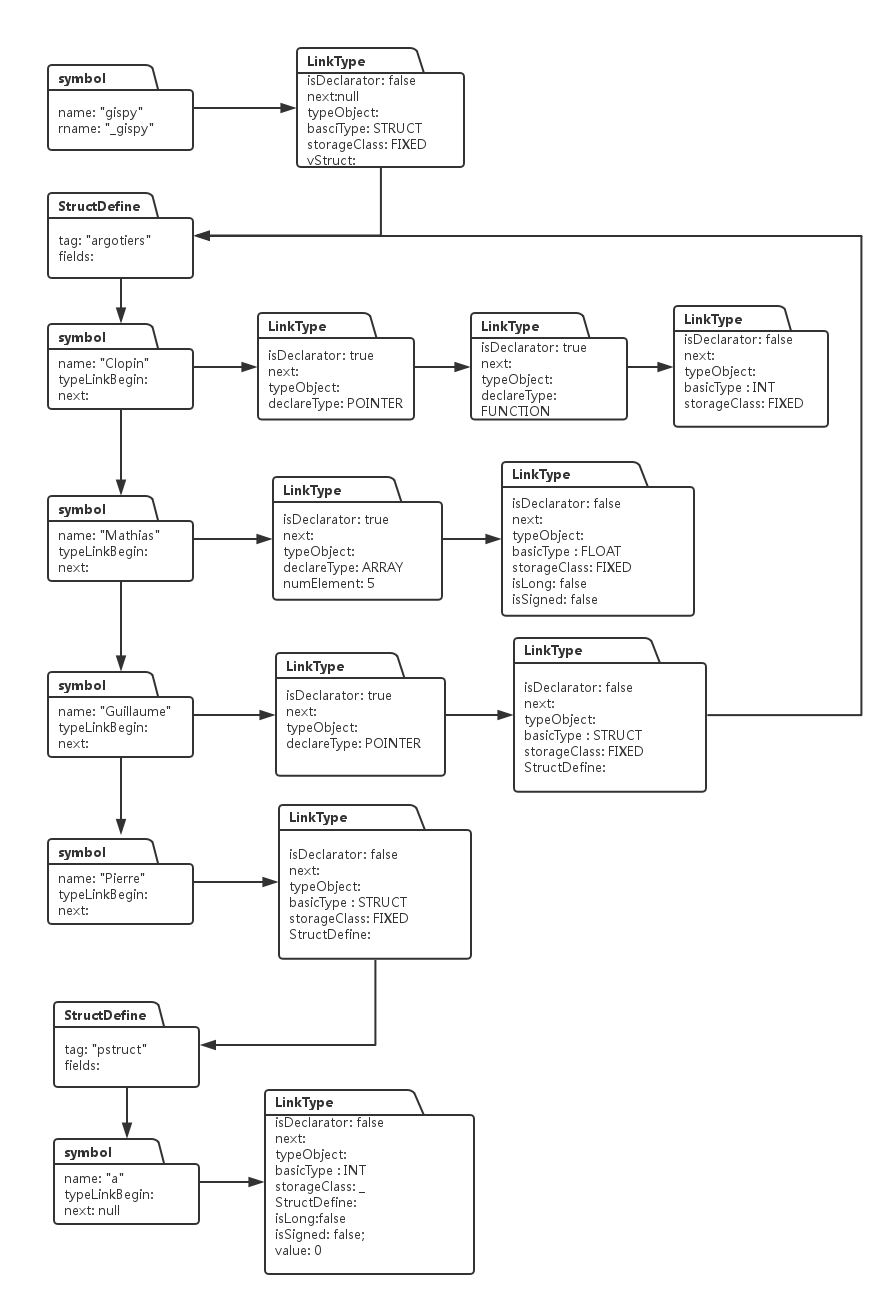
這個系統看起來似乎很複雜,但實際上它是由若干個簡單的型別系統結合而成的,搞清楚前面我們描述的型別系統佇列,對這個圖的理解應該不難,這個圖其實也表明,任何複雜的的系統,都是由多個簡單的單元相互勾連交叉所形成的。
這兩節的程式碼主要用於解釋概念,在實際開發時,我們會根據需要,對當前程式碼做相應修改,下一節,我們基於前面的變數宣告解析過程,看看語句:
long int *x, y;
所宣告的兩個變數,他們的型別系統和符號表是如何建立的。
相關推薦
C語言的符號表和型別系統2
閱讀部落格的朋友可以到我的網易雲課堂中,通過視訊的方式檢視程式碼的除錯和執行過程: 這一節,我們繼續就上一節討論的內容,繼續就符號表和型別系統的構建進行深入的探討。 基於上一節的基礎,我們看看,編譯器如何為一個變數構建它在符號表中的記錄和型別系統。假設我
符號表和型別系統的程式碼實現
前幾節,我們討論的符號表和型別系統的基本原理,這一節,我們看看如何從程式碼上實現前面我們探討的內容,畢竟,實踐才是檢驗真理的唯一標準,我們仍然基於前面說過的宣告語句: long int *x, y; 看看,在對該語句的語法解析過程中,如何構造相應的符號表
C語言——單鏈表——學生管理系統
鞏固了一下單鏈表的知識點,並運用單鏈表寫了個簡單的學生管理系統 實現功能:增、刪、改、查 #define _CRT_SECURE_NO_WARNINGS #include<stdio.h> #include<stdlib.h> #includ
c語言的指標和型別大小示例
#include <stdio.h> int main() { long *testLong; printf("%d\n",testLong); long *previous=testLong; testLong+
C語言——順序表和單鏈表的逆置
順序表的逆置 #include<stdio.h> #include<stdlib.h> #define MAX 100 typedef struct node { int num[MAX]; int length; } *Link, Node;
嵌入式系統開發人員C語言測試題(資料型別和變數)
} (40)以下程式的執行結果是______。 main() { unionEXAMPLE{ struct{ intx; inty; }in; inta; intb; }e; e.a= 1; e.b=
C語言—鄰接矩陣和鄰接表的理解
要談鄰接表,那我們先談談鄰接矩陣,因為鄰接表就是因為鄰接矩陣對於稀疏圖造成記憶體的很大浪費。那麼它是如何浪費的哪? 別急慢慢來! 什麼叫做鄰接矩陣? 它就是儲存頂點是否存在連線關係的二維陣列如下(右),關係圖(左) 解釋圖:如果a1->a2有線連線的話,用1
c語言整型和字元型的自動型別轉換
char a = -1; //機器碼為0xff unsigned char b = 254; //機器碼0xfe if (a <= b){ printf("a <= b\n"); } else{ printf("a > b\n"); } 上述程式碼輸出結果:
C語言程式設計:圖書管理系統(超詳細有登入系統,附程式碼和試驗報告)
C課程設計——圖書管理系統 1、題目意義 圖書館,作為文獻的聚集地和展示平臺,常常扮演著引領文化前進的角色,是每個大學不可或缺的基礎設施,而圖書管理系統則是一個圖書館能夠正常運轉的關鍵。本次課程設計使用C語言製作程式來實現圖書的登記,刪除,查詢,瀏覽以及讀者的借
C語言中的*和&符號
之前對*和&符號一直理解的比較淺顯。只知道: *p好像表示的是一個指標; &p表示的是一個地址。 然而這次當遇到了下面這個情況的時候: int a = 10; int *b = &a; printf(“%d\n”, a); printf(“%d\n”, &
C語言常量以及變數型別,儲存型別和作用域
變數 其值可以改變的量稱為變數。一個變數應該有一個名字,在記憶體中佔據一定的儲存單元。變數定義必須放在變數使用之前。一般放在函式體的開頭部分。要區分變數名和變數值是兩個不同的概念。 變數定義的一般形式為: 型別說明符 變數名, 變數名, ...;在書寫變數定義時,應注意以下幾點: 允許在一個型
資料結構 C語言 線性表 順序表 實現2
話不多說,先上main函式流程圖 main流程圖方便看程式進行狀態。原本是想將所有的基礎資料結構寫完以後再傳的,可我等不及了,不寫點東西就感覺啥都沒做一樣。 將程式碼集中在一個檔案了,方便傳送和閱讀一些。 #include <stdio.h> #include <stri
C語言檔案讀取和單鏈表的新增、刪除和排序等操作例項
/* 1、從文字檔案中匯入班級學生資訊:學號、姓名、性別、籍貫 2、將學號重複的刪除 3、顯示匯入的學生資訊 4、按學號、姓名、性別、籍貫相等和不相等查詢 5、多次查詢 6、查詢結果寫入檔案 7、VC++6.0編譯通過 //以下程式碼存為main.cpp */ #inclu
c語言常量變數和資料型別
常量:在程式執行過程中不被改變的量。 變數:在程式執行過程中可以被改變的量。 變數定義: 資料型別 變數名 = 常量;(初始化) 定義性宣告: 資料型別 變數名; 變數命名規則: 1、數字、字母、下劃線都可做變數名; 2、變數名的開頭不能為數字
C語言線性表的簡單建立和操作
留作學習參考 #include<stdio.h> #include<stdlib.h> #define MAXSIZE 100 typedef struct SqList *List; //建立一個結構體指標型別 指向結構體 s
在C語言裡,float型別的量和int型別的量運算時,這個表示式值的數
比方說: 2.5+3=5.500000 //向上轉型,因為float型精確度比int型高 3.5+6.4=9.900000 //兩個都是float型結果還是float 型 'a'+'b'='ab'//兩個字元相連變成了字串 char a='a';char b='b';a+
C語言中各種資料型別中所佔的位元組和取值範圍
問題:C語言資料型別取值範圍,是根據什麼定義這個範圍取值? 首先,在計算機中所有資料都是用一個一個的二進位制位(0或1)儲存的,單位稱為:位(bit);然後,每8位二進位制數(比如01010001)代表一個位元組(byte)大小,即1位元組=8位;再然後,C語言每個資料型別
c語言:把只含因子2、3和5的數稱為醜數,求按從小到大的順序的第1500個醜數(兩種方法比較)
把只含因子2、3和5的數稱為醜數,求按從小到大的順序的第1500個醜數。例如6、8都是醜數,但14不是,因為它包含因子7。習慣上把1當作第1個醜數。演算法1:逐個判斷每個整數是不是醜數的解法,直觀但不夠高效#include<stdio.h>int ugly(int
C語言中用佇列和搜尋解決"加1乘2平方問題"
描述 給定兩個正整數m、n,問只能做加1、乘2和平方這三種變化,從m變化到n最少需要幾次 輸入 輸入兩個10000以內的正整數m和n,且m小於n 輸出 輸出從m變化到n的最少次數 輸入樣例 1 16 輸出樣例
C語言中各資料型別和他們對應的最大值和最小值的常量
C中各種型別的最大值最小值常量定義在”limits.h”和”float.h”中。 CHAR_MIN和CHAR_MAX分別表示有符號小整型的最小值和最大值,UCHAR_MAX表示無符號小整型的最大值; SHRT_MIN和SHRT_MAX分別表示有符號短整型的最