
python資料分析之航空公司客戶價值分析
一.引言
本篇文章是根據航空公司提供的乘客個人資訊,通過建立合理的客戶價值評估模型,對客戶進行分群,比較分析不同客戶群的特點和價值,來指定相應的營銷策略,從而減少客戶流失,挖掘出潛在客戶,實現盈利。在這裡是用K-means聚類方法來對乘客進行分群的。
源資料部分如下圖所示:

各屬性解釋如下:

二.資料探索
通過呼叫describe()函式對資料進行一個大致的瞭解,主要是檢視缺失值和異常值。通過觀察發現,存在票價為零,折扣率為0,總飛行數為0的情況。通過簡單處理,我輸出了一個包含個屬性空值個數,最大值,最小值資料的表格。部分如下:
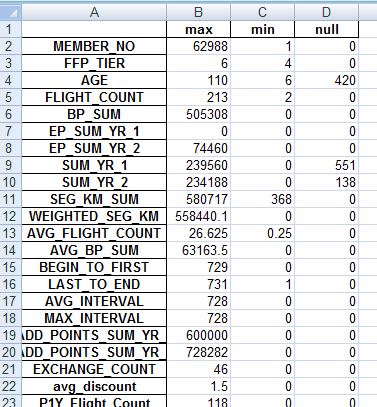
對應程式碼:
import pandas as pd datafile='D:/航空公司客戶價值分析/data/air_data2.csv' resultfile='D:/航空公司客戶價值分析/explore.xls' data=pd.read_csv(datafile) explore=data.describe().T#對資料的統計性描述,T是我進行了轉置 explore['null']=len(data)-explore['count'] df=explore[['max','min','null']] df.to_excel(resultfile)
三.資料預處理
1.資料清洗
通過上一步的資料探索分析發現數據中存在缺失值,而這一部分的比例相對較小,故直接刪掉。具體處理如下:
- 丟棄票價為空的記錄
- 丟棄票價為0,平均折扣率不為0且總飛行公里數大於零的記錄。
2.屬性規約與資料變換
原始資料中的屬性太多。而評估航空公司客戶價值通常根據LRFMC模型,與其相關的只有6個屬性即,FFP_DATE、LOAD_TIME、FLIGHT_COUNT、AVG_DISCOUNT、SEG_KM_SUM、LAST_TO_END。
簡單介紹下LRFMC模型,即客戶關係長度L、消費時間間隔R、消費頻率F、飛行里程M和折扣係數的平均值C。這五個指標為評價客戶價值的重要因素,而上面6個屬性與這5個指標的關係如下:
- L=LOAD_TIME-FFP_DATE
會員入會時間距觀測視窗結束的月數=觀測視窗結束的時間-入會時間
- R=LAST_TO_END
- F=FLIGHT_COUNT
- M=SEG_KM_SUM
- C=AVG_DISCOUNT
客戶在觀測時間內乘坐艙位所對應的折扣係數的平均值=平均折扣率
提取了相關的資料後,發現這5個指標的取值範圍相差較大所以需對資料進行標準化處理。
程式碼如下:
import pandas as pd
import datetime
#資料清洗
#刪除空值,異常值
datafile='D:/航空公司客戶價值分析/data/air_data2.csv'
resultfile='D:/航空公司客戶價值分析/data_cleaned.csv'
data=pd.read_csv(datafile)
data=data[data['SUM_YR_1'].notnull()&data['SUM_YR_2'].notnull()]#剔除掉票價為空的
#保留票價非零的或者折扣率和飛行公里數同時為0的
index1=data['SUM_YR_1']!=0
index2=data['SUM_YR_2']!=0
index3=(data['SEG_KM_SUM'])==0&(data['avg_discount']==0)
data=data[index1|index2|index3]
data.to_csv(resultfile,encoding = 'utf_8_sig')#輸出為utf8格式,不然excel開啟中文會亂碼
#屬性規約與資料變換
#根據航空公司的LRFMC價值指標,刪除掉無關屬性
d1,d2=[],[]
for x in data['LOAD_TIME']:
d1.append(datetime.datetime.strptime(x,'%Y/%m/%d'))
for y in data['FFP_DATE']:
d2.append(datetime.datetime.strptime(y,'%Y/%m/%d'))
d3=[d1[i]-d2[i] for i in range(len(d1))]
data['L']=[round((x.days/30),2) for x in d3]
data2=data[['L','LAST_TO_END','FLIGHT_COUNT','SEG_KM_SUM','avg_discount']]
data2.columns=['L','R','F','M','C']
data2.to_csv('D:/航空公司客戶價值分析/zscoredata.csv',encoding = 'utf_8_sig',index=False)輸出為:
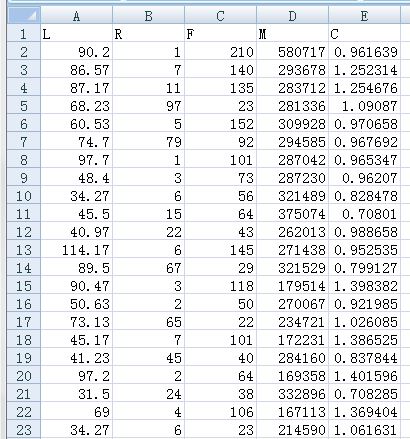
將以上資料進行零—均值標準化:
import pandas as pd
datafile='D:/航空公司客戶價值分析/zscoredata.csv'
resultfile='D:/航空公司客戶價值分析/standard_data.csv'
data=pd.read_csv(datafile)
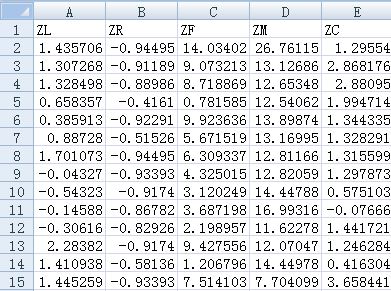
data=(data-data.mean(axis=0))/(data.std(axis=0))
data.columns=['Z'+i for i in data.columns]
data.to_csv(resultfile,encoding = 'utf_8_sig',index=False)此時輸出為:
四.模型構建
客戶價值分析模型由兩個部分構成。第一個部分是根據航空公司客戶5個指標,對客戶進行聚類分群,第二部分是對分群后的客戶群進行特徵分析,並對客戶群的客戶價值進行排名。
1.K-Means聚類演算法對客戶資料進行分群,k=5,即把客戶分成5類。k-means位於scikit-Learn庫中,需要先安裝這個庫。
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
from sklearn.externals import joblib
from sklearn.cluster import KMeans
if __name__=='__main__':#防止模組範圍內的程式碼在子程序中被重新執行,因為Windows中沒有fork()函式
datafile='D:/航空公司客戶價值分析/standard_data.csv'
resultfile='D:/航空公司客戶價值分析/kmeans.csv'
k=5
data=pd.read_csv(datafile)
#呼叫K-Means方法進行聚類分析
kmodel=KMeans(n_clusters=k,n_jobs=4)#n_jobs是並行數,一般賦值為電腦的CPU數。
# #save model
# joblib.dump(kmodel,'kmeans.model',compress=3)
# #load model to model
# model=joblib.load('kmeans.model')
kmodel.fit(data)
r1=pd.Series(kmodel.labels_).value_counts()
r2=pd.DataFrame(kmodel.cluster_centers_)
r3=pd.Series(['客戶群1','客戶群2','客戶群3','客戶群4','客戶群5',])
r=pd.concat([r3,r1,r2],axis=1)
r.columns=['聚類類別','聚類個數']+list(data.columns)
r.to_csv(resultfile,encoding = 'utf_8_sig',index=False)輸出聚類分析結果:
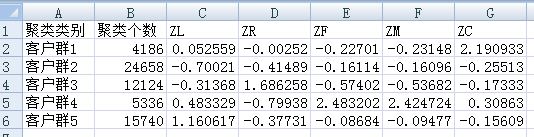
上圖可以看到各個類群的客戶個數,及聚類中心。
2.客戶價值分析
針對上面的聚類結果,對客戶進行特徵分析,繪製雷達圖。
#繪製雷達圖
labels = np.array(list(data.columns))#標籤
dataLenth = 5#資料個數
r4=r2.T
r4.columns=list(data.columns)
fig = plt.figure()
y=[]
for x in list(data.columns):
dt= r4[x]
dt=np.concatenate((dt,[dt[0]]))
y.append(dt)
ax = fig.add_subplot(111, polar=True)
angles = np.linspace(0, 2*np.pi, dataLenth, endpoint=False)
angles = np.concatenate((angles, [angles[0]]))
ax.plot(angles, y[0], 'b-', linewidth=2)
ax.plot(angles, y[1], 'r-', linewidth=2)
ax.plot(angles, y[2], 'g-', linewidth=2)
ax.plot(angles, y[3], 'y-', linewidth=2)
ax.plot(angles, y[4], 'm-', linewidth=2)
plt.rcParams['font.sans-serif']=['SimHei']
ax.legend(r3,loc=1)
ax.set_thetagrids(angles * 180/np.pi, labels, fontproperties="SimHei")
ax.set_title("matplotlib雷達圖", va='bottom', fontproperties="SimHei")
ax.grid(True)
plt.show()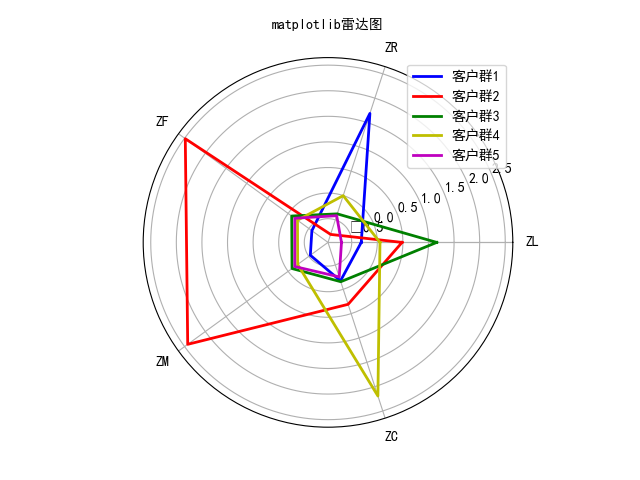
由上圖可以很清晰的看到每個客戶群的指標情況,將每個客戶群的優勢特徵,劣勢特徵總結如下:
優勢特徵:
客戶群1:R
客戶群2:F、M、L
客戶群3:L
客戶群4:C
客戶群5:無
劣勢特徵:
客戶群1:F、M
客戶群2:R
客戶群3:R、F、M、C
客戶群4:F、M
客戶群5:R、L、C
基於LRFMC模型的具體含義,我們可以對這5個客戶群進行價值排名。同時,將這5個客戶群重新定義為五個等級的客戶類別:重要保持客戶,重要挽留客戶,重要發展客戶,一般客戶,低價值客戶。- 重要保持客戶:這類客戶平均折扣率(C)和入會員時間(L)都很高(入會員時間越長,會員級別越高,折扣越大),最近乘坐過本航班時間間隔(R)低,乘坐的次數(F)或(M)高。說明他們經常乘坐飛機,且有一定經濟實力,是航空公司的高價值 客戶。對應客戶群2。
- 重要發展客戶:這類客戶平均折扣率高(C),最近乘坐過本航班時間間隔(R)短,但是乘坐的次數(F)和(M)都很低。說明這些乘客剛入會員不久,所以乘坐飛機次數少,是重要發展客戶,對應客戶群4。
- 重要挽留客戶:這類客戶入會時間長(L),最近乘坐過本航班時間間隔(R)較長,里程數和乘坐次數都變低,為重要挽留客戶。對應客戶群3
- 一般與低價值客戶:這類客戶乘坐時間間隔長(R)或乘坐次數(F)和總里程(M)低,平均折扣也很低。對應客戶群5和客戶群1.
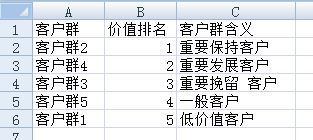
因為乘客情況是實時變動的,所以該模型並不穩定,應根據實際情況,定期更新資料,對新增的客戶資訊進行聚類分析,重新訓練模型進行調整。
相關推薦
python資料分析之航空公司客戶價值分析
一.引言 本篇文章是根據航空公司提供的乘客個人資訊,通過建立合理的客戶價值評估模型,對客戶進行分群,比較分析不同客戶群的特點和價值,來指定相應的營銷策略,從而減少客戶流失,挖掘出潛在客戶,實現盈利。在這裡是用K-means聚類方法來對乘客進行分群的。 源資料部分
資料探勘——航空公司客戶價值分析(程式碼完整)
最近在閱讀張良均、王路等人出版的書《python資料分析與挖掘實戰》,其中有個案例是介紹航空公司客戶價值的分析,其中用到的聚類方法是K-Means方法,我一直把學習的重心放在監督學習上,今天就用這個案例練習一下非監督學習。由於書上將這個案例介紹的比較詳細,導致網上的好多部落
Python資料探勘:利用聚類演算法進行航空公司客戶價值分析
無小意丶 個人部落格地址:無小意 知乎主頁:無小意丶 公眾號: 資料路(shuju_lu) 剛剛開始寫部落格,希望能保持關注,會繼續努力。 以資料相關為主,網際網路為輔進行文章釋出。 本文是《Python資料分析與挖掘實戰》一書的實戰部分,在整理分析後的復現。 本篇文
資料探勘例項(航空公司客戶價值分析)
一、實現目標 (1)藉助航空公司客戶資料,對客戶進行分類 (2)對不同的客戶進行特徵分析,比較不同類客戶的客戶價值 (3)對不同價值的客戶類別提供個性化服務,指定相應的營銷策略 二、分析方法與過程 航空客運資訊挖掘主要步驟: (1)從航空公司的資料來
航空公司客戶價值分析
air height xls 得到 3.1 amp 識別 cluster 有客 數據集:http://pan.baidu.com/s/1clfQY6 挖掘目標 (1) 根據航空公司客戶數據對客戶進行分類。 (2) 對不同的客戶類別進行特征分析,比價不同類客戶的客戶價
R——航空公司客戶價值分析
用KMeans實現航空公司客戶價值分析,程式碼如下: ###航空公司客戶價值分析 ##設定工作空間 setwd("D:/my study/R資料分析與挖掘實戰/data&code/7/上機實驗") ##資料探索分析 #資料讀取 datafile=read
實戰:航空公司客戶價值分析
一、 背景與挖掘目標 試圖實現以下目標: (1)藉助航空公司資料,對客戶進行分類。 (2)對不同類別的客戶進行特徵分析,比較不同類別客戶的價值分析。 (3)對不同價值的客戶類別進行個性化服務,制定相應的營銷策略。 二、分析方法 使用 LRMFC模型來進行分析 L: 三、資
基於R語言的航空公司客戶價值分析
#分析航空公司現狀 1.行業內競爭 民航的競爭除了三大航空公司之間的競爭之外,還將加入新崛起的各類小型航空公司、民營航空公司,甚至國外航空巨頭。航空產品生產過剩,產品同質化特徵愈加明顯,於是航空公司從價格、服務間的競爭逐漸轉向對客戶的競爭。 2.行業外競爭 隨著高鐵、動車等鐵路運輸的興建,航空公司受到
利用聚類分析航空公司客戶價值
目標: 客戶分類,比較分析不同類別客戶價值,制定相應的營銷策略 思路與流程: 分析的目標是將航空公司客戶分類,屬於無監督學習,故採用聚類挖掘模型 確定模型之後,需要選擇相應的指標,這裡指標的選擇需結合業務來確定,能夠反映客戶的關鍵特徵 確定模型和指標之
python資料分析:客戶價值分析案例實戰
簡介:本案例以電信運營商客戶資訊為資料,通過層次聚類和K-means聚類,對使用者劃分成不同的群體,然後可以根據使用者群體的不同特徵提供個性化的策略,從而達到提高ARPU的效果。 1.商業理解 根據客戶的日常消費行為,我們可以把客戶劃分為不同的群體,根據
Python Pandas 做資料分析之玩轉 Excel 報表分析
Python Pandas 是大資料分析的基礎,這裡將分享和Excel報表相關的分析技巧,都是工作中的實戰內容。 本場 Chat 主要內容: Excel、CSV 資料的讀、寫、儲存; DataFrame 的 Index、Columns 相關操作; loc、iloc、XS 和 Mul
資料探勘實戰:帶你做客戶價值分析(附程式碼)
來源:資料路本文約4000字,建議閱讀7分鐘。手把手教你利用利用KMeans聚類進行航空公司客戶
python資料型別之列表(list)和其常用方法
列表是python常用資料型別之一,是可變的,可由n = []建立,也可由n = list()建立,第一種方法更常用。 常用方法總結: # 建立方法 n = [] 或者 n = list() # index 查詢索引值 li = ['Edward', 'Mark'
python資料型別之字典(dict)和其常用方法
字典的特徵: key-value結構key必須可hash,且必須為不可變資料型別、必須唯一。 # hash值都是數字,可以用類似於2分法(但比2分法厲害的多的方法)找。可存放任意多個值、可修改、可以不唯一無序查詢速度快常用方法: info = {'stu01': 'alex', 'stu02':
python資料型別之集合(set)和其常用方法
集合是一個無序的,不重複的資料組合作用(集合的重點):1.去重,把一個列表變成集合就自動去重了2.關係測試,測試兩組資料庫之前的交集、差集、並集等關係 s = {1, 1, 2, 2, 3, 4, 'a', 'a', '!', '!'} print(type(s)) # <class 'set
Python 資料型別之 集合 set
####集合 集合是無序的,不重複的資料集合,它裡面的元素是可雜湊的(不可變型別),但是集合本身是不可雜湊(所以集合做不了字典的鍵)的。以下是集合最重要的兩點: 1.去重,把一個列表變成集合,就自動去重了。 2.關係測試,測試兩組資料之前的交集、差集、並集等關係。 #建立集合 ##建立集合 s
Python資料結構之: 棧與佇列
棧(stacks) 是一種只能通過訪問其一端來實現資料儲存與檢索的線性資料結構,具有後進先出(last in first out,LIFO)的特徵 stack = [] stack.append("A") #A入棧 stack.append("B") #B入棧 st
python資料結構之KMP演算法的實現
我相信網上已經有很多關於KMP演算法的講解,大致都是關於部分匹配表的實現思路和作用,還有就是目標串的下標不變,僅改變模式串的下標來進行匹配,確實用KMP演算法,當目標串很大模式串很小時,其效率很高的,但都是相對而言。至於對於部分匹配表的作用以及實現思路,建議看一下這篇文章寫的是比較易懂的
Python資料處理之(三)Numpy建立array
一、關鍵字 array:建立陣列 dtype:指定資料型別 zeros:建立資料全為0 ones:建立資料全為1 empty:建立資料接近0 arrange:按指定範圍建立資料 linspace:建立線段
Python資料處理之(二)Numpy屬性
簡單介紹一下numpy中常見的三個屬性: ndim: 維度 shape: 行數和列數 size: 元素個數 使用numpy首先要匯入模組,為了方便