
Python3實現常用資料標準化方法
資料標準化是機器學習、資料探勘中常用的一種方法。包括我自己在做深度學習方面的研究時,資料標準化是最基本的一個步驟。資料標準化主要是應對特徵向量中資料很分散的情況,防止小資料被大資料(絕對值)吞併的情況。另外,資料標準化也有加速訓練,防止梯度爆炸的作用。下面是從李巨集毅教授視訊中截下來的兩張圖。
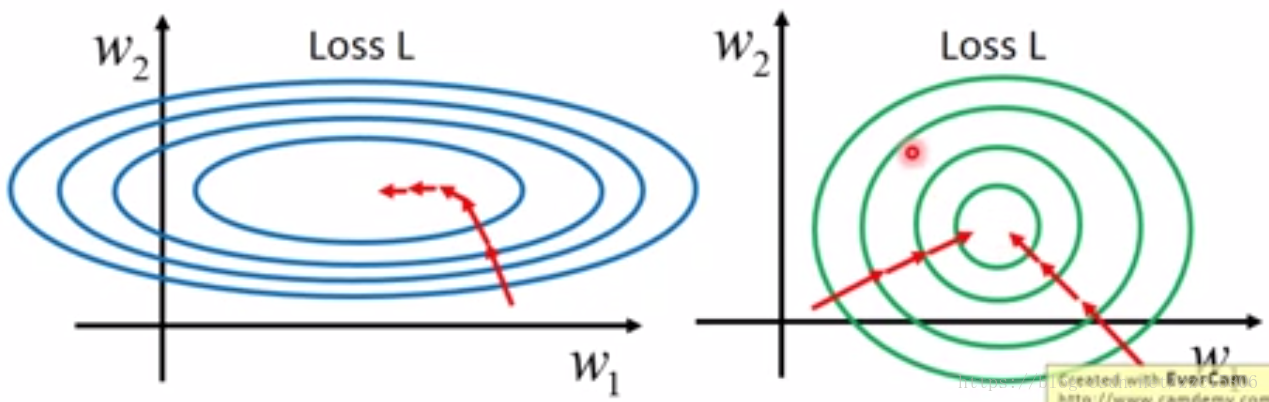
左圖表示未經過資料標準化處理的loss更新函式,右圖表示經過資料標準化後的loss更新圖。可見經過標準化後的資料更容易迭代到最優點,而且收斂更快。
一、[0, 1] 標準化
[0, 1] 標準化是最基本的一種資料標準化方法,指的是將資料壓縮到0~1之間。標準化公式如下,
程式碼實現,
def MaxMinNormalization(x, min, max):
"""[0,1] normaliaztion"""
x = (x - min) / (max - min)
return x
或者,
def MaxMinNormalization(x):
"""[0,1] normaliaztion"""
x = (x - np.min(x)) / (np.max(x) - np.min(x))
return 二、Z-score標準化
Z-score標準化是基於資料均值和方差的標準化化方法。標準化後的資料是均值為0,方差為1的正態分佈。這種方法要求原始資料的分佈可以近似為高斯分佈,否則效果會很差。標準化公式如下,
下面,我們看看為什麼經過這種標準化方法處理後的資料為是均值為0,方差為1,

程式碼實現,
def ZscoreNormalization(x, mean_, std_):
"""Z-score normaliaztion"""
x = (x - mean_) / std_
return 或者,
def ZscoreNormalization(x):
"""Z-score normaliaztion"""
x = (x - np.mean(x)) / np.std(x)
return x
【參考文獻】
相關推薦
Python3實現常用資料標準化方法
資料標準化是機器學習、資料探勘中常用的一種方法。包括我自己在做深度學習方面的研究時,資料標準化是最基本的一個步驟。資料標準化主要是應對特徵向量中資料很分散的情況,防止小資料被大資料(絕對值)吞併的情況。另外,資料標準化也有加速訓練,防止梯度爆炸的作用。下面是從李
三種常用資料標準化方法
引入 評價是現代社會各領域的一項經常性的工作,是科學做出管理決策的重要依據。隨著人們研究領域的不斷擴大,所面臨的評價物件日趨複雜,如果僅依據單一指標對事物進行評價往往不盡合理,必須全面地從整體的角度考慮問題,多指標綜合評價方法應運而生。所謂多指標綜合評價方法,就
【轉載】常用資料增強方法總結及實現
【參考資料】論文:ImageNet Classification with Deep Convolutional Neural Networks【常用方法】1、Color Jittering:對顏色的資料增強:影象亮度、飽和度、對比度變化(此處對色彩抖動的理解不知是否得當);
python3中常用的列表方法(method)
答案 列表推導 復制對象 判斷 水仙花 素數 構造 改變 ted python3中常用的列表方法(method)詳見: >>> help(list) 文檔見: python_base_docs/list_xxxx.html 深拷貝和淺拷貝淺拷貝 shall
python pandas常用資料處理方法
pandas 1、header = 0 不同於 header = None header = 0 表示 第0行為列 header = None 表示讀取的時候 認為沒有標題,全是資料 可以用 skiprows = 1 跳過列名 2、pandas 獲取指定的行列資料 df.ilo
好書丨最想推薦給程式設計師們看的基於Python3實現的資料科學書
點選上方“程式人生”,選擇“置頂公眾號”第一時間關注程式猿(媛)身邊的故事參與文末話題討論,有機
這是我最想推薦給程式設計師們看的基於Python3實現的資料科學書
點選關注非同步圖書,置頂公眾號每天與你分享IT好書 技術乾貨 職場知識參與文末話題討論,每日贈送非同步圖書。——非同步小編和武俠世界裡有少林和武當兩大門派一樣,資料科學領域也有兩個不同的學派:以統計分析為基礎的統計學派,以及以機器學習為基礎的人工智慧派。雖然這兩個學派
Python3常用資料結構及方法介紹(三)——字串
三.字串 特點:不可更改 1.基本操作(同其他序列) ①索引 >>> 'python'[2] 't' ②分片 >>> 'beauty'[0:2] 'be' >>> 'beauty'[::2] 'bat' ③相加/相乘
Python3常用資料結構及方法介紹(二)——元組
二.元組 tuple 1特點: ①元組不可更改 ②圓括號 ③可重新賦值 >>> tuple0=(1,2,3) >>> tuple0=(2,3,4,1) >>> tuple0 (2, 3, 4, 1) 2常用元組操作(與列表類
Python3常用資料結構及方法介紹(一)——列表
一.列表 list 1特點: ①列表可更改 ②方括號 [1, 2, 3] 2常用列表操作: ①索引: >>> list1 = [1,2,3,4,5,6,7,8,9,10] >>> list1[4] 5 ②分片: >>>
Hive實現資料抽樣的常用三種方法
背景 在大規模資料量的資料分析及建模任務中,往往針對全量資料進行挖掘分析時會十分耗時和佔用叢集資源,因此一般情況下只需要抽取一小部分資料進行分析及建模操作。 Hive提供了資料取樣(SAMPLING)的功能,能夠根據一定的規則進行資料抽樣,目前支援資料塊抽樣,分桶抽樣和隨機
jQuery實現的ajax操作(最常用的json方法)
add mage jquer clas load rgba 方法 htm 9.png load(url, [data], [callback])1 獲取HTML傳輸格式的數據: load(url, [data], [callback]) ( 可以設置選擇器)2 獲取xml傳
常用標準化方法
score a20 block 一個 col https 最大值 討論 學習 常用標準化方法 覺得有用的話,歡迎一起討論相互學習~Follow Me 原創文章,如需轉載請保留出處 Z-scores 把數值標準化到Z分數。標準化後的變量均值為0,標準差為1。系統將每一個值
python3 常用資料型別轉換語法
python3 常用資料型別轉換語法 函式 說明 int(x [,base ]) 將x轉換為一個整數 long(x [,base ]) 將x轉換為一個長整數 float(x ) 將x轉換到一個浮點數 complex(real [,imag ]) 建立一個複數 str(x ) 將物件 x 轉換
JS實現陣列去重方法總結(三種常用方法)
方法一: 雙層迴圈,外層迴圈元素,內層迴圈時比較值 如果有相同的值則跳過,不相同則push進陣列 Array.prototype.distinct = function(){ var arr = this,result = [], i,j,len = arr.length; f
C# ListBox實現顯示插入最新的資料的方法
原文:C# ListBox實現顯示插入最新的資料的方法 在我們使用ListBox控制元件時,如果我們在裡面不斷的新增一條條資料,但是在我們新增的資料過多超過了ListBox顯示的視窗時(此時會產生滑動條), 發現我們無法看到最新新增的資料。實現倒序顯示此處有兩種方法: //第一種,使用lis
李巨集毅機器學習 P12 HW2 Winner or Loser 筆記(不使用框架實現使用MBGD優化方法和z_score標準化的logistic regression模型)
建立logistic迴歸模型: 根據ADULT資料集中一個人的age,workclass,fnlwgt,education,education_num,marital_status,occupation等資訊預測其income大於50K或者相反(收入)。 資料集: ADULT資料集。
django中常用的資料查詢方法
5.2 資料查詢 要從資料庫檢索資料,首先要獲取一個*查詢集***(QuerySet),查詢集表示從資料庫獲取的物件集合,它可以有零個,一個或多個過濾器。返回查詢集的方法,稱為過濾器,過濾器根據給定的引數縮小查詢結果範圍,相當於sql語句中where或limit。 在管理器上
資料特徵 歸一化/標準化 方法
歸一化/標準化 定義 歸一化:就是將訓練集中數值特徵的值縮放到0和1之間。公式如下 標準化:就是將訓練集中數值特徵的值縮放成均值為0,方差為1的狀態。公式如下 需要先計算出均值和標準差,下面是標準差的計算公式 μ表示均值,x*表示標準化的表示式 優點
Java實現陣列去除重複資料的方法詳解
一.用List集合實現 int[] str = {5, 6, 6, 6, 8, 8, 7,4}; List<Integer> list = new ArrayList<Integer>(); for (int i=0; i<str.length; i++) { if(