
Show and Tell: A Neural Image Caption Generator 翻譯
摘要
自動描述影象的內容是連線計算機視覺和自然語言處理的人工智慧中的一個基本問題。在本文中,我們提出了一個基於深度重構架構的生成模型,它結合了計算機視覺和機器翻譯方面的最新進展,可以用來生成描述影象的自然語句。訓練該模型以最大化訓練影象給出的目標描述句子的可能性。在幾個資料集上的實驗顯示模型的準確性和它從影象描述中學到的語言的流暢性。我們的模型通常是相當準確的,我們從定性和定量兩方面進行驗證。例如,Pascal資料集當前最先進的BLEU-1得分(越高越好)為25,我們的方法得到59,與69的人類表現相比較。我們還顯示了BLEU-1 Flickr30k從56分改善到66分,SBU從19分改善到28分。最後,在新發布的COCO資料集中,我們實現了27.7的BLEU-4,這是當前最先進的技術。

介紹
能夠使用適當形成的英文句子自動描述影象的內容是一項非常具有挑戰性的任務,但它可能會產生很大的影響,例如幫助視障人士更好地理解網路上的影象內容。比起經過深入研究的影象分類或目標識別任務來說,這個任務要困難得多,而這個任務一直是計算機視覺領域的主要焦點[27]。事實上,描述不僅要捕捉影象中包含的物件,還必須表達這些物件如何相互關聯,以及它們的屬性和所涉及的活動。此外,上述語義知識必須用英語這樣的自然語言表達,這意味著除了視覺理解之外還需要一種語言模型。
大多數以前的嘗試已經提出將上述子問題的現有解決方案縫合在一起,以便從影象到其描述[6,16]。與此相反,我們想在這個工作中提出一個單一的聯合模型,將影象I作為輸入,並且訓練使得生成目標詞序列S = {S1,S2,…,}每個詞St來自一個給定的字典,它充分地描述了影象。
我們工作的主要靈感來自機器翻譯方面的最新進展,其中的任務是將用源語言編寫的句子S翻譯成目標語言的翻譯T,通過最大化p(T | S) 。多年來,機器翻譯也是通過一系列單獨的任務(單獨翻譯單詞,調整單詞,重新排序等)來實現的,但最近的工作表明,翻譯可以用一種更簡單的方法來完成,目前的神經網路(RNNs)[3,2,30]仍然達到了最先進的效能。 “編碼器”RNN讀取源語句並將其轉換為豐富的固定長度向量表示,該表示又被用作生成目標語句的“解碼器”RNN的初始隱藏狀態。
在這裡,我們建議遵循這個優雅的配方,用深度卷積神經網路(CNN)代替編碼器RNN。在過去的幾年裡,已經有說服力的證明CNN可以通過將輸入影象嵌入到一個固定長度的向量中來產生豐富的輸入影象表示,這樣這個表示就可以用於各種視覺任務[28]。因此,使用CNN作為影象“編碼器”是很自然的,首先對影象分類任務進行預訓練,並使用最後一個隱藏層作為生成語句的RNN解碼器(見圖1)的輸入。我們稱這個模型為神經影象標題或NIC。
我們的貢獻如下。首先,我們提出一個端到端的問題系統。它是一個使用隨機梯度下降完全可訓練的神經網路。其次,我們的模型結合了用於視覺和語言模型的最先進的子網路。這些可以在更大的語料庫上預先訓練,從而可以利用額外的資料。最後,與最先進的方法相比,它的效能顯著提高;例如,在Pascal資料集上,NIC產生了59的BLEU得分,與目前的最新技術25比較,而人的成績達到69.在Flickr30k上,我們從56提高到66, SBU,從19日至28日。
相關工作
從視覺資料中產生自然語言描述的問題早已在計算機視覺中被研究,但主要是視訊[7,32]。這導致由視覺原始識別器組成的複雜系統與結構化形式語言(例如,圖形或邏輯系統,通過基於規則的系統進一步轉換為自然語言。這樣的系統手工設計很重,相對較脆,只能在有限的領域進行演示,例如交通場景或運動。
自然文字靜止影象描述的問題近來越來越受到關注。利用最近的物件識別,它們的屬性和位置,我們可以驅動自然語言生成系統,儘管這些系統的表達能力有限。 Farhadi等人[6]使用檢測來推斷場景元素的三元組,使用模板將其轉換為文字。同樣,李等人[19]從檢測開始,並使用包含檢測到的物件和關係的短語拼湊出最終的描述。 Kulkani等人使用了一個更復雜的超越三元組的檢測圖。 [16],但與基於模板的文字生成。基於語言分析的更強大的語言模型也被使用[23,1,17,18,5]。上述方法已經能夠比較簡單地描述影象了,但是在文字生成方面,它們是大量手工設計的和僵化的。
大量工作已經解決了給定影象的等級描述問題[11,8,24]。這種方法基於將影象和文字共同嵌入到相同向量空間的想法。對於影象查詢,檢索位於嵌入空間中靠近影象的描述。最近,神經網路被用來共同嵌入影象和句子[29],甚至影象作物和子句[13],但不試圖產生新穎的描述。一般來說,上述方法不能描述以前看不見的物件組合,即使在訓練資料中可能已經觀察到單個物件。此外,他們避免解決評估生成的描述有多好的問題。
在這項工作中,我們將用於影象分類的深度卷積網路[12]與用於序列建模的遞迴網路相結合[10],以建立一個生成影象描述的單一網路。 RNN是在這個單一的“端到端”網路的背景下進行培訓的。這個模型受到機器翻譯中最近成功的序列生成的啟發[3,2,30],不同之處在於我們不是從一個句子開始,而是提供一個由一個卷積網處理的影象。最近的作品是由Kiros等人[15]使用一個前饋神經網路,預測下一個字給出的影象和歷史單詞。毛等人最近的工作是 [21]使用一個RNN來做相同的預測任務。這與目前的提議非常相似,但是有一些重要的不同之處:我們使用更強大的RNN模型,並直接提供RNN模型的視覺輸入,這使得RNN能夠跟蹤已經被文中解釋了。由於這些看似微不足道的差異,我們的系統在既定的基準上取得了更好的結果。最後,Kiros等人[14]通過使用強大的計算機視覺模型和編碼文字的LSTM來構建聯合多模態嵌入空間。與我們的方法相反,他們使用兩個單獨的路徑(一個用於影象,一個用於文字)來定義聯合嵌入,並且即使他們可以生成文字,他們的方法也被高度調整以用於排序。
模型
在本文中,我們提出了一個神經和概率框架來從影象生成描述。統計機器翻譯的最新進展表明,給定一個強大的序列模型,可以通過直接最大化正確翻譯的概率來獲得最新的結果, 這個端到端的系統可以用來訓練和推理。這些模型利用遞迴神經網路將可變長度輸入編碼成一個固定的維向量,並使用這種表示將其“解碼”為期望的輸出句子。因此,使用相同的方法是自然的,在給定影象(而不是源語言的輸入句子)的情況下,使用相同的原理將其“翻譯”到其描述中。
因此,我們建議通過使用以下公式直接最大化正確描述的概率:
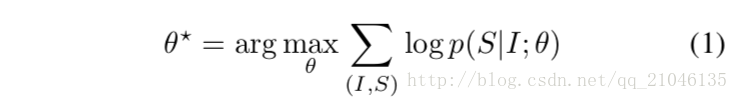
其中θ是我們模型的引數,I是影象,S是它的正確翻譯。由於S代表任何一個句子,它的長度是無限的。因此,應用鏈規則來模擬S0…SN上的聯合概率是很常見的,其中N是這個特定例子的長度。
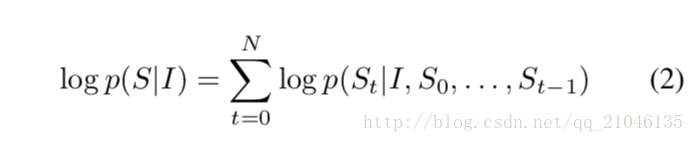
為了方便,我們放棄了對θ的依賴。在訓練時,(S,I)是一個訓練樣本對,我們使用隨機梯度下降在整個訓練集上優化(2)中所述的對數概率之和(更多的訓練細節在第4節中給出)。
使用Re-current神經網路(RNN)對p(St | I,S0,…,St-1)進行建模是自然的,其中,直到t-1為止的可變詞數由a固定長度隱藏狀態或記憶體ht。通過使用非線性函式f來檢視新的輸入xt後,該ht被更新:
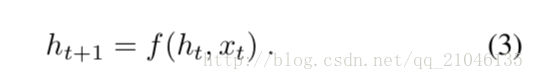
為了使上面的RNN更加具體,我們要做出兩個關鍵的設計選擇:f的確切形式是什麼,以及如何輸入影象和文字作為輸入。對於f,我們使用了一個長短期記憶(LSTM)網路,該網路在翻譯等順序任務上表現出了最先進的效能。這個模型在下一節中概述。
為了表示影象,我們使用卷積神經網路(CNN)。它們已經被廣泛地用於影象任務並被研究,並且是當前用於物件識別和檢測的技術。我們對CNN的特殊選擇使用了一種新穎的批量標準化方法,並且在ILSVRC 2014分類競賽中獲得了當前的最佳效能[12]。此外,他們已被證明推廣到其他任務,如場景分類通過轉移學習[4]。單詞用嵌入模型表示。
3.1 基於LSTM的句子生成器
公式(3)中的f的選擇取決於其處理消失和爆炸梯度的能力[10],這是RNN設計和訓練中最常見的挑戰。為了應對這一挑戰,引入了一種稱為LSTM的特殊形式的迴圈網路[10],並在翻譯[3,30]和序列生成[9]中取得了巨大的成功。
LSTM模型的核心是一個儲存單元,它在每個時間步驟編碼知識,在這個步驟之前觀察到什麼輸入(見圖2)。單元的行為是由“門”控制的 - 這些層是多重應用的,因此如果門是1,則可以從門控層保留一個值,如果門是0,則該值為零。特別地,三個門正在被用來控制是否忘記當前的單元格值(忘記門f),是否應該讀取其輸入(輸入門i)以及是否輸出新的單元格值(輸出門o)。門和單元更新和輸出的定義如下:
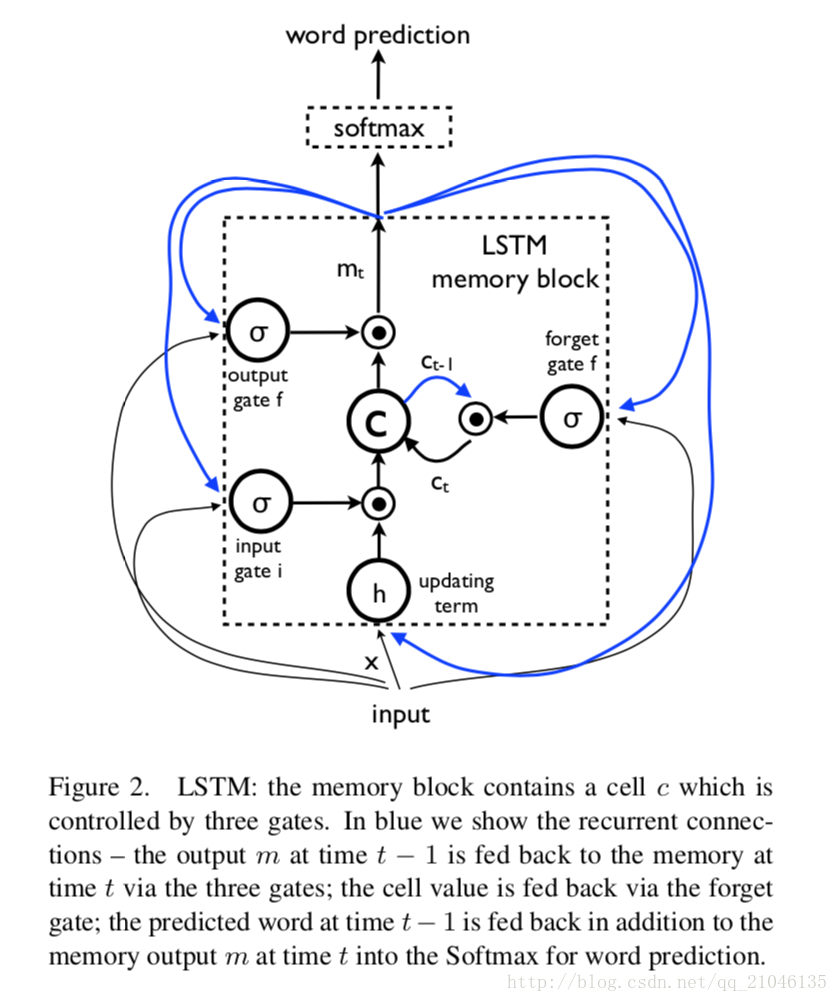
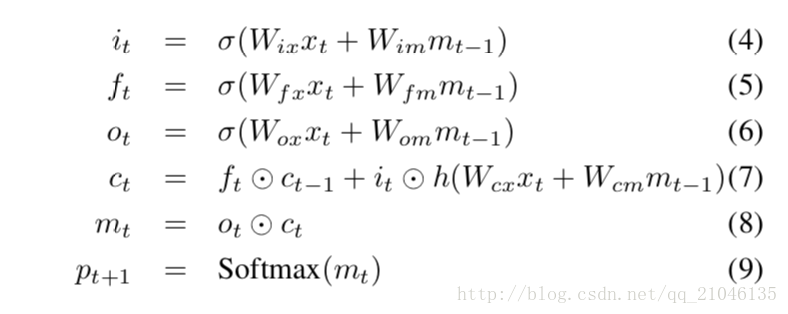
其中⊙表示具有門值的乘積,各種W矩陣是訓練引數。這樣的多重門可以對LSTM進行強有力的訓練,因為這些門可以很好地處理爆炸和消失的梯度[10]。非線性是sigmoidσ(·)和諧波正切h(·)。最後一個等式mt是用來饋給Softmax的,它將在所有的單詞上產生一個概率分佈pt。
訓練LSTM模型被訓練以預測在句子看到影象之後的每個單詞以及由p(St | I,S0,…,St-1)定義的所有在前單詞。為此,以非卷積形式考慮LSTM是有益的 - 為影象和每個句子單詞建立LSTM儲存器的副本,使得所有LSTM共享相同的引數,並且LSTM的輸出mt-1在timet-1被設定為LSTMattimet(見圖3)。所有經常性連線都轉換為展開版本的前饋連線。更詳細地說,如果用I表示輸入影象,用S =(S0,…,SN)表示描述這個影象的真實句子,則展開過程如下:
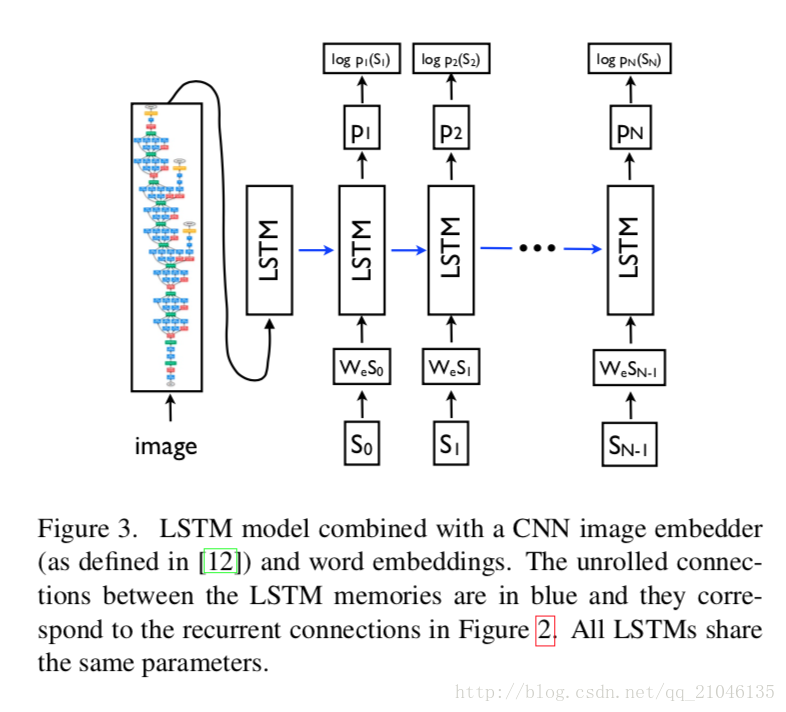
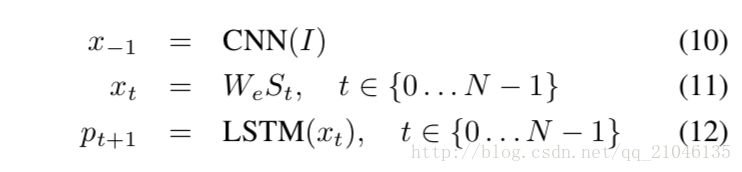
在這裡我們將每個單詞表示為一個與字典大小相等的單向量向量St。注意,我們用S0表示開始單詞,用SN表示句子的結束單詞。如果停用詞生成,LSTM表示已經產生了完整的句子。影象和單詞都對映到同一個空間,影象通過使用視覺CNN,單詞通過使用單詞嵌入我們。影象I只在t = -1時輸入一次,以通知LSTM影象內容。我們經驗證實,在每個時間步將影象饋送作為額外輸入產生較差的結果,因為網路可以明確地利用影象中的噪聲並且更容易過濾。
我們的損失是每個步驟中正確單詞的負對數可能性的總和,如下所示:
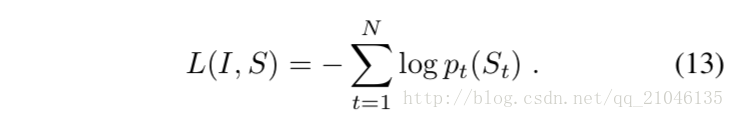
上面的損失是最小化的。 LSTM的所有引數,影象嵌入器CNN的頂層和單詞嵌入我們。
推論有多種方法可以用來生成給定影象的句子,使用NIC。第一個是抽樣,我們只是根據p1對第一個單詞進行取樣,然後提供相應的嵌入作為輸入和樣本p2,如此繼續,直到我們取樣特殊的句末標記或一些最大長度。第二個是BeamSearch:迭代地考慮直到時間t的k個最佳句子的集合作為生成大小為t + 1的句子的候選者,並且僅保留它們的結果最好的k。這更接近S = arg maxS’p(S’| I)。我們在下面的實驗中使用了 BeamSearch 方法,使用了 20 的光束。使用1的光束尺寸(即貪心搜尋)平均降低了2個BLEU點的結果。
評估指標
儘管有時不清楚描述是否被認為是成功的,但是現有技術已經提出了一些評估指標。最可靠(但費時)的方法是要求評估人員根據影象的每個描述的有用性給出主觀評分。在本文中,我們使用這個來強化一些自動度量確實與這個主觀評分相關,遵循[11]中提出的指導方針,要求評分者評估每個生成的句子從1到41。
對於這個指標,我們建立了一個Amazon Mechanical Turk實驗。每幅影象由2名工人評定。工人之間的相同意見的概率是65%,而如果意見不一致,我們只是將分數平均,並將平均值記錄為分數。對於方差分析,我們執行自舉(對重新取樣結果進行重新取樣,替換和計算方法/標準偏差)。像[11]一樣,我們報告的分數大於或等於一組預定義的閾值。
剩下的指標可以自動計算,假設一個人可以訪問groundtruth,即人類生成的描述。到目前為止在影象描述文獻中最常使用的度量是BLEU得分[25],這是生成的和參考句子2之間的單詞n-gram的精確度的形式。儘管這個度量具有一些明顯的缺點,被證明與人類評估有很好的相關性。在這項工作中,我們也證實了這一點,正如我們在4.3節中所展示的那樣。一個廣泛的評估協議,以及我們的系統產生的輸出,可以在http:// nic.droppages.com/找到。
除了BLEU之外,還可以將模型的困惑用於給定的翻譯(這與我們在(1)中的目標函式密切相關)。困惑是每個預測詞的逆概率的幾何平均值。我們使用這個度量來進行關於模型選擇和超引數調整的選擇,但是我們並不報告它,因為BLEU總是首選的。關於度量的更詳細的討論可以在[31]中找到,研究這個課題的研究小組已經報告了其他一些被認為更適合評估標題的指標。我們報告了兩個這樣的度量標準 - ME- TEOR和Cider - 希望在度量的選擇上進行更多的討論和研究。
最後,目前關於影象描述的文獻也已經使用了代理任務來對給定的影象進行一系列可用的描述(參見例項[14])。這樣做的好處是可以使用像recall @ k這樣已知的排名指標。另一方面,將描述生成任務轉換為排序任務是不令人滿意的:隨著描述影象的複雜性增長,連同其字典一起,可能的句子數隨著字典的大小呈指數增長,一個預定義的句子將適合一個新的形象將下降,除非這些句子的數量也呈指數增長,這是不現實的;更不用說為每幅影象有效地評估這樣一個龐大的語料庫所蘊藏的計算複雜性。在語音識別中已經使用了相同的論點,其中必須產生對應於給定聲音序列的語句;雖然早期的嘗試集中於分離孤立的音素或單詞,但是這項任務的最新方法現在是生成性的,可以從一個大的詞典中產生句子。
現在我們的模型可以生成合理的質量描述,儘管評估影象描述的含糊性(可能有多個有效的描述不在實際中),我們相信我們應該專注於生成任務的評估指標,而不是排行。
4.2 資料集
為了評估,我們使用許多由英文影象和句子組成的資料集來描述這些影象。
資料集的統計如下:
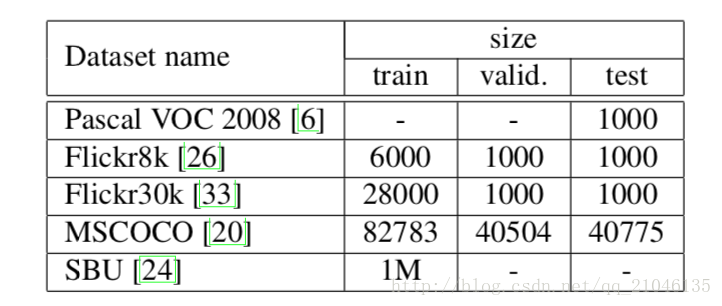
除了SBU之外,每張圖片都有5個相對直觀和不偏倚的標籤。 SBU由圖片所有者在將圖片上傳到Flickr時進行描述。因此,他們不能保證是視覺的或無偏見的,因此這個資料集有更多的噪音。
Pascal資料集通常用於測試系統是否在不同資料(例如其他四個資料集中的任何一個)上進行過訓練。在SBU的情況下,我們分出了1000個影象進行測試,並在[18]中使用其餘的訓練。同樣,我們從MSCOCO驗證集中保留4K個隨機影象作為測試,稱為COCO-4k,並用它在下一節中報告結果。
4.3 結果
由於我們的模型是端到端的資料驅動和訓練,並且考慮到大量的資料集,我們想要回答諸如“資料集大小如何影響泛化”,“可以進行什麼型別的傳輸學習達到“,”如何處理弱標記的例子“。因此,我們在5個不同的資料集上進行了實驗,在第4.2節中進行了解釋,這使我們能夠深入理解我們的模型。
4.3.1訓練細節
我們在訓練模型時面臨的許多挑戰都與過度擬合有關。事實上,純監督的方法需要大量的資料,但高質量的資料集少於10萬個影象。分配描述的任務比物件分類嚴格得多,而且資料驅動方法最近才成為主導,這要歸功於像ImageNet那樣大的資料集(資料量比我們在本文中描述的資料集要多十倍,SBU除外)。因此,我們相信,即使我們獲得的結果相當好,但隨著訓練集規模的增長,我們的方法相對於大多數當前人為工程方法的優勢只會在未來幾年內增加。
儘管如此,我們還是探索了一些處理過度擬合的技巧。最顯眼的方法是將我們系統的CNN分量的權重初始化為預訓練模型(例如,在ImageNet上)。我們在所有的實驗中都做了這個(類似於[8]),在泛化方面確實有很大的幫助。另一組可以明智地初始化的權重是We,嵌入這個詞。我們嘗試從一個大型新聞語料庫中初始化它們[22],但沒有觀察到顯著的收益,為了簡單起見,我們決定將它們初始化。最後,我們做了一些模型級別的過度擬合避免技術。我們嘗試 dropout [34]和 ensembling 模型,以及通過折算隱藏單元的數量與深度來探索模型的大小(即容量)。輟學和加班給了一些BLEU點的改善,這是我們在整個報告中報告。
我們用隨機梯度下降法來訓練所有權重集,其固定學習率和無動量。所有的權重都是隨機初始化的,除了CNN的權重,我們保持不變,因為改變它們有負面的影響。我們使用了512個維度來定義LSTM記憶單元的大小。
描述用基本的標記化進行預處理,保留所有在訓練集中出現至少5次的單詞。
4.3.2生成結果
我們在表1和2中的所有相關資料集上報告了我們的主要結果。由於PASCAL沒有訓練集,我們使用了使用MSCOCO訓練的系統(可以說是該任務的最大和最高質量的資料集)。
PASCAL和SBU的最新成果沒有使用基於深度學習的影象特徵,所以可以說這些分數的一個重大改進來自單獨的改變。 Flickr資料集最近已被使用[11,21,14],但主要是在檢索框架中進行評估。一個值得注意的例外是[21],他們在這裡進行了檢索和生成,並且在Flickr資料集上得到了最好的效能。
表2中的人類評分是通過比較其中一個人類標題和其他四個人物來計算的。我們為五個評估者中的每一個評估,並平均評估他們的BLEU分數。由於這給我們的系統帶來了輕微的優勢,因為BLEU得分是用五個參考句子而不是四個來計算的,所以我們把五個參考而不是四個的平均差值加回到人類得分。
鑑於過去幾年這個領域已經取得了顯著的進展,我們認為報告BLEU-4這個機器翻譯標準是更有意義的。此外,我們報告了與表14中的人類評估更好地相關的指標。
儘管最近在更好的評估指標方面做出了努力[31]但是,當使用人評估者評估我們的標題時(參見第4.3.6節),我們的模型的表現要差得多,這意味著需要更多的工作來實現更好的指標。在正式的測試集上,只有官方網站才能提供標籤,我們的模型有27.2個BLEU-4。
4.3.3遷移學習,資料大小和標籤質量
由於我們已經訓練了許多模型,並且我們有多個測試集,所以我們想研究是否可以將模型轉移到不同的資料集,以及域中的不匹配將被補償多少。更高質量的標籤或更多的培訓資料。
傳輸學習和資料大小最明顯的情況是在Flickr30k和Flickr8k之間。兩個資料集的標籤類似,都是由同一組建立的。事實上,當使用Flickr30k進行訓練(大約有4倍以上的訓練資料)時,得到的結果更好的是4 BLEU點。很顯然,在這種情況下,我們看到增加了更多的訓練資料,因為整個過程是資料驅動和過度擬合的傾向。 MSCOCO甚至更大(比Flickr30k多5倍的訓練資料),但是由於收集過程是不同的,因此詞彙可能會有更多的差異,並且會有更大的不匹配。事實上,所有的BLEU分數都降低了10分。儘管如此,這些描述仍然是合理的。
由於PASCAL沒有正式的訓練集,獨立於Flickr和MSCOCO收集,我們向MSCOCO 報告轉移學習(見表2)。使用Flickr30k進行轉換學習的結果與 BLEU-1的53(參見59)相比更差。
最後,雖然SBU的標籤很薄弱(即標籤是標題而不是人為的描述),但是更大更嘈雜的音色則更加困難。但是,更多的資料可用於培訓。在 SBU 上執行MSCOCO模型時,我們的效能會從 28 降低到 16。
4.3.4生成多樣性討論
通過訓練生成 p(S | I)的生成模型,一個明顯的問題是模型是否產生新穎的標題,以及生成的標題是否多樣和高質量。表3顯示了從我們的波束搜尋解碼器中返回N個最佳列表的一些樣本,而不是最好的假設。
請注意,樣本是多樣的,可能會顯示來自同一影象的不同方面。 BLEU 得分在前15 個生成句子之間的一致性是 58,這與其中的人類相似。這表明我們的模型產生的多樣性的數量。粗體是訓練集中不存在的句子。
如果我們選出最好的候選句子,那麼這個句子就會在80%的時間裡出現在訓練集中。考慮到訓練資料量非常小,這並不令人感到意外,因此模型選擇“exemplar”句子並用它們生成描述相對比較容易。如果我們反過來分析前15個生成的句子,大約一半的時間我們看到一個完全新穎的描述,但是仍然具有相似的BLEU得分,表明它們具有足夠的質量,但是它們提供了健壯的多樣性。

4.3.5 排名結果
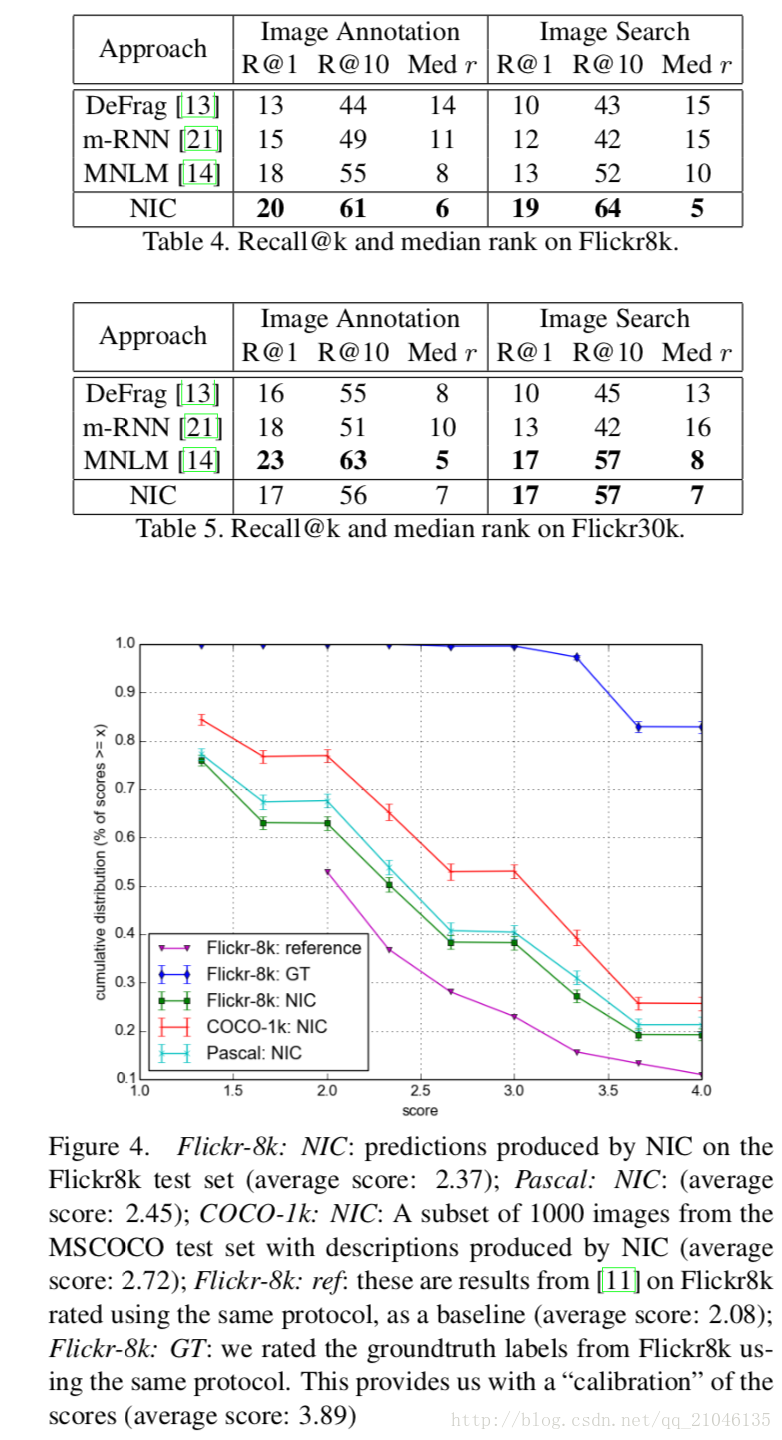
雖然我們認為排名是一種評價影象描述生成的不滿意方式,但是許多論文都會報告排名分數,並使用一組測試字幕作為候選排名給出測試影象。 在這些指標(MNLM)上效果最好的方法,特別實施了排名感知損失。 儘管如此,NIC在排序任務(給定影象的排名描述和給出描述的排名影象)方面表現出色,如表4和表5所示。注意,對於影象註釋任務,我們將得分類似於 什麼[21]使用。
4.3.6人的評估
圖4顯示了NIC提供的描述的人工評估結果,以及各種資料集的參考系統和實地測試結果。我們可以看到,NIC比參照系統要好,但顯然比預期的要糟糕。這表明BLEU不是一個完美的度量標準,因為它不能很好地捕捉評估者評估NIC和人類描述之間的差異。額定影象的例子可以在圖5中看到。有趣的是,例如在第一列的第二個影象中,看到模型如何能夠注意到飛盤的大小。

4.3.6人的評估
圖4顯示了NIC提供的描述的人工評估結果,以及各種資料集的參考系統和實地測試結果。我們可以看到,NIC比參照系統要好,但顯然比預期的要糟糕。這表明BLEU不是一個完美的度量標準,因為它不能很好地捕捉評估者評估NIC和人類描述之間的差異。額定影象的例子可以在圖5中看到。有趣的是,例如在第一列的第二個影象中,看到模型如何能夠注意到飛盤的大小。
4.3.7嵌入分析
為了表示前一個字St-1作為產生St的解碼LSTM的輸入,我們使用了字嵌入向量[22],它具有獨立於字典大小的優點(與簡單的單向字典相反,熱編碼方法)。而且,這些詞彙嵌入可以與模型的其餘部分一起進行聯合訓練。看到學習的表示如何從語言的統計中捕捉到一些語義,這是非常了不起的。表4.3.7顯示了一些例子中最接近的學習嵌入空間中的其他單詞。
請注意,模型學習到的一些關係將如何幫助視覺元件。事實上,將“馬”,“小馬”和“驢”彼此靠近將鼓勵CNN提取與馬匹動物相關的特徵。我們假設,在極少數情況下,我們看到一個例子(例如,“獨角獸”),它接近其他詞嵌入(如“馬”)應提供更多的資訊,將完全失去更傳統的基於書包的方法
5.結論
我們已經提出了NIC,這是一個端到端的神經網路系統,可以自動檢視影象並以簡單的英文生成合理的描述。 NIC基於一個卷積神經網路,該網路將影象編碼成一個緊湊的表示,然後是一個迴圈的神經網路,產生相應的句子。訓練該模型以最大化給予該影象的句子的可能性。幾個資料集實驗表明NIC的魯棒性的定性結果來(生成的句子是非常合理的)和定量的評價,無論是使用排名指標或BLEU,在馬折角翻譯使用的指標來評價生成仙的質量 - 尖叫從這些實驗中可以清楚地看出,隨著用於影象描述的可用資料集的大小增加,像NIC這樣的方法的效能也會提高。此外,看看如何使用無監督的資料,無論是單獨使用影象還是單獨使用文字,都可以改善影象描述方法。
相關推薦
Show and Tell: A Neural Image Caption Generator 翻譯
摘要 自動描述影象的內容是連線計算機視覺和自然語言處理的人工智慧中的一個基本問題。在本文中,我們提出了一個基於深度重構架構的生成模型,它結合了計算機視覺和機器翻譯方面的最新進展,可以用來生成描述影象的自然語句。訓練該模型以最大化訓練影象給出的目標描述句子的可能
Show, Attend and Tell: Neural Image Caption Generation with Visual Attention 閱讀筆記
0 模型在做什麼 圖0-0 Image Caption效果簡介 本文介紹的模型,將圖片資訊與相應的文字資訊進行結合,在預測文字中相應單詞的時候不同的影象區域被啟用 如在圖0-0 第一對圖片中,當用於生成句子中的dog單詞時,圖片中狗相關的區域變的高亮 類似的第二張
論文筆記:Image Caption(Show and Tell)
Show and Tell: A Neural Image Caption Generator Show and Tell 1、四個問題 要解決什麼問題? Image Caption(自動根據影象生成一段文字描述)。 用了什麼方法
Build and train a neural net from scratch in Python
Deep learning frameworks like TensorFlow or PyTorch are being used with some frequency. but using such a framework hides a lot of internals which can help
論文筆記:Image Caption(Show, attend and tell)
Show, Attend and Tell: Neural Image Caption Generation with Visual Attention Show, Attend and Tell 1、四個問題 要解決什麼問題? Image Cap
image caption筆記(三):《Show, Attend and Tell_Neural Image Caption》
一、 基本思想 文章在NIC的基礎上加入了attention機制 二、模型結構 對LSTM部分做出的改動,其餘與NIC相同。 &nbs
image caption解讀系列(二):《Show, Attend and Tell_Neural Image Caption》
一、相關工作 二、 基本思想 文章在NIC的基礎上加入了attention機制 三、模型結構 對LSTM部分做出的改動,其餘與NIC相同。 四、程式碼分析 (0)預處理 首先是把資料中長度大於2
論文閱讀計劃2(Deep Joint Rain Detection and Removal from a Single Image)
rem 領域 深度學習 conf mage 圖片 多任務 RoCE deep Deep Joint Rain Detection and Removal from a Single Image[1] 簡介:多任務全卷積從單張圖片中去除雨跡。本文在現有的模型上,開發了一種多
Show, attend and tell演算法詳解及原始碼
mark一下,感謝作者分享! https://blog.csdn.net/shenxiaolu1984/article/details/51493673 原論文:https://arxiv.org/pdf/1502.03044v2.pdf 原始碼:https://github.c
How to detect and extract forest areas in a aerial image map with the knowledge of DIP
Signal processing is a common subject in electrical engineering, communication engineering and mathematics that deals with analysis and processing
image caption解讀系列(二):《Knowing When to Look: Adaptive Attention via A Visual Sentinel for Image Capt》
本文主要是在這篇部落格的基礎上結合程式碼進行分析。 文章依然採用了encoder-decoder的框架。作者認為decoder的時候非視覺詞多依賴的是語義資訊而不是視覺資訊。而且,在生成caption的過程中,非視覺詞的梯度會誤導或者降低視覺資訊的有效性。因此,本文提出
製作一個python-docker image and run a container!
#docker pull holbertonschool/ubuntu-1404-python3 #docker run --name python3 -v /home:/mnt -ti docker.io/holbertonschool/ubuntu-1404-pytho
Show HN: FlubuCore a .net cross platform build and deployment automation system
lubuCore - Fluent Builder is a cross platform build and deployment automation system. You can define your build and deployment scripts in C# using an intui
How to Develop a Deep Learning Photo Caption Generator from Scratch
Tweet Share Share Google Plus Develop a Deep Learning Model to Automatically Describe Photograph
Analyze an image and send a status alert
Summary Industrial and high-tech maintenance companies often photograph their sites for potential hazards or emergencies and then inf
[HTML5] Add an SVG Image to a Webpage and Get a Reference to the Internal Elements in JavaScript
show acc ntb content open direct () ren for We want to show an SVG avatar of the patio11bot, so we‘ll do that in three ways: Using a
Livemedia-creator- How to create and use a Live CD
download further burning method create Livemedia-creator- How to create and use a Live CDNote for older method (namely for Fedora 23) using livec
image caption項目調研及實踐
one challenge 比較 相同 版本 實現 維數 安裝方法 mach image caption, 或者說叫image story teller,就是用一句話把一張圖片的內容描述出來。 比較先進的是以下這篇論文所描述的方法: Vinyals, Oriol, et a
the pitfull way to create a uClinux image including gdb.
ldr let load cli pla install his sam inux After downloaded and installed the GCT‘s SDK and toolchain, we try to make an our own image whi
Ai challenger 2017 image caption小結
oss 提升 適合 pytorch 改進 ack https 修改 bottom 參加了今年的ai challenger 的image caption比賽,最終很幸運的獲得了第二名。這裏小結一下。 Pytorch 越來越火了。。 前五名有三個pytoch