
SVO深度解析(三)之深度濾波(建圖部分)
轉載請說明出處:
http://blog.csdn.net/zhubaohua_bupt/article/details/749110003.1深度濾波簡介
SVO在建圖部分採用的是深度濾波器,論文中並沒有詳細的介紹。深度濾波在SVO作者寫的另一篇叫REMODE[1]的文章裡,介紹了深度濾波的每一個步驟。REMODE[1]這篇文章講的是利用svo提供的位姿,進行三維重建,屬於漸進式三維重建。其過程和SVO深度濾波一樣,只不過在REMODE裡,實現用GPU進行了加速處理。
SVO深度濾波是利用一系列的前後幀,完成對指定幀上畫素深度的求取。用一些列幀,來求取指定幀上每個畫素深度的原因是,在計算畫素點深度時,單次匹配恢復的深度有誤差,需要依靠多次深度測量值的融合,來恢復誤差較小的深度值。SVO把畫素的深度誤差模型看做概率分佈,有兩個屬性
SVO深度濾波對深度進行漸進式融合(動態融合)。其過程可表述如下:
關鍵幀上選取畫素點(SVO是fast角點,REMODE是梯度點),作為種子(seed,種子就是深度未收斂的畫素點),每來一幀影象,融合更新一下之前提取的種子,直至種子的深度收斂,這是個動態過程,類似於濾波,大概這就是叫深度濾波的原因吧。如果新的一幀是關鍵幀,那麼再次提取新的畫素點作為種子。
就這樣舊的種子不斷收斂,新的種子不斷增加,不斷進行下去。
下面來探討一下深度濾波的整個過程。
3.2 深度濾波分步驟詳細介紹
對於一個種子,其每一次深度濾波(也叫深度融合,利用新的一幀來更新種子的深度值),都行需要經以下過程。
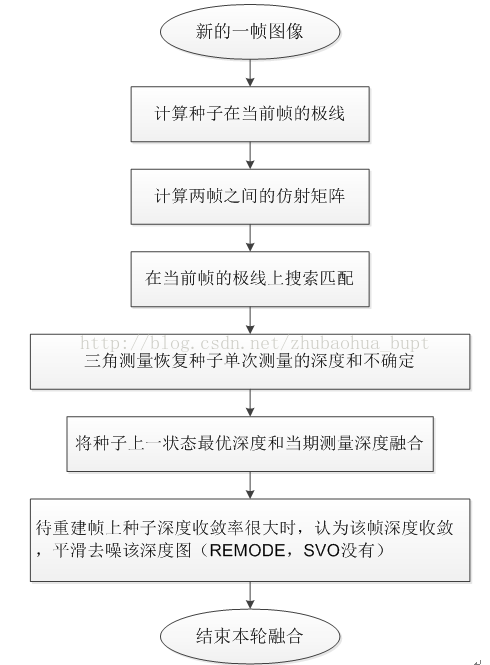
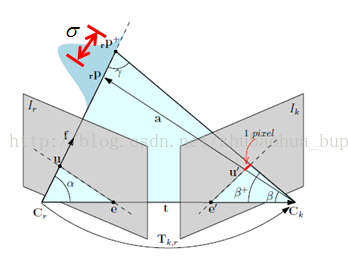
3.2.1 計算極線
關於極線的基本知識,本文不做介紹。對於每個種子,在當前幀計算極線的條件是:
<1>已知種子所在幀與當前幀的相對位姿
<2>已知種子的初始深度
條件<1>的作用是用來做匹配,由VO提供。
條件<2>的作用是縮小找匹配的搜尋量。當種子新提取時,這個時候還沒有深度值,用場景平均深度初始。
本文用z表示種子的深度,sigma2表示深度方差,sigma表示深度標準差。
極線的計算方法如下:
step1:
在深度延長線上,構造兩個三維點P1,P2,這兩個三維點來源同一個畫素,唯一的不同就是深度,
分別為 P1(x,y,z- n*sigma),P2(x,y,z+ n*sigma),這裡n可以調節,一般選擇n=1,2,3(3sigma原則)。
Step2:
將P1,P2利用幀間位姿,投影至當前幀,投影點為u1,u2,連線u1,u2就是我們所要計算的極線。
SVO工程裡,實現在Matcher.cpp裡的findEpipolarMatchDirect()函式裡。

REMODE工程裡,實現在epipolar.cpp seedEpipolarMatchKernel()函式裡。

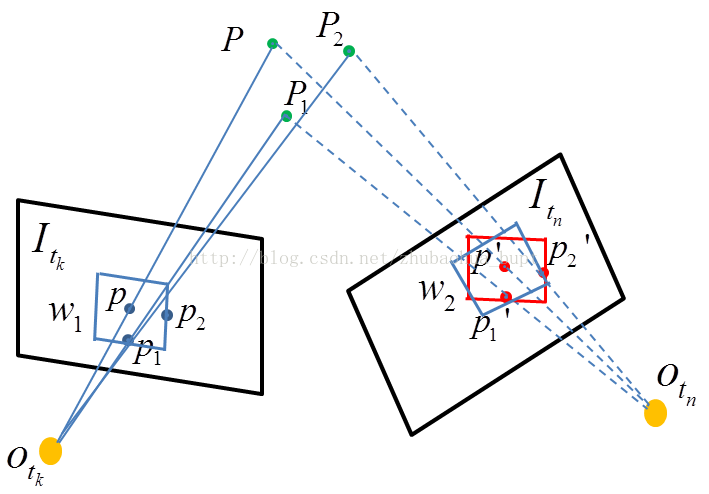
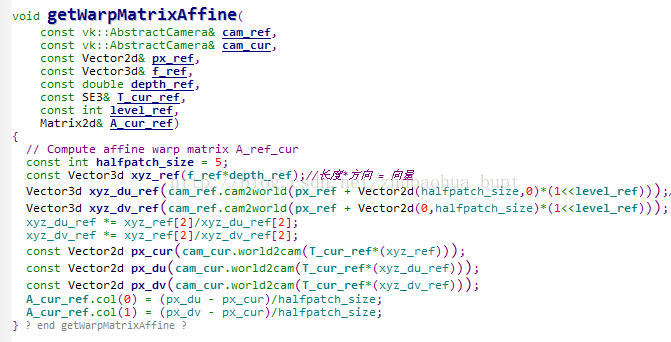
3.2.2 計算仿射矩陣
為什麼要計算仿射矩陣?
我們知道,同一張影象在經過旋轉平移後,同一個場景在影象上的成像位置就發生了變換。
在畫素做匹配時,我們需要用畫素周圍的資訊(一般是矩形視窗)來描述本畫素的特徵。
設想一下,如果幀間影象發生了旋轉,我們還用同樣的視窗(當前幀的視窗座標和種子所在幀視窗座標一樣)
來描述搜尋點,是不是不太合適?

3.2.3 搜尋匹配
跟蹤部分的匹配,是靠特徵對齊完成的,不需要極線搜尋,這是因為在深度和位姿都比較準確的情況下,
用特徵對齊可以完成匹配。
但是,深度估計卻不能這樣幹,它需要極線搜尋,因為深度未知或者深度不確定性太大。
SVO選用ZMSSD,通過8*8矩形patch來描述畫素,用於計算種子和當前幀搜尋點的相似性。
實際上,在svo搜尋匹配過程中,當計算的極線小於兩個畫素時,直接採用影象對齊,
因為這個時候深度不確定較小(可以通過極線的計算方式想一下為什麼)。
否則,沿極線搜尋匹配。程式碼在findEpipolarMatchDirect()裡,

3.2.4三角測量恢復深度以及匹配不確定性的計算
經過搜尋匹配後,能夠得到種子p以及種子p在當前幀上的匹配畫素點p’,
通過三角測量,就可以恢復種字p的深度。
原理可以參考 http://blog.csdn.net/zhubaohua_bupt/article/details/74926111
實現部分:
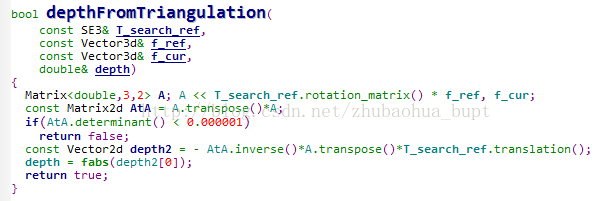
多次三角測量的深度是為了,融合得到種子較準確的深。那麼既然有融合,不同測量值肯定有不同權重。
不確定性就是用來計算權重的。在SVO中,深度的不確定被認為是,
在匹配時,誤匹配一個畫素所帶來的最大深度誤差。
其計算很簡單,可以直接看論文。
3.2.5 深度融合
SVO的融合是不斷利用最新時刻深度的觀測值,來融合上一時刻深度最優值,直至深度收斂。
深度資料具體融合過程的過程如下,



3.2.6 平滑去噪
這一步在SVO裡沒有,在REMODE裡,作者加上這一步驟,對深度圖有不錯的去噪平滑效果,如下圖。

這個就不細說了,因為這一步驟本身與SVO無關,有興趣的話可以看一下論文[1],作者通過構造一個能量函式,
然後迭代優化能量函式,當能量函式最小時,就完成平滑去噪。
至此,我們探討了SVO整個深度濾波。
REMODE論文:
[1] MatiaPizzoli,Christian Forster, and Davide Scaramuzza. REMODE: Probabilistic,monocular densereconstruction in real time. In International Conference onRobotics andAutomation (ICRA), pages 2609–2616, Hong Kong,China, June 2014.
相關推薦
SVO深度解析(三)之深度濾波(建圖部分)
轉載請說明出處: http://blog.csdn.net/zhubaohua_bupt/article/details/74911000 3.1深度濾波簡介 SVO在建圖部分採用的是深度濾波器,
RocketMQ原始碼深度解析三之Broker篇
(一)Broker的初始化 在初始化過程中,會呼叫 BrokerController 物件的 initialize 方法進行初始化工作,大致邏輯如下: (1)載入 topics.json、 consumerOffset.json、 subscriptionG
Spring5原始碼深度解析(一)之理解Configuration註解
程式碼地址:https://github.com/showkawa/spring-annotation/tree/master/src/main/java/com/brian 1.Spring體系結構 1.1、Spring Core:主要元件是BeanFactory,建立JavaBean的工廠,使用控制反
spring原始碼深度解析— IOC 之 容器的基本實現
概述 上一篇我們搭建完Spring原始碼閱讀環境,spring原始碼深度解析—Spring的整體架構和環境搭建 這篇我們開始真正的閱讀Spring的原始碼,分析spring的原始碼之前我們先來簡單回顧下spring核心功能的簡單使用 容器的基本用法 bean是spring最核心的東
spring原始碼深度解析— IOC 之 預設標籤解析(上)
概述 接前兩篇文章 spring原始碼深度解析—Spring的整體架構和環境搭建 和 spring原始碼深度解析— IOC 之 容器的基本實現 本文主要研究Spring標籤的解析,Spring的標籤中有預設標籤和自定義標籤,兩
spring原始碼深度解析— IOC 之 預設標籤解析(下)
在spring原始碼深度解析— IOC 之 預設標籤解析(上)中我們已經完成了從xml配置檔案到BeanDefinition的轉換,轉換後的例項是GenericBeanDefinition的例項。本文主要來看看標籤解析剩餘部分及BeanDefinition的註冊。 預設標籤中的自定義標籤解析
spring原始碼深度解析— IOC 之 自定義標籤解析
概述 之前我們已經介紹了spring中預設標籤的解析,解析來我們將分析自定義標籤的解析,我們先回顧下自定義標籤解析所使用的方法,如下圖所示: 我們看到自定義標籤的解析是通過BeanDefinitionParserDelegate.parseCustomElement(ele)進行的,解析來
spring原始碼深度解析— IOC 之 開啟 bean 的載入
概述 前面我們已經分析了spring對於xml配置檔案的解析,將分析的資訊組裝成 BeanDefinition,並將其儲存註冊到相應的 BeanDefinitionRegistry 中。至此,Spring IOC 的初始化工作完成。接下來我們將對bean的載入進行探索。 之前系列文章: spring原始
spring原始碼深度解析— IOC 之 bean 建立
在 Spring 中存在著不同的 scope,預設是 singleton ,還有 prototype、request 等等其他的 scope,他們的初始化步驟是怎樣的呢?這個答案在這篇部落格中給出。 singleton Spring 的 scope 預設為 singleton,第一部分分析了從快取中獲取單
spring原始碼深度解析— IOC 之 屬性填充
doCreateBean() 主要用於完成 bean 的建立和初始化工作,我們可以將其分為四個過程: createBeanInstance() 例項化 bean populateBean() 屬性填充 迴圈依賴的處理 initializeBean() 初始化
spring原始碼深度解析— IOC 之 迴圈依賴處理
什麼是迴圈依賴 迴圈依賴其實就是迴圈引用,也就是兩個或則兩個以上的bean互相持有對方,最終形成閉環。比如A依賴於B,B依賴於C,C又依賴於A。如下圖所示: 注意,這裡不是函式的迴圈呼叫,是物件的相互依賴關係。迴圈呼叫其實就是一個死迴圈,除非有終結條件。 Spring中迴圈依賴場景有: (1)構造
spring5 原始碼深度解析— IOC 之 bean 的初始化
一個 bean 經歷了 createBeanInstance() 被創建出來,然後又經過一番屬性注入,依賴處理,歷經千辛萬苦,千錘百煉,終於有點兒 bean 例項的樣子,能堪大任了,只需要經歷最後一步就破繭成蝶了。這最後一步就是初始化,也就是 initializeBean(),所
Elastic-Job原始碼解析(三)之分片定時任務執行
通過本篇的閱讀你將學會了解Elastic-Job的定時時機,及如何通過分片方式做一個分散式的定時任務框架。瞭解常用的三種分片策略,及如何自定義分散式分片策略 目錄 Elastic-Job如何通過SpringJobScheduler啟動定時 Ela
Python之路(第三十三篇) 網路程式設計:socketserver深度解析
一、socketserver 模組介紹 socketserver是標準庫中的一個高階模組,用於網路客戶端與伺服器的實現。(version = "0.4") 在python2中寫作SocketServer,在python3中寫作socketserver。 socoketserver兩個主要的類,一個是S
[ZZ] 深度學習三巨頭之一來清華演講了,你只需要知道這7點
動態 能夠 關系 領域 那一刻 計劃 world 哪些 net 深度學習三巨頭之一來清華演講了,你只需要知道這7點 http://wemedia.ifeng.com/10939074/wemedia.shtml Yann LeCun還提到了一項FAIR開發的,用於
數據結構(三十一)圖的遍歷之深度優先遍歷
width depth idt 廣度優先遍歷 http 如果 搜索 src 技術分享 圖的遍歷和樹的遍歷類似。圖的遍歷是指從圖中的某個頂點出發,對圖中的所有頂點訪問且僅訪問一次的過程。通常有兩種遍歷次序方案:深度優先遍歷和廣度優先遍歷。 一、深度優先遍歷算法描述
Goroutine並發調度模型深度解析之手擼一個協程池
if判斷 存儲 衍生 成了 100% 玩意兒 取出 F12 pan golanggoroutine協程池Groutine Pool高並發 並發(並行),一直以來都是一個編程語言裏的核心主題之一,也是被開發者關註最多的話題;Go語言作為一個出道以來就自帶 『高並發』光
深度解析 Go 語言中「切片」的三種特殊狀態
我們今天要來講一個非常細節的小知識,這個知識被大多數 Go 語言的開發者無視了,它就是切片的三種特殊狀態 —— 「零切片」、「空切片」和「nil 切片」。 切片被視為 Go 語言中最為重要的基礎資料結構,使用起來非常簡單,有趣的內部結構讓它成了 Go 語言面試中最為常見的考點。切片的底層是
MySQL儲存引擎之Spider核心深度解析
作者介紹 朱閱岸,中國人民大學博士,現供職於騰訊雲資料庫團隊。研究方向主要為資料庫系統理論與實現、新硬體平臺下的資料庫系統以及TP+AP型混合系統。 Spider是為MySQL/MariaDB開發的一個特殊引擎,具有內嵌分片功能。現在它已經被
C++的三種單例模式-----深度解析
三種單例模式轉自部落格:http://blog.csdn.net/q_l_s/article/details/52369065 小編想要對三種的單例模式做下解析 簡介 因為在設計或開發中,肯定會有這麼一種情況,一個類只能有一個物件