
大資料及人工智慧基礎系列3 文字挖掘的TF-IDF計算
文章來源:http://blog.csdn.net/eastmount/article/details/50323063
在文字聚類、文字分類或者比較兩個文件相似程度過程中,可能會涉及到TF-IDF值的計算。這裡主要講述基於Python的機器學習模組和開源工具:scikit-learn。
- 一.Scikit-learn概念
- 1.概念知識
- 2.安裝軟體
- 二.TF-IDF基礎知識
- 1.TF-IDF
- 2.舉例介紹
- 三.TF-IDF呼叫兩個方法
- 1.CountVectorizer
- 2.TfidfTransformer
- 3.別人示例
一. Scikit-learn概念
1.概念知識
官方網址:http://scikit-learn.org/stable/Scikit-learn是一個用於資料探勘和資料分析的簡單且有效的工具,它是基於Python的機器學習模組,基於BSD開源許可證。

Scikit-learn的基本功能主要被分為六個部分:分類(Classification)、迴歸(Regression)、聚類(Clustering)、資料降維(Dimensionality reduction)、模型選擇(Model selection)、資料預處理(Preprocessing)。
Scikit-Learn中的機器學習模型非常豐富,包括SVM,決策樹,GBDT,KNN等等,可以根據問題的型別選擇合適的模型,具體可以參考官網文件,推薦大家從官網中下載資源、模組、文件進行學習。

2.安裝軟體
Python 2.0我推薦使用"pip install scikit-learn"或"easy_install scikit-learn"全自動安裝,再通過"from sklearn import feature_extraction"匯入。安裝時如果出現錯誤"unknown encoding: cp65001",輸入"chcp 936"將編碼方式由utf-8變為簡體中文gbk。
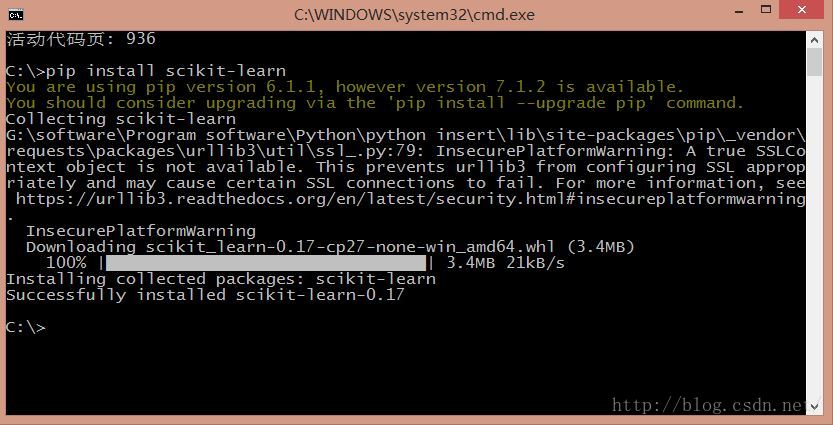
二. TF-IDF基礎知識
1.TF-IDF
TF-IDF(Term Frequency-InversDocument Frequency)是一種常用於資訊處理和資料探勘的加權技術。該技術採用一種統計方法,根據字詞的在文字中出現的次數和在整個語料中出現的文件頻率來計算一個字詞在整個語料中的重要程度。它的優點是能過濾掉一些常見的卻無關緊要本的詞語,同時保留影響整個文字的重要字詞。計算方法如下面公式所示。
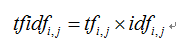
其中,式中tfidfi,j表示詞頻tfi,j和倒文字詞頻idfi的乘積。TF-IDF值越大表示該特徵詞對這個文字的重要性越大。
TF(Term Frequency)表示某個關鍵詞在整篇文章中出現的頻率。
IDF(InversDocument Frequency)表示計算倒文字頻率。文字頻率是指某個關鍵詞在整個語料所有文章中出現的次數。倒文件頻率又稱為逆文件頻率,它是文件頻率的倒數,主要用於降低所有文件中一些常見卻對文件影響不大的詞語的作用。
下面公式是TF詞頻的計算公式。
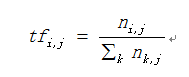
其中,ni,j為特徵詞ti在文字dj中出現的次數,是文字dj中所有特徵詞的個數。計算的結果即為某個特徵詞的詞頻。
下面公式是IDF的計算公式。
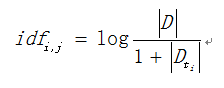
其中,|D|表示語料中文字的總數,表示文字中包含特徵詞ti的數量。為防止該詞語在語料庫中不存在,即分母為0,則使用作為分母。
2.示例
下面通過一個示例進行講解TF-IDF權重計算的方法。
假設現在有一篇文章《貴州的大資料分析》,這篇文章包含了10000個片語,其中“貴州”、“大資料”、“分析”各出現100次,“的”出現500次(假設沒有去除停用詞),則通過前面TF詞頻計算公式,可以計算得到三個單詞的詞頻,即:

現在預料庫中共存在1000篇文章,其中包含“貴州”的共99篇,包含“大資料”的共19篇,包含“分析”的共“59”篇,包含“的”共“899”篇。則它們的IDF計算如下:

由IDF可以發現,當某個詞在語料庫中各個文件出現的次數越多,它的IDF值越低,當它在所有文件中都出現時,其IDF計算結果為0,而通常這些出現次數非常多的詞或字為“的”、“我”、“嗎”等,它對文章的權重計算起不到一定的作用。
同時計算TF-IDF值如下:

通過TF-IDF計算,“大資料”在某篇文章中出現頻率很高,這就能反應這篇文章的主題就是關於“大資料”方向的。如果只選擇一個詞,“大資料”就是這篇文章的關鍵詞。所以,可以通過TF-IDF方法統計文章的關鍵詞。同時,如果同時計算“貴州”、“大資料”、“分析”的TF-IDF,將這些詞的TF-IDF相加,可以得到整篇文件的值,用於資訊檢索。
TF-IDF演算法的優點是簡單快速,結果比較符合實際情況。缺點是單純以詞頻衡量一個詞的重要性,不夠全面,有時重要的詞可能出現次數並不多。而且,這種演算法無法體現詞的位置資訊。
三. TF-IDF計算
Scikit-Learn中TF-IDF權重計算方法主要用到兩個類:CountVectorizer和TfidfTransformer。
1.CountVectorizer
CountVectorizer類會將文字中的詞語轉換為詞頻矩陣,例如矩陣中包含一個元素a[i][j],它表示j詞在i類文字下的詞頻。它通過fit_transform函式計算各個詞語出現的次數,通過get_feature_names()可獲取詞袋中所有文字的關鍵字,通過toarray()可看到詞頻矩陣的結果。
程式碼如下:
- # coding:utf-8
- from sklearn.feature_extraction.text import CountVectorizer
- #語料
- corpus = [
- 'This is the first document.',
- 'This is the second second document.',
- 'And the third one.',
- 'Is this the first document?',
- ]
- #將文字中的詞語轉換為詞頻矩陣
- vectorizer = CountVectorizer()
- #計算個詞語出現的次數
- X = vectorizer.fit_transform(corpus)
- #獲取詞袋中所有文字關鍵詞
- word = vectorizer.get_feature_names()
- print word
- #檢視詞頻結果
- print X.toarray()
- >>>
- [u'and', u'document', u'first', u'is', u'one', u'second', u'the', u'third', u'this']
- [[011100101]
- [010102101]
- [100010110]
- [011100101]]
- >>>
從結果中可以看到,總共包括9個特徵詞,即:
[u'and', u'document', u'first', u'is', u'one', u'second', u'the', u'third', u'this']
同時在輸出每個句子中包含特徵詞的個數。例如,第一句“This is the first document.”,它對應的詞頻為[0, 1, 1, 1, 0, 0, 1, 0, 1],假設初始序號從1開始計數,則該詞頻表示存在第2個位置的單詞“document”共1次、第3個位置的單詞“first”共1次、第4個位置的單詞“is”共1次、第9個位置的單詞“this”共1詞。所以,每個句子都會得到一個詞頻向量。
2.TfidfTransformer
TfidfTransformer用於統計vectorizer中每個詞語的TF-IDF值。具體用法如下:
- # coding:utf-8
- from sklearn.feature_extraction.text import CountVectorizer
- #語料
- corpus = [
- 'This is the first document.',
- 'This is the second second document.',
- 'And the third one.',
- 'Is this the first document?',
- ]
- #將文字中的詞語轉換為詞頻矩陣
- vectorizer = CountVectorizer()
- #計算個詞語出現的次數
- X = vectorizer.fit_transform(corpus)
- #獲取詞袋中所有文字關鍵詞
- word = vectorizer.get_feature_names()
- print word
- #檢視詞頻結果
- print X.toarray()
- from sklearn.feature_extraction.text import TfidfTransformer
- #類呼叫
- transformer = TfidfTransformer()
- print transformer
- #將詞頻矩陣X統計成TF-IDF值
- tfidf = transformer.fit_transform(X)
- #檢視資料結構 tfidf[i][j]表示i類文字中的tf-idf權重
- print tfidf.toarray()
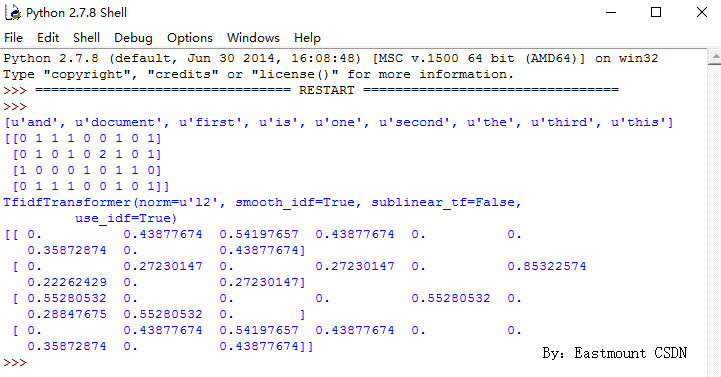
3.別人示例
如果需要同時進行詞頻統計並計算TF-IDF值,則使用核心程式碼:
vectorizer=CountVectorizer()
transformer=TfidfTransformer()
tfidf=transformer.fit_transform(vectorizer.fit_transform(corpus))
下面給出一個liuxuejiang158大神的例子,供大家學習,推薦大家閱讀原文:
python scikit-learn計算tf-idf詞語權重 - liuxuejiang
- # coding:utf-8
- __author__ = "liuxuejiang"
- import jieba
- import jieba.posseg as pseg
- import os
- import sys
- from sklearn import feature_extraction
- from sklearn.feature_extraction.text import TfidfTransformer
- from sklearn.feature_extraction.text import CountVectorizer
- if __name__ == "__main__":
- corpus=["我 來到 北京 清華大學",#第一類文字切詞後的結果,詞之間以空格隔開
- "他 來到 了 網易 杭研 大廈",#第二類文字的切詞結果
- "小明 碩士 畢業 與 中國 科學院",#第三類文字的切詞結果
- "我 愛 北京 天安門"]#第四類文字的切詞結果
- vectorizer=CountVectorizer()#該類會將文字中的詞語轉換為詞頻矩陣,矩陣元素a[i][j] 表示j詞在i類文字下的詞頻
- transformer=TfidfTransformer()#該類會統計每個詞語的tf-idf權值
- tfidf=transformer.fit_transform(vectorizer.fit_transform(corpus))#第一個fit_transform是計算tf-idf,第二個fit_transform是將文字轉為詞頻矩陣
- word=vectorizer.get_feature_names()#獲取詞袋模型中的所有詞語
- weight=tfidf.toarray()#將tf-idf矩陣抽取出來,元素a[i][j]表示j詞在i類文字中的tf-idf權重
- for i in range(len(weight)):#列印每類文字的tf-idf詞語權重,第一個for遍歷所有文字,第二個for便利某一類文字下的詞語權重
- print u"-------這裡輸出第",i,u"類文字的詞語tf-idf權重------"
- for j in range(len(word)):
- print word[j],weight[i][j]
- -------這裡輸出第 0 類文字的詞語tf-idf權重------ #該類對應的原文字是:"我來到北京清華大學"
- 中國 0.0
- 北京 0.52640543361
- 大廈 0.0
- 天安門 0.0
- 小明 0.0
- 來到 0.52640543361
- 杭研 0.0
- 畢業 0.0
- 清華大學 0.66767854461
- 碩士 0.0
- 科學院 0.0
- 網易 0.0
- -------這裡輸出第 1 類文字的詞語tf-idf權重------ #該類對應的原文字是: "他來到了網易杭研大廈"
- 中國 0.0
- 北京 0.0
- 大廈 0.525472749264
- 天安門 0.0
- 小明 0.0
- 來到 0.414288751166
- 杭研 0.525472749264
-
相關推薦
大資料及人工智慧基礎系列3 文字挖掘的TF-IDF計算
文章來源:http://blog.csdn.net/eastmount/article/details/50323063 在文字聚類、文字分類或者比較兩個文件相似程度過程中,可能會涉及到TF-IDF值的計算。這裡主要講述基於Python的機器學習模組和開源工具:sciki
課時3.使用者管理-大資料與人工智慧實戰L1系列課程-小象學院
知識要點 1.新增新組 groupadd groupname 2.新增新使用者 useradd username 3.設定使用者密碼 passwd username 4.給使用者新增組 usermod -g groupname
課時7.vim文字編輯器-大資料與人工智慧實戰L1系列課程-小象學院
1.vim test 首先會進入“一般模式”,此模式只接受各種快捷鍵,不能編輯檔案內容; i 從一般模式進入編輯模式,此模式下可以輸入內容; o 從一般模式進入編輯模式並且是游標所在行的下一行開始輸入內容; u 撤銷到上一步操作,
課時1.常用命令和快捷鍵-大資料與人工智慧實戰L1系列課程-小象學院
知識要點 學習本節課程之前請參照本課時資料完成虛擬機器的安裝! ctrl + c 2.清屏 ctrl + l ctrl + r Tab鍵 cd path cd ~ cd -
課時2.系統管理命令-大資料與人工智慧實戰L1系列課程-小象學院
知識要點 1.檢視本地時間 date 2.檢視主機名 hostname 3.修改主機名(重啟後永久生效) vim /etc/sysconfig/network 4.修改IP(重啟後永久生效) vim /etc/sy
課時6.檔案許可權操作-大資料與人工智慧實戰L1系列課程-小象學院
1.檔案或資料夾許可權 資料夾或者檔名稱前用四種字母和符號表示的一串字串表示的檔案或者資料夾型別和許可權。 -:表示檔案型別為檔案 d:表示檔案型別為資料夾 l:小寫的L表示符號連結 r:可讀 w:可寫 x:
課時8.常用壓縮和解壓縮-大資料與人工智慧實戰L1系列課程-小象學院
1.zip壓縮/解壓縮,壓縮檔案字尾名.zip zip tes.zip test.txt 壓縮資料夾 zip -r dirtest.zip dirtest 解壓縮檔案/資料夾 unzip tes.zip/dirtest.zip
大資料從0基礎到專案實戰(CDH5+Spark2.3.x)
課程下載:https://pan.baidu.com/s/1gfb4vhowT4hGAVYb-bRVEg 提取碼:jqff 本課程為就業課程,以完整的實戰專案為主線,專案各個環節既深入講解理論知識,又結合專案業務進行實操,從而達到一站式學習,讓你快速達到就業水平。 大資料常見熱門技術,一課搞定: linu
圖靈系列叢書(互動設計、程式設計、大資料、人工智慧等)
建造者模式 簡介 建造者模式是屬於建立型模式。建造者模式使用多個簡單的物件一步一步構建成一個複雜的物件。這種型別的設計模式屬於建立型模式,它提供了一種建立物件的最佳方式。 簡單的來說就是將一個複雜的東西抽離出來,對外提供一個簡單的呼叫,可以在同樣的構建過程建立不同的表示。和工廠模式很
都昌資訊袁永福:利用電子病歷賦能框架,為健康醫療大資料打好基礎【電子病歷和健康醫療大資料系列】
隨著國家健康醫療大資料政策的推行,電子病歷作為其中的基礎資料庫之一,在醫院的資訊系統中的地位不斷攀升。針對電子病歷在健康醫療大資料的發展問題,動脈網專訪了國內最具代表性的幾家電子病歷企業的專家。 南京都昌資訊科技有限公司是一家新興的技術型軟體開發企業。公司雖然年輕,但成員卻是長期從事於電子病歷行業的專家。團
大資料生態系統基礎: HBASE(一):HBASE 介紹及安裝、配置
一、介紹 Apache HBase是Hadoop資料庫,一個分散式的、可伸縮的大型資料儲存。 當您需要隨機的、實時的讀/寫訪問您的大資料時,請使用Apache HBase。這個專案的目標是承載非常大的表——數十億行X百萬列的列——執行在在商用硬體
c#基礎系列3---深入理解ref 和out
ref 聲明 函數的參數 .... -- 新增 tel struct 結果 “大菜”:源於自己剛踏入猿途混沌時起,自我感覺不是一般的菜,因而得名“大菜”,於自身共勉。 擴展閱讀 c#基礎系列1---深入理解 值類型和引用類型 c#基礎系列2---深入理解 Str
大資料環境搭建------基礎環境配置
準備材料: 作業系統:Centos7(最好有網路) 軟體:JDK:jdk-8u171-linux-x64.tar.gz(最好使用JDK1.8以上) 在虛擬機器中搭建三個linux系統,分別代表三個節點 {主節點:master 從節點:slave1、slave2} 此次操作均在root使
雲端計算,大資料,人工智慧三者有何關係?【轉】
轉自:【http://cloud.idcquan.com/yjs/115806.shtml】原文:來源:今日頭條/領先網路 2017-05-02 17:17 雲端計算,大資料,和人工智慧,最近火的不行不行的詞彙,似乎不相同,但又似乎相互關聯,到底是什麼樣的關係呢?其實他們本沒有什麼關係,各自活在不
一文帶你快速瞭解最火的數字經濟(大資料、人工智慧等都有)
人工智慧行業應用加速(暴富機會由“網際網路+”轉向AI+) “網際網路+”紅利已開發將盡,未來,新的暴富紅利將由“人工智慧”接棒。從產業演進看,科技巨頭正加速全球化併購,打造AI生態閉環,開源化也將成為全球性趨勢。開源化使得人工智慧的行業運用門檻急遽降低,未來幾年將迎來人工智慧行業應用浪潮。 2
大資料學習路線是什麼?學大資料需要什麼基礎?
因為大資料前景好,薪資高,很多人想通過參加學習大資料,然後進入大資料行業發展。但是因為大資料的門檻較高,對於學習人員有一定的要求,那麼學習大資料需要什麼基礎知識呢? 一起來了解下對於大資料學習者本身的學歷水平的要求。 目前大多數的機構,對於大資料學習者要求必須是大專學歷以上,而且大專學歷還要
物聯網、雲端計算、大資料、人工智慧之間有怎樣的聯絡和區別?
一、物聯網 1、什麼是物聯網? 物聯網在之前被定義為通過射頻識別(RFID)、紅外線感應器、全球定位系統、鐳射掃描器、氣體感應器等資訊感測裝置按約定的協議把任何物品與網際網路連線起來進行資訊交換,以實現智慧化識別、定位、跟蹤、監控和管理的一種網路,簡言之物聯網就是“物物相連的網際網路
大資料與人工智慧催生智慧時代
讀書筆記,資料來源:中國工程院院士鄔賀銓給吳軍的新書《智慧時代——大資料與智慧革命重新定義未來》寫的序。 科學研究四個正規化 吳軍認為科學研究發展經歷了四個正規化: 描述自然現象的實驗科學; 以牛頓定律和麥克斯韋方程為代表的理論科學; 模擬複雜現象的電腦科
傳統遇上現代科技,大資料和人工智慧的醫療應用【楚才國科】
近年來,人工智慧已經成為熱詞,從製造業、智慧家居、交通,教育到醫療,人工智慧的迅速發展已經不斷在提高人們的生活水平。在多檔科技節目的推動下,如《機智過人》、人工智慧交流群 862729908《我是未來》等等,包括青少年都在關注! 那麼將大資料和人工智慧與我們中醫相結合,這又會擦出怎樣的火花呢
[大資料專案]-小牛學堂2018年大資料24期-10階段3個專案
2018最新最全大資料技術、專案視訊。整套視訊,非那種淘寶雜七雜八網上能免費找到拼湊的亂八七糟的幾年前的不成體系浪費咱們寶貴時間的垃圾,詳細內容如下,需要的聯絡QQ:3164282908(加Q註明部落格園)。 更有海量大資料技術視訊、大資料專案視訊,機器學習深度學習技術視訊、專案視訊。Pyt