
網路爬蟲之Scrapy實戰二:爬取多個網頁
前面介紹的scrapy爬蟲只能爬取單個網頁。如果我們想爬取多個網頁。比如網上的小說該如何如何操作呢。比如下面的這樣的結構。是小說的第一篇。可以點選返回目錄還是下一頁

對應的網頁程式碼:
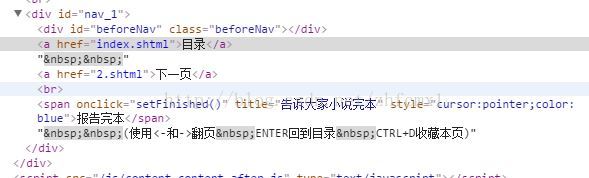
我們再看進入後面章節的網頁,可以看到增加了上一頁

對應的網頁程式碼

通過對比上面的網頁程式碼可以看到. 上一頁,目錄,下一頁的網頁程式碼都在<div>下的<a>元素的href裡面。不同的是第一章只有2個<a>元素,從二章開始就有3個<a>元素。因此我們可以通過<div>下<a>元素的個數來判決是否含有上一頁和下一頁的頁面。程式碼如下

最終得到生成的網頁連結。並呼叫Request重新申請這個網頁的資料

那麼在pipelines.py的檔案中。我們同樣需要修改下儲存的程式碼。如下。可以看到在這裡就不是用json.而是直接開啟txt檔案進行儲存
class Test1Pipeline(object): def __init__(self): self.file='' def process_item(self, item, spider): self.file=open(r'E:\scrapy_project\xiaoshuo.txt','wb') self.file.write(item['content']) self.file.close() return item
完整的程式碼如下:在這裡需要注意兩次yield的用法。第一次yield後會自動轉到Test1Pipeline中進行資料儲存,儲存完以後再進行下一次網頁的獲取。然後通過Request獲取下一次網頁的內容
# -*- coding:UTF-8 -*- # from scrapy.spiders import Spider from scrapy.selector import Selector from scrapy.http import Request fromtest1.items import Test1Item from scrapy.utils.response import open_in_browser class testSpider(Spider): name="test1" allowd_domains=['http://www.xunsee.com'] start_urls=["http://www.xunread.com/article/8c39f5a0-ca54-44d7-86cc-148eee4d6615/1.shtml"] def parse(self, response): init_urls="http://www.xunread.com/article/8c39f5a0-ca54-44d7-86cc-148eee4d6615" sel=Selector(response) context='' content=sel.xpath('//div[@id="content_1"]/text()').extract() for c in content: context=context+c.encode('utf-8') items=Test1Item() items['content']=context count = len(sel.xpath('//div[@id="nav_1"]/a').extract()) if count > 2: next_link=sel.xpath('//div[@id="nav_1"]/a')[2].xpath('@href').extract() else: next_link=sel.xpath('//div[@id="nav_1"]/a')[1].xpath('@href').extract() yield items for n in next_link: url=init_urls+'/'+n print url yield Request(url,callback=self.parse)
相關推薦
網路爬蟲之Scrapy實戰二:爬取多個網頁
前面介紹的scrapy爬蟲只能爬取單個網頁。如果我們想爬取多個網頁。比如網上的小說該如何如何操作呢。比如下面的這樣的結構。是小說的第一篇。可以點選返回目錄還是下一頁 對應的網頁程式碼: 我們再看進入後面章節的網頁,可以看到增加了上一頁 對應的網頁程式碼 通過
python 模擬滑鼠點選+bs4爬取多個網頁新聞(題目、媒體、日期、內容、url)
在搜狗新聞中,輸入關鍵詞(兩岸關係fa發展前景)後,出現6頁有關於這個關鍵詞的新聞。 現在目的就是爬取有關這個關鍵詞的網頁文章,如題目、媒體、日期、內容、url。如下圖: 載入包 import requests from bs4 import Beautif
網路爬蟲之scrapy爬取某招聘網手機APP釋出資訊
1 引言 2 APP抓包分析 3 編寫爬蟲昂 4 總結 1 引言 過段時間要開始找新工作了,爬取一些崗位資訊來分析一下吧。目前主流的招聘網站包括前程無憂、智聯、BOSS直聘、拉勾等等。有
爬蟲任務二:爬取(用到htmlunit和jsoup)通過百度搜索引擎關鍵字搜取到的新聞標題和url,並保存在本地文件中(主體借鑒了網上的資料)
標題 code rgs aps snap one reader url 預處理 采用maven工程,免著到處找依賴jar包 <project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http:
scrapy爬蟲框架(三):爬取桌布儲存並命名
寫在開始之前 按照上一篇介紹過的 scrapy爬蟲的建立順序,我們開始爬取桌布的爬蟲的建立。 首先,我們先過一遍 scrapy爬蟲的建立順序: 第一步:確定要在pipelines裡進行處理的資料,寫好items檔案 第二步:建立爬蟲檔案,將所需要的資訊從
Python3 Scrapy框架學習二:爬取豆瓣電影Top250
開啟專案裡的items.py檔案,定義如下變數, import scrapy from scrapy import Item,Field class DoubanItem(scrapy.Item): # define the fields for your it
【Java爬蟲學習】WebMagic框架爬蟲學習實戰一:爬取網易雲歌單資訊,並存入mysql中
最近,需要使用Java進行爬蟲編寫,就去學了Java的爬蟲。因為之前學習了Scrapy框架,所以學Java的爬蟲使用了WebMagic框架,這個框架是基於Scrapy框架開發的。大家有興趣可以去看看操作文件: 這個框架是國人開發的,所以說明文件都是中文,簡單易懂。
爬蟲二:爬取智聯招聘職位資訊
1. 簡介 因為想要找到一個數據分析的工作,能夠了解到市面上現有的職位招聘資訊也會對找工作有所幫助。 今天就來爬取一下智聯招聘上資料分析師的招聘資訊,並存入本地的MySQL。 2. 頁面分析 2.1 找到資料來源 開啟智聯招聘首頁,選擇資料分析師職位,跳轉進入資料分析師的詳情頁面。我
16.Python網路爬蟲之Scrapy框架(CrawlSpider)
引入 提問:如果想要通過爬蟲程式去爬取”糗百“全站資料新聞資料的話,有幾種實現方法? 方法一:基於Scrapy框架中的Spider的遞迴爬取進行實現(Request模組遞歸回調parse方法)。 方法二:基於CrawlSpider的自動爬取進行實現(更加簡潔和高效)。 今日概
Python網路爬蟲之scrapy爬蟲的基本使用
Scrapy爬蟲的資料型別: 1. Request類:向網路上提交請求,跟requests庫裡的不是一個型別! 2. Responce類:封裝爬取內容 3. ITEM:spider封裝類
Python爬蟲實戰一:爬取csdn學院所有課程名、價格和課時
import urllib.request import re,xlwt,datetime class csdn_spider(): def __init__(self): self.c = 0 def sava_data(self,name,class_num,price
18、python網路爬蟲之Scrapy框架中的CrawlSpider詳解
正則 art _id 糗事百科 put pytho 切換 ron 提交 CrawlSpider的引入: 提問:如果想要通過爬蟲程序去爬取”糗百“全站數據新聞數據的話,有幾種實現方法? 方法一:基於Scrapy框架中的Spider的遞歸爬取進行實現(Reque
python 爬蟲學習三(Scrapy 實戰,豆瓣爬取電影資訊)
利用Scrapy爬取豆瓣電影資訊主要列出Scrapy的三部分程式碼: spider.py檔案: # _*_ coding=utf-8 _*_ import scrapy from course.douban_items import DouBanItem from scra
Python爬蟲——實戰三:爬取蘇寧易購的商品價格(渲染引擎方法)
蘇寧易購的商品價格請求URL為 https://pas.suning.com/nspcsale_0_000000000152709847_000000000152709847_0000000000_10_010_0100101_20268_1000000_
Python爬蟲——實戰一:爬取京東產品價格(逆向工程方法)
在京東的單個產品頁面上,通過檢視原始碼檢查html,可以看到 <span class="p-price"><span>¥</span><span class="price J-p-1279836"></sp
python爬蟲十二:爬取快速ip代理,攻破503
轉:https://zhuanlan.zhihu.com/p/26701898 1.自定爬蟲方法 # -*- coding: utf-8 -*- import scrapy import requests from proxy.items import ProxyItem
python3網絡爬蟲(2.1):爬取堆糖美女
pre 線程 span 需要 pic ring clas lin chrome 額,明明記得昨晚存了草稿箱,一覺醒來沒了,那就簡寫點(其實是具體怎麽解釋我也不太懂/xk,純屬個人理解,有錯誤還望指正) 環境: 版本:python3 IDE:pycharm201
學習了一個月python,進行實戰一下:爬取文章標題和正文並儲存的程式碼
爬取東方財富網文章標題和正文並儲存的程式碼。自己知道寫的很爛,不過主要是為了自己備忘,也為了以後回頭看看自己的爛作品,哈哈哈。 #!/usr/bin/env python # -*- coding:utf-8 -*- import requests from bs4 import B
Python爬蟲練手小專案:爬取窮遊網酒店資訊
Python爬蟲練手小專案:爬取窮遊網酒店資訊 Python學習資料或者需要程式碼、視訊加Python學習群:960410445 前言 對於初學者而言,案例主要的是為了讓大家練手,明白其中如何這樣寫的思路,而不是拿著程式碼執行就完事了。 基本環境配置 系統
Java網路爬蟲(七)--實現定時爬取與IP代理池
定點爬取 當我們需要對金融行業的股票資訊進行爬取的時候,由於股票的價格是一直在變化的,我們不可能手動的去每天定時定點的執行程式,這個時候我們就需要實現定點爬取了,我們引入第三方庫quartz的使用: package timeutils; imp