
Scipy科學計算庫---基礎+進階語法
一、Scipy入門
1.1常用命令
import numpy as np
shift+enter運行當前單元格程式碼並切換到新的單元格
crtl+enter運行當前單元格
crtl+s儲存
Alt+Enter運行當前單元格並插入一個單元格
Ctrl+c關閉程式
A向上加一個單元
M單元轉入Markdown狀態
Y單元轉入程式碼格式
B向下加一個單元
1.2安裝操作簡介
1.2.1網址
官網:https://www.scipy.org/
安裝:在C:\Python27\Scripts下開啟cmd執行:
執行:pip install scipy
1.2.2安裝Anaconda及環境搭建(舉例演示)
建立環境:
conda create -n env_name python=3.6
示例: conda create -n Py_36 python=3.6 #建立名為Py_367的環境
列出所有環境:conda info -e
進入環境: source activate Py_36 (OSX/LINUX系統)
activate Py_36 (windows系統)
1.2.3、jupyter 安裝
jupyter簡介:jupyter(Jupyter Notebook)是一個互動式筆記本
支援執行40多種程式語言
資料清理和轉換,數值模擬,統計建模,機器學習等
jupyter 安裝:conda install jupyter notebook
啟動 jupyter:啟用相應環境
在控制檯執行 :**jupyter notebook**
notebook伺服器執行地址:http://localhost:8888
新建(notebook,文字檔案,資料夾)
qian
二、基礎語法
2.1儲存和載入命令—io.savemat/io.loadmat
#stats.norm.rvs()
from scipy import io
import numpy as np
a=np.arange(9).reshape(3,3)
#用scipy的io模組儲存到mat檔案中
io.savemat("a.mat",{"text":a})
#運用localmat載入資料
data=io.loadmat("a.mat" 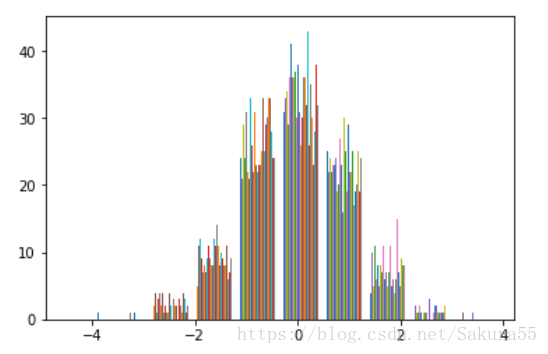
2.2、Scipy實現統計功能
2.2.1生成隨機數
利用scipy.stats的包統計函式實現分析隨機數的功能
均勻分佈(uniform)
x=stats.unifrom.rvs(size = 20)生成20個[0,1]均勻分佈隨機數
正太分佈(norm)
x=stats.norm.rvs(size = 20)生成20個正態分佈隨機數
貝塔分佈(beta)
x=stats.beta.rvs(size=20,a=3,b=4) 生成20個服從引數a=3,b=4貝塔分佈隨機數 生成20個正態分佈隨機數
離散分佈
伯努利分佈(bernoulli)
幾何分佈(geom)
泊松分佈(poisson)
x=stats.poisson.rvs(0.6,loc=0,size = 20)生成20個服從泊松分佈隨機數
2.2.2均值和標準差—fit
ndarray=stats.norm.rvs(size=100)
mean,std=stats.norm.fit(ndarray)2.2.3偏度—stats.skewtes()
偏度
skewtest>0,正偏
skewtest<0,負偏
from scipy import stats
from matplotlib import pyplot as plt
#用scipy生成一個正太分佈
normal1=stats.norm.rvs(size=100)
#繪圖操作
plt.hist(normal1)
normal2=stats.norm.rvs(size=100)
#計算偏度
staistic1,pvalue1=stats.skewtest(normal1)
staistic1
0.23677884737006907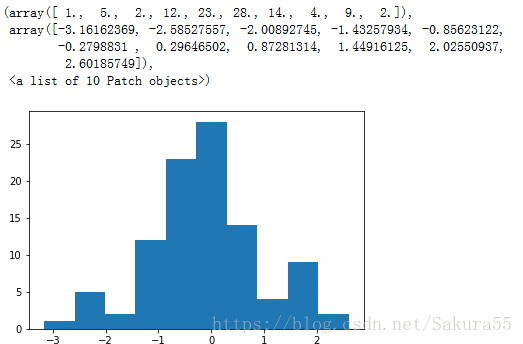
2.2.4峰度—stats.kurtosistest()
from scipy import stats
from matplotlib import pyplot as plt
import numpy as np
norm=stats.norm.rvs(size=100)
normmalExample=stats.norm.rvs(size=100)
#計算峰度
kurtosis,pvalue=stats.kurtosistest(normmalExample)
print("峰度",kurtosis)
print("接近正太分佈的飽和度:",pvalue)
kurt
>>0.21912014864574728
pvalue
>>0.8265564557880772
>#前面的峰度,值越大,月陡峭
>plt.hist(norm)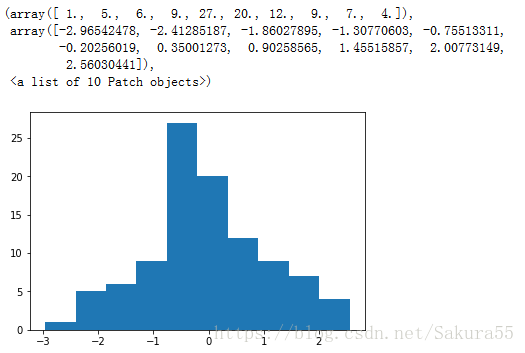
2.2.5檢測相互對應的百分比和數值—stats.scoreatpercentile/stats.percentileofscore
#-*-coding:utf-8-*-
from scipy import stats
from matplotlib import pyplot as plt
import numpy as np
normmalExample=stats.norm.rvs(size=100)
result=stats.scoreatpercentile(normmalExample,95)
print("%95:",result)
values=stats.percentileofscore(normmalExample,1)
print(values,"%")2.2.6正太分佈程度檢驗—pvalue
1 正態性檢驗(normality test),同樣返回兩個值,第二個返回p-values
2 利用 檢驗 stats.normaltest()
一般情況pvalue>0.05表示服從正態分佈
2.2.7正太分佈程度檢驗—pvalue
import matplotlib.pyplot as plt
在Anaconda環境下(py36)C:\Users\lenovo>匯入:conda install matplotlib
plt.hist(arr)#設定直方圖
plt.show()#顯示圖
三、綜合練習
3.1分數問題
求均值 中位數 眾數 極差 方差
標準差 變異係數(均值/方差) 偏度 峰度
import numpy as np
arrEasy=np.array([[0,2],[2.5,4],[5,6],[7.5,9],[10,13],
[12.5,16],[15,19],[17.5,23],[20,27],
[22.5,31],[25,35],[27.5,40],[30,53],
[32.5,68],[35,90],[37.5,110],[40,130],
[42.5,148],[45,165],[47.5,182],[50,195],
[52.5,208],[55,217],[57.5,226],[60,334],
[62.5,342],[65,349],[67.5,500],[70,511],
[72.5,300],[75,200],[77.5,80],[80,20]])
arrDiff=np.array([[0,20],[2.5,30],[5,45],[7.5,70],[10,100],[12.5,135],[15,170],[17.5,205],[20,226],
[22.5,241],[25,251],[27.5,255],[30,256],[32.5,253],[35,249],[37.5,242],[40,234],
[42.5,226],[45,217],[47.5,208],[50,195],[52.5,182],[55,165],[57.5,148],[60,130],
[62.5,110],[65,40],[67.5,30],[70,20],[72.5,5],[75,5],[77.5,0],[80,0]])步驟1 分數和人數對應擴充套件
#方法1 repeat
sorces=arrEasy[:,0]
person=arrEasy[:,1]
a=np.repeat(list(sorces),list(person))
a
array([ 0. , 0. , 2.5, ..., 80. , 80. , 80. ])
sorces2=arrDiff[:,0]
person2=arrDiff[:,1]
b=np.repeat(list(sorces2),list(person2))
b
array([ 0., 0., 0., ..., 75., 75., 75.])
#方法2 獨立封裝打包
def createScore(arr):
score = [] #所有學員分數
row = arr.shape[0]
for i in np.arange(0,row):
for j in np.arange(0,int(arr[i][1])):
score.append(arr[i][1]))
score = np.array(score)
return score步驟2:建立函式,根據傳入陣列,對其進行統計
#用的方法2
def calStatValue(score):
#集中趨勢度量
print('均值')
print(np.mean(score))
print('中位數')
print(np.median(score))
print('眾數')
print(stats.mode(score))
#離散趨勢度量
print('極差')
print(np.ptp(score))
print('方差')
print(np.var(score))
print('標準差')
print(np.std(score))
print('變異係數')
print(np.mean(score)/np.std(score))
#偏度與峰度的度量
print('偏度')
print(stats.skewness(score))
print('峰度')
print(stats.Kurtosis(score))相關推薦
Scipy科學計算庫---基礎+進階語法
一、Scipy入門 1.1常用命令 import numpy as np shift+enter運行當前單元格程式碼並切換到新的單元格 crtl+enter運行當前單元格 crtl+s儲存 Alt+Enter運行當前單元
【思庫教育】2017PHP項目實戰基礎+進階+項目之基礎篇
商品 資源庫 商城 文件引入 正則表達式 匿名 header 類和對象 多少 下載鏈接: 【思庫教育】2017PHP項目實戰基礎+進階+項目之基礎篇 小白變大牛,您的專屬資源庫! 小白變大牛,您的專屬資源庫! 內容非常充實,可以看目錄,設計的面多,項目多,技能多
Python科學計算庫-Numpy之基礎結構
1.numpy.array()中的資料要保證是同一種類型,不然其中一個數據與其他不同時,整體都會被進行型別轉換 如:numbers=numpy.array([ 1, 2, 3, 4])
python科學計算庫numpy基礎
Numpy是什麼? NumPy(NumericalPython的縮寫)是一個開源的Python科學計算庫。使用NumPy,就可以很自然地使用陣列和矩陣。NumPy包含很多實用的數學函式,涵蓋線性代數運算、傅立葉變換和隨機數生成等功能。 Numpy基礎 NumPy的主要物件是同種元素的多維
Oracle基礎進階
行程 sysdate create upd add 三種模式 數據庫對象 hello 輸出 PL/SQL 是Oracle對sql語言的過程化擴展,指在sql命令語言中增加了過程處理語句,是sql語言具有過程處理能力.語法: [declare --聲明變量
Django基礎進階
讀取 編寫 編寫程序 pen hunk 文件路徑 settings 處理 oct 內容回顧: 1、Django請求生命周期 路由(URL) 視圖 (VIEW)
01月05日 三周四次【Python基礎進階】
是個 快速 files 函數 true 結果 lis pre 序列 1.8 遞歸列出目錄裏的文件1.9 匿名函數 1.8 遞歸列出目錄裏的文件 #### 遍歷目錄裏的文件(不支持子目錄文件) import os for i in os.listdir(‘C:/Users
01月11日 四周四次【Python基礎進階】
顯示 進階 col super 自定義 方法總結 總結 類方法 3.1 3.1/3.2 類的繼承3.3 類的屬性總結3.4 類的方法總結 3.1/3.2 類的繼承 類的繼承 繼承是面向對象的重要特點之一 繼承關系: 繼承是相對兩個類而言的父子關系,子類繼承父類所有的公有
01月12日 四周五次【Python基礎進階】
python3.5 rc腳本(類的定義與腳本的結構)3.6 rc腳本(start方法)3.7 rc腳本(stop和status方法)3.8 rc腳本(以daemon方式啟動) 3.5 rc腳本(類的定義與腳本的結構)/3.6 rc腳本(start方法)/3.7 rc腳本(stop和status方法) imp
前端基礎進階系列
所有 工具 函數調用 使用 如何 最有 獲得 this 對象 前端基礎進階(一):內存空間詳細圖解 前端基礎進階(二):執行上下文詳細圖解 前端基礎進階(三):變量對象詳解 前端基礎進階(四):詳細圖解作用域鏈與閉包 前端基礎進階(五):全方位解讀this 前端基礎進階(
Windows系統Qt5配置GSL科學計算庫
系統:win10, 64bits 軟體: (1)Qt5.11.1 (2)gsl2.5:ftp://ftp.gnu.org/gnu/gsl/ (3)msys:https://sourceforge.net/projects/mingwbuilds/files/external-binary
python基礎進階
python開發基礎進階 1.程式的組成 從兩個方面分類: 程式 = 資料 +(彙編)指令 程式 = 資料結構 + 演算法 演算法:編寫程式的邏輯,解決問題的流程 [tess.cpp]a=hello #資料:a hello 這裡為
python基礎進階知識
1.linux命令的基本使用 1.ls :顯示當前資料夾裡的內容 2.pwd :顯示當前檔案的路徑 3.touch :如果檔案不存在,建立一個檔案 4.mkdir :如果資料夾不存在,建立一個資料夾 5.rm :刪除指定檔案 如果要刪除資料夾則需要在rm 後加-r 6.cd :切換
python 科學計算庫Numpy
科學計算庫Numpy 1、讀取檔案 numpy.gerfromtxt()用於讀取檔案,其中傳入的引數依次是: 1、需要讀取txt檔案位置,此處檔案與程式位於同一目錄下 2、delimiter 分割的標記 3、dtype 轉換型別
前端基礎進階(十三):透徹掌握Promise的使用,讀這篇就夠了(轉)
https://www.jianshu.com/p/fe5f173276bd Promise的重要性我認為我沒有必要多講,概括起來說就是必須得掌握,而且還要掌握透徹。這篇文章的開頭,主要跟大家分析一下,為什麼會有Promise出現。 在實際的使用當中,有非常多的應用場景我們不能立即知道應該如
分享6個月java基礎+進階精簡資料(視訊+原始碼+就業專案+面試報裝)
每天都有初學者詢問該如何學習,如何快速學習,因精力有限不能一一回復請見諒,現系統整理一套java初學者最佳的學習方法、路線、大綱及視訊資料,並對一些過期的知識點進行剔除!如Struts2,hibernate等舊框架!完全不需要在新手期進行學習,因為外面公司基本不再使用!希望
Python 進階語法
一.函數語言程式設計 1 高階函式 1.1 map()是 Python 內建的高階函式,它接收一個函式 f 和一個 list,並通過把函式 f 依次作用在 list 的每個元素上,得到一個新的 list 並返回。 def f(x): return x*x pri
django 基礎進階ORM 2
1.多表操作 新增記錄: 針對一對多 book_obj=Book.objects.create(title="python葵花寶典",price=100,publishDate="2012-12-12",publish_id=1) &n
Shell程式設計基礎進階
為什麼學習shell程式設計 shell指令碼語言是實現linux/unix 系統管理機自動化運維所必備的重要工具,linux/unix系統的底層及基礎應用軟體的核心大部分涉及shell指令碼的內容。每一個合格的linux系統管理員或運維工程師,都需要熟練的編寫shell指令碼語言,並能夠閱讀系統及各
Python神經網路-常見的科學計算庫中的易錯點和技巧
文章說明:本文主要內容來自吳恩達老師的神經網路課程的課後練習,結合何寬的部落格,希望能為大家更加通俗清晰地理解和解決一些在使用Python實現神經網路中可能遇到的一些問題。 文章目錄 常見的科學計算庫中的易錯點和技巧 矩陣相加