
init程序【2】——解析配置檔案
在前面的一篇文章中分析了init程序的啟動過程和main函式,本文將著重對配置檔案(init.rc)的解析做一下分析。
init.rc指令碼語法
init.rc檔案不同於init程序,init程序僅當編譯完Android後才會生成,而init.rc檔案存在於Android平臺原始碼中。init.rc在原始碼中的位置為:@system/core/rootdir/init.rc。init.rc檔案的大致結構如下圖所示:
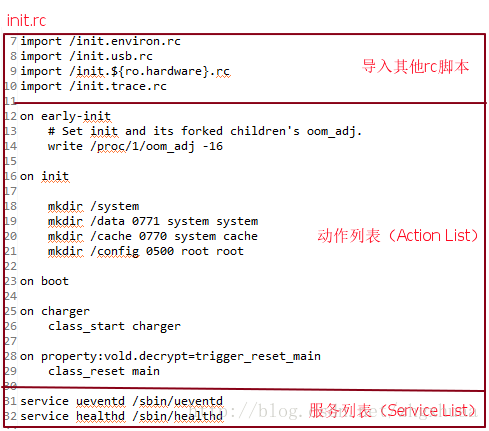
關於init.rc指令碼的介紹,在@system/core/init/readme.txt中有完整的介紹,這裡不再贅述,不想看英文的朋友也可以看下面的部分,這個部分關於rc指令碼的介紹轉自http://blog.csdn.net/nokiaguy/article/details/9109491。相當於readme的翻譯吧。
init.rc檔案並不是普通的配置檔案,而是由一種被稱為“Android初始化語言”(Android Init Language,這裡簡稱為AIL)的指令碼寫成的檔案。在瞭解init如何解析init.rc檔案之前,先了解AIL非常必要,否則機械地分析init.c及其相關檔案的原始碼毫無意義。
為了學習AIL,讀者可以到自己Android手機的根目錄尋找init.rc檔案,最好下載到本地以便檢視,如果有編譯好的Android原始碼,在<Android原始碼根目錄>out/target/product/geneic/root目錄也可找到init.rc檔案。
AIL由如下4部分組成。
1. 動作(Actions)
2. 命令(Commands)
3.服務(Services)
4. 選項(Options)
這4部分都是面向行的程式碼,也就是說用回車換行符作為每一條語句的分隔符。而每一行的程式碼由多個符號(Tokens)表示。可以使用反斜槓轉義符在Token中插入空格。雙引號可以將多個由空格分隔的Tokens合成一個Tokens。如果一行寫不下,可以在行尾加上反斜槓,來連線下一行。也就是說,可以用反斜槓將多行程式碼連線成一行程式碼。
AIL的註釋與很多Shell指令碼一行,以#開頭。
AIL在編寫時需要分成多個部分(Section),而每一部分的開頭需要指定Actions或Services。也就是說,每一個Actions或Services確定一個Section。而所有的Commands和Options只能屬於最近定義的Section。如果Commands和Options在第一個Section之前被定義,它們將被忽略。
Actions和Services的名稱必須唯一。如果有兩個或多個Action或Service擁有同樣的名稱,那麼init在執行它們時將丟擲錯誤,並忽略這些Action和Service。
下面來看看Actions、Services、Commands和Options分別應如何設定。
Actions的語法格式如下:
- on <trigger>
- <command>
- <command>
- <command>
也就是說Actions是以關鍵字on開頭的,然後跟一個觸發器,接下來是若干命令。例如,下面就是一個標準的Action
- on boot
- ifup lo
- hostname localhost
- domainname localdomain
其中boot是觸發器,下面三行是command
那麼init.rc到底支援哪些觸發器呢?目前init.rc支援如下5類觸發器。
1. boot
這是init執行後第一個被觸發Trigger,也就是在 /init.rc被裝載之後執行該Trigger
2. <name>=<value>
當屬性<name>被設定成<value>時被觸發。例如,
on property:vold.decrypt=trigger_reset_main
class_reset main
3. device-added-<path>
當裝置節點被新增時觸發
4. device-removed-<path>
當裝置節點被移除時新增
5. service-exited-<name>
會在一個特定的服務退出時觸發
Actions後需要跟若干個命令,這些命令如下:
1. exec <path> [<argument> ]*
建立和執行一個程式(<path>)。在程式完全執行前,init將會阻塞。由於它不是內建命令,應儘量避免使用exec ,它可能會引起init執行超時。
2. export <name> <value>
在全域性環境中將 <name>變數的值設為<value>。(這將會被所有在這命令之後執行的程序所繼承)
3. ifup <interface>
啟動網路介面
4. import <filename>
指定要解析的其他配置檔案。常被用於當前配置檔案的擴充套件
5. hostname <name>
設定主機名
6. chdir <directory>
改變工作目錄
7. chmod <octal-mode><path>
改變檔案的訪問許可權
8. chown <owner><group> <path>
更改檔案的所有者和組
9. chroot <directory>
改變處理根目錄
10. class_start<serviceclass>
啟動所有指定服務類下的未執行服務。
11 class_stop<serviceclass>
停止指定服務類下的所有已執行的服務。
12. domainname <name>
設定域名
13. insmod <path>
載入<path>指定的驅動模組
14. mkdir <path> [mode][owner] [group]
建立一個目錄<path> ,可以選擇性地指定mode、owner以及group。如果沒有指定,預設的許可權為755,並屬於root使用者和 root組。
15. mount <type> <device> <dir> [<mountoption> ]*
試圖在目錄<dir>掛載指定的裝置。<device> 可以是[email protected]的形式指定一個mtd塊裝置。<mountoption>包括 "ro"、"rw"、"re
16. setkey
保留,暫時未用
17. setprop <name><value>
將系統屬性<name>的值設為<value>。
18. setrlimit <resource> <cur> <max>
設定<resource>的rlimit (資源限制)
19. start <service>
啟動指定服務(如果此服務還未執行)。
20.stop<service>
停止指定服務(如果此服務在執行中)。
21. symlink <target> <path>
建立一個指向<path>的軟連線<target>。
22. sysclktz <mins_west_of_gmt>
設定系統時鐘基準(0代表時鐘滴答以格林威治平均時(GMT)為準)
23. trigger <event>
觸發一個事件。用於Action排隊
24. wait <path> [<timeout> ]
等待一個檔案是否存在,當檔案存在時立即返回,或到<timeout>指定的超時時間後返回,如果不指定<timeout>,預設超時時間是5秒。
25. write <path> <string> [ <string> ]*
向<path>指定的檔案寫入一個或多個字串。
Services (服務)是一個程式,他在初始化時啟動,並在退出時重啟(可選)。Services (服務)的形式如下:
- service <name> <pathname> [ <argument> ]*
- <option>
- <option>
例如,下面是一個標準的Service用法
- service servicemanager /system/bin/servicemanager
- class core
- user system
- group system
- critical
- onrestart restart zygote
- onrestart restart media
- onrestart restart surfaceflinger
- onrestart restart drm
1. critical
表明這是一個非常重要的服務。如果該服務4分鐘內退出大於4次,系統將會重啟並進入 Recovery (恢復)模式。
2. disabled
表明這個服務不會同與他同trigger (觸發器)下的服務自動啟動。該服務必須被明確的按名啟動。
3. setenv <name><value>
在程序啟動時將環境變數<name>設定為<value>。
4. socket <name><type> <perm> [ <user> [ <group> ] ]
Create a unix domain socketnamed /dev/socket/<name> and pass
its fd to the launchedprocess. <type> must be"dgram", "stream" or "seqpacket".
User and group default to0.
建立一個unix域的名為/dev/socket/<name> 的套接字,並傳遞它的檔案描述符給已啟動的程序。<type> 必須是 "dgram","stream" 或"seqpacket"。使用者和組預設是0。
5. user <username>
在啟動這個服務前改變該服務的使用者名稱。此時預設為 root。
6. group <groupname> [<groupname> ]*
在啟動這個服務前改變該服務的組名。除了(必需的)第一個組名,附加的組名通常被用於設定程序的補充組(通過setgroups函式),檔案預設是root。
7. oneshot
服務退出時不重啟。
8. class <name>
指定一個服務類。所有同一類的服務可以同時啟動和停止。如果不通過class選項指定一個類,則預設為"default"類服務。
9. onrestart
當服務重啟,執行一個命令(下詳)。
init.rc指令碼分析
在上一篇文章中說過,init將動作執行的時間劃分為幾個階段,按照被執行的先後順序依次為:early-init、init、early-boot、boot。在init程序的main()方法中被呼叫的先後順序決定了它們的先後(直接原因), 根本原因是:各個階段的任務不同導致後面的對前面的有依賴,所以這裡的先後順序是不能亂調整的。
@system/core/init/init.c

early-init主要用於設定init程序(程序號為1)的oom_adj的值,以及啟動ueventd程序。oom_adj是Linux和Android中用來表示程序重要性的一個值,取值範圍為[-17, 15]。在Android中系統在殺死程序時會根據oom_adj和空閒記憶體大小作為依據,oom_adj越大越容易被殺死。
Android將程式分成以下幾類,按照重要性依次降低的順序:
| 名 稱 | oom_adj | 解釋 |
| FOREGROUD_APP | 0 | 前 臺程式,可以理解為你正在使用的程式 |
| VISIBLE_APP | 1 | 使用者可見的程式 |
| SECONDARY_SERVER | 2 | 後 臺服務,比如說QQ會在後臺執行服務 |
| HOME_APP | 4 | HOME,就是主介面 |
| HIDDEN_APP | 7 | 被 隱藏的程式 |
| CONTENT_PROVIDER | 14 | 內容提供者, |
| EMPTY_APP | 15 | 空程式,既不提供服務,也不提供內容 |
on early-init
# Set init and its forked children's oom_adj.
write /proc/1/oom_adj -16
# Set the security context for the init process.
# This should occur before anything else (e.g. ueventd) is started.
setcon u:r:init:s0
start ueventd在執行完early-init以後,接下來就是init階段。在init階段主要用來:設定環境變數,建立和掛在檔案節點。下面是init接的的不分程式碼截選:
@system/core/rootdir/init.environ.rc.in
# set up the global environment
on init
export PATH /sbin:/vendor/bin:/system/sbin:/system/bin:/system/xbin
export LD_LIBRARY_PATH /vendor/lib:/system/lib
export ANDROID_BOOTLOGO 1
export ANDROID_ROOT /system
export ANDROID_ASSETS /system/app
export ANDROID_DATA /data
export ANDROID_STORAGE /storage
export ASEC_MOUNTPOINT /mnt/asec
export LOOP_MOUNTPOINT /mnt/obb
export BOOTCLASSPATH %BOOTCLASSPATH%
以前設定環境變數這一段時在init.rc中的,現在放到了init.environ.rc.in,這樣程式碼也更清晰一些。
@system/core/rootdir/init.rc
on init
sysclktz 0
loglevel 3
# Backward compatibility
symlink /system/etc /etc
symlink /sys/kernel/debug /d
# Right now vendor lives on the same filesystem as system,
# but someday that may change.
symlink /system/vendor /vendor
# Create cgroup mount point for cpu accounting
mkdir /acct
mount cgroup none /acct cpuacct
mkdir /acct/uid
mkdir /system
mkdir /data 0771 system system
mkdir /cache 0770 system cache
mkdir /config 0500 root root接下來是fs相關的幾個過程,它們主要用於檔案系統的掛載,下面是擷取的一小部分程式碼:
on post-fs
# once everything is setup, no need to modify /
mount rootfs rootfs / ro remount
# mount shared so changes propagate into child namespaces
mount rootfs rootfs / shared rec
mount tmpfs tmpfs /mnt/secure private rec
# We chown/chmod /cache again so because mount is run as root + defaults
chown system cache /cache
chmod 0770 /cache
# We restorecon /cache in case the cache partition has been reset.
restorecon /cache如果你看過以前的版本的init.rc指令碼,看到這裡會想起,應該還有幾行:
mount yaffs2 [email protected] /system
mount yaffs2 [email protected] /data可以看出在Android 4.4中預設已經不再使用yaffs2。在完成檔案系統的建立和掛載後,完整的Android根檔案系統結構如下:

接下來看一下boot部分,該部分主要用於設定應用程式終止條件,應用程式驅動目錄及檔案許可權等。下面是一部分程式碼片段:
on boot
# basic network init
ifup lo
hostname localhost
domainname localdomain
# set RLIMIT_NICE to allow priorities from 19 to -20
setrlimit 13 40 40
# Memory management. Basic kernel parameters, and allow the high
# level system server to be able to adjust the kernel OOM driver
# parameters to match how it is managing things.
write /proc/sys/vm/overcommit_memory 1
write /proc/sys/vm/min_free_order_shift 4
chown root system /sys/module/lowmemorykiller/parameters/adj
chmod 0664 /sys/module/lowmemorykiller/parameters/adj
chown root system /sys/module/lowmemorykiller/parameters/minfree
chmod 0664 /sys/module/lowmemorykiller/parameters/minfree
class_start core
class_start main在on boot部分,我們可以發現許多”on property:<name> = <value>"的程式碼片段,這些是根據屬性的觸發器,但相應的屬性滿足一定的條件時,就會觸發相應的動作。此外,還有許多service欄位,service後面第一項表示服務的名稱,第二項表示服務的路徑,接下來的第2行等是服務的附加內容,配合服務使用,主要包含執行許可權、條件以及重啟等相關選項。
解析配置檔案
前面瞭解了init.rc指令碼的相關內容,接下來我們分析一下init程序是如何解析rc指令碼的。首先,在init程序的main()函式中呼叫init_parse_config_file()函式對屬性進行解析,下面就來看一下這個函式:init_parse_config_file("/init.rc");//解析init.rc配置檔案int init_parse_config_file(const char *fn)
{
char *data;
data = read_file(fn, 0);
if (!data) return -1;
parse_config(fn, data);
DUMP();
return 0;
}read_file(fn, 0)函式將fn指標指向的路徑(這裡即:/init.rc)所對應的檔案讀取到記憶體中,儲存為字串形式,並返回字串在記憶體中的地址;然後parse_config會對檔案進行解析,生成動作列表(Action List)和服務列表(Service List)。關於read_file()函式的實現在@system/core/init/util.c中。下面是parse_config()的實現:
static void parse_config(const char *fn, char *s)
{
struct parse_state state;
struct listnode import_list;//匯入連結串列,用於保持在init.rc中通過import匯入的其他rc檔案
struct listnode *node;
char *args[INIT_PARSER_MAXARGS];
int nargs;
nargs = 0;
state.filename = fn;//初始化filename的值為init.rc檔案
state.line = 0;//初始化行號為0
state.ptr = s;//初始化ptr指向s,即read_file讀入到記憶體中的init.rc檔案的首地址
state.nexttoken = 0;//初始化nexttoken的值為0
state.parse_line = parse_line_no_op;//初始化行解析函式
list_init(&import_list);
state.priv = &import_list;
for (;;) {
switch (next_token(&state)) {
case T_EOF://如果返回為T_EOF,表示init.rc已經解析完成,則跳到parser_done解析import進來的其他rc指令碼
state.parse_line(&state, 0, 0);
goto parser_done;
case T_NEWLINE:
state.line++;//一行讀取完成後,行號加1
if (nargs) {//如果剛才解析的一行為語法行(非註釋等),則nargs的值不為0,需要對這一行進行語法解析
int kw = lookup_keyword(args[0]);//init.rc中每一個語法行均是以一個keyword開頭的,因此args[0]即表示這一行的keyword
if (kw_is(kw, SECTION)) {
state.parse_line(&state, 0, 0);
parse_new_section(&state, kw, nargs, args);
} else {
state.parse_line(&state, nargs, args);
}
nargs = 0;//復位
}
break;
case T_TEXT://將nexttoken解析的一個text儲存到args字串陣列中,nargs的最大值為INIT_PARSER_MAXARGS(64),即init.rc中一行最多不能超過INIT_PARSER_MAXARGS個text(單詞)
if (nargs < INIT_PARSER_MAXARGS) {
args[nargs++] = state.text;
}
break;
}
}
parser_done:
list_for_each(node, &import_list) {
struct import *import = node_to_item(node, struct import, list);
int ret;
INFO("importing '%s'", import->filename);
ret = init_parse_config_file(import->filename);
if (ret)
ERROR("could not import file '%s' from '%s'\n",
import->filename, fn);
}
}parse_config()函式,程式碼雖然很短,實際上卻比較複雜。接下來將對其進行詳細分析。首先看一下struct parse_state的定義:
struct parse_state
{
char *ptr;//指標,指向剩餘的尚未被解析的資料(即:ptr指向當前解析到的位置)
char *text;//一行文字
int line; //行號
int nexttoken;//下一行的標示,T_EOF標示檔案結束,T_TEXT表示需要進行解釋的文字,T_NEWLINE標示一個空行或者是註釋行
void *context;//一個action或者service
void (*parse_line)(struct parse_state *state, int nargs, char **args);//函式指標,指向當前行的解析函式
const char *filename;//解析的rc檔案
void *priv;//執行import連結串列的指標
};next_token()以行為單位分割引數傳遞過來的字串。
@system/core/init/parser.c
int next_token(struct parse_state *state)
{
char *x = state->ptr;
char *s;
if (state->nexttoken) {//nexttoken的值為0
int t = state->nexttoken;
state->nexttoken = 0;
return t;
}
for (;;) {
switch (*x) {
case 0://到底末尾,解析完成
state->ptr = x;
return T_EOF;
case '\n'://換行符,返回T_NEWLINE,表示下一個token是新的一行
x++;
state->ptr = x;
return T_NEWLINE;
case ' '://忽略空格、製表符等
case '\t':
case '\r':
x++;
continue;
case '#'://在當前解析到的字元為#號時,將指標一直移動到#行的末尾,然後判斷下一個字元是T_NEWLINE還是T_EOF
while (*x && (*x != '\n')) x++;//注意x++,當指標移動到#行末尾時,x執行末尾的下一個字元
if (*x == '\n') {
state->ptr = x+1;
return T_NEWLINE;
} else {
state->ptr = x;
return T_EOF;
}
default:
goto text;//解析的為普通文字
}
}
textdone://x指向一個單詞的開頭位置,s指向末尾位置,將s設定為0(C字串末尾為0),即表示單詞結束
state->ptr = x;
*s = 0;
return T_TEXT;
text:
state->text = s = x;
textresume:
for (;;) {
switch (*x) {
case 0:
goto textdone;
case ' ':
case '\t':
case '\r':
x++;
goto textdone;
case '\n':
state->nexttoken = T_NEWLINE;
x++;
goto textdone;
case '"':
x++;
for (;;) {
switch (*x) {
case 0:
/* unterminated quoted thing */
state->ptr = x;
return T_EOF;
case '"':
x++;
goto textresume;
default:
*s++ = *x++;
}
}
break;
case '\\':
x++;
switch (*x) {
case 0:
goto textdone;
case 'n':
*s++ = '\n';
break;
case 'r':
*s++ = '\r';
break;
case 't':
*s++ = '\t';
break;
case '\\':
*s++ = '\\';
break;
case '\r':
/* \ <cr> <lf> -> line continuation */
if (x[1] != '\n') {
x++;
continue;
}
case '\n':
/* \ <lf> -> line continuation */
state->line++;
x++;
/* eat any extra whitespace */
while((*x == ' ') || (*x == '\t')) x++;
continue;
default:
/* unknown escape -- just copy */
*s++ = *x++;
}
continue;
default:
*s++ = *x++;
}
}
return T_EOF;
}在parse_config()中通過next_token從rc指令碼中解析出一行行的rc語句,下面看一下另一個重要的函式lookup_keyword()的實現:
int lookup_keyword(const char *s)
{
switch (*s++) {
case 'c':
if (!strcmp(s, "opy")) return K_copy;
if (!strcmp(s, "apability")) return K_capability;
if (!strcmp(s, "hdir")) return K_chdir;
if (!strcmp(s, "hroot")) return K_chroot;
if (!strcmp(s, "lass")) return K_class;
if (!strcmp(s, "lass_start")) return K_class_start;
if (!strcmp(s, "lass_stop")) return K_class_stop;
if (!strcmp(s, "lass_reset")) return K_class_reset;
if (!strcmp(s, "onsole")) return K_console;
if (!strcmp(s, "hown")) return K_chown;
if (!strcmp(s, "hmod")) return K_chmod;
if (!strcmp(s, "ritical")) return K_critical;
break;
case 'd':
if (!strcmp(s, "isabled")) return K_disabled;
if (!strcmp(s, "omainname")) return K_domainname;
break;
case 'e':
if (!strcmp(s, "xec")) return K_exec;
if (!strcmp(s, "xport")) return K_export;
break;
case 'g':
if (!strcmp(s, "roup")) return K_group;
break;
case 'h':
if (!strcmp(s, "ostname")) return K_hostname;
break;
case 'i':
if (!strcmp(s, "oprio")) return K_ioprio;
if (!strcmp(s, "fup")) return K_ifup;
if (!strcmp(s, "nsmod")) return K_insmod;
if (!strcmp(s, "mport")) return K_import;
break;
case 'k':
if (!strcmp(s, "eycodes")) return K_keycodes;
break;
case 'l':
if (!strcmp(s, "oglevel")) return K_loglevel;
if (!strcmp(s, "oad_persist_props")) return K_load_persist_props;
break;
case 'm':
if (!strcmp(s, "kdir")) return K_mkdir;
if (!strcmp(s, "ount_all")) return K_mount_all;
if (!strcmp(s, "ount")) return K_mount;
break;
case 'o':
if (!strcmp(s, "n")) return K_on;
if (!strcmp(s, "neshot")) return K_oneshot;
if (!strcmp(s, "nrestart")) return K_onrestart;
break;
case 'p':
if (!strcmp(s, "owerctl")) return K_powerctl;
case 'r':
if (!strcmp(s, "estart")) return K_restart;
if (!strcmp(s, "estorecon")) return K_restorecon;
if (!strcmp(s, "mdir")) return K_rmdir;
if (!strcmp(s, "m")) return K_rm;
break;
case 's':
if (!strcmp(s, "eclabel")) return K_seclabel;
if (!strcmp(s, "ervice")) return K_service;
if (!strcmp(s, "etcon")) return K_setcon;
if (!strcmp(s, "etenforce")) return K_setenforce;
if (!strcmp(s, "etenv")) return K_setenv;
if (!strcmp(s, "etkey")) return K_setkey;
if (!strcmp(s, "etprop")) return K_setprop;
if (!strcmp(s, "etrlimit")) return K_setrlimit;
if (!strcmp(s, "etsebool")) return K_setsebool;
if (!strcmp(s, "ocket")) return K_socket;
if (!strcmp(s, "tart")) return K_start;
if (!strcmp(s, "top")) return K_stop;
if (!strcmp(s, "wapon_all")) return K_swapon_all;
if (!strcmp(s, "ymlink")) return K_symlink;
if (!strcmp(s, "ysclktz")) return K_sysclktz;
break;
case 't':
if (!strcmp(s, "rigger")) return K_trigger;
break;
case 'u':
if (!strcmp(s, "ser")) return K_user;
break;
case 'w':
if (!strcmp(s, "rite")) return K_write;
if (!strcmp(s, "ait")) return K_wait;
break;
}
return K_UNKNOWN;
} case T_NEWLINE:
state.line++;//一行讀取完成後,行號加1
if (nargs) {//如果剛才解析的一行為語法行(非註釋等),則nargs的值不為0,需要對這一行進行語法解析
int kw = lookup_keyword(args[0]);//init.rc中每一個語法行均是以一個keyword開頭的,因此args[0]即表示這一行的keyword
if (kw_is(kw, SECTION)) {
state.parse_line(&state, 0, 0);
parse_new_section(&state, kw, nargs, args);
} else {
state.parse_line(&state, nargs, args);
}
nargs = 0;//復位
}
break;在parse_config()中,在找的keyword以後,接下來會判斷這個keyword是否是section,是則走解析section的邏輯,否則走其他邏輯。下面我們看一下kw_is的實現:
#define kw_is(kw, type) (keyword_info[kw].flags & (type))關鍵字定義
@system/core/init/keywords.h#ifndef KEYWORD//如果沒有定義KEYWORD則執行下面的分支
//宣告一些函式,這些函式即Action的執行函式
int do_chroot(int nargs, char **args);
int do_chdir(int nargs, char **args);
int do_class_start(int nargs, char **args);
int do_class_stop(int nargs, char **args);
int do_class_reset(int nargs, char **args);
int do_domainname(int nargs, char **args);
int do_exec(int nargs, char **args);
int do_export(int nargs, char **args);
int do_hostname(int nargs, char **args);
int do_ifup(int nargs, char **args);
int do_insmod(int nargs, char **args);
int do_mkdir(int nargs, char **args);
int do_mount_all(int nargs, char **args);
int do_mount(int nargs, char **args);
int do_powerctl(int nargs, char **args);
int do_restart(int nargs, char **args);
int do_restorecon(int nargs, char **args);
int do_rm(int nargs, char **args);
int do_rmdir(int nargs, char **args);
int do_setcon(int nargs, char **args);
int do_setenforce(int nargs, char **args);
int do_setkey(int nargs, char **args);
int do_setprop(int nargs, char **args);
int do_setrlimit(int nargs, char **args);
int do_setsebool(int nargs, char **args);
int do_start(int nargs, char **args);
int do_stop(int nargs, char **args);
int do_swapon_all(int nargs, char **args);
int do_trigger(int nargs, char **args);
int do_symlink(int nargs, char **args);
int do_sysclktz(int nargs, char **args);
int do_write(int nargs, char **args);
int do_copy(int nargs, char **args);
int do_chown(int nargs, char **args);
int do_chmod(int nargs, char **args);
int do_loglevel(int nargs, char **args);
int do_load_persist_props(int nargs, char **args);
int do_wait(int nargs, char **args);
#define __MAKE_KEYWORD_ENUM__//定義一個巨集
/*
* 定義KEYWORD巨集,這裡KEYWORD巨集中有四個引數,其各自的含義如下:
* symbol表示keyword的名稱(即init.rc中的關鍵字);
* flags表示keyword的型別,包括SECTION、COMMAND和OPTION三種類型,其定義在init_parser.c中;
* nargs表示引數的個數,即:該keyword需要幾個引數
* func表示該keyword所對應的處理函式。
*
* KEYWORD巨集雖然有四個引數,但是這裡只用到了symbol,其中K_##symbol中的##表示連線的意思,
* 即最後的得到的值為K_symbol。
*/
#define KEYWORD(symbol, flags, nargs, func) K_##symbol,
enum {
K_UNKNOWN,
#endif
KEYWORD(capability, OPTION, 0, 0)//根據上面KEYWORD的巨集定義,這一行就變成了K_capability,
KEYWORD(chdir, COMMAND, 1, do_chdir)//key_chdir,後面的依次類推
KEYWORD(chroot, COMMAND, 1, do_chroot)
KEYWORD(class, OPTION, 0, 0)
KEYWORD(class_start, COMMAND, 1, do_class_start)
KEYWORD(class_stop, COMMAND, 1, do_class_stop)
KEYWORD(class_reset, COMMAND, 1, do_class_reset)
KEYWORD(console, OPTION, 0, 0)
KEYWORD(critical, OPTION, 0, 0)
KEYWORD(disabled, OPTION, 0, 0)
KEYWORD(domainname, COMMAND, 1, do_domainname)
KEYWORD(exec, COMMAND, 1, do_exec)
KEYWORD(export, COMMAND, 2, do_export)
KEYWORD(group, OPTION, 0, 0)
KEYWORD(hostname, COMMAND, 1, do_hostname)
KEYWORD(ifup, COMMAND, 1, do_ifup)
KEYWORD(insmod, COMMAND, 1, do_insmod)
KEYWORD(import, SECTION, 1, 0)
KEYWORD(keycodes, OPTION, 0, 0)
KEYWORD(mkdir, COMMAND, 1, do_mkdir)
KEYWORD(mount_all, COMMAND, 1, do_mount_all)
KEYWORD(mount, COMMAND, 3, do_mount)
KEYWORD(on, SECTION, 0, 0)
KEYWORD(oneshot, OPTION, 0, 0)
KEYWORD(onrestart, OPTION, 0, 0)
KEYWORD(powerctl, COMMAND, 1, do_powerctl)
KEYWORD(restart, COMMAND, 1, do_restart)
KEYWORD(restorecon, COMMAND, 1, do_restorecon)
KEYWORD(rm, COMMAND, 1, do_rm)
KEYWORD(rmdir, COMMAND, 1, do_rmdir)
KEYWORD(seclabel, OPTION, 0, 0)
KEYWORD(service, SECTION, 0, 0)
KEYWORD(setcon, COMMAND, 1, do_setcon)
KEYWORD(setenforce, COMMAND, 1, do_setenforce)
KEYWORD(setenv, OPTION, 2, 0)
KEYWORD(setkey, COMMAND, 0, do_setkey)
KEYWORD(setprop, COMMAND, 2, do_setprop)
KEYWORD(setrlimit, COMMAND, 3, do_setrlimit)
KEYWORD(setsebool, COMMAND, 2, do_setsebool)
KEYWORD(socket, OPTION, 0, 0)
KEYWORD(start, COMMAND, 1, do_start)
KEYWORD(stop, COMMAND, 1, do_stop)
KEYWORD(swapon_all, COMMAND, 1, do_swapon_all)
KEYWORD(trigger, COMMAND, 1, do_trigger)
KEYWORD(symlink, COMMAND, 1, do_symlink)
KEYWORD(sysclktz, COMMAND, 1, do_sysclktz)
KEYWORD(user, OPTION, 0, 0)
KEYWORD(wait, COMMAND, 1, do_wait)
KEYWORD(write, COMMAND, 2, do_write)
KEYWORD(copy, COMMAND, 2, do_copy)
KEYWORD(chown, COMMAND, 2, do_chown)
KEYWORD(chmod, COMMAND, 2, do_chmod)
KEYWORD(loglevel, COMMAND, 1, do_loglevel)
KEYWORD(load_persist_props, COMMAND, 0, do_load_persist_props)
KEYWORD(ioprio, OPTION, 0, 0)
#ifdef __MAKE_KEYWORD_ENUM__
KEYWORD_COUNT,
};
#undef __MAKE_KEYWORD_ENUM__
#undef KEYWORD//取消KEYWORD巨集的定義
#endif看一下keyword在init_parse.c中是如何被使用的:
#include "keywords.h"
#define KEYWORD(symbol, flags, nargs, func) \
[ K_##symbol ] = { #symbol, func, nargs + 1, flags, },
struct {
const char *name;//關鍵字的名稱
int (*func)(int nargs, char **args);//對應關鍵字的處理函式
unsigned char nargs;//引數個數,每個關鍵字的引數個數是固定的
unsigned char flags;//關鍵字屬性,包括:SECTION、OPTION和COMMAND,其中COMMAND有對應的處理函式,見keyword的定義。
} keyword_info[KEYWORD_COUNT] = {
[ K_UNKNOWN ] = { "unknown", 0, 0, 0 },
#include "keywords.h"
};
#undef KEYWORD
#define kw_is(kw, type) (keyword_info[kw].flags & (type))
#define kw_name(kw) (keyword_info[kw].name)
#define kw_func(kw) (keyword_info[kw].func)
#define kw_nargs(kw) (keyword_info[kw].nargs)- 第一次包含keywords.h時,它聲明瞭一些諸如do_class_start的函式,另外還定義了一個列舉,列舉值為K_class、K_mkdir等關鍵字。
- 第二次包含keywords.h後,得到了keyword_info結構體陣列,這個keyword_info結構體陣列以前定義的列舉值為索引,儲存對應的關鍵字資訊。
#define SECTION 0x01
#define COMMAND 0x02
#define OPTION 0x04在瞭解了keyword後,下面我們繼續來分析rc指令碼的解析,讓我們回到之前的程式碼,繼續分析。
case T_NEWLINE:
state.line++;//一行讀取完成後,行號加1
if (nargs) {//如果剛才解析的一行為語法行(非註釋等),則nargs的值不為0,需要對這一行進行語法解析
int kw = lookup_keyword(args[0]);//init.rc中每一個語法行均是以一個keyword開頭的,因此args[0]即表示這一行的keyword
if (kw_is(kw, SECTION)) {
state.parse_line(&state, 0, 0);
parse_new_section(&state, kw, nargs, args);
} else {
state.parse_line(&state, nargs, args);
}
nargs = 0;//復位
}
break;void parse_new_section(struct parse_state *state, int kw,
int nargs, char **args)
{
printf("[ %s %s ]\n", args[0],
nargs > 1 ? args[1] : "");
switch(kw) {
case K_service://解析Service
state->context = parse_service(state, nargs, args);//當service_list中不存在同名service時,執行新加入service_list中的service
if (state->context) {//service為新增加的service時,即:<span style="font-family: Arial, Helvetica, sans-serif;">service_list中不存在同名service</span>
state->parse_line = parse_line_service;//制定解析service行的函式為<span style="font-family: Arial, Helvetica, sans-serif;">parse_line_service</span>
return;
}
break;
case K_on://解析section
state->context = parse_action(state, nargs, args);
if (state->context) {
state->parse_line = parse_line_action;
return;
}
break;
case K_import://解析import
parse_import(state, nargs, args);
break;
}
state->parse_line = parse_line_no_op;
}先看一下service的解析:
static void *parse_service(struct parse_state *state, int nargs, char **args)
{
struct service *svc;//保持Service相關資訊
if (nargs < 3) {
parse_error(state, "services must have a name and a program\n");
return 0;
}
if (!valid_name(args[1])) {
parse_error(state, "invalid service name '%s'\n", args[1]);
return 0;
}
//service_list中是否已存在同名service<span style="white-space:pre"> </span>
svc = service_find_by_name(args[1]);
if (svc) {//<span style="font-family: Arial, Helvetica, sans-serif;">如果已存在同名service則直接返回,不再做其他操作</span>
parse_error(state, "ignored duplicate definition of service '%s'\n", args[1]);
return 0;
}
nargs -= 2;
svc = calloc(1, sizeof(*svc) + sizeof(char*) * nargs);
if (!svc) {
parse_error(state, "out of memory\n");
return 0;
}
svc->name = args[1];
svc->classname = "default";//設定classname為“default”
memcpy(svc->args, args + 2, sizeof(char*) * nargs);
svc->args[nargs] = 0;
svc->nargs = nargs;
svc->onrestart.name = "onrestart";
list_init(&svc->onrestart.commands);
list_add_tail(&service_list, &svc->slist);//將service新增到全域性連結串列service_list中
return svc;
}@system/core/init/init.h
struct service {
/* list of all services */
struct listnode slist;//雙向連結串列
const char *name;//service的名字
const char *classname;//service所屬class的名字,預設是“default”
unsigned flags;//service的屬性
pid_t pid;//程序號
time_t time_started; /* time of last start 上一次啟動的時間*/
time_t time_crashed; /* first crash within inspection window 第一次死亡的時間*/
int nr_crashed; /* number of times crashed within window 死亡次數*/
uid_t uid;
gid_t gid;
gid_t supp_gids[NR_SVC_SUPP_GIDS];
size_t nr_supp_gids;
char *seclabel;
struct socketinfo *sockets;//有些service需要使用socket,socketinfo用來描述socket相關資訊
struct svcenvinfo *envvars;//service一般執行在一個單獨的程序中,envvars用來描述建立這個程序時所需的環境變數資訊
//關鍵字onrestart標示一個OPTION,可是onrestart後面一般跟著COMMAND,下面這個action結構體可用來儲存command資訊
struct action onrestart; /* Actions to execute on restart. */
/* keycodes for triggering this service via /dev/keychord */
int *keycodes;
int nkeycodes;
int keychord_id;
int ioprio_class;
int ioprio_pri;
int nargs;//引數個數
/* "MUST BE AT THE END OF THE STRUCT" */
char *args[1];//用於儲存引數
}; /* ^-------'args' MUST be at the end of this struct! */從parse_service函式可以看出,它的作用就是講service新增到service_list列表中,並制定解析函式為parse_line_service,也就是說具體的service的解析靠的是parse_line_service方法。
static void parse_line_service(struct parse_state *state, int nargs, char **args)
{
struct service *svc = state->context;
struct command *cmd;
int i, kw, kw_nargs;
if (nargs == 0) {
return;
}
svc->ioprio_class = IoSchedClass_NONE;
kw = lookup_keyword(args[0]);
switch (kw) {
case K_capability:
break;
case K_class:
if (nargs != 2) {
parse_error(state, "class option requires a classname\n");
} else {
svc->classname = args[1];
}
break;
case K_console:
svc->flags |= SVC_CONSOLE;
break;
case K_disabled:
svc->flags |= SVC_DISABLED;
svc->flags |= SVC_RC_DISABLED;
break;
case K_ioprio:
if (nargs != 3) {
parse_error(state, "ioprio optin usage: ioprio <rt|be|idle> <ioprio 0-7>\n");
} else {
svc->ioprio_pri = strtoul(args[2], 0, 8);
if (svc->ioprio_pri < 0 || svc->ioprio_pri > 7) {
parse_error(state, "priority value must be range 0 - 7\n");
break;
}
if (!strcmp(args[1], "rt")) {
svc->ioprio_class = IoSchedClass_RT;
} else if (!strcmp(args[1], "be")) {
svc->ioprio_class = IoSchedClass_BE;
} else if (!strcmp(args[1], "idle")) {
svc->ioprio_class = IoSchedClass_IDLE;
} else {
parse_error(state, "ioprio option usage: ioprio <rt|be|idle> <0-7>\n");
}
}
break;
case K_group:
if (nargs < 2) {
parse_error(state, "group option requires a group id\n");
} else if (nargs > NR_SVC_SUPP_GIDS + 2) {
parse_error(state, "group option accepts at most %d supp. groups\n",
NR_SVC_SUPP_GIDS);
} else {
int n;
svc->gid = decode_uid(args[1]);
for (n = 2; n < nargs; n++) {
svc->supp_gids[n-2] = decode_uid(args[n]);
}
svc->nr_supp_gids = n - 2;
}
break;
case K_keycodes:
if (nargs < 2) {
parse_error(state, "keycodes option requires atleast one keycode\n");
} else {
svc->keycodes = malloc((nargs - 1) * sizeof(svc->keycodes[0]));
if (!svc->keycodes) {
parse_error(state, "could not allocate keycodes\n");
} else {
svc->nkeycodes = nargs - 1;
for (i = 1; i < nargs; i++) {
svc->keycodes[i - 1] = atoi(args[i]);
}
}
}
break;
case K_oneshot:
svc->flags |= SVC_ONESHOT;
break;
case K_onrestart:
nargs--;
args++;
kw = lookup_keyword(args[0]);
if (!kw_is(kw, COMMAND)) {
parse_error(state, "invalid command '%s'\n", args[0]);
break;
}
kw_nargs = kw_nargs(kw);
if (nargs < kw_nargs) {
parse_error(state, "%s requires %d %s\n", args[0], kw_nargs - 1,
kw_nargs > 2 ? "arguments" : "argument");
break;
}
cmd = malloc(sizeof(*cmd) + sizeof(char*) * nargs);
cmd->func = kw_func(kw);
cmd->nargs = nargs;
memcpy(cmd->args, args, sizeof(char*) * nargs);
list_add_tail(&svc->onrestart.commands, &cmd->clist);
break;
case K_critical:
svc->flags |= SVC_CRITICAL;
break;
case K_setenv: { /* name value */
struct svcenvinfo *ei;
if (nargs < 2) {
parse_error(state, "setenv option requires name and value arguments\n");
break;
}
ei = calloc(1, sizeof(*ei));
if (!ei) {
parse_error(state, "out of memory\n");
break;
}
ei->name = args[1];
ei->value = args[2];
ei->next = svc->envvars;
svc->envvars = ei;
break;
}
case K_socket: {/* name type perm [ uid gid ] */
struct socketinfo *si;
if (nargs < 4) {
parse_error(state, "socket option requires name, type, perm arguments\n");
break;
}
if (strcmp(args[2],"dgram") && strcmp(args[2],"stream")
&& strcmp(args[2],"seqpacket")) {
parse_error(state, "socket type must be 'dgram', 'stream' or 'seqpacket'\n");
break;
}
si = calloc(1, sizeof(*si));
if (!si) {
parse_error(state, "out of memory\n");
break;
}
si->name = args[1];
si->type = args[2];
si->perm = strtoul(args[3], 0, 8);
if (nargs > 4)
si->uid = decode_uid(args[4]);
if (nargs > 5)
si->gid = decode_uid(args[5]);
si->next = svc->sockets;
svc->sockets = si;
break;
}
case K_user:
if (nargs != 2) {
parse_error(state, "user option requires a user id\n");
} else {
svc->uid = decode_uid(args[1]);
}
break;
case K_seclabel:
if (nargs != 2) {
parse_error(state, "seclabel option requires a label string\n");
} else {
svc->seclabel = args[1];
}
break;
default:
parse_error(state, "invalid option '%s'\n", args[0]);
}
}section的處理與service類似,通過分析init.rc的解析過程,我們知道,所謂的解析就是將rc指令碼中的內容通過解析,填充到service_list和action_list中去。那他們是在哪裡進行呼叫的呢,讓我們回憶一下init程序中main函式的實現。
INFO("reading config file\n");
init_parse_config_file("/init.rc");//解析init.rc配置檔案
action_for_each_trigger("early-init", action_add_queue_tail);
queue_builtin_action(wait_for_coldboot_done_action, "wait_for_coldboot_done");
queue_builtin_action(mix_hwrng_into_linux_rng_action, "mix_hwrng_into_linux_rng");
queue_builtin_action(keychord_init_action, "keychord_init");
queue_builtin_action(console_init_action, "console_init");
/* execute all the boot actions to get us started */
action_for_each_trigger("init", action_add_queue_tail);
/* skip mounting filesystems in charger mode */
if (!is_charger) {
action_for_each_trigger("early-fs", action_add_queue_tail);
action_for_each_trigger("fs", action_add_queue_tail);
action_for_each_trigger("post-