
Python網路爬蟲筆記(7)處理HTTPS請求 SSL證書驗證
現在隨處可見 https 開頭的網站,urllib2可以為 HTTPS 請求驗證SSL證書,就像web瀏覽器一樣,如果網站的SSL證書是經過CA認證的,則能夠正常訪問,如:https://www.baidu.com/等...
如果SSL證書驗證不通過,或者作業系統不信任伺服器的安全證書,比如瀏覽器在訪問12306網站如:https://www.12306.cn/mormhweb/的時候,會警告使用者證書不受信任。(據說 12306 網站證書是自己做的,沒有通過CA認證)
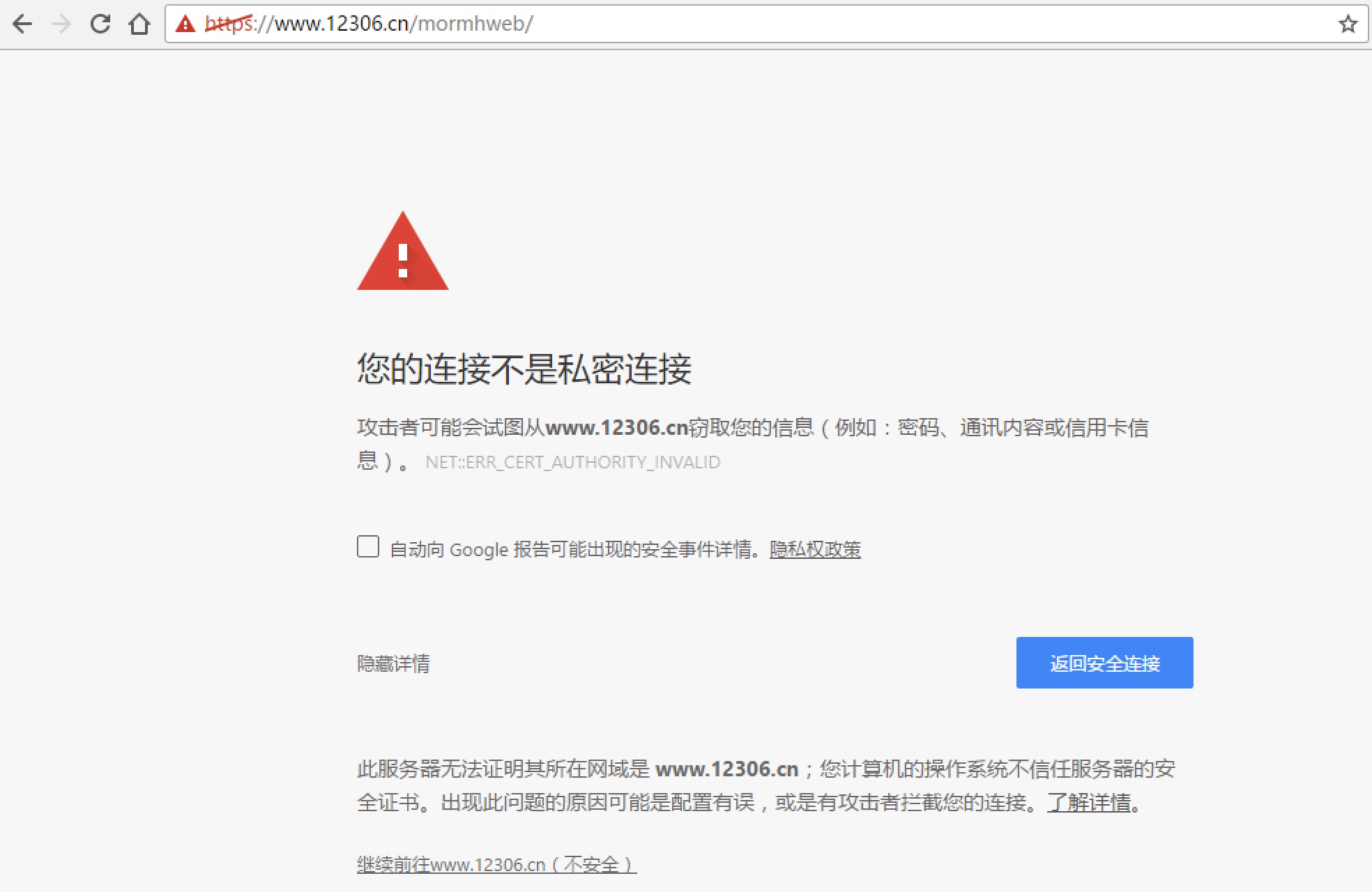
urllib2在訪問的時候則會報出SSLError:
import urllib2
url = "https://www.12306.cn/mormhweb/" 執行結果:
urllib2.URLError: <urlopen error [SSL: CERTIFICATE_VERIFY_FAILED] certificate verify failed (_ssl.c:590)>
所以,如果以後遇到這種網站,我們需要單獨處理SSL證書,讓程式忽略SSL證書驗證錯誤,即可正常訪問。
import urllib
import urllib2
# 1. 匯入Python SSL處理模組
import ssl
# 2. 表示忽略未經核實的SSL證書認證
context = ssl._create_unverified_context()
url = "https://www.12306.cn/mormhweb/"
headers = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/54.0.2840.99 Safari/537.36" 關於CA
CA(Certificate Authority)是數字證書認證中心的簡稱,是指發放、管理、廢除數字證書的受信任的第三方機構,如北京數字認證股份有限公司、上海市數字證書認證中心有限公司等...
CA的作用是檢查證書持有者身份的合法性,並簽發證書,以防證書被偽造或篡改,以及對證書和金鑰進行管理。
現實生活中可以用身份證來證明身份, 那麼在網路世界裡,數字證書就是身份證。和現實生活不同的是,並不是每個上網的使用者都有數字證書的,往往只有當一個人需要證明自己的身份的時候才需要用到數字證書。
普通使用者一般是不需要,因為網站並不關心是誰訪問了網站,現在的網站只關心流量。但是反過來,網站就需要證明自己的身份了。
比如說現在釣魚網站很多的,比如你想訪問的是www.baidu.com,但其實你訪問的是www.daibu.com”,所以在提交自己的隱私資訊之前需要驗證一下網站的身份,要求網站出示數字證書。
一般正常的網站都會主動出示自己的數字證書,來確保客戶端和網站伺服器之間的通訊資料是加密安全的。
相關推薦
Python網路爬蟲筆記(7)處理HTTPS請求 SSL證書驗證
現在隨處可見 https 開頭的網站,urllib2可以為 HTTPS 請求驗證SSL證書,就像web瀏覽器一樣,如果網站的SSL證書是經過CA認證的,則能夠正常訪問,如:https://www.baidu.com/等...如果SSL證書驗證不通過,或者作業系統不信任伺服器的
處理HTTPS請求 SSL證書驗證
現在隨處可見 https 開頭的網站,urllib2可以為 HTTPS 請求驗證SSL證書,就像web瀏覽器一樣,如果網站的SSL證書是經過CA認證的,則能夠正常訪問,如:https://www.baidu.com/等...如果SSL證書驗證不通過,或者作業系統不信任伺服器的安全證書,比如瀏覽器在訪
網路爬蟲筆記(Day6)——妹子圖
利用多程序爬取妹子圖:http://www.mzitu.com 完整程式碼如下: 程序,參看博文 程序和執行緒——Python中的實現 import requests from lxml import etree import os import mul
網路爬蟲筆記(Day5)——騰訊社招&拉勾網
分析過程與鏈家是一樣的。 騰訊社招完整程式碼如下: import requests from lxml import etree from mysql_class import Mysql # 自己封裝好的Mysql類 def txshezhao(keywords, page):
網路爬蟲筆記(Day5)——鏈家
注意:請不要爬取過多資訊,僅供學習。 分析: 業務需求分析......(此例為住房資訊...) 查詢相關網頁資訊(以鏈家為例) 分析URL,查詢我們需要的內容,建立連線 定位資料 儲存資料 首先進入鏈家網首頁,點選租房,F12檢查網頁,查詢我們需要的資訊
網路爬蟲筆記(Day4)
爬取今日頭條圖集 進入今日頭條首頁:https://www.toutiao.com/ 步驟:1、檢視網頁,查詢我們需要的URL,分析URL
網路爬蟲筆記(Day3)
首先分析 雪球網 https://xueqiu.com/#/property 第一次進去後,第一次Ajax請求得到的是 若下圖所示的 max_id=-1, count=10。 然後往下拉,第二次Ajax請求,如下圖; 發現URL裡面就max_id 和count不同,
網路爬蟲筆記(Day8)——IP代理
可以去某寶或其他渠道購買,具體使用看自己購買商家的API文件,檢視使用方法。 ip_proxy.py import requests class ip_getter(object): def __init__(self): self.ip_proxy_str =
網路爬蟲筆記(Day8)——BeautifulSoup
BeautifulSoup 我們到網站上爬取資料,需要知道什麼樣的資料是我們想要爬取的,什麼樣的資料是網頁上不會變化的。 Beautiful Soup提供一些簡單的、python式的函式用來處理導航、搜尋、修改分析樹等功能。它是一個工具箱,通過解析文件為使用者提供需要抓取的資料,因為
網路爬蟲筆記(Day7)——Selenium
首先下載chromedriver 將其放入Python執行環境下,然後再去pip安裝selenium。 最簡單的結構 程式碼如下: from selenium import webdriver # ----------------------不開啟瀏覽器視窗-------------
Python 網路爬蟲學習(一)
最近在學習一些Python網路爬蟲的東西,現將所學習內容整理如下,希望與大家相互交流,共同進步。 一、網路爬蟲基本概念 1.網路爬蟲(Web Spider) 是通過網頁的連結地址來尋找網頁的。從網站某一個頁面(通常是首頁)開始,讀取網頁的內
用Python寫網路爬蟲系列(三)表單處理
import urllib,urllib2 LOGIN_URL = r'http://example.webscraping.com/user/login' LOGIN_EMAIL = '[email protected]' LOGIN_PASSWORD ='q
python網絡爬蟲筆記(四)
inf 比較 小寫字母 網絡爬蟲 作用 自定義 gpo 外部 而且 一、python中的高階函數算法 1、sorted()函數的排序 sorted()函數是一個高階函數,還可以接受一個key函數來實現自定義的函數排序,key指定的函數作用於每個序列元素上,並根據key函
python網絡爬蟲筆記(九)
out 模塊 ade npe tex visible 代碼 端口號 pac 4.1.1 urllib2 和urllib是兩個不一樣的模塊 urllib2最簡單的就是使用urllie2.urlopen函數使用如下 urllib2.urlopen(url[,
Python網絡爬蟲筆記(五):下載、分析京東P20銷售數據
9.png amp F12 不存在 strong xls sco 列表 std (一) 分析網頁 下載下面這個鏈接的銷售數據 https://item.jd.com/6733026.html#comment 1、 翻頁的時候,谷歌F12的Network頁簽可以
python | 爬蟲筆記(五)- 數據存儲
height iter use jordan rip 輕量 數據存儲 回滾 nosql 5.1 文件存儲 先用request把源碼獲取,再用解析庫解析,保存到文本 1- txt 文本打開方式: file = open(‘explore.txt‘, ‘a‘, encodin
python | 爬蟲筆記 - (八)Scrapy入門教程
RoCE yield ini 配置 自己 數據存儲 2.3 rom 提取數據 一、簡介 Scrapy是一個基於Twisted 的異步處理框架,是針對爬蟲過程中的網站數據爬取、結構性數據提取而編寫的應用框架。 可以應用在包括數據挖掘,信息處理或存儲歷史數據等一系列的程序中。
Python網路資料爬取----網路爬蟲基礎(一)
The website is the API......(未來的資料都是通過網路來提供的,website本身對爬蟲來講就是自動獲取資料的API)。掌握定向網路資料爬取和網頁解析的基本能力。 ##Requests 庫的使用,此庫是Python公認的優秀的第三方網路爬蟲庫。能夠自動的爬取HTML頁面;自動的
影象處理基本概念筆記(7)
七、 119、影象處理方法 影象處理技術就是利用計算機、攝像機及其他數字處理技術對影象施加某種運算和處理,以提取影象中的各種資訊,從而達到某種特定目的的技術。 影象處理技術具有再現性好、精度高、適用面寬等特點。現有影象處理方法包括點運算、濾波、全域性優化、幾何變換等 ,應用十分廣泛。
Python時間序列LSTM預測系列學習筆記(7)-多變數
本文是對: https://machinelearningmastery.com/multivariate-time-series-forecasting-lstms-keras/ https://blog.csdn.net/iyangdi/article/details/77877410