
Hbase 日常運維監控效能指標調優
1.1監控Hbase執行狀況
1.1.1作業系統
1.1.1.1IO
a.群集網路IO,磁碟IO,HDFS IO
IO越大說明檔案讀寫操作越多。當IO突然增加時,有可能:1.compact佇列較大,叢集正在進行大量壓縮操作。
2.正在執行mapreduce作業
可以通過CDH前臺檢視整個叢集綜合的資料或進入指定機器的前臺檢視單臺機器的資料: 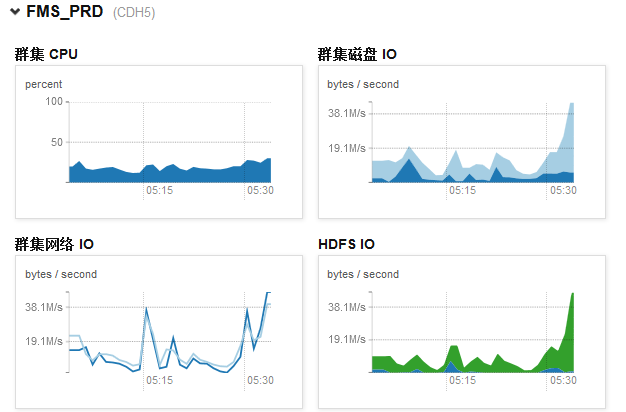
b.Io wait
磁碟IO對叢集的影響比較大,如果io wait時間過長需檢查系統或磁碟是否有異常。通常IO增加時io wait也會增加,現在FMS的機器正常情況io wait在50ms以下
跟主機相關的指標可以在CDH前臺左上角先點“主機”選項卡然後選要檢視的主機:
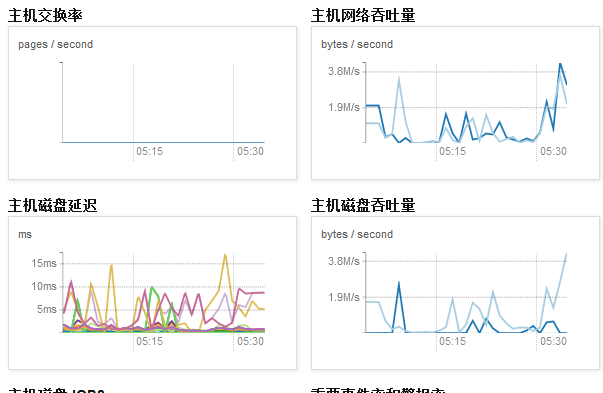
1.1.1.2CPU
如果CPU佔用過高有可能是異常情況引起叢集資源消耗,可以通過其他指標和日誌來檢視叢集正在做什麼。
1.1.1.3記憶體
1.1.2 JAVA
GC 情況
regionserver長時間GC會影響叢集效能並且有可能會造成假死的情況
1.1.3重要的hbase指標
1.1.3.1region情況
需要檢查
1.region的數量(總數和每臺regionserver上的region數)
2.region的大小
如果發現異常可以通過手動merge region和手動分配region來調整
從CDH前臺和master前臺以及regionServer的前臺都可以看到region數量,如master前臺:
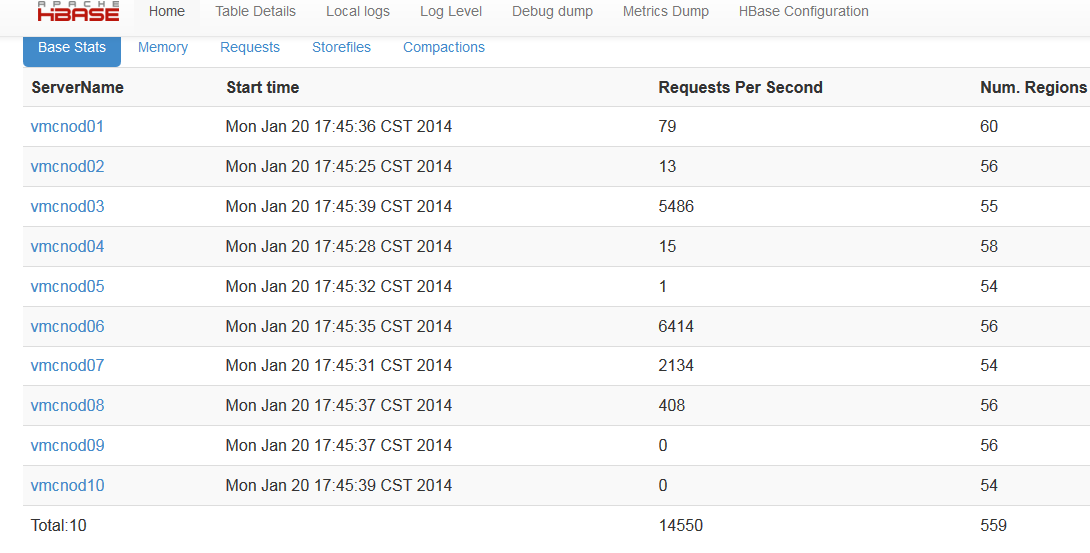
在region server前臺可以看到storeFile大小:
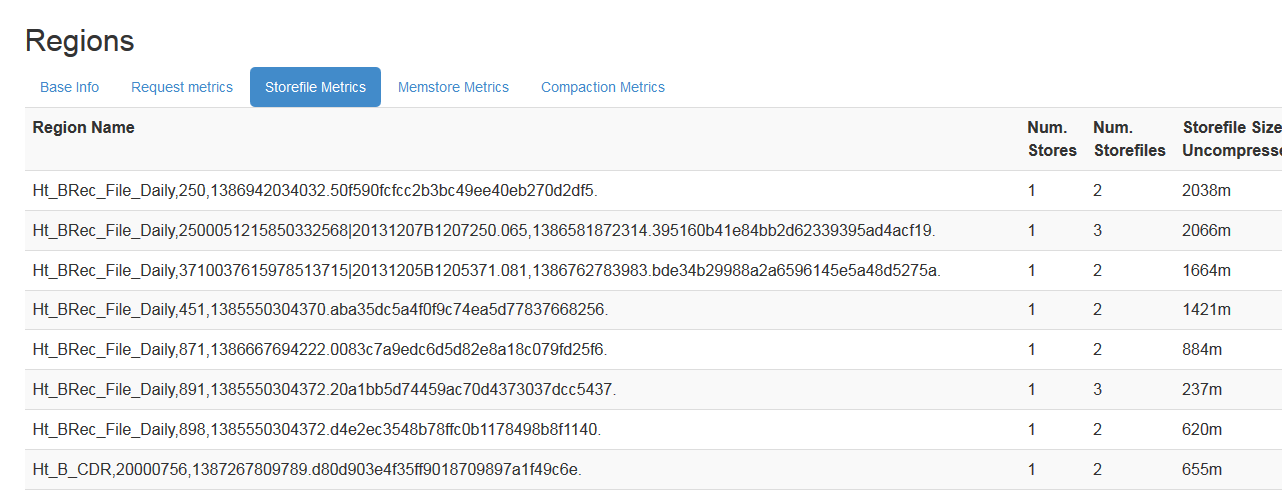
1.1.3.2快取命中率
快取命中率對hbase的讀有很大的影響,可以觀察這個指標來調整blockcache的大小。
從regionserver web頁面可以看到block cache的情況:
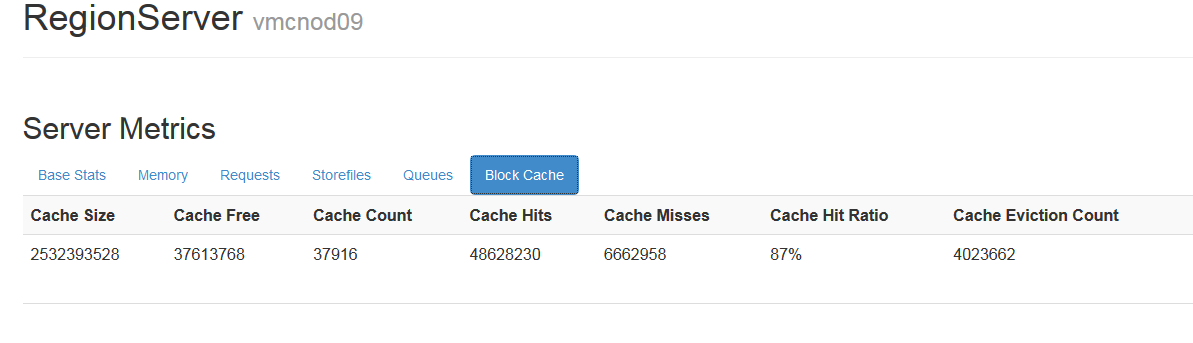
1.1.3.3讀寫請求數
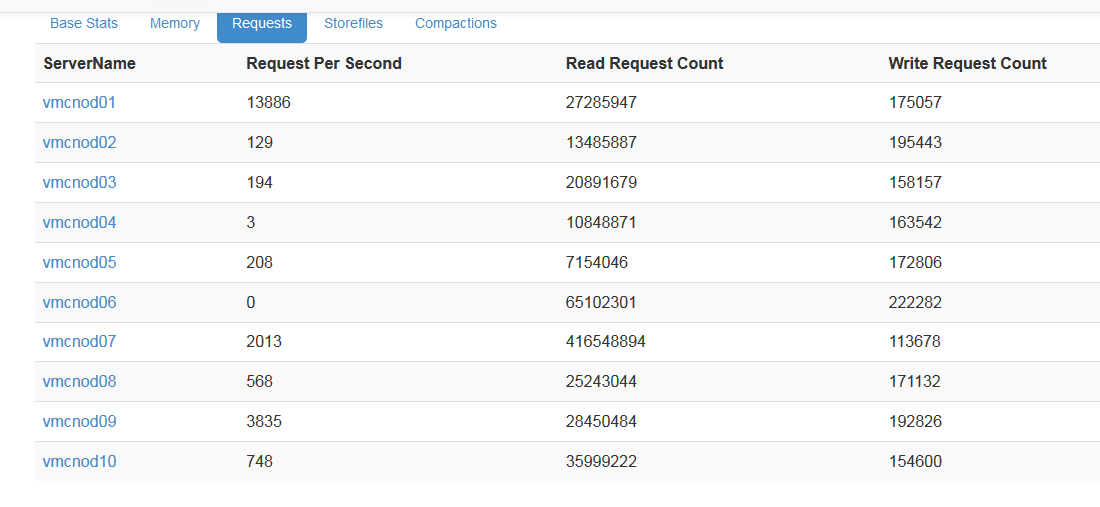
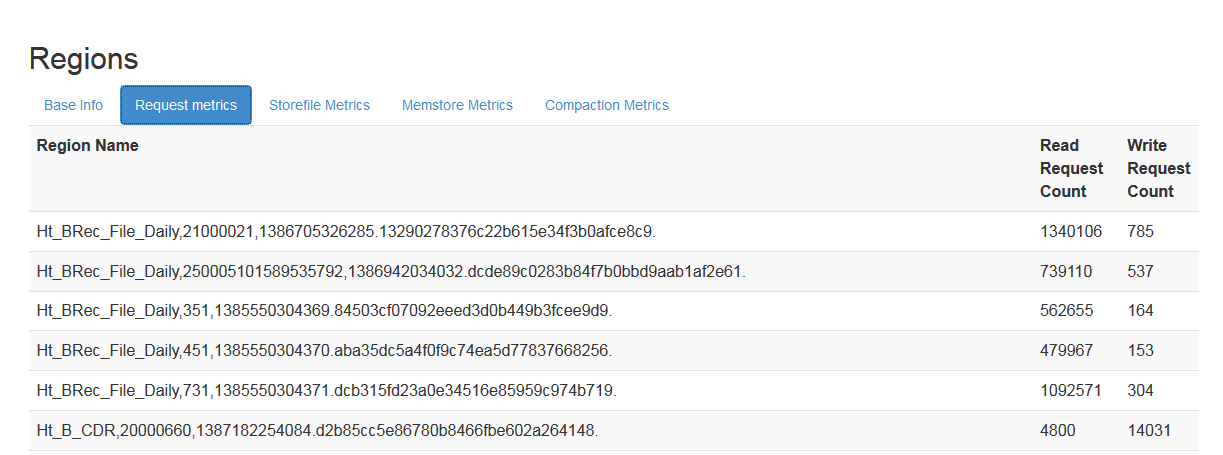
通過讀寫請求數可以大概看出每臺regionServer的壓力,如果壓力分佈不均勻,應該檢查regionServer上的region以及其它指標
master web上可以看到所以regionServer的讀寫請求數
regionServer上可以看到每個region的讀寫請求數
1.1.3.4壓縮佇列
壓縮佇列存放的是正在壓縮的storefile,compact操作對hbase的讀寫影響較大
通過cdh的hbase圖表庫可以看到叢集總的壓縮佇列大小:
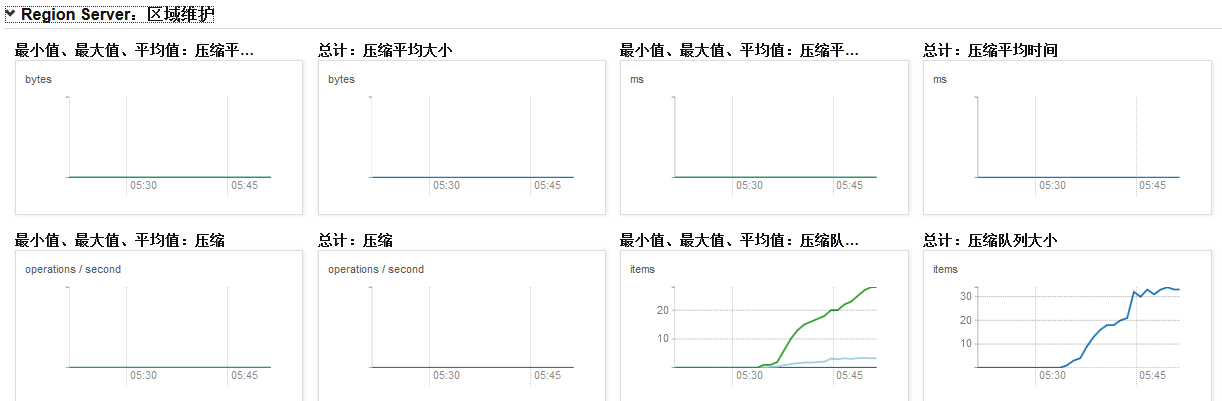
可以通過CDH的hbase主頁查詢compact日誌:
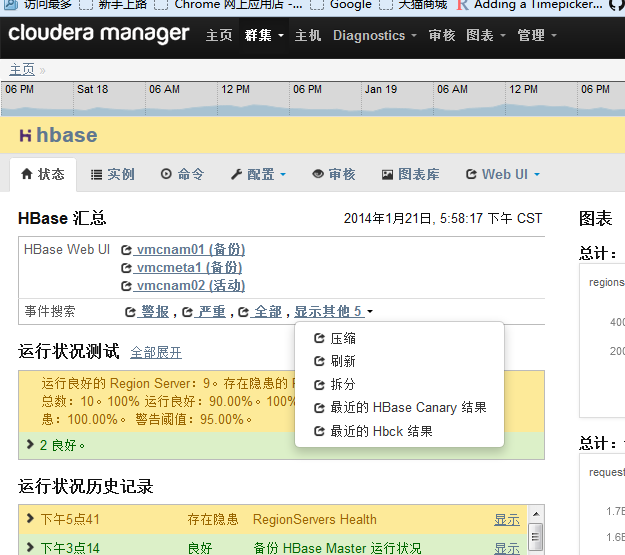
點選“壓縮”進入:
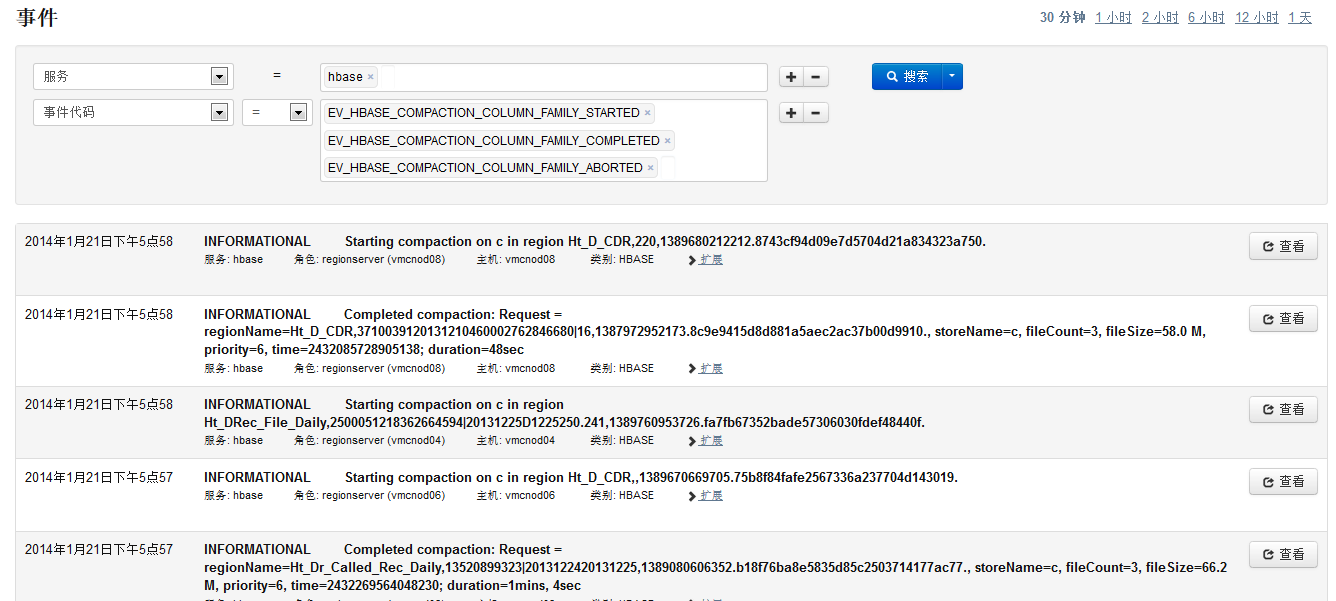
1.1.3.5重新整理佇列
單個region的memstore寫滿(128M)或regionServer上所有region的memstore大小總合達到門限時會進行flush操作,flush操作會產生新的storeFile
同樣可以通過CDH的hbase前臺檢視flush日誌:
1.1.3.6rpc呼叫佇列
沒有及時處理的rpc操作會放入rpc操作佇列,從rpc佇列可以看出伺服器處理請求的情況
1.1.3.7檔案塊儲存在本地的百分比
datanode和regionserver一般都部署在同一臺機器上,所以region server管理的region會優先儲存在本地,以節省網路開銷。如果block locality較低有可能是剛做過balance或剛重啟,經過compact之後region的資料都會寫到當前機器的datanode,block locality也會慢慢達到接近100:
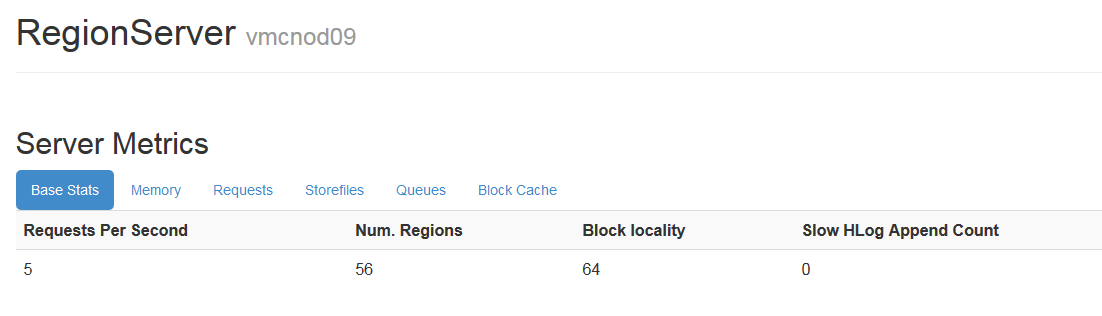
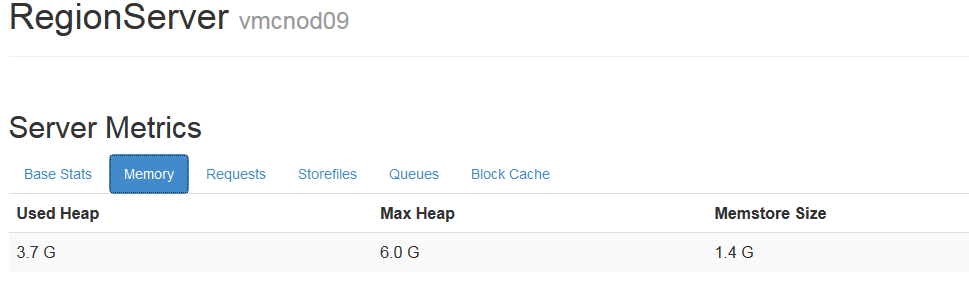
1.1.3.8記憶體使用情況
記憶體使用情況,主要可以看used Heap和memstore的大小,如果usedHeadp一直超過80-85%以上是比較危險的
memstore很小或很大也不正常
從region Server的前臺可以看到:
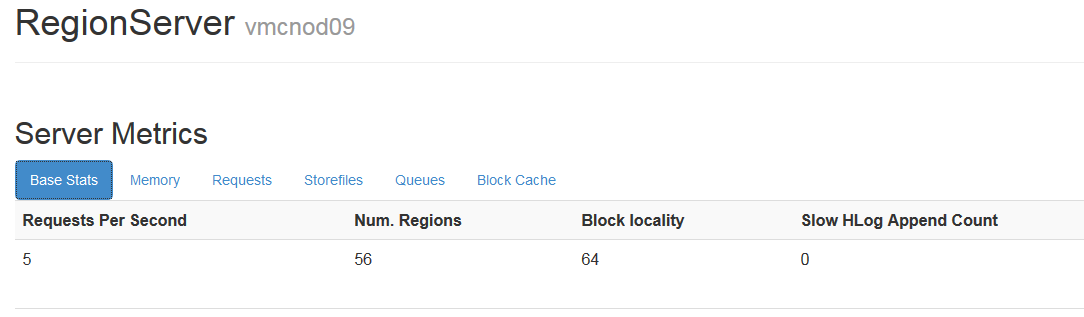
1.1.3.9slowHLogAppendCount
寫HLog過慢(>1s)的操作次數,這個指標可以作為HDFS狀態好壞的判斷
在region Server前臺檢視:
1.1.4CDH檢查日誌
CDH有強大的系統事件和日誌搜尋功能,每一個服務(如:hadoop,hbase)的主頁都提供了事件和告警的查詢,日常運維除了CDH主頁的告警外,需要檢視這些事件以發現潛在的問題:
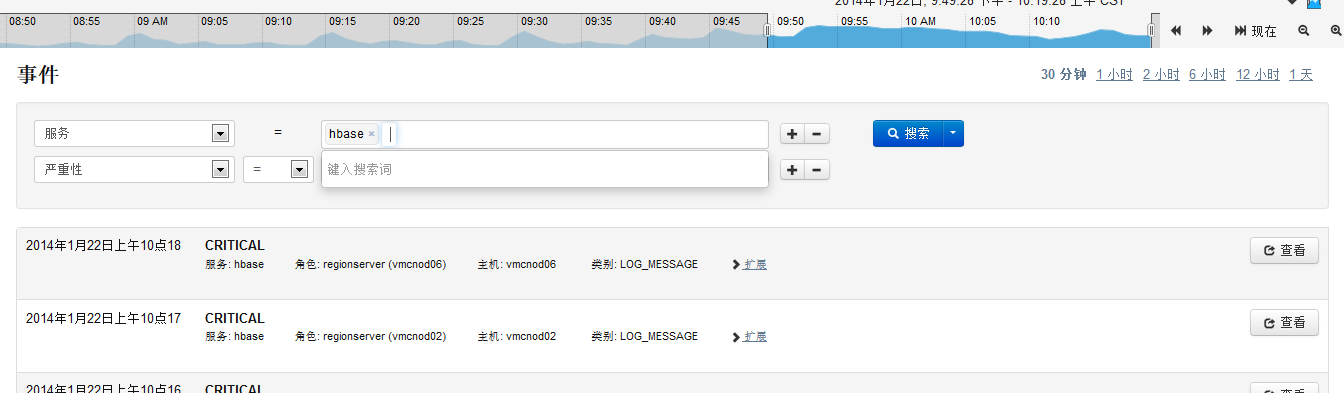
選擇“事件搜尋”中的標籤(“警報”、“嚴重”)可以進入相關的事件日誌,如“嚴重”:
1.2檢查資料一致性以及修復方法
資料一致性是指:
1.每個region都被正確的分配到一臺regionserver上,並且region的位置資訊及狀態都是正確的。
2.每個table都是完整的,每一個可能的rowkey 都可以對應到唯一的一個region.
1.2.1檢查
hbase hbck
注:有時叢集正在啟動或region正在做split操作,會造成資料不一致
hbase hbck -details
加上–details會列出更詳細的檢查資訊,包括所以正在進行的split任務
hbase hbck Table1 Table2
如果只想檢查指定的表,可以在命令後面加上表名,這樣可以節省操作時間
CDH
通過CDH提供的檢查報告也可以看到hbck的結果,日常只需要看CDH hbck的報告即可:
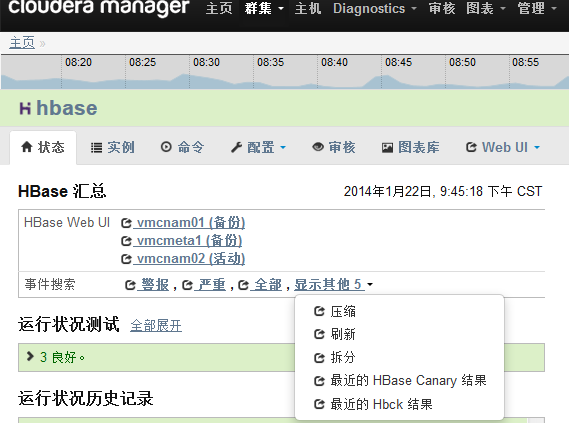
選擇“最近的Hbck結果”:
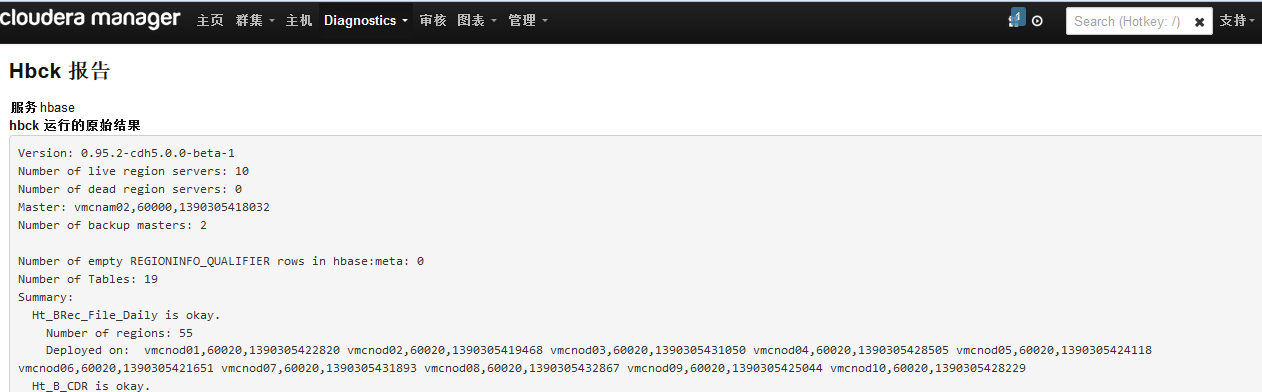
1.2.2修復
1.2.2.1區域性的修復
如果出現數據不一致,修復時要最大限度的降低可能出現的風險,使用以下命令對region進行修復風險較低:
1.2.2.1.1hbase hbck -fixAssignments
修復region沒有分配(unassigned),錯誤分配(incorrectly assigned)以及多次分配(multiply assigned)的問題
1.2.2.1.2hbase hbck -fixMeta
刪除META表裡有記錄但HDFS裡沒有資料記錄的region
新增HDFS裡有資料但是META表裡沒有記錄的region到META表
1.2.2.1.3hbase hbck -repairHoles
等價於:hbase hbck -fixAssignments -fixMeta -fixHdfsHoles
-fixHdfsHoles的作用:
如果rowkey出現空洞,即相鄰的兩個region的rowkey不連續,則使用這個引數會在HDFS裡面建立一個新的region。建立新的region之後要使用-fixMeta和-fixAssignments引數來使用掛載這個region,所以一般和前兩個引數一起使用
1.2.2.2Region重疊修復
進行以下操作非常危險,因為這些操作會修改檔案系統,需要謹慎操作!
進行以下操作前先使用hbck –details檢視詳細問題,如果需要進行修復先停掉應用,如果執行以下命令時同時有資料操作可能會造成不可期的異常。
1.2.2.2.1hbase hbck -fixHdfsOrphans
將檔案系統中的沒有metadata檔案(.regioninfo)的region目錄加入到hbase中,即建立.regioninfo目錄並將region分配到regionser
1.2.2.2.2hbase hbck -fixHdfsOverlaps
通過兩種方式可以將rowkey有重疊的region合併:
1.merge:將重疊的region合併成一個大的region
2.sideline:將region重疊的部分去掉,並將重疊的資料先寫入到臨時檔案,然後再匯入進來。
如果重疊的資料很大,直接合併成一個大的region會產生大量的split和compact操作,可以通過以下引數控制region過大:
-maxMerge 合併重疊region的最大數量
-sidelineBigOverlaps 假如有大於maxMerge個數的 region重疊, 則採用sideline方式處理與其它region的重疊.
-maxOverlapsToSideline 如果用sideline方式處理重疊region,最多sideline n個region .
1.2.2.2.3hbase hbck -repair
以下命令的縮寫:
hbase hbck -fixAssignments -fixMeta -fixHdfsHoles -fixHdfsOrphans -fixHdfsOverlaps -fixVersionFile –sidelineBigOverlaps
可以指定表名:
hbase hbck -repair Table1 Table2
1.2.2.2.4hbase hbck -fixMetaOnly –fixAssignments
如果只有META表的region不一致,則可以使用這個命令修復
1.2.2.2.5hbase hbck –fixVersionFile
Hbase的資料檔案啟動時需要一個version file,如果這個檔案丟失,可以用這個命令來新建一個,但是要保證hbck的版本和Hbase叢集的版本是一樣的
1.2.2.2.6hbase org.apache.hadoop.hbase.util.hbck.OfflineMetaRepair
如果ROOT表和META表都出問題了Hbase無法啟動,可以用這個命令來建立新的ROOT和META表。
這個命令的前提是Hbase已經關閉,執行時它會從hbase的home目錄載入hbase的相關資訊(.regioninfo),如果表的資訊是完整的就會建立新的root和meta目錄及資料
1.2.2.2.7hbase hbck –fixSplitParents
當region做split操作的時候,父region會被自動清除掉。但是有時候子region在父region被清除之前又做了split。造成有些延遲離線的父region存在於META表和HDFS中,但是沒有部署,HBASE又不能清除他們。這種情況下可以使用此命令重置這些在META表中的region為線上狀態並且沒有split。然後就可以使用之前的修復命令把這個region修復
1.3手動merge region
進行操作前先將balancer關閉,操作完成後再開啟balancer
經過一段時間的執行之後有可能會產生一些很小的region,需要定期檢查這些region並將它們和相鄰的region合併以減少系統的總region數,減少管理開銷
合併方法:
1.找到需要合併的region的encoded name
2.進入hbase shell
3.執行merge_region ‘region1’,’region2’
1.4手動分配region
如果發現臺regionServer資源佔用特別高,可以檢查這臺regionserver上的region是否存在過多比較大的region,通過hbase shell將部分比較大的region分配給其他不是很忙的regions server:
move ‘regionId’,’serverName’
例:
move ‘54fca23d09a595bd3496cd0c9d6cae85’,’vmcnod05,60020,1390211132297’
1.5手動major_compact
進行操作前先將balancer關閉,操作完成後再開啟balancer
選擇一個系統比較空閒的時間手工major_compact,如果hbase更新不是太頻繁,可以一個星期對所有表做一次 major_compact,這個可以在做完一次major_compact後,觀看所有的storefile數量,如果storefile數量增加到 major_compact後的storefile的近二倍時,可以對所有表做一次major_compact,時間比較長,操作儘量避免高鋒期
注:fms現在生產上開啟了自動major_compact,不需要做手動major compact
1.6balance_switch
balance_switch true 開啟balancer
balance_switch flase 關閉balancer
配置master是否執行平衡各個regionserver的region數量,當我們需要維護或者重啟一個regionserver時,會關閉balancer,這樣就使得region在regionserver上的分佈不均,這個時候需要手工的開啟balance。
1.7regionserver重啟
graceful_stop.sh –restart –reload –debug nodename
進行操作前先將balancer關閉,操作完成後再開啟balancer
這個操作是平滑的重啟regionserver程序,對服務不會有影響,他會先將需要重啟的regionserver上面的所有 region遷移到其它的伺服器,然後重啟,最後又會將之前的region遷移回來,但我們修改一個配置時,可以用這種方式重啟每一臺機子,對於hbase regionserver重啟,不要直接kill程序,這樣會造成在zookeeper.session.timeout這個時間長的中斷,也不要通過 bin/hbase-daemon.sh stop regionserver去重啟,如果運氣不太好,-ROOT-或者.META.表在上面的話,所有的請求會全部失敗
1.8regionserver關閉下線
bin/graceful_stop.sh nodename
進行操作前先將balancer關閉,操作完成後再開啟balancer
和上面一樣,系統會在關閉之前遷移所有region,然後stop程序。
1.9flush表
所有memstore重新整理到hdfs,通常如果發現regionserver的記憶體使用過大,造成該機的 regionserver很多執行緒block,可以執行一下flush操作,這個操作會造成hbase的storefile數量劇增,應儘量避免這個操 作,還有一種情況,在hbase進行遷移的時候,如果選擇拷貝檔案方式,可以先停寫入,然後flush所有表,拷貝檔案
1.10Hbase遷移
1.10.1copytable方式
bin/hbase org.apache.hadoop.hbase.mapreduce.CopyTable –peer.adr=zookeeper1,zookeeper2,zookeeper3:/hbase ‘testtable’
這個操作需要新增hbase目錄裡的conf/mapred-site.xml,可以複製hadoop的過來。
1.10.2Export/Import
bin/hbase org.apache.hadoop.hbase.mapreduce.Export testtable /user/testtable [versions] [starttime] [stoptime]
bin/hbase org.apache.hadoop.hbase.mapreduce.Import testtable /user/testtable
1.10.3直接拷貝hdfs對應的檔案
首先拷貝hdfs檔案,如bin/hadoop distcp hdfs://srcnamenode:9000/hbase/testtable/ hdfs://distnamenode:9000/hbase/testtable/
然後在目的hbase上執行bin/hbase org.jruby.Main bin/add_table.rb /hbase/testtable
生成meta資訊後,重啟hbase
2Hadoop日常運維
2.1監控Hadoop執行狀況
1.nameNode、ResourseManager記憶體(namenode要有足夠記憶體)
2.DataNode和NodeManager執行狀態
3.磁碟使用情況
4.伺服器負載狀態
2.2檢查HDFS檔案健康狀況
命令:hadoop fsck
2.3開啟垃圾箱(trash)功能
trash功能它預設是關閉的,開啟後,被你刪除的資料將會mv到操作使用者目錄的”.Trash”資料夾,可以配置超過多長時間,系統自動刪除過期資料。這樣一來,當操作失誤的時候,可以把資料mv回來
3本專案場景下的hbase引數調整

相關推薦
Hbase 日常運維監控效能指標調優
1.1監控Hbase執行狀況 1.1.1作業系統 1.1.1.1IO a.群集網路IO,磁碟IO,HDFS IO IO越大說明檔案讀寫操作越多。當IO突然增加時,有可能:1.compact佇列較大,叢集正在進行大量壓縮操作。 2.正在執行mapreduce作業 可以通過CDH前臺檢視整個叢集綜合的資料或進入指
運維監控篇(2)_Zabbix簡單的效能調優
Zabbix是一款高效能的分散式監控報警系統。比如現在常見的家用桌上型電腦配置處理器I5-3470、記憶體4GB1600MHz、硬碟7200rpm就能夠監控1000臺左右的HOST,是的沒錯Zabbix就是可以達到這樣的高效能。Zabbix執行時間長了會出現小小的瓶頸,小小瓶頸中最大的瓶頸是資料庫。怎樣解
Linux日常運維管理技巧--監控系統狀態
linux日常運維管理技巧--監控系統狀Linux日常運維管理技巧--監控系統狀態一、查看磁盤狀態1.iostat –x 磁盤使用 %util 表示io等待,2.iotop 磁盤使用(動態顯示)二、free查看內存使用情況1. free 命令顯示系統使用和空閑的內存情況,包括物理內存、交互區內存(swap)和
日常運維管理技巧六(檢視磁碟IO效能 iostat)
六、監控io效能(這個是關於磁碟的,磁碟的狀態的兩個命令 iostat iotop) 在日常運維過程中,除了CPU、記憶體外,磁碟的io也是非常重要的指標。有時候CPU、記憶體明明有剩餘,但系統就是負載很高,我們用vmstat命令檢視會發現b列或wa列比較大
SQL Server自動化運維繫列——監控效能指標指令碼(Power Shell)
需求描述 一般在生產環境中,有時候需要自動的檢測指標值狀態,如果發生異常,需要提前預警的,比如發郵件告知,本篇就介紹如果通過Power shell實現狀態值監控 監控值範圍 根據經驗,作為DBA一般需要監控如下系統能行指標 cpu: \Processor(_Total)\% P
SQL SERVER日常運維巡檢系列之八——效能
前言 做好日常巡檢是資料庫管理和維護的重要步驟,而且需要對每次巡檢日期、結果進行登記,同時可能需要出一份巡檢報告。 本系列旨在解決一些常見的困擾: 不知道巡檢哪些東西不知道怎麼樣便捷體檢機器太多體檢麻煩生成報告困難,無法直觀呈現結果 效能是系統好壞的重要指
Hbase叢集運維及應用效能優化總結(hbase1.20+)
(一). 作業系統 1. 足夠大的記憶體 2. 作業系統64位,jdk64位 3. 設定li
SQL SERVER日常運維巡檢系列之一——伺服器狀態及各硬體指標
前言 做好日常巡檢是資料庫管理和維護的重要步驟,而且需要對每次巡檢日期、結果進行登記,同時可能需要出一份巡檢報告。 本系列旨在解決一些常見的困擾: 不知道巡檢哪些東西不知道怎麼樣便捷體檢機器太多體檢麻煩生成報告困難,無法直觀呈現結果 伺服器的硬體情況大多數
【Jpom】一款簡而輕的低侵入式線上構建、自動部署、日常運維、專案監控軟體
一款簡而輕的低侵入式線上構建、自動部署、日常運維、專案監控軟體 https://jpom.io/ | http
運維監控大數據的提取與分析
monitor 運維監控 本文內容整理來自【敏捷運維大講堂】蔣君偉老師的線上直播分享。分別從以下3個維度來分享:1、雲時代監控分析的窘境;2、使用標簽標記監控數據的維度;3、監控數據應用場景。雲時代監控分析的窘境在虛擬化與容器技術廣泛應用的情況下,運維對象大規模地增長,監控平臺每天存儲的指標都以億計,
Linux日常運維小結
運維小結-011. 如何看當前Linux系統有幾顆物理CPU和每顆CPU的核數?物理cpu個數:cat /proc/cpuinfo |grep -c ‘physical id’CPU一共有多少核:grep -c processor /proc/cpuinfo將CPU的總核數除以物理CPU的個數,得到每顆CPU
如何做好日常運維的安全工作
安全一、主動與被動發現漏洞這裏的主動是指安全工程師主動去做的事情,而被動並不是被動挨打,而是積極去獲取信息,積極防禦。 因為攻防之間信息不對稱,很多攻擊、利用方式及漏洞安全工程師不一定能第一時間獲取到信息就導致了服務器被黑,出現被上傳webshell無外乎這集中情況:使用開源程序出現高危漏洞被攻擊者上傳we
筆記9(日常運維2iptables nat表、zone、service、cron、chkconfig、systemd、unit、target、rsyncscreen)
linux日常運維.nat表應用 A機器兩塊網卡ens33(192.168.133.130)、ens37(192.168.100.1),ens33可以上外網,ens37僅僅是內部網絡,B機器只有ens37(192.168.100.100),和A機器ens37可以通信互聯。 需求1:可以讓B機器連接外網 查看路
Linux日常運維管理技巧
linux日常運維管理技巧Linux日常運維管理技巧監控系統狀態1.w/uptime查看系統狀態, 執行這個命令可得知目前登入系統的用戶有那些人,以及他們正在執行的程序,以及當前負載的情況。2.cat /proc/cpuinfo 查看CPU核數,指的是邏輯CPU3.vmstat 監控系統狀態,用來獲得有關進程
linux日常運維(crond,systemd,chkconfing,unit,target)
target unit systemd chkconfing crond 1、任務計劃:crond[root@litongyao ~]# cat /etc/crontab (crontab配置文件) SHELL=/bin/bash
Linux日常運維(rsync通過服務連接,linux日誌,screen)
rsync 通過 服務鏈接 一、rsync通過服務同步分為服務端(server1) 和客戶端(server2)服務端(server1):[root@litongyao ~]# vim /etc/rsyncd.confport=873
第13章 linux系統管理技巧(日常運維管理技巧)
linux第13章 linux系統管理技巧(日常運維管理技巧)這一章的內容是核心,以後會用的幾率也是很大的,只要掌握必備的基礎知識,做初級系統管理員是不成問題的。13.1監控系統的狀態作為一個運維工程師、系統管理員,如果對自己的系統不了解的話,那怎麽排查問題呢?如果出現問題的話,肯定要查一下是什麽問題,哪裏的
第十章 日常運維
sys a13 linux pts 保存 run 讀寫 輸出 block 10.1 使用w產看系統負載 w/uptime 查看系統負載 系統時間+啟動了多久+用戶數+系統負載載值(1分鐘+5分鐘+1分鐘)系統負載載值:單位時間內使用CPU活動的線程有多少個。<c
日常運維命令
全局命令 src 磁盤 sar 表示 bbc 網卡流量 很慢 監控 監控系統狀態進行初步的判定w命令時間 用戶 網絡用戶顯示是pts tty1 客戶端 load average系統負載 :1分鐘,5分鐘,15分鐘時間段內系統負載是多少 單位時間段內使用CUP活動的進
日常運維管理,w,wmstat,top,sar,nload
col dad roc fff 監控系統 分享 stat ces term 監控系統狀態查看歷史文件 nload 查看網卡實時流量狀態左右方向鍵,可以查看不同網卡信息日常運維管理,w,wmstat,top,sar,nload