
InputField 限制字數
問題:遊戲中輸入角色名字不能超過一定位元組數,記作n
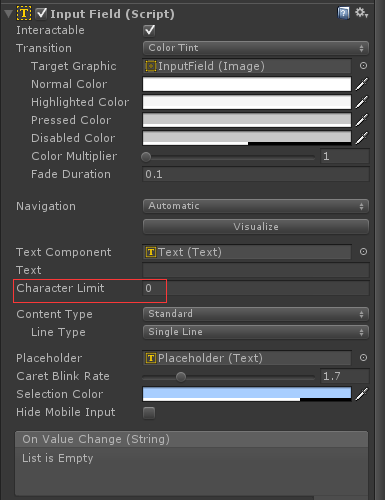
元件InputField裡
Character Limit:限制字元長度(0表示不限制),比如:設定只能輸入3個字元(中文,英文,數字,符號都按1個字元來算)
當設定為5,
輸出結果:
中文或者英文,均只能輸入五個。
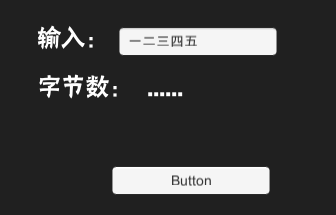
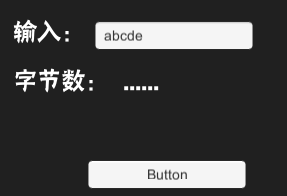
明顯不滿足,十個位元組=5箇中文=10個英文
所以,需要新增額外程式碼檢測,判斷是否超過了n個位元組。
在此之前,先了解ASCII、gb系列、Unicode、UTF-8的區別
- ASCII碼
美國:八個二進位制位就可以組合出256種狀態,這被稱為一個位元組(byte)。ASCII碼一共規定了128個字元的編碼,這128個符號(包括32個不能打印出來的控制符號),只佔用了一個位元組的後面7位,最前面的1位統一規定為0。範圍:0000000~1111111
32~126(共95個)是字元(32是空格),其中48~57為0到9十個阿拉伯數字。
65~90為26個大寫英文字母,97~122號為26個小寫英文字母,其餘為一些標點符號、運算子號等。
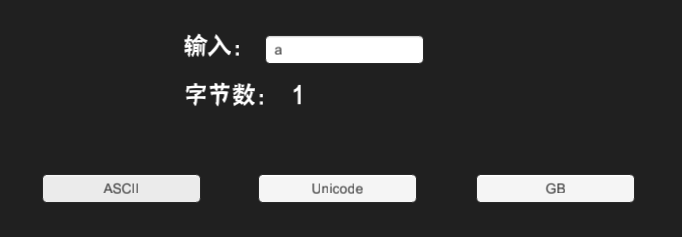
測試:
using UnityEngine;
using System.Collections;
using UnityEngine.UI;
public class CheckASCIICodeScript : MonoBehaviour {
public InputField m_input;//輸入的內容
public Text m_output;//輸出
public Button m_AsciiBtn;
public Button m_unicodeBtn;
public Button m_GBBtn;
public Button m_UTF8;
void 輸入a,結果:
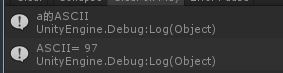
輸入漢字,結果都是63,因為漢字超過了128,所以獲取不了正確的ASCII。
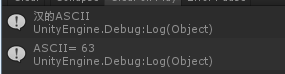
- 非ASCII碼
1個位元組==8個二進位制位,1個英文字母==1個字元==1個位元組,1個漢字==2個位元組
(1)其他非英語國家,各自為政,將剩下的128個未佔用狀態填充上自己的語言。這也僅可新增128種,對於高達10萬的漢字來講肯定是不夠的。
(2)GB2312。於是GB2312就出來了,GB2312 是對 ASCII 的中文擴充套件, 規定:一個小於127的字元的意義與原來相同,但兩個大於127的字元連在一起時,就表示一個漢字,前面的一個位元組(他稱之為高位元組)從0xA1用到0xF7,後面一個位元組(低位元組)從0xA1到0xFE,這樣我們就可以組合出大約7000多個簡體漢字了。
(3)GBK。但是這對於漢字來講還是不夠,於是乾脆不再要求低位元組一定是127號之後的內碼,只要第一個位元組是大於127就固定表示這是一個漢字的開始,不管後面跟的是不是擴充套件字符集裡的內容。結果擴充套件之後的編碼方案被稱為 GBK 標準,GBK 包括了 GB2312 的所有內容,同時又增加了近20000個新的漢字(包括繁體字)和符號。
(4)GB18030。對於GBK再擴充套件,加入幾千個新的少數民族的字。
輸入a:
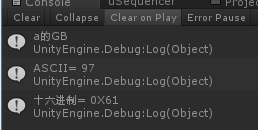
輸入漢字:

漢字的第一位位元組的ASCII碼186已經超過了128。故說明,通過單獨取ASCII是無法得到正確結果,一直返回的是63.
UNICODE編碼
每個國家都搞出像天朝這樣一套自己的編碼標準,於是ISO(國際標誰化組織)重新搞了一套標準–UNICODE, 在UNICODE中,一個漢字算兩個英文字元的時代已經快過去了。UNICODE的UCS-2編碼方式是定長雙位元組編碼,包括英文字母在內。UCS-2只能表示65535個字元,IOS預備了UCS-4方案,四個位元組來表示一個字元,可以組合出21億個不同的字元出來(最高位有其他用途)。英文字母只用一個位元組表示就夠了,但是其他更大的符號可能需要3個位元組或者4個位元組,甚至更多。如果Unicode統一規定,每個符號用三個或四個位元組表示,那麼每個英文字母前都必然有二到三個位元組是0,這對於儲存來說是極大的浪費。
需要注意的是,Unicode只是一個符號集,它只規定了符號的二進位制程式碼,卻沒有規定這個二進位制程式碼應該如何儲存。於是出現了多種儲存方式,也就是說有許多種不同的二進位制格式,可以用來表示unicode。unicode在很長一段時間內無法推廣,直到網際網路的出現。

輸入漢字:你,
結果為:
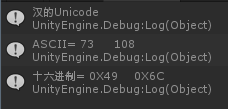
輸入a,英文也由兩個位元組組成。第二個位元組為0
結果為:
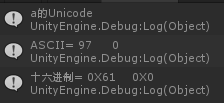
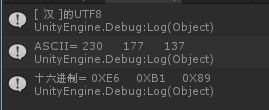
UTF8
UTF-8是Unicode的實現方式之一,傳輸、儲存,其他還有UTF-16(字元用兩個位元組或四個位元組表示),UTF-32(字元用四個位元組表示)。
UTF-8最大的一個特點,就是它是一種變長的編碼方式。它可以使用1~4個位元組表示一個符號,根據不同的符號而變化位元組長度。1個位元組==8個二進位制位==2^8==256。UTF-8的編碼規則很簡單,只有二條:
(1)對於單位元組的符號,位元組的第一位設為0,後面7位為這個符號的unicode碼。因此對於英語字母,UTF-8編碼和ASCII碼是相同的。
(2)對於n位元組的符號(n>1),第一個位元組的前n位都設為1,第n+1位設為0,後面位元組的前兩位一律設為10。剩下的沒有提及的二進位制位,全部為這個符號的unicode碼。
下表總結了編碼規則,字母x表示可用編碼的位。Unicode符號範圍 | UTF-8編碼方式
(十六進位制) | (二進位制)
——————–+———————————————
0000 0000-0000 007F | 0xxxxxxx
0000 0080-0000 07FF | 110xxxxx 10xxxxxx
0000 0800-0000 FFFF | 1110xxxx 10xxxxxx 10xxxxxx
0001 0000-0010 FFFF | 11110xxx 10xxxxxx 10xxxxxx 10xxxxxx

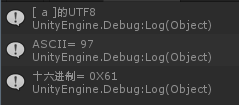
如果是漢字,每一位ascii 大於128
因此當指定一個文本里最多出現多少個位元組的字的時候,
可以通過InputField OnValueChange拖入指令碼,這樣,沒輸入一個字元(中文或英文)都會及時檢測。
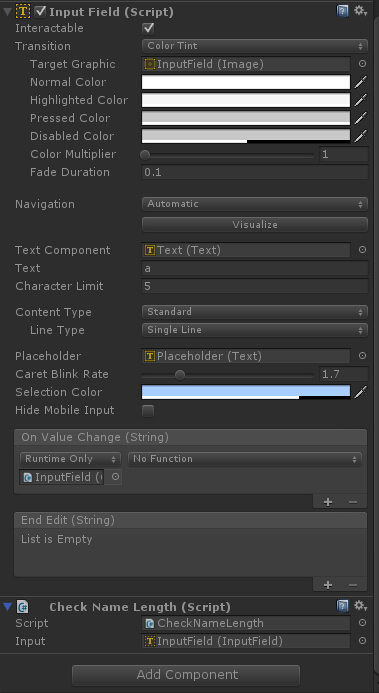
檢測方法有幾個:
using UnityEngine;
using System.Collections;
using UnityEngine.UI;
using System;
public class CheckNameLengthScript : MonoBehaviour {
public InputField input;
private const int CHARACTER_LIMIT = 10;
public CheckNameLengthScript.SplitType m_SplitType = SplitType.ASCII;
public enum SplitType
{
ASCII=1,
GB=2,
Unicode=3,
UTF8=4,
}
public void Check()
{
input.text = GetSplitName((int)m_SplitType);
}
public string GetSplitName(int checkType)
{
string temp = input.text.Substring(0, (input.text.Length < CHARACTER_LIMIT + 1) ? input.text.Length : CHARACTER_LIMIT + 1);
if (checkType == (int)SplitType.ASCII)
{
return SplitNameByASCII(temp);
}
else if (checkType == (int)SplitType.GB)
{
return SplitNameByGB(temp);
}
else if (checkType == (int)SplitType.Unicode)
{
return SplitNameByUnicode(temp);
}
else if (checkType == (int)SplitType.UTF8)
{
return SplitNameByUTF8(temp);
}
return "";
}
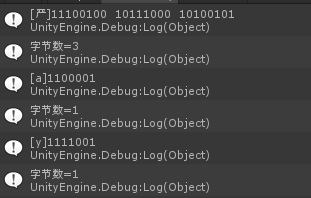
//4、UTF8編碼格式(漢字3byte,英文1byte),//UTF8編碼格式,目前是最常用的
private string SplitNameByUTF8(string temp)
{
string outputStr = "";
int count = 0;
for (int i = 0; i < temp.Length; i++)
{
string tempStr = temp.Substring(i, 1);
byte[] encodedBytes = System.Text.ASCIIEncoding.UTF8.GetBytes(tempStr);//Unicode用兩個位元組對字元進行編碼
string output = "[" + temp + "]";
for (int byteIndex = 0; byteIndex < encodedBytes.Length; byteIndex++)
{
output += Convert.ToString((int)encodedBytes[byteIndex], 2)+" ";//二進位制
}
Debug.Log(output);
int byteCount = System.Text.ASCIIEncoding.UTF8.GetByteCount(tempStr);
Debug.Log("位元組數=" + byteCount);
if (byteCount>1)
{
count += 2;
}
else
{
count += 1;
}
if (count <= CHARACTER_LIMIT)
{
outputStr += tempStr;
}
else
{
break;
}
}
return outputStr;
}
private string SplitNameByUnicode(string temp)
{
string outputStr = "";
int count = 0;
for (int i = 0; i < temp.Length; i++)
{
string tempStr = temp.Substring(i, 1);
byte[] encodedBytes = System.Text.ASCIIEncoding.Unicode.GetBytes(tempStr);//Unicode用兩個位元組對字元進行編碼
if(encodedBytes.Length==2)
{
int byteValue = (int)encodedBytes[1];
if (byteValue == 0)//這裡是單個位元組
{
count += 1;
}
else
{
count += 2;
}
}
if (count <= CHARACTER_LIMIT)
{
outputStr += tempStr;
}
else
{
break;
}
}
return outputStr;
}
private string SplitNameByGB(string temp)
{
string outputStr = "";
int count = 0;
for (int i = 0; i < temp.Length; i++)
{
string tempStr = temp.Substring(i, 1);
byte[] encodedBytes = System.Text.ASCIIEncoding.Default.GetBytes(tempStr);
if (encodedBytes.Length == 1)
{
//單位元組
count += 1;
}
else
{
//雙位元組
count += 2;
}
if (count <= CHARACTER_LIMIT)
{
outputStr += tempStr;
}
else
{
break;
}
}
return outputStr;
}
private string SplitNameByASCII(string temp)
{
byte[] encodedBytes = System.Text.ASCIIEncoding.ASCII.GetBytes(temp);
string outputStr = "";
int count = 0;
for (int i = 0; i < temp.Length; i++)
{
if ((int)encodedBytes[i] == 63)//雙位元組
count += 2;
else
count += 1;
if (count <= CHARACTER_LIMIT)
outputStr += temp.Substring(i, 1);
else if (count > CHARACTER_LIMIT)
break;
}
if (count <= CHARACTER_LIMIT)
{
outputStr = temp;
}
return outputStr;
}
}
相關推薦
InputField 限制字數
問題:遊戲中輸入角色名字不能超過一定位元組數,記作n 元件InputField裡 Character Limit:限制字元長度(0表示不限制),比如:設定只能輸入3個字元(中文,英文,數字,符號都按1個字元來算) 當設定為5, 輸出結果: 中文或者
js限制字數的輸入
disable cnblogs tar doc function alt img sub charset <!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN" "http://www.w3.or
限制字數輸出,,超出的用...
space nbsp images wid psi class ellipsis hit bsp 1 <div style="width:200px; white-space:nowrap;overflow:hidden;text-overflow:ellipsis
工作總結 input 限制字數 textarea限制字數
post 分享圖片 image tex tar 最大 input 工作總結 字數 最大能輸入50個字 復制粘貼也不行 <textarea maxlength="50" class=" smallarea" cols="60" name="txta" rows=
vue輸入框限制字數,達到100字禁止輸入
<!DOCTYPE html> <html> <head> <meta charset="utf-8"> <meta http-equiv="X-UA-Compatible" content="IE=edge,chrome
文章簡介[field:description /]限制字數
在用織夢繫統時,用[field:description /]標籤調取文章簡介時,限制字數的方法有下面3種: 第一種方法:(推薦,可加省略號) [field:description function='cn_substr(Html2text(&am
UITextView 限制字數
- (BOOL)textView:(UITextView *)textView shouldChangeTextInRange:(NSRange)range replacementText:(NSString *)text { if ([text rangeOfS
玄宇說:JQ實現限制字數替換“…”
多說無用上圖為準 $(document).ready(function(){ //限制字元個數 $(".zishu").each(function () {
PHP 字串限制字數和獲取字串字數
一、擷取限制字數:mb_substr() mb_substr( $str, $start, $length, $encoding ) $str,需要截斷的字串 $start,截斷開始處,起始處為0
textarea限制字數
<textarea class="textarea1" rows="3" cols="80" name="famcQuery" id="txtRemark" onkeyup="check(this)")></textarea> fun
iOS UITextView 限制字數(解決了截斷輸入聯想和對系統鍵盤中文不友好的問題)
原貼出處:http://blog.csdn.net/z794614061/article/details/53821798 個人認為是目前最好的截斷方式! 解決的問題有: 1.截斷漢字對中文輸入不友好的問題(比如要輸入最後一個漢字“講”,輸入字母j之後就不讓你輸入了。注:在系統自帶鍵盤中文會出現這個問題)
android設定textview限制字數以省略號顯示的方法
<TextView android:id="@+id/text_view" android:layout_width="wrap_content" android:layout_height="wrap_content"
dede修改描述description限制字數長度
修改了好幾個地方: 1、在dede資料夾下面article_description_main.php頁面,找到“if($dsize>250) $dsize = 250;”語句把250修改為500。 2、dede 檔案下的 article_edit.php(這裡5.7以
input,textarea限制字數,實時繫結
目前常用二種方法 1.在input 或 textarea中加屬性 maxlength="10" 2.js判斷 function limitImport(str,num){ $(docu
textfield限制字數(相容中文,複製,刪除)iOS
這個方法經多次查詢,親自測試可用於中文輸入檢測,以及複製,刪除等都對限制字數沒有影響。[textnameaddTarget:selfaction:@selector(textFieldDidChange
UITextField和UITextView限制字數(包括中文)
一直以來UITextField和UITextView的字數顯示就困擾著我,特別當輸入為中文輸入法時 今天再搜尋這個問題時看到了2位同學的部落格,通過整合完成了對UITextField和UITextView的中文輸入法字數限制 先感謝這兩位同學http://blog.sina
表單輸入限制字數
1.表單輸入限制位元組,一個漢字=2個位元組 //獲取字串的位元組長度 function len(s) { s = String(s); return s.length
html實現鈍角效果;html實現限制一行字數的顯示,超出的部分用省略號(....)來代替
button posit uitext 鄙視 gulp 最新 完全 經典 ava 前端實現div框邊角的鈍化雖然簡單,但是有時候突然想不到,特此寫下幾句實現方法,以便記憶。 實現div框四個角都鈍角的操作:設置 div : border-radius=10p
css限制顯示字數,文字長度超出部分用省略號表示【轉】
class over nbsp text pac ips csdn div width 為了保證頁面的整潔美觀,在很多的時候,我們常需要隱藏超出長度的文字。這在列表條目,題目,名稱等地方常用到。 (1).文字超出一行,省略超出部分,顯示‘...‘ 如果這種情況比較多,可以取
vue監聽對input輸入的字體字數限制
script href htm 雙向 keywords attribute chrom his handle <!DOCTYPE html> <html> <head> <meta charset="utf-8"> <