
為什麼要記憶體對齊
當我們聽到”記憶體對齊“這個概念時,從字面意思來看,很容易理解。那就是讓記憶體按一定規則對齊。
當然 就會有人說 你這不是廢話 ??
現在我就來說一說為什麼要記憶體對齊以及怎麼個對齊法(如何對齊)?
首先來談談什麼叫記憶體對齊!!我百度了一下如下解釋:
記憶體對齊:
記憶體對齊”應該是編譯器的“管轄範圍”。編譯器為程式中的每個“資料單元”安排在適當的位置上。但是C語言的一個特點就是太靈活,太強大,它允許你干預“記憶體對齊”。如果你想了解更加底層的祕密,“記憶體對齊”對你就不應該再透明瞭。
對於記憶體對齊問題,主要存在於struct和union等複合結構在記憶體中的分佈情況,許多實際的計算機系統對基本型別資料在記憶體中存放的位置有限制,它們要求這些資料的首地址的值是某個數M(通常是4或8);對於記憶體對齊,主要是為了提高程式的效能,資料結構,特別是棧,應儘可能在自然邊界上對齊,經過對齊後,cpu的記憶體訪問速度大大提升。
Windows中預設對齊數為8,Linux中預設對齊數為4;
(1)記憶體對齊的主要作用:
1、平臺原因(移植原因)A 不是所有的硬體平臺都能訪問任意地址上的任意資料的;
B 某些硬體平臺只能在某些地址處取某些特定型別的資料,否則丟擲硬體異常。
2、效能原因:
A 資料結構(尤其是棧)應該儘可能地在自然邊界上對齊。
B 原因在於,為了訪問未對齊的記憶體,處理器需要作兩次記憶體訪問;而對齊的記憶體訪問僅需要一次訪問。
(2)記憶體對齊規則:
在記憶體中,編譯器按照成員列表順序分別為每個結構體變數成員分配記憶體,當儲存過程中需要滿足邊界對齊的 要求時,編譯器會在成員之間留下額外的記憶體空間。如果想確認結構體佔多少儲存空間,則使用關鍵字sizeof,如果想得知結構體的某個特定成員在結構體的位置,則使用offsetof巨集(定義於stddef.h)。
<span style="font-size:18px;">#include<stddef.h>
#include<iostream>
using namespace std;
#pragma pack(4)
struct m
{
int a;
short b;
int c;
};
int main()
{
cout <<"結構體m的大小:"<< sizeof(m) << endl;
cout << endl;
int offset_b = offsetof(struct m, a);// 獲得成員a相對於m儲存地址的偏移量
cout <<"a相對於m儲存地址的偏移量:"<< offset_b << endl;
system("pause");
return 0;
}</span> 從執行結果來看我們可以證實上面記憶體對齊規則的第一條:第一個資料成員放在offset為0的地方;
現在咱來看看上面結構體是如何記憶體對齊的;先用程式碼列印它們每個資料成員的儲存地址的偏移量:
從執行結果來看我們可以證實上面記憶體對齊規則的第一條:第一個資料成員放在offset為0的地方;
現在咱來看看上面結構體是如何記憶體對齊的;先用程式碼列印它們每個資料成員的儲存地址的偏移量:
<span style="font-size:18px;">int main()
{
cout <<"結構體m的大小:"<< sizeof(m) << endl;
cout << endl;
int offset_b = offsetof(struct m, a);// 獲得成員a相對於m儲存地址的偏移量
int offset_b1 = offsetof(struct m, b);// 獲得成員a相對於m儲存地址的偏移量
int offset_b2 = offsetof(struct m, c);// 獲得成員a相對於m儲存地址的偏移量
cout <<"a相對於m儲存地址的偏移量:"<< offset_b << endl;
cout << "b相對於m儲存地址的偏移量:" << offset_b1 << endl;
cout << "c相對於m儲存地址的偏移量:" << offset_b2 << endl;
system("pause");
return 0;
}</span> 在此c在結構體中偏移量為8加上它自身(int)4個位元組,剛好是12(c的開始位置為8,所以要加它的4個位元組)
現在我來給大家分析一下:
在此c在結構體中偏移量為8加上它自身(int)4個位元組,剛好是12(c的開始位置為8,所以要加它的4個位元組)
現在我來給大家分析一下:
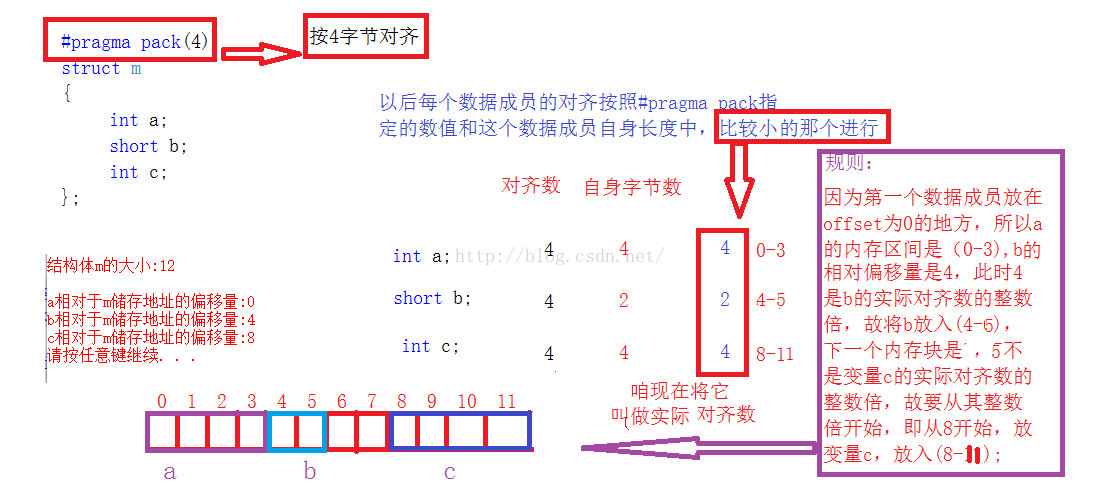
上面記憶體結束為11,因為0-11,12是最大對齊數的整數倍,故取其臨近的倍數,所以就取4的整數倍即12; 上圖中我用連續的陣列來模仿記憶體,如圖是它們的記憶體對齊圖; 如果將最大記憶體對齊數改為8,他將驗證記憶體對齊規則中的第3條。 如果將其改為2,會發生什麼:我們來看看:
<span style="font-size:18px;">#pragma pack(2)
struct m
{
int a;
short b;
int c;
};
int main()
{
cout <<"結構體m的大小:"<< sizeof(m) << endl;
cout << endl;
int offset_b = offsetof(struct m, a);// 獲得成員a相對於m儲存地址的偏移量
int offset_b1 = offsetof(struct m, b);// 獲得成員a相對於m儲存地址的偏移量
int offset_b2 = offsetof(struct m, c);// 獲得成員a相對於m儲存地址的偏移量
cout <<"a相對於m儲存地址的偏移量:"<< offset_b << endl;
cout << "b相對於m儲存地址的偏移量:" << offset_b1 << endl;
cout << "c相對於m儲存地址的偏移量:" << offset_b2 << endl;
system("pause");
return 0;
}</span>
對於這個結果,我們按剛才第一個例子我所分析的過程來分析這段程式碼,得到的是10; 故當我們將#pragma pack的n值小於所有資料成員長度的時候,結果將改變。
相關推薦
為何要記憶體對齊
為何要記憶體對齊 http://www.ibm.com/developerworks/library/pa-dalign/ 因為處理器讀寫資料,並不是以位元組為單位,而是以塊(2,4,8,16位元組)為單位進行的。如果不進行對齊,那麼本來只需要一次進行的訪問,可能需要好幾次才能完成,並且還要進
為什麼要記憶體對齊
當我們聽到”記憶體對齊“這個概念時,從字面意思來看,很容易理解。那就是讓記憶體按一定規則對齊。 當然 就會有人說 你這不是廢話 ?? 現在我就來
什麼是記憶體對齊?為什麼要記憶體對齊?
要了解為什麼要記憶體對齊,首先我們要了解什麼是記憶體對齊 什麼是記憶體對齊 關於什麼是記憶體對齊,我們先來看幾個例子 typedef struct { int a; double b; short c; }A; typed
為什麼要記憶體對齊 Data alignment: Straighten up and fly right
為了速度和正確性,請對齊你的資料. 概述:對於所有直接操作記憶體的程式設計師來說,資料對齊都是很重要的問題.資料對齊對你的程式的表現甚至能否正常執行都會產生影響.就像本文章闡述的一樣,理解了對齊的本質還能夠解釋一些處理器的"奇怪的"行為. 記憶體存取粒度
為什麼要進行結構體記憶體對齊
結構體記憶體對齊 什麼是結構體記憶體對齊 結構體不像陣列,結構體中可以存放不同型別的資料,它的大小也不是簡單的各個資料成員大小之和,限於讀取記憶體的要求,而是每個成員在記憶體中的儲存都要按照一定偏移量來儲存,根據型別的不同,每個成員都要按照一定的對齊數進
struct自然邊界上的記憶體對齊
記憶體對齊大多數情況對程式設計師是透明的,是由編譯器自動處理。在C裡面允許我們干預記憶體對齊。而由於記憶體對齊的原因,巧妙的設計結構體也是非常必要的。 關於記憶體對齊問題,字、雙字和四字在自然邊界上不需要在記憶體中對齊,對字、雙字和四字來
C++虛擬函式表以及記憶體對齊文章
C++虛擬函式表以及記憶體對齊文章 C++ 物件的記憶體佈局(上) https://blog.csdn.net/haoel/article/details/3081328 C++ 物件的記憶體佈局(下) https://blog.csdn.net/haoel/article/deta
結構體記憶體對齊模式
結構體的位元組大小,一個簡單的結構體定義如下,這個結構的大小應是8位元組(32位下) typedef struct MODEL4 { char c; int x; }MODEL4; char的大小是1,而int是4,但總的大小是8,這就是結構體記憶體對齊的原因。在32位的機器上,資料是以
C++11 記憶體對齊 alignof alignas
一 現象 先看一段程式碼: struct s1 { char s; int i; }; struct s2 { int i; double d; }; cout << "-------basic type" << endl; c
行內函數,巨集定義,記憶體對齊,型別轉換
巨集 與 inline的區別 存在的價值,兩者都是文字替換,降低程式跳轉次數,提高效率 1. define 是預處理命令,無法除錯 ,最簡單文字替換, inline 是編譯期替換,可以除錯, 存在引數型別檢查 2. 使用inline的時候,函式必須定義 直接定義的函式
記憶體對齊演算法
--------------------------------------------- -- 時間:2018-11-09 -- 建立人:Ruo_Xiao -- 郵箱:[email protected] ----------------------------------------
關於記憶體對齊
記憶體對齊可以用一句話來概括:“資料項只能儲存在地址是資料項大小的整數倍的記憶體位置上” 例如int型別佔用4個位元組,地址只能在0,4,8等位置上。 位元組對齊的緣故,如下的結構體的佔用記憶體是一樣 struct A{ &
現代計算機記憶體對齊機制
64位計算機和32位計算機CPU對記憶體處理的區別 64位CPU,位寬為8個位元組。(64位/8位/位元組=8位元組) 32位CPU,位寬位4個位元組。(32位/8位/位元組=4位元組) 我們假想記憶體空間是一個二階矩陣。(事實上記憶體是一維線性排列的) 那麼二維陣列的列數在64位C
結構體記憶體對齊總結
首先我們都知道結構體是多個變數的集合,在其中可以存放整型,浮點型等等各種,然後結構體記憶體是如何對齊的呢,他並不是按連續順序去排下去的,首先我們先上一段程式碼 #include<iostream> #include<cstdlib> using namesp
結構體的大小 記憶體對齊
結構體的大小 記憶體對齊 Struct A { int a; int b; }; int main() { Printf(“%d\n”,sizeof(struct A)); 共佔8位
記憶體對齊和補齊
對齊:是針對單個成員變數的; 補齊:是針對擺放的所有成員變數的整體而言要對齊; //4位元組的對齊粒度 #pragma pack(4) // #pragma pack(n) /* n = 1,
初夏小談:結構體記憶體對齊詳解
記憶體對齊?什麼是記憶體對齊? 對於這個問題我們先來看看這樣的一個結構體(在32位系統下) typedef struct Stu1 { char C1; int num1; short S1; }Stu1; 如果我們不知道記憶體對齊或者不清楚記憶體對齊時,我們可能這樣分析
關於記憶體對齊的問題
在最近的專案中,我們涉及到了“記憶體對齊”技術。對於大部分程式設計師來說,“記憶體對齊”對他們來說都應該是“透明的”。“記憶體對齊”應該是編譯器的 “管轄範圍”。編譯器為程式中的每個“資料單元”安排在適當的位置上。但是C語言的一個特點就是太靈活,太強大,它允許你干預“記憶體對齊”。如果你想了解 更加
C語言結構體對齊(記憶體對齊問題)
C語言結構體對齊也是老生常談的話題了。基本上是面試題的必考題。內容雖然很基礎,但一不小心就會弄錯。寫出一個struct,然後sizeof,你會不會經常對結果感到奇怪?sizeof的結果往往都比你宣告的變數總長度要大,這是怎麼回事呢? 開始學的時候,
記憶體對齊的要素--資料成員對齊的規則
Data structure alignment refers to the way data is arranged and accessed in computer memory. It consists of three separate but related issues:&nb