
常見伺服器架構
連結:http://www.zhihu.com/question/20657269/answer/15763722
來源:知乎
著作權歸作者所有。商業轉載請聯絡作者獲得授權,非商業轉載請註明出處。
初級篇:(單機模式)
假設配置:(Dual core 2.0GHz,4GB ram,SSD)
基礎框架:apache(PHP) + Mysql / IIS + MSSQL
(最基礎框架,處理一般訪問請求)
進階1:替換Apache為Nginx,並在資料庫前加上cache層【資料庫的速度是最大的瓶頸】
Nginx(PHP) + Memcache + Mysql
(此時已經具備處理小型訪問量的能力)
進階2:隨著訪問量的上漲,最先面臨的問題就來了:CGI無法匹配上Nginx的高IO效能,這時候可以通過寫擴充套件來替代指令碼程式來提升效能,C擴充套件是個好辦法,但是大家更喜歡用簡單的指令碼語言完成任務,Taobao團隊開源了一個Nginx_lua模組,可以用lua寫Nginx擴充套件,這時候可處理的併發已經超越進階1 一個檔次了。
Nginx(nginx_lua or C) + Memcache + Mysql
(此時處理個同時線上三四千人沒有問題了)
進階3
|----write------>RabbitMQ--------
Nginx(lua or c)----- |--------->Mysql
|----read------>Memcache--------
(此時的併發吞吐能力已經可以處理萬人左右線上)
中級篇:(分而治之)
此時我們在單機優化上已經算是達到極限,接下來就要叢集來顯示作用了。
資料庫篇: 資料庫總是在整個環節中是吞吐能力最弱的,最常見的方法就是sharding。
sharding可以按多種方法來分,沒有定式,看情況。可以按使用者ID區段分,按讀寫分等等,可用參考軟體:mysql proxy(工作原理類似lvs)
快取篇:memcache一般採用的是構建memcache pool,將快取分散到多臺memcache節點上,如何將快取資料均勻分散在各節點,一般採用將各節點順序編號,然後hash取餘對應到各個節點上去。這樣可以做到比較均勻的分散,但是有一個致命點就是,如果節點數增加或減少,將會帶來幾乎80%的資料遷移,解決方案我們在高階篇再提。
WEB伺服器篇:
方法2:參見 HAProxy - The Reliable, High Performance TCP/HTTP Load Balancer
高階篇:(高可用性+高可擴充套件性的叢集)
單點排程故障解決:
叢集的好處顯而易見,但是有一個弊端就是單節點進行排程,如果節點出現故障,則整個叢集全部都無法服務,對此的解決方案,我們使用keepalived來解決。Keepalived for Linux
keepalived是基於VRRP協議(VRRP協議介紹)的,請一定先了解VRRP協議後再進行配置。
keepalived可以把多臺裝置虛擬出一個IP,並自動在故障節點與備用節點之間實現failover切換。這樣我們配置兩臺貨多臺lvs排程節點,然後配置好keepalived就可以做到lvs排程節點出現故障後,自動切換到備用排程節點。(同樣適用於mysql)
memcache叢集擴充套件解決:
memcache因為我們一般採用的都是hash後除以節點數取餘,然後分配到對應節點上,如果節點數出現變化,以前的快取資料將基本都不能命中。
解決方法:consistent hashing 簡介:一致性雜湊
consistent hashing大概的思路就是,把hash後的值保證在 0 ~ (2^32)-1 的數值上,然後把這一連串數字對應對映到一個想象的圓上。 <img src="https://pic2.zhimg.com/c3cd8e6cf787c82d6f7e011e882ce27d_b.jpg" data-rawwidth="95" data-rawheight="108" class="content_image" width="95">
把要儲存的各個值hash後,放到圓上,如圖
<img src="https://pic2.zhimg.com/77a5474913b2017a9c64e877940ca625_b.jpg" data-rawwidth="238" data-rawheight="257" class="content_image" width="238">
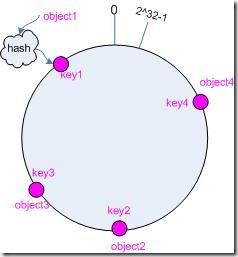
然後把cache節點也用同樣的hash方法,對映到圓上,然後每個剛才hash過的value順時針尋找離自己最近的節點,這個節點就是儲存它的節點。
<img src="https://pic2.zhimg.com/cf3a58c791488b89d6bda4f6c8c43d55_b.jpg" data-rawwidth="287" data-rawheight="257" class="content_image" width="287">
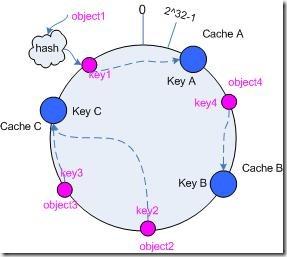
為了提高儲存的平衡性,演算法還可以加入虛擬節點的概念,即每個實際cache節點,會在圓上對應N個虛擬的節點,這樣可以提高演算法的命中率,更加平衡。
consistent hashing原理:Consistent hashing and random trees
相關推薦
常見伺服器架構
作者:牛浩帆 連結:http://www.zhihu.com/question/20657269/answer/15763722 來源:知乎 著作權歸作者所有。商業轉載請聯絡作者獲得授權,非商業轉載請註明出處。初級篇:(單機模式) 假設配置:(Dual core 2.0GHz,4GB ram,SSD)基礎框架
伺服器架構設計,常見問題分析
MMORPG伺服器架構 轉自:http://www.blogjava.net/landon/archive/2012/07/14/383092.html 分析總結的很好,分享下。 一.摘要 1.網路遊戲 MMORPG 整體伺服器框架,包括早期,中
常見的伺服器架構
常見的伺服器架構有以下種 伺服器叢集架構: 伺服器叢集就是指將很多伺服器集中在一起進行同一種服務,在客戶端開來就像一個伺服器,在客戶端看來就像只有一個伺服器。叢集可以利用多個計算機從而獲得很高的計算速度,也可以用很多計算機做備份,從而使任何一個機器壞了整個系統還是能正常執行。 伺服器負載均衡
DNS伺服器架構
DNS拓撲架構圖: 1,主域名伺服器配置: ~]# yum install bind –y ~]# systemctl start named.service ~]# systemctl enable
QQ遊戲百萬人同時線上伺服器架構實現
QQ遊戲於前幾日終於突破了百萬人同時線上的關口,向著更為遠大的目標邁進,這讓其它眾多傳統的棋牌休閒遊戲平臺黯然失色,相比之下,聯眾似乎已經根本不是QQ的對手,因為QQ除了這100萬的遊戲線上人數外,它還擁有3億多的註冊量(當然很多是重複註冊的)以及QQ聊天軟體900萬的同時線上率,我們已經
針對中小型網站 3000人左右/15分鐘 的伺服器架構
分享一下我老師大神的人工智慧教程!零基礎,通俗易懂!http://blog.csdn.net/jiangjunshow 也歡迎大家轉載本篇文章。分享知識,造福人民,實現我們中華民族偉大復興!
常見伺服器返回的狀態碼
伺服器向用戶返回的狀態碼和提示資訊,常見的有以下一些(方括號中是該狀態碼對應的HTTP動詞)。 200 OK - [GET]:伺服器成功返回使用者請求的資料,該操作是冪等的(Idempotent)。 201 CREATED - [POST/PUT/PATCH]:使用者新建或
一文詳解高效能伺服器架構設計
引言 本文從一個簡單的伺服器架構,通過討論出現的問題,進行一步一步優化,最後進化成高效能分散式伺服器架構。 初始情況:一個典型的伺服器結構 新增資料訪問層DAL,解決超出連線次數的問題 新增快取,減少與資料庫建立連線 即使添加了DAL,但是資料
伺服器架構(四)
---恢復內容開始--- 店家註冊按鈕 呼叫 需要拿到註冊的三個輸入框 獲取這些按鈕(找到他們) 再獲取註冊按鈕 和關閉按鈕註冊按鈕直接找,然後新增一個點選事件關閉按鈕直接找,然後獲取點選事件 重寫進入方法
1億使用者的訪問量的伺服器架構
我們以淘寶架構為例,瞭解下大型電商專案的服務端架構是怎樣的,如圖1所示: 上面是一些安全體系系統,如資料安全體系、應用安全體系、前端安全體系等。 中間是業務運營服務系統,如會員服務、商品服務、店鋪服務、交易服務等。 還有共享業務,如分散式資料層、資料分析服務、配置服務、資料搜尋服務等。
專題訓練-視訊點播伺服器架構設計
1.系統設計決策 1.1需求概述 某公司因業務需要,需建設一套視訊監控系統,經過架構設計,視訊監控系統包括視訊收集伺服器、視訊檔案伺服器、視訊點播伺服器、監控客戶端、點播客戶端、播放器、採集伺服器(DVR、DVS)、視訊採集節點(雲臺、攝像頭)。 視訊點播伺服器負責提供點播服務,監控客戶
mysql伺服器架構
mysql是最廣泛使用的開源資料庫之一,作為後端開發人員,或多或少都會和mysql打交道,本篇文章會從sql查詢語句的執行過程,來介紹mysql的伺服器架構, 查詢的過程大致分為從客戶端到伺服器,在伺服器上解析,生成執行計劃,執行,並返回結果給客戶端。如下圖1.1所示。 &nb
淺析國內某種端遊伺服器架構
做伺服器開發兩年了,也沒學到太多的東西,更多的應該是處理問題的思路。而思路決定你如何處理問題,我覺得這個很關鍵,比你噼裡啪啦的打了一通程式碼要好一些。現在逐漸從遊戲伺服器的邏輯層轉到了稍微深層次一點的內容了,比如伺服器架構,伺服器AOI,網路底層,一些庫等等,所以也慢慢的與大家分享交流下心得,免得閉門造車。國
修改常見伺服器的banner
curl -I yourdomain.com 能看到什麼? Server: Apache xxx PHP xxx XXX xxx ,明碼實價,一字排開。這是幹嘛,賣菜呢?我們不妨看看 curl -I www.google.com 結果如何:HTTP/1.1 302 FoundC
Serverless(無伺服器架構)4大優點和缺點
Serverless核心概念在早期,術語無伺服器 是指依賴於第三方應用程式或服務來管理伺服器端邏輯的應用程式。 此類應用程式是基於雲的資料庫(如Google Firebase)或身份驗證服務(如Auth0或AWS Cognito)。 它們被稱為後端即服務(BaaS)服務。
伺服器架構mysql主從同步
在主伺服器上建立mysql使用者建立使用者(使用root也可以,但是不建議) , 該使用者必須有 REPLICATION SLAVE 許可權 建立使用者:CREATE USER 'test1'@'192.168.8.%' IDENTIFIED WITH mysql_native_password b
伺服器架構inotify+rsync檔案實時同步
釋出伺服器上下載 wget https://github.com/downloads/rvoicilas/inotify-tools/inotify-tools-3.14.tar.gz 在程式碼釋出伺服器上安裝inotify,執行如下命令 tar xzvf inotify-tools-3.14.t
伺服器架構配置keepalived 雙機熱備
下載wget http://keepalived.org/software/keepalived-2.0.6.tar.gz mkdir /usr/local/keepalived/ tar -zxvf keepalived-2.0.6.tar.gz -C /usr/local/keepa
C/C++伺服器架構機制設計總結
近期在寫基於go的遊戲伺服器框架, 在全面脫離C/C++前, 需要對老架構進行一個總結 基於C/C++遊戲伺服器框架總體設計的還是不錯的, 兄弟們總體使用效果都是好評. 因為在技術上喜歡"偷懶", 所以在很多設計上, 都是力求簡單, 高效(開發效率). 基於任務的非同步DB查詢系統, 帶多重非同步
一個高可擴充套件的基於非阻塞IO的伺服器架構
目錄 執行緒體系結構 反應堆模式 元件架構 接收器 分配器 分配器級別事件處理器 應用程式級別事件處理器 總結 參考資料 如果你被要求去寫一個高可擴充套件性的基於JAVA的伺服器,你很快就會決定使用JAVA NIO包。為了讓伺服器跑起來,你可能會花很多時間閱讀部落格和教程來了解執行緒同