
卷積神經網路學習(一)——基本卷積神經網路搭建
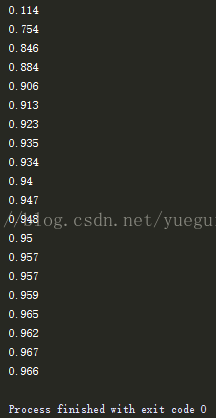
執行結果:#!/usr/bin/env python # -*- coding:utf-8 -*- import tensorflow as tf from tensorflow.examples.tutorials.mnist import input_data # number 1 to 10 data mnist = input_data.read_data_sets('MNIST_data',one_hot=True) # 輸出結果依然是準確度 def compute_accuracy(v_xs, v_ys): global prediction y_pre = sess.run(prediction, feed_dict={xs: v_xs, keep_prob: 1}) correct_prediction = tf.equal(tf.argmax(y_pre,1), tf.argmax(v_ys,1)) accuracy = tf.reduce_mean(tf.cast(correct_prediction, tf.float32)) result = sess.run(accuracy, feed_dict={xs: v_xs, ys: v_ys, keep_prob: 1}) return result # 定義Weight變數,輸入shape,返回變數的引數。其中我們使用tf.truncted_normal產生隨機變數來進行初始化: def weight_variable(shape): initial = tf.truncated_normal(shape,stddev=0.1) return tf.Variable(initial) # 定義biase變數,輸入shape ,返回變數的一些引數。其中我們使用tf.constant常量函式來進行初始化: def bias_variable(shape): initial = tf.constant(0.1,shape=shape) return tf.Variable(initial) # 定義卷積,tf.nn.conv2d函式是tensoflow裡面的二維的卷積函式,x是圖片的所有引數,W是此卷積層的權重,然後定義步長 # strides=[1,1,1,1]值,strides[0]和strides[3]的兩個1是預設值,中間兩個1代表padding時在x方向運動一步,y方向運動一步,padding採用的方式是SAME。 def conv2d(x,W): # stride [1,x_movement,y_movement,1] return tf.nn.conv2d(x,W,strides=[1,1,1,1],padding='SAME') # x為圖片的所有資訊 strides 步長 水平數值方向跨度都為1 # 為了得到更多的圖片資訊,padding時選擇的是一次一步,也就是strides[1]=strides[2]=1,這樣得到的圖片尺寸沒有變化 # 而我們希望壓縮一下圖片也就是引數能少一些從而減小系統的複雜度,因此我們採用pooling來稀疏化引數,也就是卷積神經網路中所的下采樣層。 # pooling 有兩種,一種是最大值池化,一種是平均值池化,本例採用的是最大值池化tf.max_pool()。 # 池化的核函式大小為2x2,因此ksize=[1,2,2,1],步長為2,因此strides=[1,2,2,1]: def max_pool_2x2(x): return tf.nn.max_pool(x,ksize=[1,2,2,1],strides=[1,2,2,1],padding='SAME') # define placeholder for inputs to network xs = tf.placeholder(tf.float32, [None, 784])/255. # 28x28 ys = tf.placeholder(tf.float32, [None, 10]) # 定義了dropout的placeholder,它是解決過擬合的有效手段 keep_prob = tf.placeholder(tf.float32) # 先處理xs的資訊(傳入圖片的資訊),把xs的形狀變成[-1,28,28,1],-1代表先不考慮輸入的圖片例子多少這個維度,後面的1是channel的數量, # 因為我們輸入的圖片是黑白的,因此channel是1,例如如果是RGB影象,那麼channel就是3。 x_image = tf.reshape(xs, [-1, 28, 28, 1]) # print(x_image.shape) # [n_samples, 28,28,1] ## conv1 layer ## # 先定義本層的Weight,本層我們的卷積核patch的大小是5x5,因為黑白圖片channel是1所以輸入是1,輸出是32個featuremap W_conv1 = weight_variable([5, 5, 1, 32]) # patch 5x5, in size 1, out size 32 # 定義bias,它的大小是32個長度,因此我們傳入它的shape為[32] b_conv1 = bias_variable([32]) # 搭建CNN的第一個卷積層,(輸入*weight+bias),同時巢狀一個relu的非線性處理,也就是啟用函式。 h_conv1 = tf.nn.relu(conv2d(x_image, W_conv1) + b_conv1) # 由於採用SAME的padding方式,輸出圖片的大小沒有變化,只是厚度變厚了。output size 28x28x32 h_pool1 = max_pool_2x2(h_conv1) # 最後進行pooling處理,output size 14x14x32 ## conv2 layer ## # 定義CNN的第二個卷積層 W_conv2 = weight_variable([5, 5, 32, 64]) # patch 5x5, in size 32, out size 64(假設) b_conv2 = bias_variable([64]) h_conv2 = tf.nn.relu(conv2d(h_pool1, W_conv2) + b_conv2) # 輸入layer1所輸出的結果。output size 14x14x64 h_pool2 = max_pool_2x2(h_conv2) # output size 7x7x64 ## fc1 layer ## # 接下來定義 fully connected layer W_fc1 = weight_variable([7*7*64, 1024]) # 輸入的shape是h_pool2展平了的輸出大小: 7x7x64,輸出1024 b_fc1 = bias_variable([1024]) # 進入全連線層時, 我們通過tf.reshape()將h_pool2的輸出值從一個三維的變為一維的資料, -1表示先不考慮輸入圖片例子維度, 將上一個輸出結果展平. # 形狀變換: [n_samples, 7, 7, 64] ->> [n_samples, 7*7*64] h_pool2_flat = tf.reshape(h_pool2, [-1, 7*7*64]) h_fc1 = tf.nn.relu(tf.matmul(h_pool2_flat, W_fc1) + b_fc1) # 矩陣相乘 h_fc1_drop = tf.nn.dropout(h_fc1, keep_prob) # 考慮overfitting加入一個dropout處理 ## fc2 layer ## W_fc2 = weight_variable([1024, 10]) # 輸入1024,輸出10個。[0-9]十個類 b_fc2 = bias_variable([10]) # 用softmax分類器(多分類,輸出是各個類的概率),對我們的輸出進行分類 prediction = tf.nn.softmax(tf.matmul(h_fc1_drop, W_fc2) + b_fc2) # the error between prediction and real data # 利用交叉熵損失函式來定義我們的cost function cross_entropy = tf.reduce_mean(-tf.reduce_sum(ys * tf.log(prediction), reduction_indices=[1])) # loss # 用tf.train.AdamOptimizer()作為我們的優化器進行優化,使我們的cross_entropy最小 train_step = tf.train.AdamOptimizer(1e-4).minimize(cross_entropy) # learning rate = 0.0001 sess = tf.Session() init = tf.global_variables_initializer() sess.run(init) # sess.run()時記得要用feed_dict給定義的placeholder喂資料. for i in range(1000): batch_xs, batch_ys = mnist.train.next_batch(100) sess.run(train_step, feed_dict={xs: batch_xs, ys: batch_ys, keep_prob: 0.5}) if i % 50 == 0: print(compute_accuracy( mnist.test.images[:1000], mnist.test.labels[:1000]))
相關推薦
卷積神經網路學習(一)——基本卷積神經網路搭建
#!/usr/bin/env python # -*- coding:utf-8 -*- import tensorflow as tf from tensorflow.examples.tutorials.mnist import input_data # numb
深度卷積神經網路學習(一)
卷積神經網路的基礎模組為卷激流包括卷積(用於維數拓展)、非線性(洗屬性、飽和、側抑制)、池化(空間或特徵型別的聚合)和批量歸一化(優化操作,目的是為了加快訓練過程中的收斂速度,同事避免陷入區域性最優)等四種操作。下面簡單介紹這四種操作。 1、卷積:利用卷積核對輸入影象進行處
卷積神經網路CNN(一)基本概念、卷積
卷積神經網路(Convolutional Neural Network)是一個專門針對影象識別問題設計的神經網路。它模仿人類識別影象的多層過程:瞳孔攝入畫素;大腦皮層某些細胞初步處理,發現形狀邊緣、方向;抽象判定形狀(如圓形、方形);進一步抽象判定(如判斷物體是氣球)。CNN
卷積神經網絡學習(一)
適應 什麽 小學 邊緣 檢測 sim 概念 alt 解釋 一、卷積的物理意義 卷積的重要的物理意義是:一個函數(如:單位響應)在另一個函數(如:輸入信號)上的加權疊加。 在輸入信號的每個位置,疊加一個單位響應,就得到了輸出信號。這正是單位響應是如此重要的原因。 二、卷積的另
經典神經網路學習(一)——AlexNet
AlexNet網路是AlexNet在2012年ImageNet大賽上一舉奪魁隨後一炮而紅,開啟了深度學習時代的網路。Alexnet一共包含8個層,其中5個卷積層,3個全連線層,用softMAx實現1000類分類。 AlexNet網路結構圖: AlexNet網路結構圖
7天hadoop學習(一)之虛擬機器的網路連線方式及linux的靜態ip設定
學習hadoop需要用到linux,所以視訊中講解了一些用到的linux知識。 如果通過虛擬機器進去linux系統一直讀進度條就是進不去主機頁面,有可能是網絡卡原因,那麼在虛擬機器設定選項選擇高階,重新生成MAC地址。 http://www.cnblogs.com/xi
Windows下基於Caffe的SSD網路學習(一)配置加生成自己的資料集
最近準備要做畢業設計了,所以從頭又配了一遍Caffe,學了一遍SSD,看了Caffe的原始碼,準備對SSD網路做一些改進。由於這已經是第n遍配置Caffe了,但是還是費了不少時間,所以意識到,總結還是很重要的,所以寫下部落格記錄這一路如何走來,同時也希望可以給有需
Django學習(一)---基本配置及創建項目、應用
cut 維護 onf response settings 通過 學習 clu render 安裝:在Django官網下載最新版Django然後通過pip安裝即可 一、創建項目 進入文件夾,打開cmd窗口,輸入django-admin startproject myblog(
Guice源碼學習(一)基本原理
val args 就會 figure 但是 imp 屬性 div develop Guice是Google開發的一個開源輕量級的依賴註入框架,運行速度快,使用簡單。 項目地址:https://github.com/google/guice/ 最新的版本是4.1,本文基於
webService學習(一)基本概念和環境搭建
1、webService概念理解: WebService是一種跨程式語言和跨作業系統平臺的遠端呼叫技術。 所謂遠端呼叫,就是一臺計算機a上 的一個程式可以呼叫到另外一臺計算機b上的一個物件的方法,譬如,銀聯提供給商場的pos刷卡系統,商場的POS機轉賬呼叫的轉賬方法的程式碼其實是跑在銀
python面向物件學習(一)基本概念
目錄 1. 面向物件基本概念 1.1 過程和函式 1.2 面相過程 和 面相物件 基本概念 2. 類和物件的概念 1.1 類 1.3 物件 3. 類和物件的關係 4. 類的設計 大駝峰命名法 4.1 類名的確
TensorFlow 學習(一) 基本介紹
主要應用於:影象識別、聊天對話系統、自然語言處理等。 機器學習:監督學習、無監督學習。演算法:分類、迴歸。線性等 深度學習:神經網路,卷積神經網路(主要影象),迴圈神經網路(主要自然語言處理)等 TensorFlow 是深度學習框架,其他的比如 caffe 、Pytorch等。 Go
postgresql基礎學習(一)——基本命令和部分邏輯結構
目錄 安裝和配置 基本操作 邏輯結構 結構簡圖 結構說明 schema操作 小結: 安裝和配置 PostGresql ubuntu安裝: apt-get install postgresql service postgresql st
增強學習(一) ----- 基本概念
機器學習演算法大致可以分為三種: 1. 監督學習(如迴歸,分類) 2. 非監督學習(如聚類,降維) 3. 增強學習 什麼是增強學習呢? 增強學習(reinforc
JSP的學習(一)——基本語法
一、JSP基礎 ①簡介 JSP全稱Java Server Pages,Java伺服器頁面,是一種動態網頁開發技術,由sun公司定義,現在屬於Oracle公司。 JSP是基於html模板,可以在html模板中嵌入Java程式碼和JSP中的標籤。JSP=html+Java程
【計算機網路】(一)OSI, TCP/IP模型 & 網路HTTP、TCP、UDP、Socket 基本知識總結
OSI 七層模型 我們一般使用的網路資料傳輸由下而上共有七層,分別為物理層、資料鏈路層、網路層、傳輸層、會話層、表示層、應用層,也被依次稱為 OSI 第一層、第二層、⋯⋯、 第七層。 如下圖: 各層功能簡介 1.物理層(Physical Layer)
Kotlin 學習 (一) 基本語法
基本語法 定義包 包的宣告應處於原始檔頂部: package kotlin.demo import java.util.* 目錄與包的結構無需匹配:原始碼可以在檔案系統的任意位置。 定義函式 帶有兩個 Int 引數、返回 Int 的函式: fun sum
JAVA學習(一):JAVA開發環境的搭建
對於一門程式語言,首先要有開發環境,在這個環境之下,才能利用這門語言順利進行開發。 而一般,JAVA的開發環境我們用JDK來代表。 所以開發環境的搭建也就包含三個過程:下載,安裝和配置JDK。 1.下載JDK(java軟體開發工具包:編譯+執行),通過SUN官方網站
Android資料庫Realm學習(一)基本使用
剛剛開始用Realm,肯定是要對比著SQLite來琢磨的,說幾個個人認識: 一、SQLite中的資料庫名對應Realm的啥 Realm可以簡單直接使用,這個時候似乎是弱化了資料庫名的存在,也就是這個
HBase概念學習(一)基本架構
注:本文內容均不是原創,但是是我從多篇文章中摘錄結合而成,中間也插入了一些我的個人理解 --- 季義欽 參考文獻: 1 http://blog.csdn.net/woshiwanxin102213/article/details/17584043 2 http://ww