
CPU 100% 異常排查實踐與總結
1、問題背景
昨天下午突然收到運維郵件報警,顯示資料平臺伺服器cpu利用率達到了98.94%,而且最近一段時間一直持續在70%以上,看起來像是硬體資源到瓶頸需要擴容了,但仔細思考就會發現咱們的業務系統並不是一個高併發或者CPU密集型的應用,這個利用率有點太誇張,硬體瓶頸應該不會這麼快就到了,一定是哪裡的業務程式碼邏輯有問題。
2、排查思路
2.1 定位高負載程序 pid
首先登入到伺服器使用top命令確認伺服器的具體情況,根據具體情況再進行分析判斷。

通過觀察load average,以及負載評判標準(8核),可以確認伺服器存在負載較高的情況;
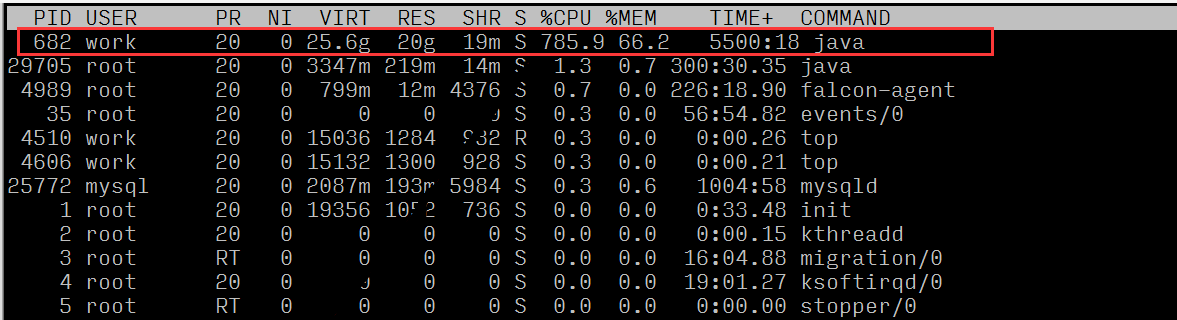
觀察各個程序資源使用情況,可以看出程序id為682的程序,有著較高的CPU佔比
2.2 定位具體的異常業務
這裡咱們可以使用 pwdx 命令根據 pid 找到業務程序路徑,進而定位到負責人和專案:

可得出結論:該程序對應的就是資料平臺的web服務。
2.3 定位異常執行緒及具體程式碼行
傳統的方案一般是4步:
- top oder by with P:1040 // 首先按程序負載排序找到 maxLoad(pid)
- top -Hp 程序PID:1073 // 找到相關負載 執行緒PID
- printf “0x%x\n”執行緒PID: 0x431 // 將執行緒PID轉換為 16進位制,為後面查詢 jstack 日誌做準備
- jstack 程序PID | vim +/十六進位制執行緒PID - // 例如:jstack 1040|vim +/0x431 -
但是對於線上問題定位來說,分秒必爭,上面的 4 步還是太繁瑣耗時了,之前介紹過淘寶的oldratlee 同學就將上面的流程封裝為了一個工具:show-busy-java-threads.sh,可以很方便的定位線上的這類問題:
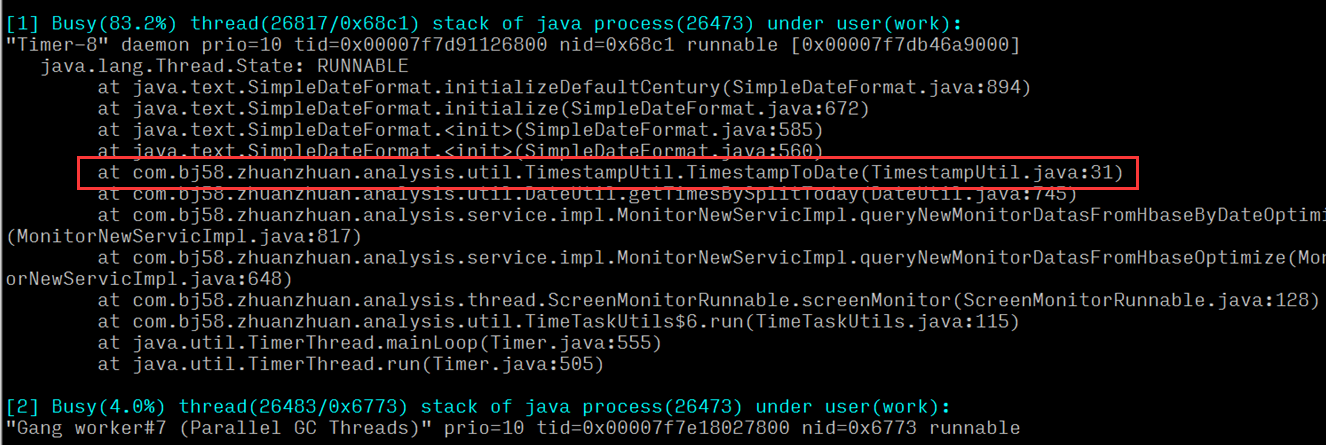
可得出結論:是系統中一個時間工具類方法的執行cpu佔比較高,定位到具體方法後,檢視程式碼邏輯是否存在效能問題。
※ 如果線上問題比較緊急,可以省略 2.1、2.2 直接執行 2.3,這裡從多角度剖析只是為了給大家呈現一個完整的分析思路。
3、根因分析
經過前面的分析與排查,最終定位到一個時間工具類的問題,造成了伺服器負載以及cpu使用率的過高。
- 異常方法邏輯:是把時間戳轉成對應的具體的日期時間格式;
- 上層呼叫:計算當天凌晨至當前時間所有秒數,轉化成對應的格式放入到set中返回結果;
- 邏輯層:對應的是資料平臺實時報表的查詢邏輯,實時報表會按照固定的時間間隔來,並且在一次查詢中有多次(n次)方法呼叫。
那麼可以得到結論,如果現在時間是當天上午10點,一次查詢的計算次數就是 10*60*60*n次=36,000*n次計算,而且隨著時間增長,越接近午夜單次查詢次數會線性增加。由於實時查詢、實時報警等模組大量的查詢請求都需要多次呼叫該方法,導致了大量CPU資源的佔用與浪費。
4、解決方案
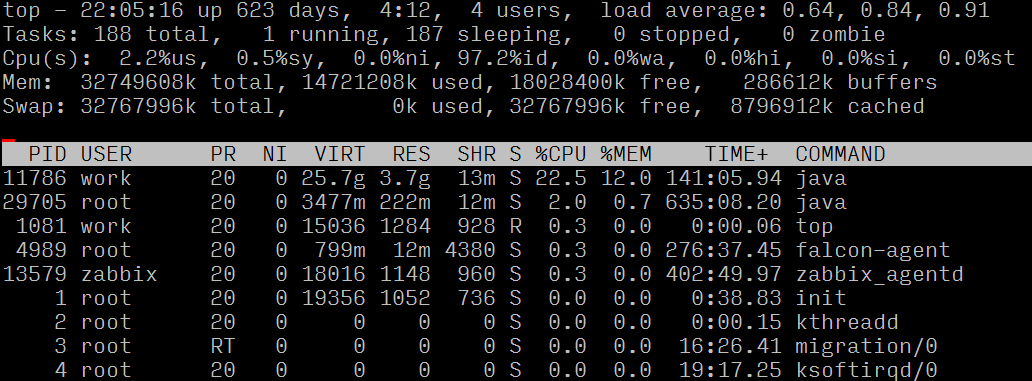
定位到問題之後,首先考慮是要減少計算次數,優化異常方法。排查後發現,在邏輯層使用時,並沒有使用該方法返回的set集合中的內容,而是簡單的用set的size數值。確認邏輯後,通過新方法簡化計算(當前秒數-當天凌晨的秒數),替換呼叫的方法,解決計算過多的問題。上線後觀察伺服器負載和cpu使用率,對比異常時間段下降了30倍,恢復至正常狀態,至此該問題得已解決。
5、總結
- 在編碼的過程中,除了要實現業務的邏輯,也要注重程式碼效能的優化。一個業務需求,能實現,和能實現的更高效、更優雅其實是兩種截然不同的工程師能力和境界的體現,而後者也是工程師的核心競爭力。
- 在程式碼編寫完成之後,多做 review,多思考是不是可以用更好的方式來實現。
- 線上問題不放過任何一個小細節!細節是魔鬼,技術的同學需要有刨根問題的求知慾和追求卓越的精神,只有這樣,才能不斷的成長和提升。
相關推薦
CPU 100% 異常排查實踐與總結
1、問題背景 昨天下午突然收到運維郵件報警,顯示資料平臺伺服器cpu利用率達到了98.94%,而且最近一段時間一直持續在70%以上,看起來像是硬體資源到瓶頸需要擴容了,但仔細思考就會發現咱們的業務系統並不是一個高併發或者CPU密集型的應用,這個利用率有點太誇張,硬體瓶頸應該
CPU負載過高異常排查實踐與總結
昨天下午突然收到運維郵件報警,顯示資料平臺伺服器cpu利用率達到了98.94%,而且最近一段時間一直持續在70%以上,看起來像是硬體資源到瓶頸需要擴容了,但仔細思考就會發現咱們的業務系統並不是一個高併發或者CPU密集型的應用,這個利用率有點太誇張,硬體瓶頸應該不會這麼快就到了,一定是哪裡的業務程式碼邏輯有問題
Spring Boot Tomcat 容器化部署實踐與總結
打通 目的 rim attribute exceptio process ntc with 初始化 在平時的工作和學習中經常會構建簡單的web應用程序。如果只是HelloWorld級別的程序,使用傳統的Spring+SpringMVC框架搭建得話會將大部分的時間花費在搭建框
Linux(2)---記錄一次線上服務 CPU 100%的排查過程
Linux(2)---記錄一次線上服務 CPU 100%的排查過程 當時產生CPU飆升接近100%的原因是因為專案中的websocket時時斷開又重連導致CPU飆升接近100% 。如何排查的呢 是通過日誌輸出錯誤資訊: 得知websocket時時重新 連線的資訊,然後找到原因 解決了。 當然這
BiLSTM+CRF(三)命名實體識別 實踐與總結
本博文是對上一篇部落格(https://blog.csdn.net/jmh1996/article/details/84779680 BiLSTM+CRF(二)命名實體識別 )的完善。 資料處理功能模組 語料庫資料格式: 訓練集: source_data.txt :文字 每一行為
看透設計模式-實踐與總結
23種設計模式,實際工作中,都是怎麼出現的呢? 有哪些示例呢? 本文探討 生活 與 工作實踐中 的設計模式, 但這裡不想牽扯 UML了。 01、簡單工廠模式 簡單工廠模式 又稱為 靜態工廠模式 模式場景:在一個披薩店中,要根據不同客戶的口味,生產不同的披薩,如素食披薩、希臘
常見的軟體異常場景分析與總結
根據最近一年多的排查軟體異常問題的經歷和經驗,簡單的總結一下軟體異常的場景和原因,以供參考。 1、野指標問題 可能是指標沒初始化就使用。也有可能是指標指向的記憶體已經被釋放,但是指標沒置為NULL,一旦訪問這樣的指標就會出問題。在很多情況(包括訪問空指標的情況)下可能會訪
再一次生產 CPU 高負載排查實踐
前言 前幾日早上開啟郵箱收到一封監控報警郵件:某某 ip 伺服器 CPU 負載較高,請研發儘快排查解決,傳送時間正好是凌晨。 其
《分布式服務框架原理與實踐》- 總結一下吧
配額 服務調用 全量 影響 ng- 依賴 線下 分布式服務框架 微服務架構 我們聽過無數的道理,卻仍舊過不好這一生。額,我說的是技術! 《分布式服務框架原理與實踐》這本書,一直在講一些大道理,和具體的業務和我本身的工作已經沒多大關系了。但是,不管怎麽樣,還得總結下吧
Druid出現DruidDataSource - recyle error - recyle error java.lang.InterruptedException: null異常排查與解決
cep TP 當前 pdu apt sql class light ror 線上的代碼之前運行的都很平穩,突然就出現了一個很奇怪的問題,看錯誤信息是第三方框架Druid報出來了,連接池回收連接時出現的問題。 2018-05-14 20:01:32.810 ERROR
服務器CPU繁忙或內存壓力引起網絡掉包的淺析與總結
AR 數據庫 repo RM mem this 功能 pro 分鐘 最近一段時間遇到了兩起有意思的故障,現象都是網絡掉包或網絡斷開,不過這些只是表面現象,引起現象出現的本質才是我們需要關註的重點: 案例1: 平臺 :VMware平臺 操作系統 :
Netty堆外記憶體洩露排查與總結
導讀 Netty 是一個非同步事件驅動的網路通訊層框架,用於快速開發高可用高效能的服務端網路框架與客戶端程式,它極大地簡化了 TCP 和 UDP 套接字伺服器等網路程式設計。 Netty 底層基於 JDK 的 NIO,我們為什麼不直接基於 JDK 的 NIO 或者其他NIO框架: 使用 JDK 自
Promise專案實踐與異常處理方式
Promise是解決回撥地獄的好工具,比起直接使用回撥函式promise的語法結構更加清晰,程式碼的可讀性大大增加。但是想要在真是的專案中恰當的運用promise可不是隨便寫個Demo這個簡單的,如果運用不當反而會增加程式碼的複雜性。 1. 使用Promise經常遇到的問題 1.
Atitit 計算機網路體系結構原理與實踐attilax總結 目錄 1. 計算機網路體系結構 1 1.1. Wmi 1 1.2. IPMI與BMC 1 1.3. Tcp/udp 2 1.4. 代理
Atitit 計算機網路體系結構原理與實踐attilax總結 目錄 1. 計算機網路體系結構 1 1.1. Wmi 1 1.2. IPMI與BMC 1 1.3. Tcp/udp 2 1.4. 代理與反向代理 2 1.5. TCP/IP的體系結
記一次yarn導致cpu飆高的異常排查經歷
yarn就先不介紹了,這次排坑經歷還是有收穫的,從日誌到堆疊資訊再到原始碼,很有意思,下面聽我說 問題描述: 叢集一臺NodeManager的cpu負載飆高。 程序還在但是看日誌已經不再向ResourceManager傳送心跳,不斷重複下文2的動作。 心跳停止一段時間後會重連上RM但是cpu仍然很高,再過
java CPU 100% 排查(轉載)
一個應用佔用CPU很高,除了確實是計算密集型應用之外,通常原因都是出現了死迴圈。 (友情提示:本博文章歡迎轉載,但請註明出處:hankchen,http://www.blogjava.net/hankchen) 以我們最近出現的一個實際故障為例,介紹怎麼定位和解決這類問題。 根據top命令,發現PI
java cpu高達100%問題 排查
一次系統測試時執行top命令發現cpu竟接近100%! 找到程序id 31260,執行jstack 31260 > cpu31260.log,將堆疊資訊dump到log檔案中。 通過top -p 31260 -H命令找到佔用cpu最多的執行緒,為31328 開啟cpu312
深入理解Java虛擬機器JVM高階特性與最佳實踐閱讀總結—— 第十二章 Java記憶體模型與執行緒
Java記憶體模型JMM,主要目標是定義程式中各個變數的訪問規則,即在虛擬機器中將變數儲存到記憶體和從記憶體讀取變數的底層細節,這裡的變數不包括執行緒私有的變數,如區域性引數;記憶體模型規定所有變數儲存在主記憶體;每個執行緒都有自己的工作記憶體,其中儲存了該執行緒用到的變數
記錄一次cpu 100%線上問題排查
功能問題,通過日誌,單步除錯相對比較好定位。 效能問題,例如線上伺服器CPU100%,如何找到相關服務,如何定位問題程式碼,更考驗技術人的功底。 最近做專案時碰到線上某臺例項不時出現CPU 100%的報警:線上部署了若干tomcat例項,即若干垂直切分的Java站點服務
放棄Dubbo,選擇最流行的Spring Cloud微服務架構實踐與經驗總結
在使用 Spring Cloud 之前,我們對微服務實踐是沒有太多的體會和經驗的。從最初的開源軟體雲收藏來熟悉 Spring Boot,到專案中的慢慢使用,再到最後全面擁抱 Spring Cloud。這篇文章給大家介紹我們使用 Spring Boot / Cloud 一年多的