
Python爬蟲實戰之爬取B站番劇資訊(詳細過程)
目標:爬取b站番劇最近更新
輸出格式:名字+播放量+簡介
那麼開始擼吧~用到的類庫:
requests:網路請求
pyquery:解析xml文件,像使用jquery一樣簡單哦~
1.分析頁面佈局,找到需要爬取的內容
設計video類:
import requests
from pyquery import PyQuery as pq
class Video(object):
def __init__(self,name,see,intro):
self.name=name
self.see=see
self.intro=intro
def 分析完頁面,設取爬去類:
class bilibili(object):
host="https://bangumi.bilibili.com"
def __init__(self):
self.dom=pq(requests.get('https://bangumi.bilibili.com/22/').text)
def get_recent(self):
'''最近更新''' 測試執行一下:
哎呀,怎麼回事,居然返回為空
這種情況下不要慌,如果程式碼沒有錯誤,那麼一般是由兩種情況造成
沒有選擇到目標,頁面是js動態載入的
我們先試下第一種情況,開啟瀏覽器,f12,將選擇字串複製到console中執行下,我們這就是$('#list_bangumi_new .c-list .new .c-item')

可以選擇到我們想要的目標,那看來是頁面js動態載入了,那就方便我們了,我們就只要找到它的介面就好了,開啟瀏覽器,f12,在network裡面尋找一下就好了,
url:https://bangumi.bilibili.com/api/timeline_v2_global

這是一個item的資訊,裡面有我們想要的名字資訊,那接下來就是去詳情頁尋找播放量和簡介了,但是詳情頁連結在哪那,剛剛那個接口裡並沒有,我們f12,審查一下元素。
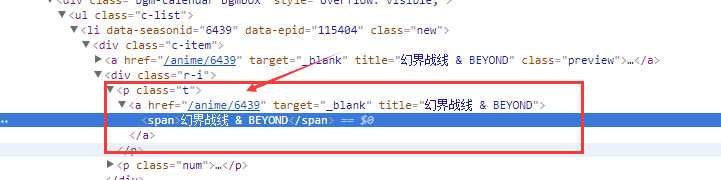
這裡的連結是/anime/6439,剛剛的接口裡並沒有這個資訊啊,那這個資訊應該就是拼接出來的了,關鍵就是6439這個數字了,去剛剛那個介面資訊裡尋找一下,果然找到了一個season_id欄位符合,那麼詳情頁連結就構造如下:
detail_url = "https://bangumi.bilibili.com/anime/{season_id}"
那麼接下來就是去分析詳情頁,爬去我們想要播放量和簡介資訊了,構造爬去程式碼如下:
see = d(".info-count .info-count-item").eq(1).find('em').text()
intro = d('.info-desc-wrp').find('.info-desc').text()
那麼最終爬取類關鍵程式碼如下:
class bilibili(object):
recent_url = "https://bangumi.bilibili.com/api/timeline_v2_global" # 最近更新
detail_url = "https://bangumi.bilibili.com/anime/{season_id}"
def __init__(self):
self.dom=pq(requests.get('https://bangumi.bilibili.com/22/').text)
def get_recent(self):
'''最近更新'''
items=json.loads(requests.get(self.recent_url).text)['result']
videos=[]
for i in items:
name=i['title']
link=self.detail_url.format(season_id=i['season_id'])
d=pq(requests.get(url=link).text)
see = d(".info-count .info-count-item").eq(1).find('em').text()
intro = d('.info-desc-wrp').find('.info-desc').text()
videos.append(Video(name=name,see=see,intro=intro))
return videos執行一下:

很ok,那接下來把它做成命令列~
2.製作命令列版
用到的類庫:
argparse:解析命令列引數
主要程式碼如下:
if __name__ == '__main__':
parser=argparse.ArgumentParser()
parser.add_argument('--recent',help="get the recent info",action="store_true")
parser.add_argument('--num',help="The number of results returned,default show all",type=int,default=0)
parser.add_argument('-v','--version',help="show version",action="store_true")
args=parser.parse_args()
if args.version:
print("bilibili 1.0")
elif args.recent:
b = bilibili()
b.get_recent(args.num)看下效果:

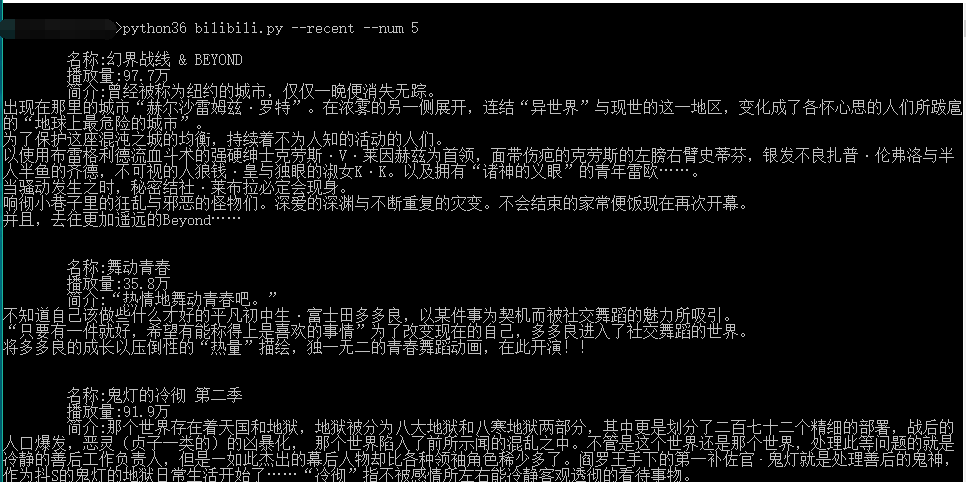
ok,大功告成,接下來大家就自由發揮新增更多的功能吧~:)
相關推薦
Python爬蟲實戰之爬取B站番劇資訊(詳細過程)
目標:爬取b站番劇最近更新 輸出格式:名字+播放量+簡介 那麼開始擼吧~ 用到的類庫: requests:網路請求 pyquery:解析xml文件,像使用jquery一樣簡單哦~ 1.分析頁面佈局,找到需要爬取的內
Python 網路爬蟲實戰:爬取 B站《全職高手》20萬條評論資料
本週我們的目標是:B站(嗶哩嗶哩彈幕網 https://www.bilibili.com )視訊評論資料。 我們都知道,B站有很多號稱“鎮站之寶”的視訊,擁有著數量極其恐怖的評論和彈幕。所以這次我們的目標就是,爬取B站視訊的評論資料,分析其為何會深受大家喜愛。 首先去調研一下,B站評論數量最多的視訊是哪一
Python爬蟲例項:爬取B站《工作細胞》短評——非同步載入資訊的爬取
《工作細胞》最近比較火,bilibili 上目前的短評已經有17000多條。 先看分析下頁面 右邊 li 標籤中的就是短評資訊,一共20條。一般我們載入大量資料的時候,都會做分頁,但是這個頁面沒有,只有一個滾動條。 隨著滾動條往下拉,資訊自動載入了,如下圖,變40
Python爬蟲實戰之爬取鏈家廣州房價_04鏈家的模擬登入(記錄)
問題引入 開始鏈家爬蟲的時候,瞭解到需要實現模擬登入,不登入不能爬取三個月之內的資料,目前暫未驗證這個說法是否正確,這一小節記錄一下利用瀏覽器(IE11)的開發者工具去分析模擬登入網站(鏈家)的內部邏輯過程,花了一個週末的時間,部分問題暫未解決。 思路介
爬蟲練習四:爬取b站番劇字幕
由於個人經常在空閒時間在b站看些小視訊歡樂一下,這次就想到了爬取b站視訊的彈幕。 這裡就以番劇《我的妹妹不可能那麼可愛》第一季為例,抓取這一番劇每一話對應的彈幕。 1. 分析頁面 這部番劇的第一季就有15話,所以我們首先需要找到每一話對應的url,然後再去爬取每一話的彈幕。 1.1 找
Python爬蟲實戰(3)-爬取豆瓣音樂Top250資料(超詳細)
前言 首先我們先來回憶一下上兩篇爬蟲實戰文章: 第一篇:講到了requests和bs4和一些網頁基本操作。 第二篇:用到了正則表示式-re模組 今天我們用lxml庫和xpath語法來爬蟲實戰。 1.安裝lxml庫 window:直接用pip去
python 爬蟲實戰4 爬取淘寶MM照片
寫真 換行符 rip 多行 get sts tool -o true 本篇目標 抓取淘寶MM的姓名,頭像,年齡 抓取每一個MM的資料簡介以及寫真圖片 把每一個MM的寫真圖片按照文件夾保存到本地 熟悉文件保存的過程 1.URL的格式 在這裏我們用到的URL是 http:/
Python 爬蟲入門之爬取妹子圖
Python 爬蟲入門之爬取妹子圖 來源:李英傑 連結: https://segmentfault.com/a/1190000015798452 聽說你寫程式碼沒動力?本文就給你動力,爬取妹子圖。如果這也沒動力那就沒救了。 GitHub 地址:&
如何利用Python快速爬取B站全站視訊資訊
B 站我想大家都熟悉吧,其實 B 站的爬蟲網上一搜一大堆。不過 紙上得來終覺淺,絕知此事要躬行,我碼故我在。最終爬取到資料總量為 760萬 條。 準備工作 首先開啟 B 站,隨便在首頁找一個視訊點選進去。常規操作,開啟開發者工具。這次是目標是通過爬取 B 站提供的 api 來獲取視訊資
Python進階(十八)-Python3爬蟲小試牛刀之爬取CSDN部落格個人資訊
分享一下我的偶像大神的人工智慧教程!http://blog.csdn.net/jiangjunshow 也歡迎轉載我的文章,轉載請註明出處 https://blog.csdn.net/mm2zzyzzp Python進階(十八)-Python3爬蟲實踐
python爬蟲學習之爬取全國各省市縣級城市郵政編碼
例項需求:運用python語言在http://www.ip138.com/post/網站爬取全國各個省市縣級城市的郵政編碼,並且儲存在excel檔案中 例項環境:python3.7 requests庫(內建的python庫,無需手動安裝) xlwt庫(需要自己手動安裝) 例項網站:
python爬蟲入門之爬取小說.md
新手教學:用Python爬取小說 我們在學習Python之餘總想著讓其更具趣味性,可以更好地學習。下面我將講解如何去從網站中爬取我們想看的小說。讓我們枯燥無聊的學習生涯稍微多些趣味。 需要只是一點點對requests庫、Beautiful庫及python基礎知識
如何用Python快速爬取B站全站視訊資訊
B站我想大家都熟悉吧,其實 B 站的爬蟲網上一搜一大堆。不過紙上得來終覺淺,絕知此事要躬行,我碼故我在。最終爬取到資料總量為 760萬 條。 準備工作 首先開啟 B 站,隨便在首頁找一個視訊點選進去。常規操作,開啟開發者工具。這次是目標是通過爬取 B 站提供的 api 來獲取視訊資訊,不去解析網頁
python爬蟲例項之爬取智聯招聘資料
這是作者的處女作,輕點噴。。。。 實習在公司時領導要求學習python,python的爬蟲作為入門來說是十分友好的,話不多說,開始進入正題。 主要是爬去智聯的崗位資訊進行對比分析出java和python的趨勢,爬取欄位:工作地點,薪資範圍,要求學歷,
[python3.6]爬蟲實戰之爬取淘女郎圖片
原博主地址:http://cuiqingcai.com/1001.html 原博是python2.7寫的,並且隨著淘寶程式碼的改版,原博爬蟲已經不可用。 參考 http://minstrel.top/TaoBaoMM 這位博主跟我一樣最近正在學習爬蟲。 1 定個小目標 l
python3 爬蟲實戰之爬取網易新聞APP端
(一)使用工具 這裡使用了火狐瀏覽器的user-agent外掛,不懂的可以點這裡火狐外掛使用 (二)爬蟲操作步驟: 百度 網易新聞並選擇 步驟一: 步驟二: 步驟三: 步驟四: 最後一步: 注意點: (1
Python爬蟲實戰之抓取淘寶MM照片(一)
背景 Python爬蟲系列教程的一次實戰,然而淘寶進行過頁面改版,現在已經沒有淘寶MM這個版面,取而代之的是淘女郎。改版後,頁面是使用JS渲染的,並不能直接通過url來切換頁碼。該系列教程後續講到
python 爬蟲實戰專案--爬取京東商品資訊(價格、優惠、排名、好評率等)
利用splash爬取京東商品資訊一、環境window7python3.5pycharmscrapyscrapy-splashMySQL二、簡介 為了體驗scrapy-spla
python爬蟲系列之爬取百度文庫(一)
一、什麼是selenium 在爬取百度文庫的過程中,我們需要使用到一個工具selenium(瀏覽器自動測試框架),selenium是一個用於web應用程式測試的工具,它可以測試直接執行在瀏覽器中,就像我們平時用瀏覽器上網一樣,支援IE(7,8,9,10,11),firefo
Python爬蟲實戰(6)-爬取QQ空間好友說說並生成詞雲(超詳細)
前言 先看效果圖: TXT檔案: 如果想生成特定圖片樣式的詞雲圖,可以直接訪問下面這篇文章學一下: https://mp.weixin.qq.com/s/FUwQ4jZu6KMkjRvEG3UfGw 前幾天我們陸陸續續的講了Python如何生成