
Trie樹的常見應用大總結(面試+附程式碼實現)
Trie樹,又稱字典樹,單詞查詢樹或者字首樹,是一種用於快速檢索的多叉樹結構,如英文字母的字典樹是一個26叉樹,數字的字典樹是一個10叉樹。他的核心思想是空間換時間,空間消耗大但是插入和查詢有著很優秀的時間複雜度。
(二)Trie的定義
Trie樹的鍵不是直接儲存在節點中,而是由節點在樹中的位置決定。一個節點的所有子孫都有相同的字首(prefix),從根節點到當前結點的路徑上的所有字母組成當前位置的字串,結點可以儲存當前字串、出現次數、指標陣列(指向子樹)以及是否是結尾標誌等等。
typedef struct Trie_Node { char count[15]; //單詞前綴出現的次數 struct Trie_Node* next[MAXN]; //指向各個子樹的指標 bool exist; //標記結點處是否構成單詞 }Trie;
Trie樹可以利用字串的公共字首來節約儲存空間,如下圖所示:
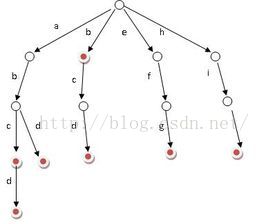
它有3個基本性質:
(1) 根節點不包含字元,除根節點外每一個節點都只包含一個字元。
(2) 從根節點到某一節點,路徑上經過的字元連線起來,為該節點對應的字串。
(3) 每個節點的所有子節點包含的字元都不相同。
(三)Trie樹的基本操作
(1)插入操作
按下標索引逐個插入字母,若當前字母存在則繼續下一個,否則new出當前字母的結點,所以插入的時間複雜度只和字串的長度n有關,為O(n)。
(2)查詢操作void Insert(Trie *root, char* s,char *add) { Trie *p=root; while(*s!='\0') { if(p->next[*s-'a']==NULL) { p->next[*s-'a']=createNode(); } p=p->next[*s-'a']; // p->count=add; ++s; } p->exist=true; strcpy(p->count,add); }
和插入操作相仿,若查詢途中某一個結點並不存在,則直接就return返回。否則繼續下去,當字串結束時,trie樹上也有結束標誌,那麼證明此字串存在,return true;
int Search(Trie* root,const char* s)
{
Trie *p=root;
while(*s!='\0')
{
p=p->next[*s-'a'];
if(p==NULL)
return 0;
++s;
}
return p->count;
}(3)刪除操作
一般來說,對Trie單個結點的刪除操作不常見,所以我在這裡也只提供遞迴刪除整個樹的操作
void del(Trie *root)
{
for(int i=0;i<MAXN;i++)
{
if(root->next[i]!=NULL)
{
del(root->next[i]);
}
}
// free(root);
delete root;
}(4)遍歷操作
如果我們想要將trie中的字串排序輸出,直接先序遍歷即可。
void Print(Trie *root)
{
Trie *p=root;
if(p->exist)
cout<<p->name<<": "<<p->count<<endl;
for(int i=0;i<26;i++)
{
if(p->next[i]!=NULL){
Print(p->next[i]);
}
}
} (1)統計前綴出現的次數
這是Trie最基本的應用,每個結點的字母使用count記錄出現的次數即可。
這裡提供一道題目,hdu 1251供大家練習。
//hdu 1251 統計前綴出現次數
#include <cstdio>
#include <iostream>
#include <string>
#include <cstring>
using namespace std;
const int MAXN=26;
typedef struct Trie_Node
{
int count; //單詞前綴出現的次數
struct Trie_Node* next[MAXN]; //指向各個子樹的指標
bool exist; //標記結點處是否構成單詞
}Trie;
Trie* createNode()
{
//Trie* p =(Trie*)malloc(sizeof(Trie));
Trie *p=new Trie;
p->count=0;
p->exist=false;
memset(p->next,0,sizeof(p->next));
return p;
}
void Insert(Trie *root, const char* s)
{
Trie *p=root;
while(*s!='\0')
{
if(p->next[*s-'a']==NULL)
{
p->next[*s-'a']=createNode();
}
p=p->next[*s-'a'];
p->count+=1;
++s;
}
p->exist=true;
}
int Search(Trie* root,const char* s)
{
Trie *p=root;
while(*s!='\0')
{
p=p->next[*s-'a'];
if(p==NULL)
return 0;
++s;
}
return p->count;
}
void del(Trie *root)
{
for(int i=0;i<MAXN;i++)
{
if(root->next[i]!=NULL)
{
del(root->next[i]);
}
}
// free(root);
delete root;
}
int main()
{
char s[15];
bool flag=false;
Trie* root=createNode();
while(gets(s))
{
if(flag)
{
int ans=Search(root,s);
printf("%d\n",ans);
}
else
{
if(strlen(s)!=0)
Insert(root,s);
}
if(strlen(s)==0)
flag=true;
}
del(root);
return 0;
}給定一組字串s,k我們輸入k則需要翻譯成s,也就是說兩者是對映關係。接下來我們給出一段話,讓你翻譯出正常的文章。用map固然簡便,但是Trie的效率更加高。只需要在k的結尾結點出記錄下s即可。
這裡也提供一道題目,hdu 1075。(被註釋的是我原來的程式,wa了,有大神看出來麻煩告訴我一下,謝謝)。
/*
//hdu 1075對映
#include <cstdio>
#include <iostream>
#include <string>
#include <cstring>
#include <stdlib.h>
using namespace std;
const int MAXN=26;
typedef struct Trie_Node
{
char count[15]; //單詞前綴出現的次數
struct Trie_Node* next[MAXN]; //指向各個子樹的指標
bool exist; //標記結點處是否構成單詞
}Trie;
Trie* createNode()
{
Trie* p =(Trie*)malloc(sizeof(Trie));
p->exist=false;
memset(p->next,0,sizeof(p->next));
return p;
}
void Insert(Trie *root, char* s,char *add)
{
Trie *p=root;
while(*s!='\0')
{
if(p->next[*s-'a']==NULL)
{
p->next[*s-'a']=createNode();
}
p=p->next[*s-'a'];
// p->count=add;
++s;
}
p->exist=true;
strcpy(p->count,add);
}
void Search(Trie* root, const char* s)
{
Trie *p=root;
while(*s!='\0')
{
if(p->next[*s-'a']==NULL)
{
printf("%s",s);
return ;
}
p=p->next[*s-'a'];
++s;
}
if(p->exist)
printf("%s",p->count);
else
printf("%s",s);
}
void del(Trie *root)
{
for(int i=0;i<MAXN;i++)
{
if(root->next[i]!=NULL)
{
del(root->next[i]);
}
}
free(root);
}
int main()
{
char text[3013],from[15],to[15];
Trie* root=createNode();
scanf("%s",from);
while(scanf("%s",from),strcmp(from,"END"))
{
scanf("%s",to);
Insert(root,to,from);
}
scanf("%s",from);
getchar();
while(gets(text),strcmp(text,"END"))
{
int len=strlen(text);
for(int i=0;i<len;i++)
{
if(islower(text[i]))
{
int j=0;
char temp[15];
memset(temp,'\0',sizeof(temp));
while(islower(text[i]))
temp[j++]=text[i++];
Search(root,temp);
}
if(!islower(text[i]))
printf("%c",text[i]);
}
printf("\n");
}
return 0;
}
*/
#include<stdio.h>
#include<string.h>
#include<stdlib.h>
#include<string>
using namespace std;
struct node{
char dic[15];
node * next[26];
bool flag;
}*root;
node *build()
{
node *p=(node *)malloc(sizeof(node));
for(int i=0;i<26;i++)
p->next[i]=NULL;
p->flag=false;
return p;
}
void insert(char *earth,char *mars)
{
int len=strlen(mars);
node *p;
p=root;
for(int i=0;i<len;i++)
{
if(p->next[mars[i]-'a']==NULL)
p->next[mars[i]-'a']=build();
p=p->next[mars[i]-'a'];
}
p->flag=true;
strcpy(p->dic,earth);
}
void query(char *earth)
{
int len=strlen(earth);
node *p;
p=root;
for(int i=0;i<len;i++)
{
if(p->next[earth[i]-'a']==NULL)
{
printf("%s",earth);
return;
}
p=p->next[earth[i]-'a'];
}
if(p->flag)
printf("%s",p->dic);
else
printf("%s", earth);
}
int main()
{
char earth[15],mars[15],ask[3010];
scanf("%s",earth);
root=build();
while(scanf("%s",earth),strcmp(earth,"END"))
{
scanf("%s",mars);
insert(earth,mars);
}
scanf("%s",earth);
getchar();
while(gets(ask),strcmp(ask,"END"))
{
int len=strlen(ask);
for(int i=0;i<len;i++)
{
if(islower(ask[i]))
{
int j=0;
memset(earth,'\0',sizeof(earth));
while(islower(ask[i]))
earth[j++]=ask[i++];
query(earth);
}
if(!islower(ask[i]))
printf("%c",ask[i]);
}
printf("\n");
}
return 0;
}我的初步想法是和(1)類似,對(1)中的trie進行先序遍歷,將字串和出現次數存進一個結構體,最後對這個陣列進行快速排序,時間複雜度為O(nlogn),看網上說可以利用分治+trie
+最小堆,我還沒有仔細搞清楚,以後研究完在新增。
(4)輸入自動補全
其實原理都差不多,把字串結尾處的結點當作root,進行先序遍歷,即可得出所有以輸入的字串為字首的答案。
/ 自動補全
#include <cstdio>
#include <iostream>
#include <string>
#include <cstring>
using namespace std;
const int MAXN=26;
typedef struct Trie_Node
{
int count; //單詞出現的次數
struct Trie_Node* next[MAXN]; //指向各個子樹的指標
bool exist; //標記結點處是否構成單詞
char name[15];
}Trie;
Trie* createNode()
{
Trie* p =(Trie*)malloc(sizeof(Trie));
p->count=0;
p->exist=false;
memset(p->next,0,sizeof(p->next));
return p;
}
void Insert(Trie *root,char* word)
{
Trie *p=root;
char *s=word;
while(*s!='\0')
{
if(p->next[*s-'a']==NULL)
{
p->next[*s-'a']=createNode();
}
p=p->next[*s-'a'];
++s;
}
p->exist=true;
p->count+=1;
strcpy(p->name,word);
}
Trie* Search(Trie* root, char* s)
{
Trie *p=root;
while(*s!='\0')
{
p=p->next[*s-'a'];
if(p==NULL)
return 0;
++s;
}
return p;
}
void del(Trie *root)
{
for(int i=0;i<MAXN;i++)
{
if(root->next[i]!=NULL)
{
del(root->next[i]);
}
}
free(root);
}
void Print(Trie *root)
{
Trie *p=root;
if(p->exist)
cout<<p->name<<": "<<p->count<<endl;
for(int i=0;i<26;i++)
{
if(p->next[i]!=NULL){
Print(p->next[i]);
}
}
}
int main()
{
char s[15];
Trie* root=createNode();
for(int i=0;i<5;i++)
{
cin>>s;
Insert(root,s);
}
while(cin>>s)
{
Trie *ans=Search(root,s);
if(ans)
Print(ans);
}
del(root);
return 0;
}相關推薦
Trie樹的常見應用大總結(面試+附程式碼實現)
(一)Trie的簡介 Trie樹,又稱字典樹,單詞查詢樹或者字首樹,是一種用於快速檢索的多叉樹結構,如英文字母的字典樹是一個26叉樹,數字的字典樹是一個10叉樹。他的核心思想是空間換時間,空間消耗大但是插入和查詢有著很優秀的時間複雜度。(二)Trie的定義Trie樹的鍵不是
十大排序演算法的實現 十大經典排序演算法最強總結(含JAVA程式碼實現)
十大經典排序演算法最強總結(含JAVA程式碼實現) 最近幾天在研究排序演算法,看了很多部落格,發現網上有的文章中對排序演算法解釋的並不是很透徹,而且有很多程式碼都是錯誤的,例如有的文章中在“桶排序”演算法中對每個桶進行排序直接使用了Collection.sort
十大經典排序演算法最強總結(含JAVA程式碼實現)
0、排序演算法說明0.1 排序的定義對一序列物件根據某個關鍵字進行排序。0.2 術語說明穩定:如
2019 web 前端面試總結(內附面經)
這篇文章不適合拿到 BAT 的大佬及自制力特別差的人 本文只是提供複習的思路,以及我自己的一些面經,並沒有具體的題目 基本情況 據說先把 offer 亮出來才能吸引你們看下去。目前一共有五個。分別是順豐,拼多多,遠景智慧,老虎證券和貝殼。其實拿到拼多多以後很
十大經典排序演算法最強總結(含JAVA程式碼實現 +演算法Gif動圖)
最近在複習排序演算法,對於演算法自己理解的總是不那麼透徹,所以在網路上搜索到有很多優秀的總結,借前輩們的經驗來灌輸一下自己,也不失為一件有效的學習方法,更有效的學習和記憶,適合自己的都是好方法。這裡總結了十大經典排序演算法,並且有Gif動圖,讓你學習起來一目瞭然,快來一起學
設計模式總結(面試必問二)
1 裝飾設計模式(IO流) 對一組物件的功能進行增強時,就可以使用該模式進行問題的解決 好處:耦合行沒有那麼,被裝飾類的變化裝飾類的變化無關 特點:裝飾類和被裝飾類都必須屬於同一介面或者父類 interface Coder { publicvoid cod
小知識點 大總結(常用,必會)
x86 嵌套 參數 access 常用 標準輸出 mct 一個 bre 1、進入救援模式的幾種方法 centos7最小化安裝,在默認情況下,會出現如下界面: Install centos 7 Test this media & install centos
買什麼資料結構與演算法,這裡有:動態圖解十大經典排序演算法(含JAVA程式碼實現)
上篇的動圖資料結構反響不錯,這次來個動圖排序演算法大全。資料結構與演算法,齊了。 幾張動態圖捋清Java常用資料結構及其設計原理 本文將採取動態圖+文字描述+正確的java程式碼實現來講解以下十大排序演算法: 氣泡排序 選擇排序 插入排序 希爾排序
樹狀陣列---區間更新(差分陣列實現)
/* * @Author: Achan * @Date: 2018-10-28 12:55:01 * @Last Modified by: Achan * @Last Modified time: 2018-10-28 19:59:13 */ #incl
乾貨收藏:學習計算機絕對不能錯過的10大網站(內附網站連結)
導讀:本文整理出大資料和人工智慧領域最實用,質量最高的10大技術網站資訊,既可以用於豐富技術知識
10 大深度學習架構:計算機視覺優秀從業者必備(附程式碼實現)
近日,Faizan Shaikh 在 Analytics Vidhya 發表了一篇題為《10 Advanced Deep Learning Architectures Data Scientists Should Know!》的文章,總結了計算機視覺領域已經成效卓著的 10
哈夫曼樹與哈夫曼編碼(C語言程式碼實現)
在一般的資料結構的書中,樹的那章後面,著者一般都會介紹一下哈夫曼(HUFFMAN)樹和哈夫曼編碼。哈夫曼編碼是哈夫曼樹的一個應用。哈夫曼編碼應用廣泛,如 JPEG中就應用了哈夫曼編碼。 首先介紹什麼是哈夫曼樹。哈夫曼樹又稱最優二叉樹,是一種帶權路徑長度最短的二叉樹。所謂
十大經典排序演算法(含JAVA程式碼實現)
排序演算法說明0.1 排序的定義對一序列物件根據某個關鍵字進行排序。0.2 術語說明穩定:如果a原本在b前面,而a=b,排序之後a仍然在b的前面;不穩定:如果a原本在b的前面,而a=b,排序之後a可能會出現在b的後面;內排序:所有排序操作都在記憶體中完成;外排序:由於資料太大
GMM混合高斯背景建模C++結合Opencv實現(內附Matlab實現)
最近在做視訊流檢測方面的工作,一般情況下這種視訊流檢測是較複雜的場景,比如交通監控,或者各種監控攝像頭,場景比較複雜,因此需要構建背景影象,然後去檢測場景中每一幀動態變化的前景部分,GMM高斯模型是建模的一種方法,關於高斯建模的介紹有很多部落格了,大家可以去找一找,本篇部落格主要依賴於上
JAVA BIO,NIO,AIO詳解(附程式碼實現)
這幾天在看面試的東西,可能是自己比較笨,花了快兩天的時間才理清楚。特此記錄一下。 首先我們要理解的一個很重要概念是,客戶端連線和傳送資料是分開的,連線不代表立馬會傳輸資料。 說說BIO,NIO,AIO到底是什麼東西 BIO:同步堵塞 NIO:非同步堵塞 AIO:非同步非堵塞
靜態連結串列插入和刪除操作詳解(C語言程式碼實現)
本節主要講解靜態連結串列的插入和刪除操作,有關靜態連結串列的詳細講解請閱讀《靜態連結串列及C語言實現》一文。 在講解靜態連結串列的插入和刪除操作之前,我們假設有如下的靜態連結串列: 圖中,array[0] 用作備用連結串列的頭結點,array[1] 用作存放資料的連結串列的頭結點,array[0]
妖怪與和尚過河問題解法完全攻略(C++完整程式碼實現)
如圖 1 所示。有三個和尚和三個妖怪(也可翻譯為傳教士和食人妖)要利用唯一一條小船過河,這條小船一次只能載兩個人,同時,無論是在河的兩岸還是在船上,只要妖怪的數量大於和尚的數量,妖怪們就會將和尚吃掉。現在需要選擇一種過河的安排,保證和尚和妖怪都能過河且和尚不能被妖怪吃掉。 圖 1 妖怪與和尚過河遊戲
機器學習-實現簡單神經網路(筆記和程式碼實現)
一、神經網路簡介 神經網路演算法的發展歷史 起源:20世紀中葉,一種仿生學產品。 興起:環境->2進位制創新;能力->軟硬體;需求->人的價效比。 主要功能: 分類識別
機器學習:貝葉斯網淺析(附程式碼實現)
貝葉斯網的目的是為了從已知屬性推測其他未知屬性的取值。貝葉斯網是描述屬性間依賴關係的有向無環圖,並使用概率分佈表描述屬性的聯合概率分佈。如下圖(A指向B表示B依賴於A):貝葉斯網由結構G和引數Θ組成,即B=<G,Θ>。Θ定量描述了屬性間的依賴關係,即Θ包含了每個屬
歐幾里得距離評價(Python3.x程式碼實現)
1.定義 歐幾里得度量(euclidean metric)(也稱歐氏距離)是一個通常採用的距離定義,指在m維空間中兩個點之間的真實距離,或者向量的自然長度(即該點到原點的距離)。在二維和三維空間中的歐氏距離就是兩點之間的實際距離。 2.公式 3.注意事項 (1)因