
搜狗微信公眾號文章抓取
機器能做的事就別讓人來做!
目標: 抓取特定微信公眾號文章
思路:利用selenium模擬瀏覽器行為,進行抓取(理由:搜狗已將文章連結進行處理,且頁面為動態生成)
框架:

步驟:
1、登入搜狗
a、找到登入按鈕並點選
self.browser.find_element_by_id("loginbtn").click()
此時產生一個登入的iframe,其中還巢狀一個iframe,都是動態生成的,內嵌於該頁面的另一個新的html頁面,我們需要
定位到第二個iframe才能進行真正的登入操作
b、定位到登入介面的實際iframe
self.browser.switch_to.frame(0)
time.sleep(10)
self.browser.switch_to.frame("ptlogin_iframe") // ptlogin_iframe為實際登入介面的iframe
c、 實現qq快捷登入
利用qq實現快速登入,前提是你已登入自己的qq賬號,然後在頁面直接點選你的qq頭像即可實現登入操作。當然,你也可以通過賬號/密碼實現登入。 self.browser.find_element_by_id("qlogin_list").find_element_by_xpath("a").click() // 找到你的qq頭像對應的元素位置並點選
2、抓取文章
搜狗頁面呈現方式:
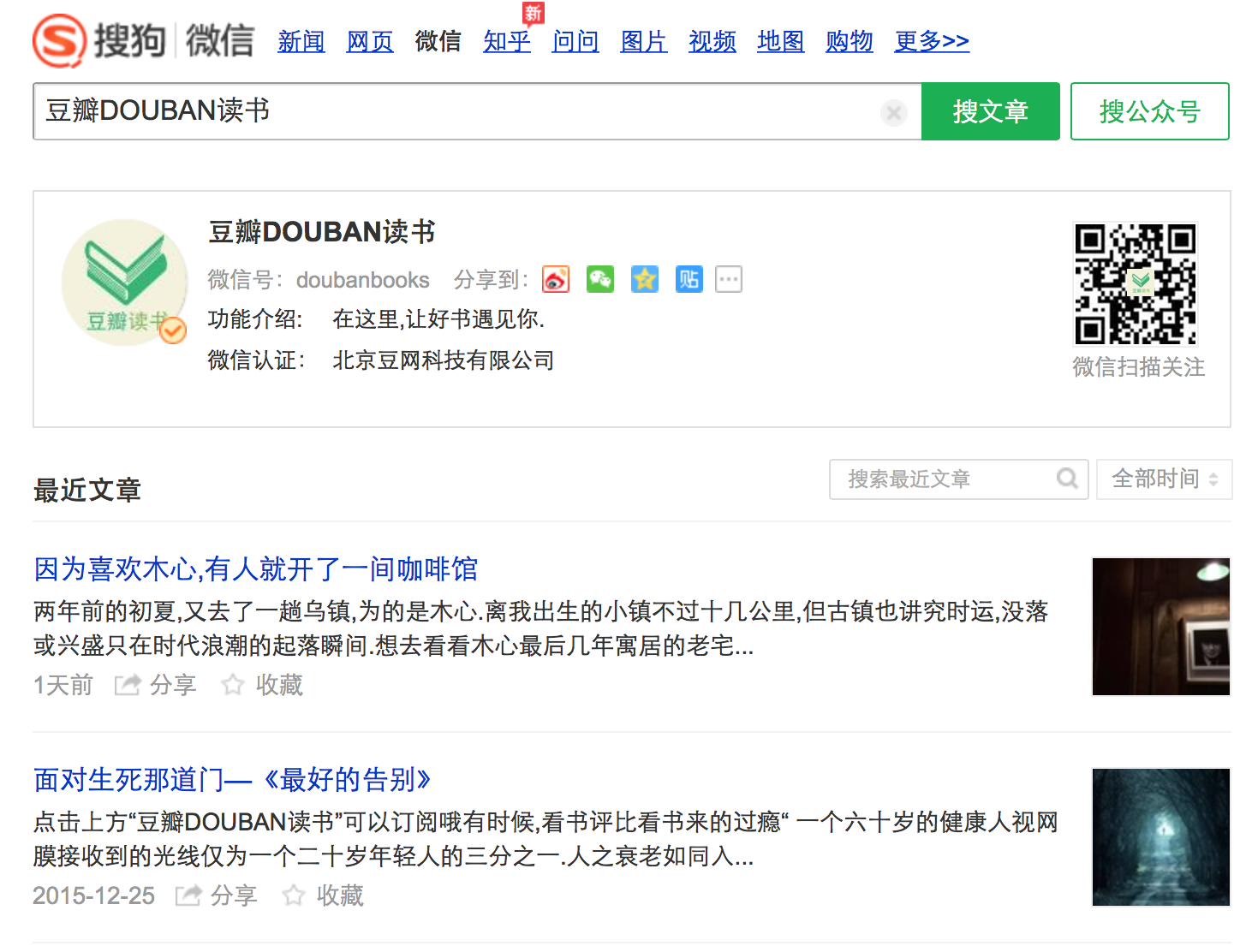
抓取資料格式: 標題, 概要資訊, 釋出時間, 圖片url, 文章實際url 通過審查元素,我們看一下每個文章在頁面原始碼中的表現形式,如下圖:

href連結到的是文章正文頁,但是該連結並非文章的實際連結地址,因此我們需要點選該連結到文章正文頁面獲取其真實連結。 其他元資料資訊則可由頁面直接獲取。具體獲取方法,即通過find_element定位到相應元素,獲取元素text資訊,此處不再 贅述。 說明一下獲取文章實際url,可通過點選文章標題或圖片跳轉到文章頁面,此時會新產生一個視窗,我們需要切換到該窗 口,才能獲取到當前的視窗URL,然後再切換回原來的視窗,繼續下一個文章元資料的抓取過程,具體操作如下:

1 def get_target_url(self, no): 2 """ 3 get real url(without encryption) of target page 4 :param no: NO. 5 :return target_url: 6 :Usage: 7 """ 8 box_a = self.get_box(no).find_element_by_xpath("div[@class='txt-box']//h4//a") # 找到標題元素並點選9 current_handle = self.browser.current_window_handle # 保留當前視窗控制代碼 10 box_a.click() 11 for handle in self.browser.window_handles: 12 if handle == current_handle: 13 continue 14 else: 15 # 切換到文章正文視窗,獲取url後關閉,並回到主視窗 16 self.browser.switch_to_window(handle) 17 target_url = self.browser.current_url 18 self.browser.close() 19 self.browser.switch_to_window(current_handle) 20 return target_url
3、抓取更多文章
初始頁面預設呈現10篇文章,點選頁面底部“檢視更多”可獲得更多文章,每次10篇,若到達最後,則不再出現“檢視更多”。具體做法:
審查元素獲取“檢視更多”並點選,每個文章對應一個div,其ID形式如“sogou_vr_11002601_box_0”,末尾的0是編號,順序遞增,檢視
更多後,可通過該ID值獲取最新出現的文章。
1 def get_more(self): 2 try: 3 more = self.browser.find_element_by_class_name("p-more") 4 if more.get_attribute("style") == "visibility: hidden;": 5 return False 6 else: 7 more.find_element_by_xpath("a").click() 8 return True 9 except Exception, e: 10 print e.message
相關推薦
搜狗微信公眾號文章抓取
機器能做的事就別讓人來做! 目標: 抓取特定微信公眾號文章 思路:利用selenium模擬瀏覽器行為,進行抓取(理由:搜狗已將文章連結進行處理,且頁面為動態生成) 框架: 步驟: 1、登入搜狗 a、找到登入按鈕並點選 self.browser.
微信文章抓取:微信公眾號文章抓取常識之臨時連結、永久連結
未經允許請勿轉載 曾經嘗試過抓取微信文章的小夥伴,一定很熟悉搜狗微信。搜狗微信是騰訊官方提供的搜尋引擎,專門用來搜尋微信公眾號發表的文章(不包含服務號)。 對於想要獲取微信文章進行研究學習的小夥伴,首先探索的途徑通常是搜狗微信。那麼關於搜狗微信以及微信相關的抓取,需
關於微信公眾號文章抓取
今天公司要我抓取微信公眾號文章,我百度了半天得到的方法有三種: 具體內容我就不復制了請去下面這個連結去看,寫的挺好 微信公眾號文章採集方案 在三者中我選擇了比較穩妥的第二種:對手機微信進行中間人攻擊 因為之前被封過小號,所以感覺解封微信太麻煩 而關於如何中間人攻擊請參考下面的連結
第三百三十節,web爬蟲講解2—urllib庫爬蟲—實戰爬取搜狗微信公眾號
文章 odin data 模塊 webapi 頭信息 hone 微信 android 第三百三十節,web爬蟲講解2—urllib庫爬蟲—實戰爬取搜狗微信公眾號 封裝模塊 #!/usr/bin/env python # -*- coding: utf-8 -*- impo
利用搜狗抓取微信公眾號文章
微信一直是一個自己玩的小圈子,前段時間搜狗推出的微信搜尋帶來了一絲曙光。搜狗搜尋推出了內容搜尋和公眾號搜尋兩種,利用後者可以抓取微信公眾號的最新內容,看了下還是比較及時的。 每個公眾號都有一個openid,最早可以直接利用http://weixin.sogou
記一次企業級爬蟲系統升級改造(四):爬取微信公眾號文章(通過搜狗與新榜等第三方平臺)
首先表示抱歉,年底大家都懂的,又涉及SupportYun系統V1.0上線。故而第四篇文章來的有點晚了些~~~對關注的朋友說聲sorry! SupportYun系統當前一覽: 首先說一下,文章的進度一直是延後於系統開發進度的。 當前系統V1.0 已經正式上線服役了,這
python爬蟲(17)爬出新高度_抓取微信公眾號文章(selenium+phantomjs)(上)
抓取微信公眾號的文章 一.思路分析 目前所知曉的能夠抓取的方法有: 1、微信APP中微信公眾號文章連結的直接抓取(http://mp.weixin.qq.com/s?__biz=MjM5MzU4ODk2MA==&mid=2735446906&idx=1&am
python爬蟲(17)爬出新高度_抓取微信公眾號文章(selenium+phantomjs)(下)(windows版本)
前兩天在linux 上面寫了一版爬取微信公眾號的文章 今天重新修改一下,讓它在windows上面也能執行 執行下面的程式碼需要安裝以下內容: pip install pyquery pip install requests pip install selenium
iframe顯示微信公眾號文章
origin replace dom節點 列表 charset string 請求 資料 domain 最近在做一個案例頁面,主要結構就是列表和內容,還有固定的頭部和底部(方便查看價格及購買),因為之前的案例詳情頁是很多的固定頁面,這樣不太方便維護,現在其他同事需要展示不同
python 多線程方法爬取微信公眾號文章
微信爬蟲 多線程爬蟲 本文在上一篇基礎上增加多線程處理(http://blog.51cto.com/superleedo/2124494 )執行思路:1,規劃好執行流程,建立兩個執行線程,一個控制線程2,線程1用於獲取url,並寫入urlqueue隊列3,線程2,通過線程1的url獲取文章內容,並保
微信PK10平臺開發與用python爬取微信公眾號文章
網址 谷歌瀏覽器 pytho google http 開發 微信 安裝python rom 本文通過微信提供微信PK10平臺開發[q-21528-76294] 網址diguaym.com 的公眾號文章調用接口,實現爬取公眾號文章的功能。註意事項 1.需要安裝python s
Python 爬蟲爬取指定微信公眾號文章
該方法是依賴於urllib2庫來完成的,首先你需要安裝好你的python環境,然後安裝urllib2庫 程式的起始方法(返回值是公眾號文章列表): def openUrl(): print("啟動爬蟲,開啟搜狗搜尋微信介面") # 載入頁面 url
如何採集微信公眾號文章|微信文章採集技巧
微信文章採集技巧用相關軟體就好了,推薦:痕夕軟體 推薦文章:微信營銷技巧:怎麼讓顧客主動找你 一、巧用二維碼 一般微信活動的分享,都會選擇通過連結、二維碼轉發來引流客戶,放大微信活動的營銷價值。除了微信朋友圈/微信群的轉發,還可以通過其他媒體平臺進行廣發“二維碼”,比如
微信公眾號文章的閱讀量和點贊數獲取指南
本文主要介紹“微信公眾號文章閱讀點贊API”的呼叫方法,以及呼叫前的準備工作和呼叫過程中可能出現的問題。 自打微信推出閱讀和點贊這一指標以來,網際網路上如何獲取、監控文章閱讀點讚的方法就層出不窮但卻不易實現,接下來,一起看看“微信公眾號文章閱讀點贊API”的呼叫。 在API測試頁,點
設定weixin://dl/business/?ticket=xxx喚起跳轉微信公眾號文章mp.weixin.qq.com/s/xxx的方法
很多人問我最近,怎麼樣外部手機瀏覽器才能開啟微信跳轉到公眾號文章連結,比如: https://mp.weixin.qq.com/s/COlBhig2NJO5IXpDiTBhDA ,這樣的連結又是如何生成的?檢視原始碼是通過 類似weixin://dl/business/?ticket=xxx這樣的地址實現
分享一個可以提高微信公眾號文章閱讀率的小工具!公眾號運營者必備哦!
這個工具叫“閱讀紅包”。 “閱讀紅包”是個什麼東西? 閱讀紅包可以理解為文章的彩蛋。 也就是,當你的粉絲閱讀完了你群發的文章,在文章末尾驚喜的發現了一個“領取紅包”的連結,該粉絲點選連結,即可按設定的中獎概率獲得一個微信紅包。 有什麼用處? 1. 給自己的粉
【Python爬蟲】爬取微信公眾號文章資訊準備工作
有一天發現我關注了好多微信公眾號,那時就想有沒有什麼辦法能夠將微信公眾號的文章弄下來,而且還想將一些文章的精彩評論一起搞下來。參考了一些文章,通過幾天的研究基本上實現了自己的要求,現在記錄一下自己的一些心得。 整個研究過程如下: 1.瞭解微信公眾號文章連結的組成,歷史文章API組成,單個文章
微信公眾號文章連結引數
https://mp.weixin.qq.com/s?src=3×tamp=1496819538&ver=1&signature=2Ui56lfdJ7txnkcz0Y0tXtfKXX8Dnh2Thra4pQ*iyV8afGJ7Z8umw
PC 上檢視微信公眾號文章的方法
1. 前言 在微信公眾號上,我關注了幾個很好的公眾號,比如玉剛說,鴻洋,郭霖。每天早上都會關注最新發文。遇到好的文章就收藏起來,有時間就拜讀一番,真得是受益匪淺。但是,在電腦上看,卻每次都是把連結從手機轉到電腦上開啟,很不方便。那麼,有沒有更好的辦法呢?有的。
用python爬取微信公眾號文章
本文通過微信提供的公眾號文章呼叫介面,實現爬取公眾號文章的功能。 # -*- coding: utf-8 -*- from selenium import webdriver import time import json import reques