
深入理解log機制
深入的探討了log機制中各種概念的來源、常用log庫的用法、內部處理流程,以及如何在一個涉及多臺主機的複雜系統中部署log等問題。本文是對這次分享的總結,將對這些問題一一展開介紹。
轉自:http://feihu.me/blog/2014/insight-into-log/
開場
log如今已經成為了我們日常開發時所必不可少的工具,它同debug一起構成了開發者手中分析問題最有力的兩個武器。兩者各有優劣,相輔相成,配合起來使用將變得無往不利。通常相比於debug來說,log在很大程度上可以更方便、更迅速的讓開發者分析程式的問題,尤其是對於非常龐大的系統、或者已經發布的程式,又或者一些非必現的問題,當我們無法方便的debug問題程式時,log檔案可以提供非常多有用的資訊,如果開發者log寫得比較合適,大多數情況下根據log就可以分析出問題所在。因此,log分析法深受開發者的喜愛。
記得初學程式設計,第一次聽到這樣一個觀點時那種難以接受心情,怎麼可能還有比debug更加容易分析程式問題的方法?好一個無知無畏!當然這一切都是源於當時寫的程式規模都比較小,非常適合debug的緣故吧。而實際上當時在不知不覺中已經或多或少使用了簡單的log,那一條條控制檯的cout與printf就是最好的證明。後來隨著程式規模越來越大,才明白debug的侷限性,逐漸的喜歡上了log。
勿在浮沙築高臺
現如今對於每一種開發語言都有非常多的庫來幫我們處理log,比如:log4j(log for Java),log4cpp(log for C++),log4net(log for .NET)等等。最早處理log的庫是
後面就用log4me作為我們使用的庫的名稱
讓我們先從無到有,從一個個簡單的使用場景一步一步分析log庫中各種概念如何發展而來。當然,我沒有去真正追究它的歷史,只是從個人需求角度分析得來。
最簡單的log
程式碼中經常會需要列印一些提示資訊用於顯示程式工作流程,或者反饋錯誤資訊,這就是所謂的log,就像船員的航海日誌一樣,我想log也是由此得名吧。為了輸出這些資訊,在C/C++中最簡單的方法是用printf或者std::cout:
增加有用資訊// I want to print a log: printf("I'm a message\n");
我們本可在每處需要列印log資訊時都採用這種方式,但不妨先停下來試想一下,如果在一個log檔案中你看到滿螢幕的這種資訊,但是卻無法知道是誰,在什麼時候,什麼位置輸出這條資訊,那這種log的價值便大大折扣。於是,你會需要在每條log中增加一些額外有用的資訊:
// I want to add more information:
printf("%s %s %d: I'm a message\n", time, __FILE__, __LINE__);這樣,每條log就有了時間,檔案和行號這些額外有用的資訊,非常有利於分析問題。
簡化呼叫:封裝
但是,這樣會不會太麻煩?每次在寫程式碼時,列印一條簡單的log你需要加這麼多無關的內容,萬一忘了怎麼辦,這簡直無法接受。你想要把所有的注意力都放在log本身上,不想關注其它的細技末節,怎麼辦?注意看,上面的函式呼叫中,後三個引數都是固定的,於是你可以對它進行這樣簡單的封裝:
// Too complicated:
#define printf0(message) \
printf("%s %s %d %s", time, __FILE__, __LINE__, message);
printf0("I'm a message\n");注:這裡用巨集而不採用函式,正如評價中@weitang指出的,如果是函式的話,__LINE__的值會一直是函式中的行號,是一個固定值,而不是呼叫處的行號。另外,這個版本的巨集只支援一個引數,後面呼叫它的其它函式中傳了可能不止一個引數,是為了演示方便。各位有興趣的話可以自行寫出合適的printf0版本。
還是一樣簡單的呼叫,不需要你再去輸入一些無關的內容,因為這個封裝的函式已經替你做好了。
設定等級:TraceLevel
log資訊並不是千篇一律只起一種作用,有的是紀錄程式的流程,有的是錯誤資訊,還有一些是警告資訊。為了讓log更有可讀性,你可能想要把不同的資訊區分開來,比如這樣:
// I want to distinguish different kinds of message:
printf0("Normal: I'm a normal message\n");
printf0("Warning: I'm a warning message\n");
printf0("Error: I'm an error message\n");那麼,你就可以通過在log檔案中搜索Normal、Warning或者Error這些關鍵字就能夠找到特定的log。這對於排錯幫助非常大,比如你只需要搜尋Error關鍵字就能夠得出程式的出錯資訊。
但是,這些Normal、Warning以及Error關鍵字需要你每次都加在要輸出的字串中,同前面一樣,你還是隻想關注log本身,不願意log和其它的資訊混在一起。於是可以這樣做:
// It's too complicated, I want something like this:
enum TraceLevel {
Normal,
Warning,
Error
};
void printf1(TraceLevel level, const char *message) {
char *levelString[] = {
"Normal: ",
"Warning: ",
"Error: "
}
printf0("%s %s", message, levelString[level]);
}
printf1(Normal, "I'm a normal message\n");
printf1(Warning, "I'm a warning message\n");
printf1(Error, "I'm an error message\n");現在你只需要指定一種log型別,就可以全心全意的處理log資訊本身了。我們把上面的Normal, Warning和Error叫做TraceLevel,故名思義,它表示log的等級。
可以進一步簡化:
// To be more convenient:
void printf_out(const char *message) {
printf1(Normal, message);
}
void printf_warn(const char *message) {
printf1(Warning, message);
}
void printf_error(const char *message) {
printf1(Error, message);
}
printf_out("I'm a normal message\n");
printf_warn("I'm a warning message\n");
printf_error("I'm an error message\n");如此一來,對於特定等級的log只需呼叫各自的log輸出函式即可,除此之外,注意力全部放在log資訊本身上。
在程式碼中,通常最多的log是Normal型別,即顯示程式流程。有時你可能只想log檔案中儲存Warning和Error型別的資訊,Normal對你來相當於干擾資訊,而且log檔案也會因此變得很大。有時你又會想讓log中包含所有型別。如何協調?如果可以動態的選擇哪些等級的資訊輸出,那豈不是log檔案就變得像是根據我的需求定製一般,可以隨意控制log包含哪些級別的資訊麼?
根據這一思路,程式碼可以這樣改變:
// I want to add a control which level should be printed:
TraceLevel getLevel1();
void printf2(TraceLevel level, const char *message) {
if (level >= getLevel1())
printf1(level, message);
}
printf2(Normal, "I'm a normal message\n");
printf2(Warning, "I'm a warning message\n");
printf2(Error, "I'm an error message\n");這裡暫時沒有采用前面簡化的方法。
getLevel1()從配置檔案中讀取當前允許的Level,程式碼中只有高於當前Level的log才會被輸出,現在log檔案便可以隨著你的需要而定製了。
多一些控制:Marker
再來考慮這樣一種情況,如果你的檔案非常大,中間要輸出的Normal log非常多,分為不同層次,比如:粗略的流程,詳細一些的,十分詳細的。和很多命令的-verbose引數一樣。由於都是Normal型別的log,所以不能夠用前面的TraceLevel,這時需要引入另外一層控制:
// My class is too big, I want a filter to determine which
// logs should be generated
const int SUB = 0;
const int TRACE_1 = 1 << 0;
const int TRACE_2 = 1 << 1;
const int TRACE_3 = 1 << 2;
int getMarker1();
void printf3(int marker, TraceLevel level, const char *message) {
if (marker == 0 || marker & getMarker1() != 0)
printf2(level, message);
}
printf3(SUB, Normal, "I'm a normal message\n");
printf3(TRACE_1, Normal, "I'm a normal message\n");
printf3(TRACE_2, Normal, "I'm a normal message\n");這裡提供了四級的控制,和前面的
TraceLevel一樣,它也可以通過配置檔案配置。假設現在配置的是TRACE_1,那麼程式碼中想要輸出的三條資訊中,只有前兩條能夠輸出。這層控制我們稱之為Marker。
注意到這裡定義的四級控制是可以通過位來操作的,能夠任意組合。如果想要TRACE_1和TRACE_2都能夠輸出,那麼只需要設定:
int marker = TRACE_1 | TRACE_2;
printf3(marker, Normal, "I'm a normal message\n");如果marker設定為SUB,則表明全部輸出。通過增加這層控制後,log的訂製變得更加靈活。
改變目的地:Appender
到目前為止,所有的log都寫到控制檯。如果你想log寫到檔案中怎麼辦?如果不是控制檯應用程式,比如,Win32或者MFC程式,log又該寫到哪裡去?也許你想到可以使用fwrite代替前面的printf,但是如果你想同時能夠將log寫到控制檯,又寫到檔案中或者其它地方怎麼辦?
放棄這種硬編碼的方法吧,你可以想到一種更加靈活,可以像前面TraceLevel和Marker一樣容易配置的方法,能夠更加優雅的控制log輸出的目的地,但不需要硬編碼在程式碼中,而是可以配置的。一起來看下面這段程式碼:
這裡定義了一個叫做Appender的基類,可以理解為處理log目的地的類,它有一個方法printf,對應著如何處理傳給它的log。
接下來定義了三個子類,分別代表輸出目的地為控制檯、檔案和Windows的EventLog。它們都覆寫了基類的printf方法,按照各自的目的地處理log的流向,比如ConsoleAppender呼叫前面的printf2函式,而FileAppender可能呼叫類似的fwrite。這樣一來,只要我們為一個程式配置用哪些Appender,log就可以根據這些配置交給對應的Appender子類處理,從而無需在程式碼中硬編碼。
這處理每一種目的地的類我們稱之為Appender。
模組獨立控制:Category
現在我們的log機制已經足夠的完善。但是,隨著程式規模越來越大,一個程式所包含的模組也越來越多,有時你並不想要一個全域性的配置,而是需要每一個模組可以獨立的進行配置,有了前面的介紹,這個需求就變得很簡單了:
// There are too many components, I want different components
// could be configured separately
TraceLevel getLevel2(const char *cat);
int getMarker2(const char *cat);
std::vector<Appender *> &getAppenders2(const char *cat);
void printf5(const char *cat, int marder, TraceLevel level,
const char *message) {
if (marker == 0 || marker & getMarker2(cat) != 0) {
if (level >= getLevel2(cat)) {
std::vector<Appender *>::iterator it = getAppenders(cat).begin();
for (; it != getAppenders.end(cat); it++)
(*it)->printf(level, message);
}
}
printf5("Library1", SUB, Normal, "I'm a normal message\n");
printf5("Library1", TRACE_1, Normal, "I'm a normal message\n");
printf5("Library1", TRACE_2, Normal, "I'm a normal message\n");對比前一節的程式碼,可以發現這裡除了增加一個引數
const char *cat以外,其它完全一樣。但正是這個引數的出現,才讓每一個模組可以獨立的配置。這種模組間獨立進行配置的方法我們稱為Category。
配置檔案
前面多次提到配置,為了達到可以靈活配置的目的,通常會將這些配置儲存成一個檔案,比如logConfig.ini:
Category: Library1 -> for Library1 category
TraceLevel : Warning -> only Warning and Error messages are allowed
Markers : TRACE_1 -> only TRACE_1 is allowed
Appenders :
ConsoleAppender -> write to console
FileAppender: -> write to file
filePath: C:\temp\log\trace_lib1.log
Category: Library2 -> for Library2 category
...那麼在什麼時機讀取這個配置檔案?一般有這樣幾種方式:
- 程式啟動時載入
logConfig.ini,如果配置不常改變時可以採用這種方式,最簡單。 - 建立一個新執行緒,間隔一段時間檢查
logConfig.ini是否已經改變,如果改變則重新讀取。這種方法比較複雜,可能會影響效率,而且間隔的時間也不好設定。 - 處理每一個log之前先檢測
logConfig.ini,如果有改變則重新讀取。 - 最後一種方法結合了前兩種方法的優點,還是在處理每個log之前檢測,但不同的是再加上一個時間間隔,如果超過時間間隔才會真的去檢測,而如果在間隔內,則直接忽略。這種方法更加高效且消耗資源最少。
對於後面三種方式,每次配置檔案有了更新之後,log輸出幾乎可以實時的作出應變。
至此,一個簡單靈活的log原型建立了,雖然它還是非常簡陋,但已經有了現代log庫的雛形,包含了其中幾個重要的概念。下面我將以我們所使用的log4me庫進行分析。
log庫常見用法
前面介紹的log雛形完全是小兒科式的程式碼,只是起一個演示作用,實際上我們無需重新發明輪子。如本文開始所介紹,已經有非常多專業的庫來處理log,這些庫以最簡單的介面提供了最大化的log資訊。我們這裡採用的log4me庫就有這樣幾個優點:
- 跨平臺,在Windows和Linux上有著完全一樣的介面與行為
- 更細的粒度來控制log
- 執行緒安全
- 高效能
我們定義了下面幾個巨集,專門用於Library1下的log輸出,這裡會取配置中Library1這個Category的配置,分別輸出不同TraceLevel的log。
#define LIB1_OUT(MESSAGE) LOG_OUT(Library1, DLL, Notice) << MESSAGE
#define LIB1_WARN(MESSAGE) LOG_OUT(Library1, DLL, Warn) << MESSAGE
#define LIB1_ERR(MESSAGE) LOG_OUT(Library1, DLL, Error) << MESSAGE
使用時像這樣:
LIB1_OUT("I'm a message.");
LIB1_WARN("I'm a message, ID = " << 1234);
LIB1_ERR("I'm a message.");這裡所有的配置都通過配置檔案完成,還有一種動態的在程式碼中建立log的方法,log4cpp的官方網站中有例子,我們這裡就不介紹了。
配置
在我們前面的演示程式碼中,提供了一種非常簡單的配置檔案,常見的儲存配置檔案的格式有xml,Windows的ini。log4me中使用的是前者,並且提供了專門的工具來簡化其操作,如下圖所示:
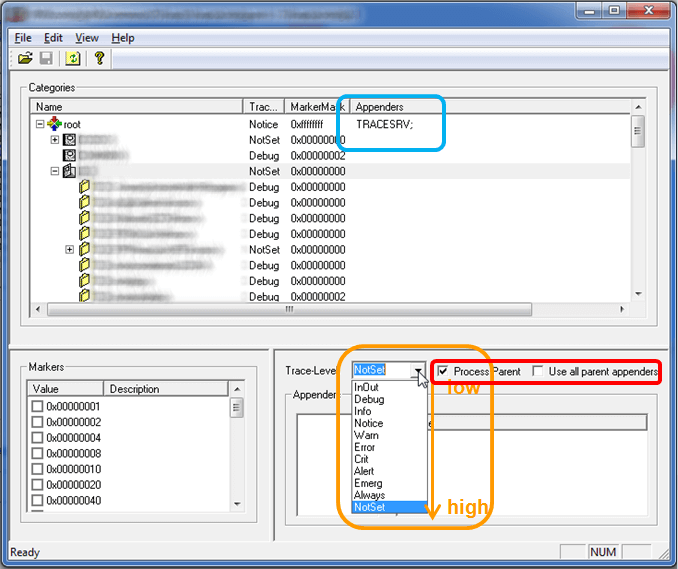
根據上圖我們進一步來看一些概念:
TraceLevel
TraceLevel用來控制輸出的log等級,下面這些比較常用:
INOUT : 進入和離開函式
DEBUG : 除錯資訊,通常用於診斷問題
INFO : 確認一切按計劃照常工作
WARNING : 程式仍然可以執行,但有意外發生,或者將來有問題可能要出現(比如硬碟容量低)
ERROR : 錯誤資訊
CRITICAL : 嚴重錯誤,表示程式可能無法繼續執行
ALWAYS : 始終輸出log這些等級按從上到下依次增加的順序排列,配置TraceLevel後,那麼只有上表中位於該level之下的才能夠輸出。
Marker
Marker用來進一步控制log的分類,不像前面的演示程式碼只定義了四種,通常庫會完全使用一個32位的整型來表示這些分類,每一位代表一類,這樣就有了32種分類,對於大多數應用場景來說這已經完全足夠。
Appender
前面介紹過Appender這個概念,它用來處理log的輸出目的地,但真正的庫可遠不止前面介紹的三種Appender,log4me提供了這些:
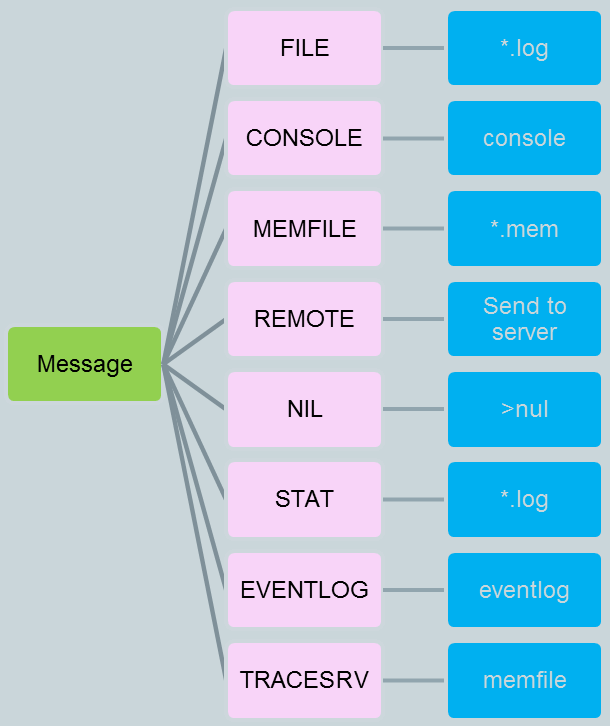
注意:最後一個Appender是TraceSrv,它寫到memfile中。什麼是memfile?這是Linux上的一種記憶體管理的方法,它將檔案對映到記憶體,通過直接讀寫記憶體來操作檔案,從而使檔案操作變得極其高效便捷,可以參考這裡:Linux記憶體管理之mmap詳解。
在Appender中還有一些常用的屬性可以配置:
- CreateNewFile: 表明log庫啟動時是否建立新檔案。
- FileCount & FileSize: 用於檔案回捲,比如一個log檔案lib.log過大時,可以將它重新命名為lib.1.log,然後再重新建立lib.log。可以建立多個檔案,而這兩個引數就用於控制檔案數目和單個檔案大小。
- CategoryFilter: 表明該Appender只處理這個filter列舉的Category。
- ProcessFilter: 與上面類似,只處理filter列舉的程序。
Formatter
這個概念在前面沒有介紹過,但它也非常容易理解:每個Appender都可以包含一個formatter,它用來格式化log資訊。因為一條log資訊可能包含時間,檔名,行號,TraceLevel,程序ID,正文等資訊,有時為了簡化log輸出,對所有的這些分類作一個取捨,從而達到格式化的目的。這很像C語言中的printf。
如果formatter設定的是:
%TIME%|%PID%|%LEVEL%|%MARKER%|%CAT%|%FILE%|%LINE%|%FUNC%|%USERTEXT%|那麼log的輸出會像這樣:
2014/04/07-16:03:35.251560|5560|Notice|SUB|COMP1|main.cpp|78|test|I'm a message|每一項都和前面formatter中設定的一一對應。
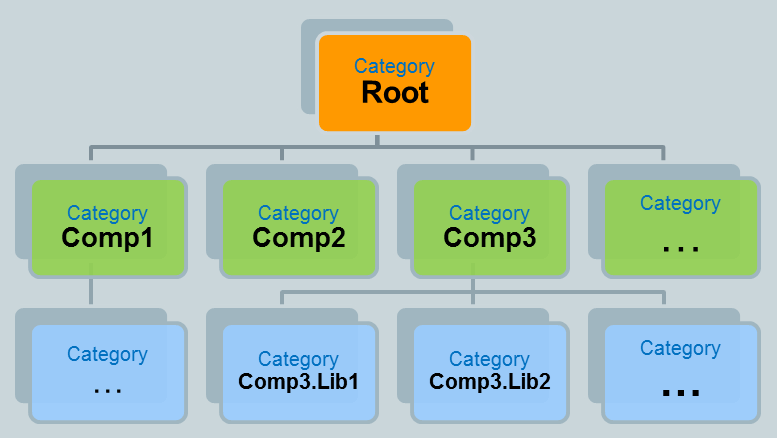
Category
現代的log庫一般都將Category組織成樹型結構,每一個節點都和前後組成父子關係,根據設定,子節點的Category完全可以繼承父節點的配置。所有的Category的根節點是root。這裡是一個典型的結構:
一個Category可以包含下面這幾個內容:
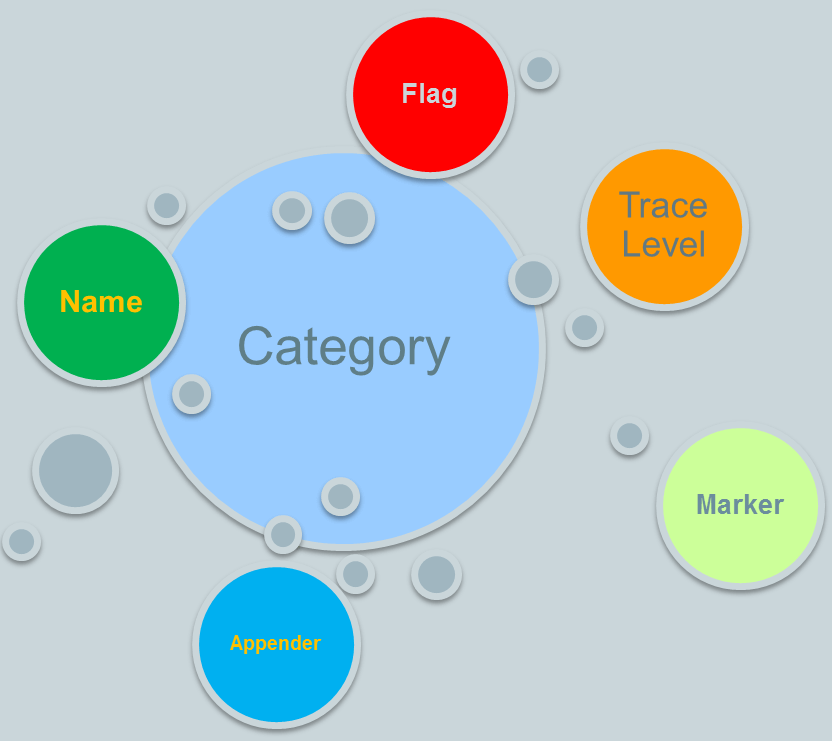
注意:一個Category可以有多個Appender。
Name, TraceLevel, Marker和Appender這裡就不再贅述。上圖中有一個Flag,這是什麼?它的存在和前面的樹型結構息息相關。前面講到,因為Category被組織成了樹型關係,子節點可以繼承父節點的配置,那麼何時可以繼承,如何繼承?這就是Flag的作用了,它包含了兩個選項:
- Process Parent: 如果勾選這一項,就表示一個子節點的log可以傳給它的父節點處理。這也是為什麼很多情況下只需要配置Root節點,其它的子節點設定這個Flag,就可以預設使用Root的全部配置。
- Use All Parent Appenders: 如果只有上面的Flag,那麼每次資訊傳到父節點時,父節點都必須根據自身的TraceLevel及Marker進行匹配,只有匹配時才會處理。而如果此Flag開啟,那麼在傳輸過程中,只要傳輸路徑上有一個節點匹配,再向上傳的所有節點都不再匹配而直接處理。
處理流程
至此你已經完全瞭解了log的基本概念以及用法,接下來我們更進一步,來看看log內部是如何工作的。
有了前面的演示程式碼之後再來看log內部處理流程將變得十分簡單,大致可以分為兩步,第一步過濾:
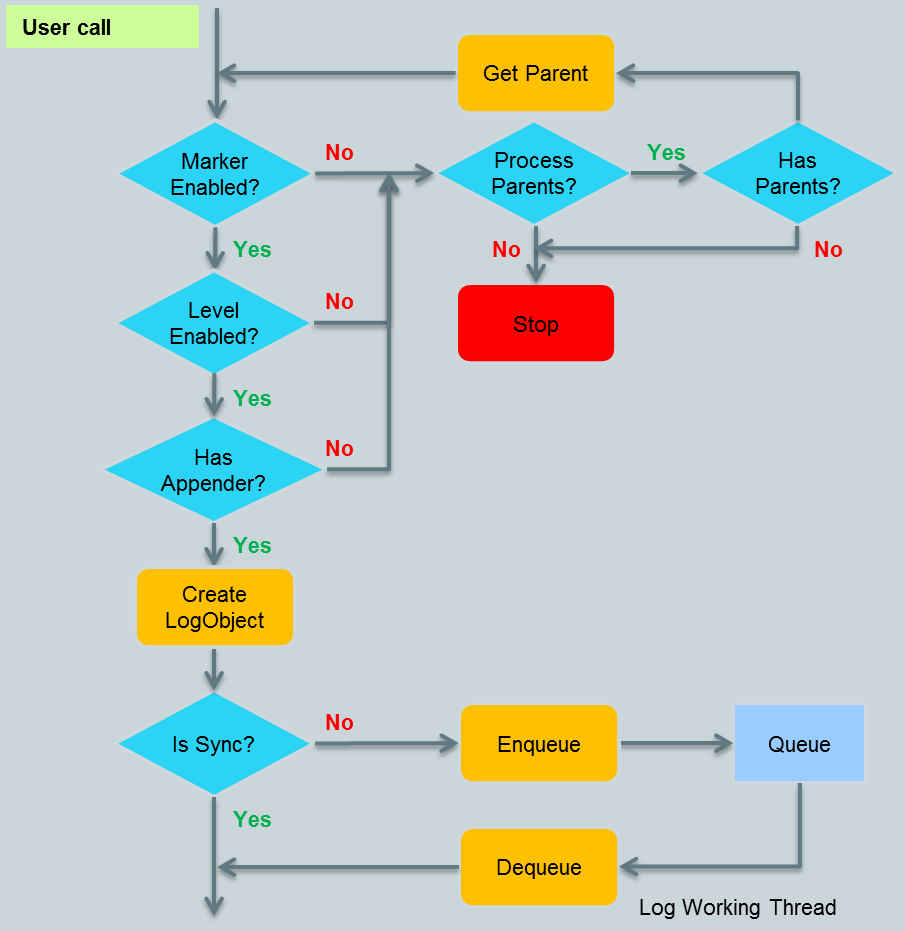
它在log的呼叫執行緒中發生,有些執行緒可能會對實時性有一定的要求,那麼log就不能夠在這種執行緒中去直接執行,而是將建立的log物件加入到佇列中,由專門的log工作執行緒處理,這樣就完全不會阻塞住主執行緒,保證主執行緒暢通無阻的執行。
流程的第二步是處理訊息:
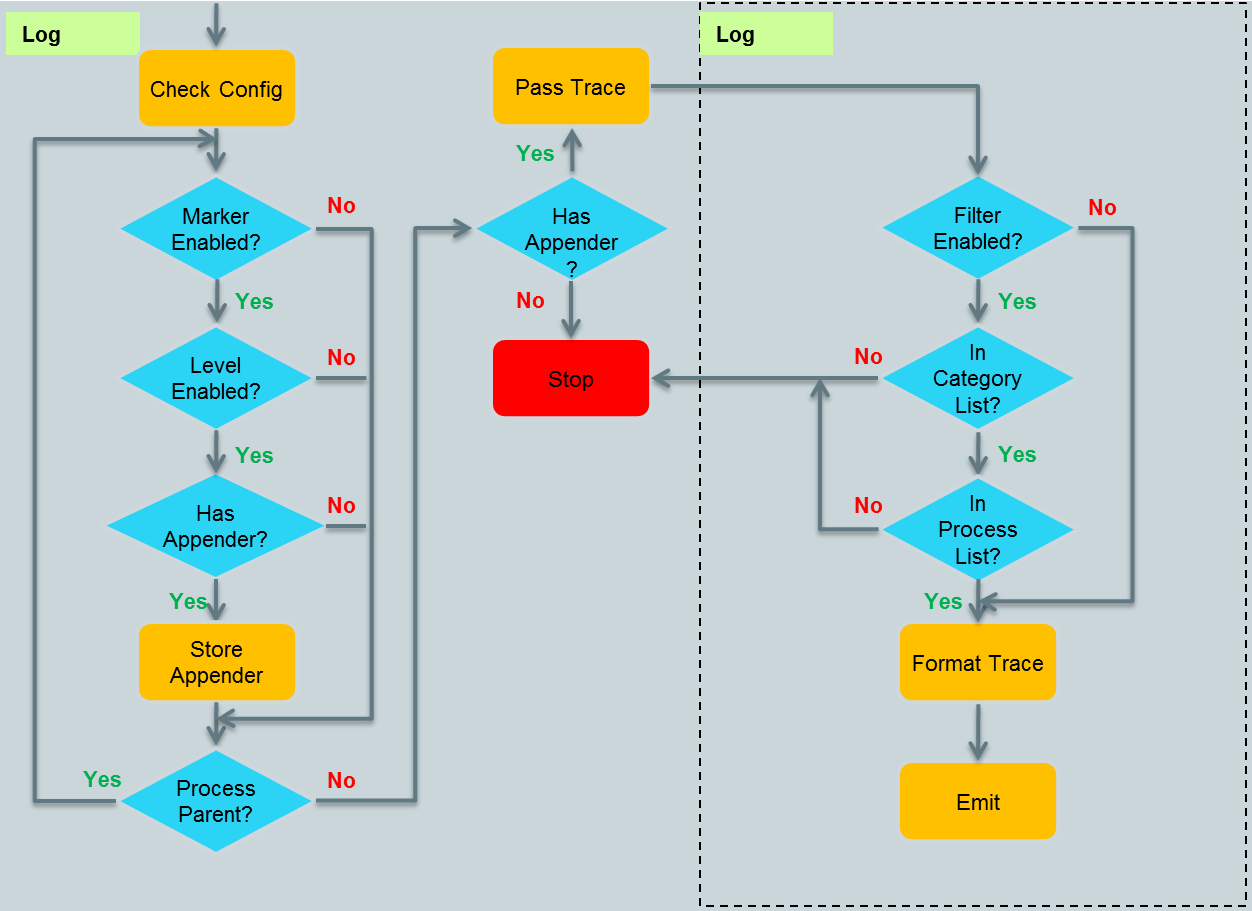
篩選過Category之後會將訊息發給每一個合適的Appender,由Appender進一步的篩選及格式化輸出。注意在這一步的剛開始有一個Check Config步驟,這和我們前面講的載入配置檔案的時機有關,很明顯,這裡用的是最後一種讀取配置的方案:即每次處理log時,檢測配置是否更新。
log在系統中的部署
也許你會想,一個簡單的庫有什麼好部署的,直接拿來用不就得了。可有時因為效能,或者系統過於龐大,配置起來會相當複雜,如果log組織的不好的話,你就會見到log檔案滿天飛,散落各處的情況。有時你可能會需要一個總的log檔案包含所有的資訊,一些特定目的的log還要存於不同的檔案中。如何保證不同程序,甚至不同的機器上的不同程序能夠無衝突的寫到同一個log檔案中呢?假設一個系統包含一臺Windows,一臺Linux,如何收集散落各個機器的log?如何方便的在Windows上檢視本應出現在Linux上的log?如果你有疑問,請看下面的解決方案:
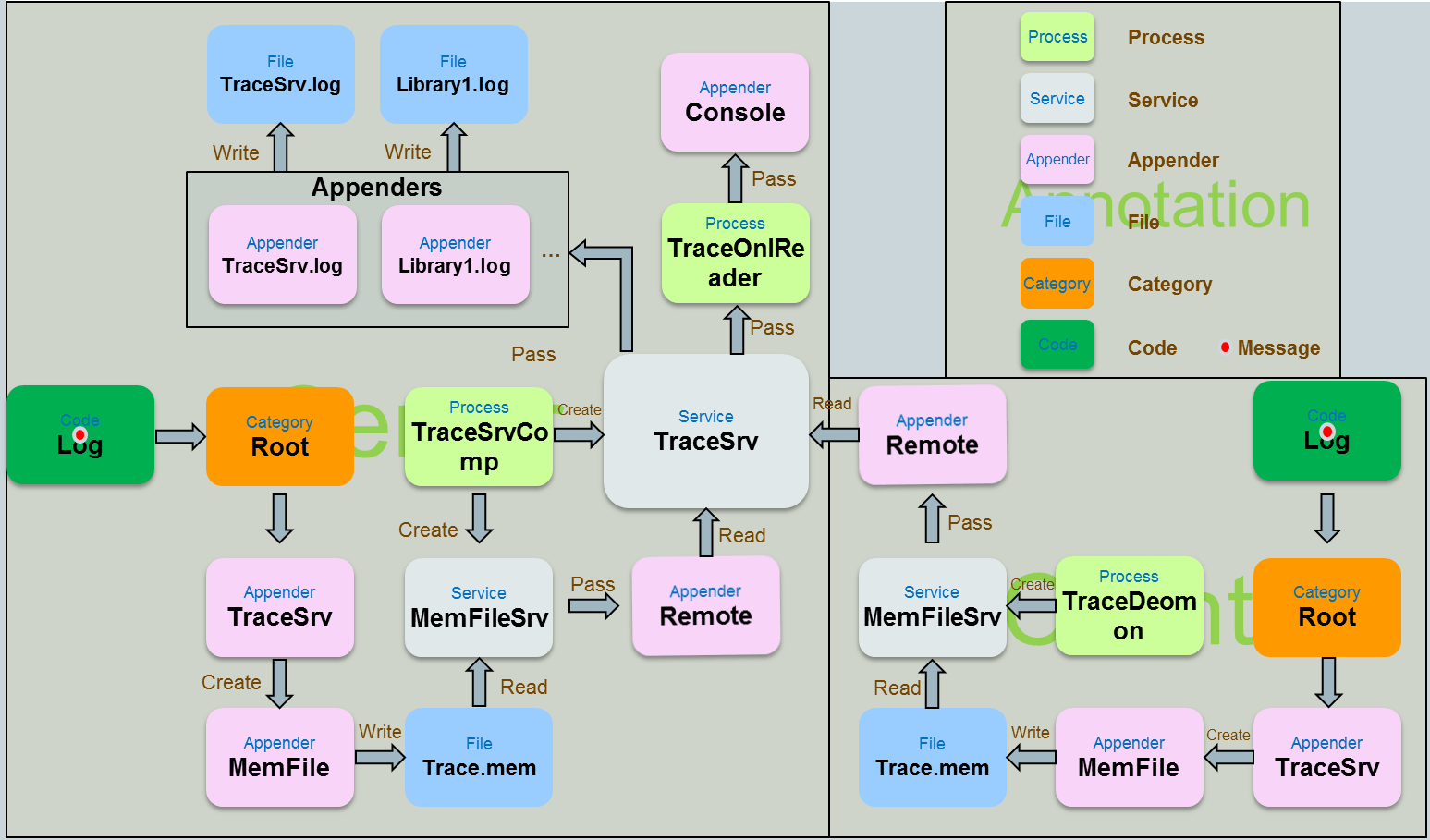
這個系統足夠龐大,包含了兩臺機器,左邊是Windows,右邊是Linux。每臺機器除各自儲存log之外,還將所有的log都最終交給Windows上的TraceSrv來處理,最終會有一份完整的包含所有機器的log存在於TraceSrv.log中,還有各個不同模組的log檔案。同時,還能夠通過遠端呼叫TraceOnlReader來實時從TraceSrv中讀取log資訊。如上圖所示,兩側綠色的Log圖例中,紅色的資訊沿著箭頭先全部匯聚到TraceSrv,然後再分發到不同的檔案中。
這樣,開發者就可以通過一次配置,便可以非常方便的組織好所有的log檔案,呼叫端完全剔除了這些複雜的細節,只需要關注log本身。
另外注意到,在Windows和Linux端各有一個memfile,它們各自存有機器上的所有log資訊,由於是運用了前面所說的mmap機制,程式直接以操作記憶體的方式來操作檔案,非常高效。
尾聲
好了,至此所有在知識分享中的內容便介紹完畢,希望對感興趣的你有所幫助。
我很喜歡部門的知識分享,分享是件好事,在分享的過程中,不僅僅可以讓他人獲取有用的資訊,而且你在分享前需要不斷的歸納總結,印證你的結論。在這個過程中,很多你當時思考不充分的問題也可能會得到解決,對你自身的知識、表達能力都有非常大的提高,利人利己。
不知你是否有過這樣的經歷,你遇到一個問題,百思不得其解,於是想向他人求助,可就在你向他人解釋這個問題的過程中,說著說著,你發現你找到問題的所在,於是問題解決了,甚至別人還沒明白怎麼回事。我就經常遇到這種情況。根據這點,有人總結出了一種新型的解決問題的方法,叫做橡皮鴨除錯法,維基百科對它有一個介紹,Jeff Atwood也專門寫過一篇文章:Rubber Duck Problem Solving。(至於為什麼叫橡皮鴨而不叫其它的,我想大概和美國人的成長經歷有關吧,每個孩子洗澡時都喜歡在浴缸中放一隻橡皮鴨,並與它交談,就像我們兒時的各種玩具一樣。)這樣做其實是有根據的,它和分享如出一輒,當你和橡皮鴨”交談”時,你需要徹底的把你的問題仔仔細細的描述一遍,不會放過每一個細節,為防質疑,你可能會做更多的調查。你在描述的同時,也一定在思考,這時之前沒有考慮到的方面可能就會暴露出來了。如果使用得當,也許,橡皮鴨除錯法可以成為log和debug以外,你分析問題又一強有力的武器:-)
最後,強烈建議你去看看Jeff的這篇文章。相關推薦
深入理解log機制
深入的探討了log機制中各種概念的來源、常用log庫的用法、內部處理流程,以及如何在一個涉及多臺主機的複雜系統中部署log等問題。本文是對這次分享的總結,將對這些問題一一展開介紹。 轉自:http://feihu.me/blog/2014/insight-into-log/
深入理解springioc機制,以下為例子做理解
通過java反射機制來讀取applicationContext.xml的內容 該xml檔案內容如下 <?xml version="1.0" encoding="UTF-8"?> <beans xmlns="http://www.springframework.org
深入理解this機制系列第二篇——this繫結優先順序
前面的話 上一篇介紹過this的繫結規則,那如果在函式的呼叫位置上同時存在兩種以上的繫結規則應該怎麼辦呢?本文將介紹this繫結的優先順序 顯式繫結 pk 隱式繫結 顯式繫結勝出 function foo() { console.log( this.a ); } var
深入理解this機制系列第一篇——this的4種繫結規則
前面的話 如果要問javascript中哪兩個知識點容易混淆,作用域查詢和this機制絕對名列前茅。前面的作用域系列已經詳細介紹過作用域的知識。本系列開始將介紹javascript的另一大山脈——this機制。本文是該系列的第一篇——this的4種繫結規則 預設繫結 全域性環境中,this預
JavaSrcipt的數字(number):深入理解內部機制
一、數字的語法 JavaScript中的數字字面量一般用十進位制表示。在JavaScript中表示數字的資料型別只有一種Number,這種天使與魔鬼同體的資料型別也就只有js了。 //同時表達整數和浮點數 var a = 78, b = 78.3; console.log(typeof a)
深入理解session機制
1. session概念 2. http協議與狀態保持 3. 理解cookie 4. php中session的生成機制 5. php中session的過期回收機制 6. php中session的客戶端儲存機制 1. session概念 在web伺服器蓬勃發
深入理解事件機制的實現
一、一個例項 假設你在家客廳裡玩遊戲,口渴了,需要到廚房開一壺水,等水開了的時候,為了防止水熬幹,你需要及時把火爐關掉。為了及時瞭解到水是否燒開,你有三種策略可以選擇: 1. 守在廚房內,等水燒開 這種策略顯然是很愚蠢的,採取這種策略,在燒水的過程中你將不能做任何事情,效率極低。 2. 呆在客廳玩遊戲
Android 深入理解 Notification 機制
本文需要解決的問題 筆者最近正在做一個專案,裡面需要用到 Android Notification 機制來實現某些特定需求。我
JDK原始碼系列(一) ------ 深入理解SPI機制
什麼是SPI機制 最近我建了另一個文章分類,用於擴充套件JDK中一些重要但不常用的功能。 SPI,全名Service Provider Interface,是一種服務發現機制。它可以看成是一種針對介面實現類的解耦方案。我們只需要採用配置檔案方式配置好介面的實現類,就可以利用SPI機制去載入到它們了,當我們需要
深入理解Java虛擬機- 學習筆記 - 虛擬機類加載機制
支持 pub eth 獲取 事件 必須 string 沒有 字節碼 虛擬機把描述類的數據從Class文件加載道內存,並對數據進行校驗,轉換解析和初始化,最終形成可以被虛擬機直接使用的Java類型,這就是虛擬機的類加載機制。在Java裏,類型的加載、連接和初始化過程都是在程序
深入理解JVM_java代碼的執行機制01
功能 存在 oot 對象實例 符號 token 類型 格式 找對象 本章學習重點: 1、Jvm: 如何將java代碼編譯為class文件。 如何裝載class文件及如何執行class文件。 jvm如何進行內存分配和回收。 jvm多線程
深入理解Java:類加載機制及反射
指定 請求 image vm虛擬機 常量池 使用 元素 靜態 創建 一、Java類加載機制 1.概述 Class文件由類裝載器裝載後,在JVM中將形成一份描述Class結構的元信息對象,通過該元信息對象可以獲知Class的結構信息:如構造函數,屬性和方法等,J
深入理解 Java 垃圾回收機制
nbsp 循環引用 方式 不同的 整理 一個 復制 垃圾回收機制 提高 垃圾回收機制中的算法: 1.引用計數法:無法檢測出循環引用。如父對象有一個對子對象的引用,子對象反過來引用父對象。這樣,他們的引用計數永遠不可能為0. 2 標記-清除算法:采用從根集合進行掃描,對存活
深入理解Java類型信息(Class對象)與反射機制
成員變量 字段 機制 () 程序 轉換 默認 數據 統一 深入理解Class對象 RRTI的概念以及Class對象作用 認識Class對象之前,先來了解一個概念,RTTI(Run-Time Type Identification)運行時類型識別,對於這個詞一
深入理解ceph-disk運行機制
意圖 gui for ons 簡單介紹 water 自動化 深入理解 /var/ 谷忠言 一,背景 目前項目所用的ceph集群內部的一個節點, 一般需要管理大約十塊硬盤左右的數據存儲空間,外加一到兩塊ssd組成的journal空間。Ceph要求每個osd對應的數據盤掛載到特
Android 異步消息處理機制前篇(二):深入理解Message消息池
連接 guid ply 指針 cau ann 區別 就會 消息處理機制 版權聲明:本文出自汪磊的博客,轉載請務必註明出處。 上一篇中共同探討了ThreadLocal,這篇我們一起看下常提到的Message消息池到底是怎麽回事,廢話少說吧,進入正題。 對於稍有經驗的開發人員來
深入理解asp.net裏的HttpModule機制
img 決定 來講 sessions test 需要 mce 應該 cat 轉自http://jeffwongishandsome.cnblogs.com/ 1、asp.net的HTTP請求處理過程說明:(1)、客戶端瀏覽器向服務器發出一個http請求,此請求會被ineti
深入理解Dalvik虛擬機- 解釋器的執行機制
util dlink stat counter before expose 加鎖 enter 機制 Dalvik的指令運行是解釋器+JIT的方式,解釋器就
iOS runtime探究(二): 從runtime開始深入理解OC消息轉發機制
phoenix face exp nslog void string ams ber 解釋 你要知道的runtime都在這裏 轉載請註明出處 http://blog
深入理解虛擬機之虛擬機類加載機制
Java JVM Java面試通關手冊(Java學習指南,歡迎Star,會一直完善下去,歡迎建議和指導):https://github.com/Snailclimb/Java_Guide 《深入理解Java虛擬機:JVM高級特性與最佳實踐(第二版》讀書筆記與常見相關面試題總結 本節常見面試題(推薦帶著