
【資料結構】演算法2.22-2.23 一元多項式的表示及相加
#include<stdio.h>
#include<string.h>
#include<stdlib.h>
#define TRUE 1
#define FALSE 0
#define OK 1
#define ERROR 0
#define INFEASIBLE -1
#define OVERFLOW -2
typedef int Status;
typedef struct
{
int coef; //係數
int expn; //指數
}term,ElemType;
typedef struct LNode
{
ElemType data;
struct LNode *next 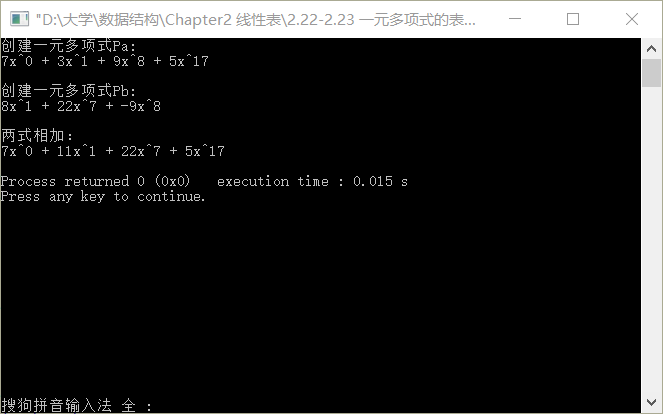
相關推薦
【資料結構】演算法2.22-2.23 一元多項式的表示及相加
#include<stdio.h> #include<string.h> #include<stdlib.h> #define TRUE 1 #define FALSE 0 #define OK 1 #define ERRO
【資料結構】演算法5.1-5.2 三元組順序表-轉置
#include<stdio.h> #include<string.h> #include<stdlib.h> #define TRUE 1 #define FALSE 0 #define OK 1 #define ERRO
【資料結構】演算法4.2&4.3 串連線Concat&求子串SubString
/* 串的定長順序儲存表示 */ #include<stdio.h> #include<string.h> #include<stdlib.h> #define OK 1 #define ERROR 0 #define
【資料結構與演算法分析1.2】編寫一個程式求解字謎遊戲問題
問題描述:輸入是由一些字母和單詞構成的二維陣列,目標是找出字謎中的單詞,這些單詞可以是水平、垂直或沿對角線以任何方向放置。找出二維陣列中所有的單詞 寫完這個程式,手都要斷掉了,太TM麻煩了,而且效率很低,到底有多少個for迴圈,自己都數不清。 //1.2編寫
【資料結構】演算法的度量
時間複雜度 T(n) = O(f(n)) 它表示隨問題規模n的增大,演算法的時間增長率和f(n)的增長率相同,稱為演算法的時間漸進複雜度。其中f(n)是問題規模n的某個函式。 一般來說,隨著n的增長,T(n)增長最慢的演算法為最優演算法 要在 hash 表中找到一個元素
【軟考】【資料結構】演算法基礎
演算法與資料結構的關係:演算法的實現依賴於資料結構的設計,儘管在設計演算法步驟時可以不考慮資料結構,但演算法在計算機上與採用的資料結構密切相關。演算法的效率與資料結構有一定的關係,但並不是資料結構越簡單演算法的效率就會越高。 1.演算法的特性
【資料結構和演算法】2談談演算法
演算法初體驗 高斯演算法"1+2+3+...+100" 普通的解決方法 int i, sum = 0, n = 100; for(i=1; i <= n; i++) { sum = sum + i; } printf(“%d”, sum); 利用高斯的演算法 int i,
【資料結構和演算法06】2-3-4樹
從第4節的分析中可以看出,二叉搜尋樹是個很好的資料結構,可以快速地找到一個給定關鍵字的資料項,並且可以快速地插入和刪除資料項。但是二叉搜尋樹有個很麻煩的問題,如果樹中插入的是隨機資料,則執行效果很好,但如果插入的是有序或者逆序的資料,那麼二叉搜尋樹的執行速度就變得很慢
【資料結構】--2.排序演算法
常見的排序演算法 :氣泡排序 、選擇排序、插入排序、歸併排序、快速排序、堆排序 https://www.cnblogs.com/eniac12/p/5329396.html #include<iostream> using namespace std; v
【資料結構與演算法分析】1.2 編寫程式解決字謎問題
原博:http://blog.csdn.net/u013667086/article/details/49179741 問題描述: 從已知的字謎中找出在字典中的單詞 解決思路: 1、用指標陣列存放字謎和字典單詞 2、將字典單
【資料結構】-線性表-順序表-1324: 演算法2-2:有序線性表的有序合併
1324: 演算法2-2:有序線性表的有序合併 題目描述 已知線性表 LA 和 LB 中的資料元素按值非遞減有序排列,現要求將 LA 和 LB 歸併為一個新的線性表 LC, 且 LC 中的資料元素仍然按值非遞減有序排列。例如,設LA=(3,5,8,11)
【資料結構】1-2 約瑟夫環問題
這裡放出兩種不同的程式碼,一個是老師給的(較為複雜),還有一個是自己寫的。 自己寫的: #include<iostream> using namespace std; struct Node { int data; //資料單元 Node *link
【資料結構】順序表的應用(2)
問題: 2.有順序表A和B,其元素均按從小到大的升序排列,編寫一個演算法,將它們合併成一個順序表C,要求C的元素也按從小到大的升序排列。 #include "stdio.h" #include "sequlist.h" int main () { int le
【資料結構】天勤線性表思考題2.1
有N個個位正整數存放在int整型陣列A中,N定義為已經定義的常亮N<=9,陣列長度為N,另給一個int型變數i,要求只用上述變數,寫一個演算法,找出N個整數中的最小者,並且要求不能破壞陣列資料。 思路:i作為變數,這個變數的百位用於儲存最小值地址,十位用來儲存最小值,
【演算法與資料結構】演算法複雜度分析
一、什麼是複雜度分析? 1.資料結構和演算法解決是“如何讓計算機更快時間、更省空間的解決問題”。 2.因此需從執行時間和佔用空間兩個維度來評估資料結構和演算法的效能。 3.分別用時間複雜度和空間複雜度兩個概念來描述效能問題,二者統稱為複雜度。 4.複雜度描述的是演算法執行時間(或佔用空間)與資料
學習JavaScript資料結構與演算法(第2版).epub
【下載地址】 本書首先介紹了JavaScript 語言的基礎知識以及ES6 和ES7 中引入的新功能,接下來討論了陣列、棧、佇列、連結串列、集合、字典、散列表、樹、圖等資料結構,之後探討了各種排序和搜尋演算法,包括氣泡排序、選擇排序、插入排序、歸併排序、快速排序、堆排序、
資料結構與演算法分析-第2章
.title { text-align: center; margin-bottom: .2em } .subtitle { text-align: center; font-size: medium; font-weight: bold; margin-top: 0 } .todo { font-famil
【資料結構與演算法】插入排序
插入排序是演算法中的基礎入門和氣泡排序、選擇排序都是必要掌握的。他們都是對比排序,需要通過比較大小交換位置,進行排序。 插入排序的實現思路: 1、 從第一個元素開始,這個元素可以認為已經被排序。 2、取出下一個元素,在已排序的序列中從後往前掃描。 3、如果該元素小於小於前
【資料結構與演算法】 ---快速排序
快速排序流程: 1.從數列中挑出一個基準值 2.將所有比基準值小的擺放在基準前面,所有比基準值大的擺在後面(相同的數可以放到任一邊);在這個分割槽退出之後,該基準就處於數列的中間位置。 3.遞迴地把“基準值前面的子數列”和“基準值後面的子數列”進行排序。 下面以數列
【資料結構與演算法】------氣泡排序
學習開發一年的時間裡,很少去了解排序演算法,氣泡排序也是最開始學習的樣子,靠死記硬背,沒有引入自己的理解。 對於什麼時間複雜度和空間複雜度和穩定性也不清楚其原委,或許在程式碼方面少了幾許的天分: 氣泡排序: 氣泡排序每一輪的比較都是前面的數和後面的數進行比較,並交