
海量資料處理之外排序
前言:
現在先讓我們來看一道有關外排序的題:
問題描述:
輸入:一個最多含有n個不重複的正整數(也就是說可能含有少於n個不重複正整數)的檔案,其中每個數都小於等於n,且n=10^7。
輸出:得到按從小到大升序排列的包含所有輸入的整數的列表。
條件:最多有大約1MB的記憶體空間可用,但磁碟空間足夠。且要求執行時間在5分鐘以下,10秒為最佳結果。
本題有很多種解法,列出一下幾種:
分析:下面咱們來一步一步的解決這個問題,
1、歸併排序。你可能會想到把磁碟檔案進行歸併排序,但題目要求你只有1MB的記憶體空間可用,所以,歸併排序這個方法不行。
2、點陣圖方案。熟悉點陣圖的朋友可能會想到用點陣圖來表示這個檔案集合。例如正如程式設計珠璣一書上所述,用一個20位長的字串來表示一個所有元素都小於20的簡單的非負整數集合,邊框用如下字串來表示集合{1,2,3,5,8,13}:
0 1 1 1 0 1 0 0 1 0 0 0 0 1 0 0 0 0 0 0
上述集合中各數對應的位置則置1,沒有對應的數的位置則置0。
參考程式設計珠璣一書上的點陣圖方案,針對我們的10^7個數據量的磁碟檔案排序問題,我們可以這麼考慮,由於每個7位十進位制整數表示一個小於1000萬的整數。我們可以使用一個具有1000萬個位的字串來表示這個檔案,其中,當且僅當整數i在檔案中存在時,第i位為1。採取這個點陣圖的方案是因為我們面對的這個問題的特殊性:1、輸入資料限制在相對較小的範圍內,2、資料沒有重複,3、其中的每條記錄都是單一的整數,沒有任何其它與之關聯的資料。
所以,此問題用點陣圖的方案分為以下三步進行解決:
- 第一步,將所有的位都置為0,從而將集合初始化為空。
- 第二步,通過讀入檔案中的每個整數來建立集合,將每個對應的位都置為1。
- 第三步,檢驗每一位,如果該位為1,就輸出對應的整數。
經過以上三步後,產生有序的輸出檔案。令n為點陣圖向量中的位數(本例中為1000 0000),程式可以用偽程式碼表示如下:
- //磁碟檔案排序點陣圖方案的虛擬碼
- //[email protected] Jon Bentley
- //July、updated,2011.05.29。
- //第一步,將所有的位都初始化為0
- for i ={0,....n}
- bit[i]=0;
- //第二步,通過讀入檔案中的每個整數來建立集合,將每個對應的位都置為1。
- for each i in the input file
- bit[i]=1;
- //第三步,檢驗每一位,如果該位為1,就輸出對應的整數。
- for i={0...n}
- if bit[i]==1
- write i on the output file
//磁碟檔案排序點陣圖方案的虛擬碼
//[email protected] Jon Bentley
//July、updated,2011.05.29。
//第一步,將所有的位都初始化為0
for i ={0,....n}
bit[i]=0;
//第二步,通過讀入檔案中的每個整數來建立集合,將每個對應的位都置為1。
for each i in the input file
bit[i]=1;
//第三步,檢驗每一位,如果該位為1,就輸出對應的整數。
for i={0...n}
if bit[i]==1
write i on the output file上面只是為了簡單介紹下點陣圖演算法的虛擬碼之抽象級描述。顯然,咱們面對的問題,可不是這麼簡單。下面,我們試著針對這個要分兩趟給磁碟檔案排序的具體問題編寫完整程式碼,如下。
3、多路歸併。
1、記憶體排序
由於要求的可用記憶體為1MB,那麼每次可以在記憶體中對250K的資料進行排序,然後將有序的數寫入硬碟。
那麼10M的資料需要迴圈40次,最終產生40個有序的檔案。
2、歸併排序
- 將每個檔案最開始的數讀入(由於有序,所以為該檔案最小數),存放在一個大小為40的first_data陣列中;
- 選擇first_data陣列中最小的數min_data,及其對應的檔案索引index;
- 將first_data陣列中最小的數寫入檔案result,然後更新陣列first_data(根據index讀取該檔案下一個數代替min_data);
- 判斷是否所有資料都讀取完畢,否則返回2。
所以,本程式按順序分兩步,第一步、Memory Sort,第二步、Merge Sort。程式的流程圖,如下圖所示(感謝F的繪製)。
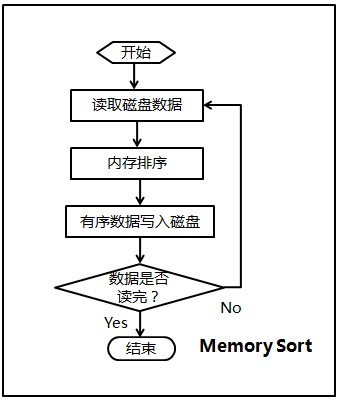
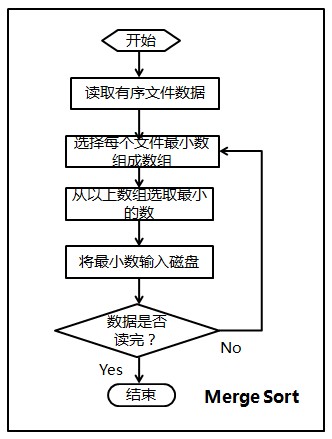
然後,編寫的完整程式碼如下:
首先我們將生成大資料量(1000萬)的程式如下:
01.//purpose: 生成隨機的不重複的測試資料
02.//[email protected] 2011.04.19 yansha
03.//1000w資料量,要保證生成不重複的資料量,一般的程式沒有做到。
04.//但,本程式做到了。
05.//July、2010.05.30。
06.#include <iostream>
07.#include <time.h>
08.#include <assert.h>
09.using namespace std;
10.
11.const int size = 10000000;
12.int num[size];
13.
14.int main()
15.{
16. int n;
17. FILE *fp = fopen("data.txt", "w");
18. assert(fp);
19.
20. for (n = 1; n <= size; n++)
21. //之前此處寫成了n=0;n<size。導致下面有一段小程式的測試資料出現了0,特此訂正。
22. num[n] = n;
23. srand((unsigned)time(NULL));
24. int i, j;
25.
26. for (n = 0; n < size; n++)
27. {
28. i = (rand() * RAND_MAX + rand()) % 10000000;
29. j = (rand() * RAND_MAX + rand()) % 10000000;
30. swap(num[i], num[j]);
31. }
32.
33. for (n = 0; n < size; n++)
34. fprintf(fp, "%d ", num[n]);
35. fclose(fp);
36. return 0;
37.}
01.//[email protected] yansha
02.//July、updated,2011.05.28。
03.#include <iostream>
04.#include <string>
05.#include <algorithm>
06.#include <time.h>
07.using namespace std;
08.
09.int sort_num = 10000000;
10.int memory_size = 250000;
11.
12.//每次只對250k個小資料量進行排序
13.int read_data(FILE *fp, int *space)
14.{
15. int index = 0;
16. while (index < memory_size && fscanf(fp, "%d ", &space[index]) != EOF)
17. index++;
18. return index;
19.}
20.
21.void write_data(FILE *fp, int *space, int num)
22.{
23. int index = 0;
24. while (index < num)
25. {
26. fprintf(fp, "%d ", space[index]);
27. index++;
28. }
29.}
30.
31.// check the file pointer whether valid or not.
32.void check_fp(FILE *fp)
33.{
34. if (fp == NULL)
35. {
36. cout << "The file pointer is invalid!" << endl;
37. exit(1);
38. }
39.}
40.
41.int compare(const void *first_num, const void *second_num)
42.{
43. return *(int *)first_num - *(int *)second_num;
44.}
45.
46.string new_file_name(int n)
47.{
48. char file_name[20];
49. sprintf(file_name, "data%d.txt", n);
50. return file_name;
51.}
52.
53.int memory_sort()
54.{
55. // open the target file.
56. FILE *fp_in_file = fopen("data.txt", "r");
57. check_fp(fp_in_file);
58. int counter = 0;
59. while (true)
60. {
61. // allocate space to store data read from file.
62. int *space = new int[memory_size];
63. int num = read_data(fp_in_file, space);
64. // the memory sort have finished if not numbers any more.
65. if (num == 0)
66. break;
67.
68. // quick sort.
69. qsort(space, num, sizeof(int), compare);
70. // create a new auxiliary file name.
71. string file_name = new_file_name(++counter);
72. FILE *fp_aux_file = fopen(file_name.c_str(), "w");
73. check_fp(fp_aux_file);
74.
75. // write the orderly numbers into auxiliary file.
76. write_data(fp_aux_file, space, num);
77. fclose(fp_aux_file);
78. delete []space;
79. }
80. fclose(fp_in_file);
81.
82. // return the number of auxiliary files.
83. return counter;
84.}
85.
86.void merge_sort(int file_num)
87.{
88. if (file_num <= 0)
89. return;
90. // create a new file to store result.
91. FILE *fp_out_file = fopen("result.txt", "w");
92. check_fp(fp_out_file);
93.
94. // allocate a array to store the file pointer.
95. FILE **fp_array = new FILE *[file_num];
96. int i;
97. for (i = 0; i < file_num; i++)
98. {
99. string file_name = new_file_name(i + 1);
100. fp_array[i] = fopen(file_name.c_str(), "r");
101. check_fp(fp_array[i]);
102. }
103.
104. int *first_data = new int[file_num];
105. //new出個大小為0.1億/250k陣列,由指標first_data指示陣列首地址
106. bool *finish = new bool[file_num];
107. memset(finish, false, sizeof(bool) * file_num);
108.
109. // read the first number of every auxiliary file.
110. for (i = 0; i < file_num; i++)
111. fscanf(fp_array[i], "%d ", &first_data[i]);
112. while (true)
113. {
114. int index = 0;
115. while (index < file_num && finish[index])
116. index++;
117.
118. // the finish condition of the merge sort.
119. if (index >= file_num)
120. break;
121. //主要的修改在上面兩行程式碼,就是merge sort結束條件。
122. //要保證所有檔案都讀完,必須使得finish[0]...finish[40]都為真
123. //July、yansha,555,2011.05.29。
124.
125. int min_data = first_data[index];
126. // choose the relative minimum in the array of first_data.
127. for (i = index + 1; i < file_num; i++)
128. {
129. if (min_data > first_data[i] && !finish[i])
130. //一旦發現比min_data更小的資料first_data[i]
131. {
132. min_data = first_data[i];
133. //則置min_data<-first_data[i]index = i;
134. //把下標i 賦給index。
135. }
136. }
137.
138. // write the orderly result to file.
139. fprintf(fp_out_file, "%d ", min_data);
140. if (fscanf(fp_array[index], "%d ", &first_data[index]) == EOF)
141. finish[index] = true;
142. }
143.
144. fclose(fp_out_file);
145. delete []finish;
146. delete []first_data;
147. for (i = 0; i < file_num; i++)
148. fclose(fp_array[i]);
149. delete [] fp_array;
150.}
151.
152.int main()
153.{
154. clock_t start_memory_sort = clock();
155. int aux_file_num = memory_sort();
156. clock_t end_memory_sort = clock();
157. cout << "The time needs in memory sort: " << end_memory_sort - start_memory_sort << endl;
158. clock_t start_merge_sort = clock();
159. merge_sort(aux_file_num);
160. clock_t end_merge_sort = clock();
161. cout << "The time needs in merge sort: " << end_merge_sort - start_merge_sort << endl;
162. system("pause");
163. return 0;
164.}
相關推薦
海量資料處理之外排序
前言: 現在先讓我們來看一道有關外排序的題: 問題描述: 輸入:一個最多含有n個不重複的正整數(也就是說可能含有少於n個不重複正整數)的檔案,其中每個數都小於等於n,且n=10^7。 輸出:得到按從小到大升序排列的包含所有輸入的整數的列表。 條件:最多有大約1MB的記憶體
海量資料處理-重新思考排序
海量資料處理--重新思考排序(1) 海量資料處理常用技術概述 如今網際網路產生的資料量已經達到PB級別,如何在資料量不斷增大的情況下,依然保證快速的檢索或者更新資料,是我們面臨的問題。 所謂海量資料處理,是指基於海量資料的儲存、處理和操作等。因為資料量太大無法
海量資料處理專題(九)——外排序(轉)
【引言】在資料結構的課程上,我們學習了不少的排序演算法,冒泡,堆,快排,歸併等。但是這些排序方法有著共同的特點,那就是所有的操作都是在記憶體中完成的,演算法過程中不需要IO,這就使得這樣的演算法總體上速度比較快,但是也隨之出現了一個問題:當需要排序的資料量異常的大的時候,以上的演算法就顯得力不從心了。這時候,
由散列表到BitMap的概念與應用(三):面試中的海量資料處理
一道面試題 在面試軟體開發工程師時,經常會遇到海量資料排序和去重的面試題,特別是大資料崗位。 例1:給定a、b兩個檔案,各存放50億個url,每個url各佔64位元組,記憶體限制是4G,找出a、b檔案共同的url? 首先我們最常想到的方法是讀取檔案a,建立雜湊表,然後再讀取檔案b,遍歷檔
十道海量資料處理面試題與十個方法大總結:
轉載之處:http://blog.csdn.net/liuqiyao_01/article/details/26567237 筆試 = (資料結構+演算法) 50%+ (計算機網路 + 作業系統)30% +邏輯智力題10% + 資料庫5% + 歪門邪道題5%,而面
海量資料處理方法及應用
一、雜湊切割top K問題 1. 給一個超過100G大小的log file, log中存著IP地址, 設計演算法找到出現次數最多的IP地址? (1)首先使用雜湊函式HashFunc(ip)將每一個IP地址轉化為整型,再通過HashFunc(i
海量資料處理例項
在bat等大公司,基本所有業務的資料量級都很龐大,那麼如何在保證資料完整性的情況下快速處理成了一個通用的難題,這裡列舉幾個例子,大致反應一些處理思想。 1.一個檔案中,每一行有一個整數,有上億行,目的:統計出現次數超過三次的整數寫入到另一個檔案中。 分析: (1)首先資料
海量資料處理演算法—Bit-Map
分享一下我老師大神的人工智慧教程!零基礎,通俗易懂!http://blog.csdn.net/jiangjunshow 也歡迎大家轉載本篇文章。分享知識,造福人民,實現我們中華民族偉大復興!
海量資料處理(一) 求top k問題
優先順序佇列 給一組海量資料,限制記憶體為2M,,找出裡面最大/小的Tokp k int main() { vector<int> vec; srand(time(NULL)); for(int i =0;i<1000000;i++) { v
海量資料處理:十道面試題與十個海量資料處理方法總結(大資料演算法面試題)
第一部分、十道海量資料處理面試題 1、海量日誌資料,提取出某日訪問百度次數最多的那個IP。 首先是這一天,並且是訪問百度的日誌中的IP取出來,逐個寫入到一個大檔案中。注意到IP是32位的,最多有個2^32個IP。同樣可以採用對映的方法
python資料處理--堆排序演算法
堆排序思路: 構建大頂堆(小頂堆) 交換堆的首尾元素,堆長度減一 交換首尾元素後,驗證堆的合規性,若不合規則調整資料位置,直至合規 重複2和3步驟,直至長度為0,結束 python實現_問題分析: 問題1:如何構建初始堆 問題2:序列長度與節點數量的關係(node
海量資料處理問題
雜湊切割、Top K問題 問題一:給一個超過100G大小的log file, log中存著IP地址, 設計演算法找到出現次數最多的IP地址? 問題二:與上題目條件相同,如何找出Top K的IP? 問題
海量資料處理:十道面試題與十個海量資料處理方法總結
第一部分、十道海量資料處理面試題 1、海量日誌資料,提取出某日訪問百度次數最多的那個IP。 首先是這一天,並且是訪問百度的日誌中的IP取出來,逐個寫入到一個大檔案中。注意到IP是32位的,最多有個2^32個IP。同樣可以採用對映的方法,比如模1000,把整個大檔
動不動的“上千萬”——海量資料處理面試題
一、 海量資料,出現次數最多or前K 1、給A,B兩個檔案,各存放50億條URL,每條URL佔用64個位元組,記憶體限制為4G,找出A,B中相同的URL。 【分析】我們先來看如果要把這些URL全部載入到記憶體中,需要多大的空間。 1MB = 2^20 = 10^6 =
面試技巧——十道海量資料處理面試題與十個方法大總結
第一部分、十道海量資料處理面試題 1、海量日誌資料,提取出某日訪問百度次數最多的那個IP。 首先是這一天,並且是訪問百度的日誌中的IP取出來,逐個寫入到一個大檔案中。注意到IP是32位的,最多有個2^32個IP。同樣可以採用對映的方法,比如模1000,把整個大
(轉)十道海量資料處理面試題與十個方法大總結
首先是這一天,並且是訪問百度的日誌中的IP取出來,逐個寫入到一個大檔案中。注意到IP是32位的,最多有個232個IP。同樣可以採用對映的方法,比如模1000,把整個大檔案對映為1000個小檔案,再找出每個小文中出現頻率最大的IP(可以採用hash_m
海量資料處理-Topk引發的思考
海量資料處理–TopK引發的思考 三問海量資料處理: 什麼是海量資料處理,為什麼出現這種需求? 如何進行海量資料處理,常用的方法和技術有什麼? 如今分散式框架已經很成熟了,為什麼還用學習海量資料處理的
十道海量資料處理面試題與十個方法大總結
海量資料處理:十道面試題與十個海量資料處理方法總結第一部分、十道海量資料處理面試題1、海量日誌資料,提取出某日訪問百度次數最多的那個IP。 首先是這一天,並且是訪問百度的日誌中的IP取出來,逐個寫入到一個大檔案中。注意到IP是32位的,
從Hadoop框架與MapReduce模式中談海量資料處理 含淘寶技術架構
從hadoop框架與MapReduce模式中談海量資料處理前言 幾周前,當我最初聽到,以致後來初次接觸Hadoop與MapReduce這兩個東西,我便稍顯興奮,覺得它們很是神祕,而神祕的東西常能勾起我的興趣,在看過介紹它們的文章或論文之後,覺得Ha
海量資料處理演算法—Bloom Filter
1. Bloom-Filter演算法簡介 Bloom-Filter,即布隆過濾器,1970年由Bloom中提出。它可以用於檢索一個元素是否在一個集合中。Bloom Filter(BF)是一種空間效率很高的隨機資料結構,它利用位陣列很簡潔地表示一個集合,並能判斷一個